Baichuan-M4: A Clinical-Grade Medical Agent System for Continuous Care
Pith reviewed 2026-06-27 16:57 UTC · model grok-4.3
The pith
Baichuan-M4 coordinates agents, memory, and tools to deliver continuous medical care with a 3.3% hallucination rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
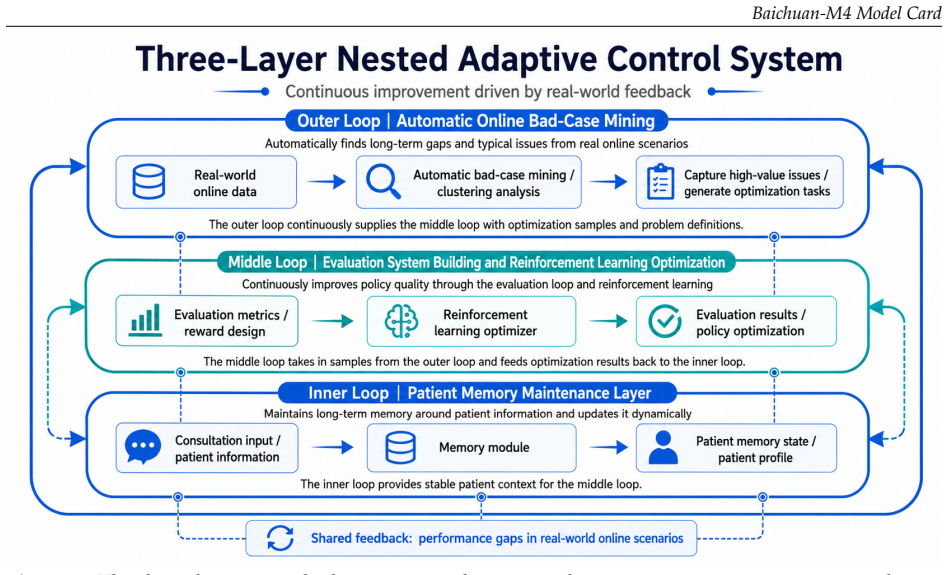
Baichuan-M4 is built as a coordinated medical agent system around three pillars: Baichuan-Harness, a unified runtime that keeps reinforcement-learning training and real-world deployment consistent while enforcing action constraints, tool use, long-term patient memory, and multi-agent coordination; a core reasoning model trained with a continuous-care reinforcement-learning framework that integrates span-level reward modeling, reasoning-path compression, curriculum learning, and stabilized policy optimization; and a clinical tool layer for patient-memory management, authoritative evidence-based retrieval, and multimodal medical perception across documents, X-rays, and dermatology.
What carries the argument
Baichuan-Harness, a unified runtime that aligns reinforcement-learning training with deployment while enforcing constraints, tool use, long-term memory, and multi-agent coordination.
If this is right
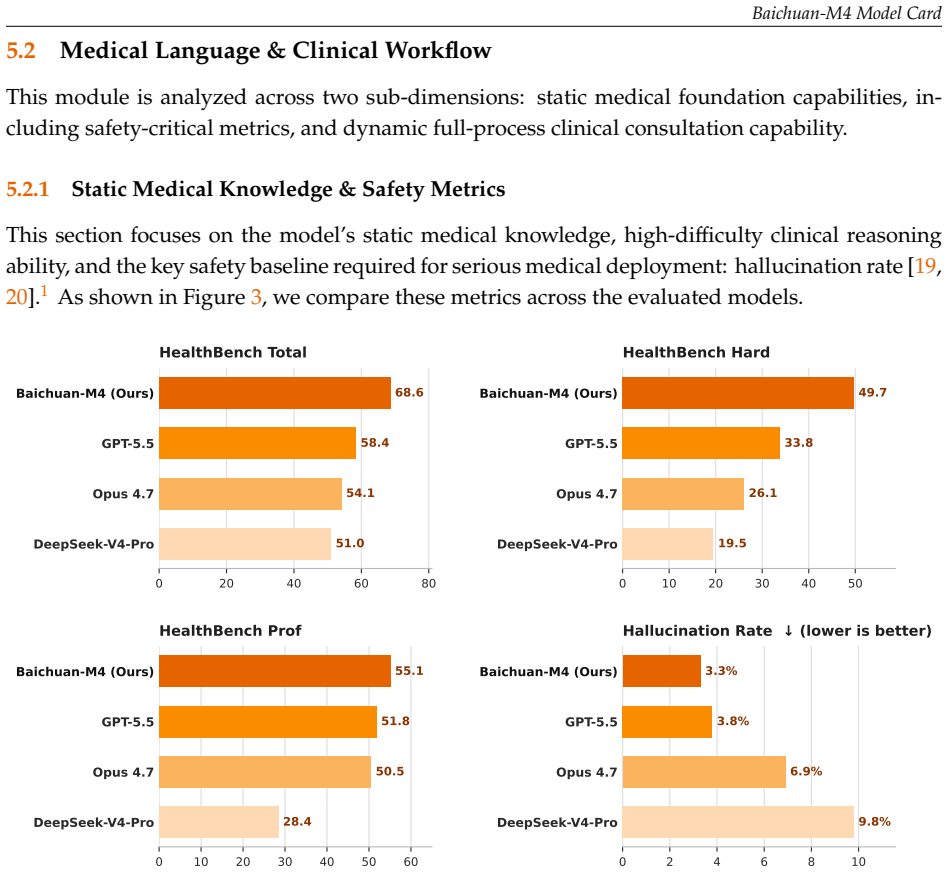
- Leads in static medical knowledge and safety benchmarks.
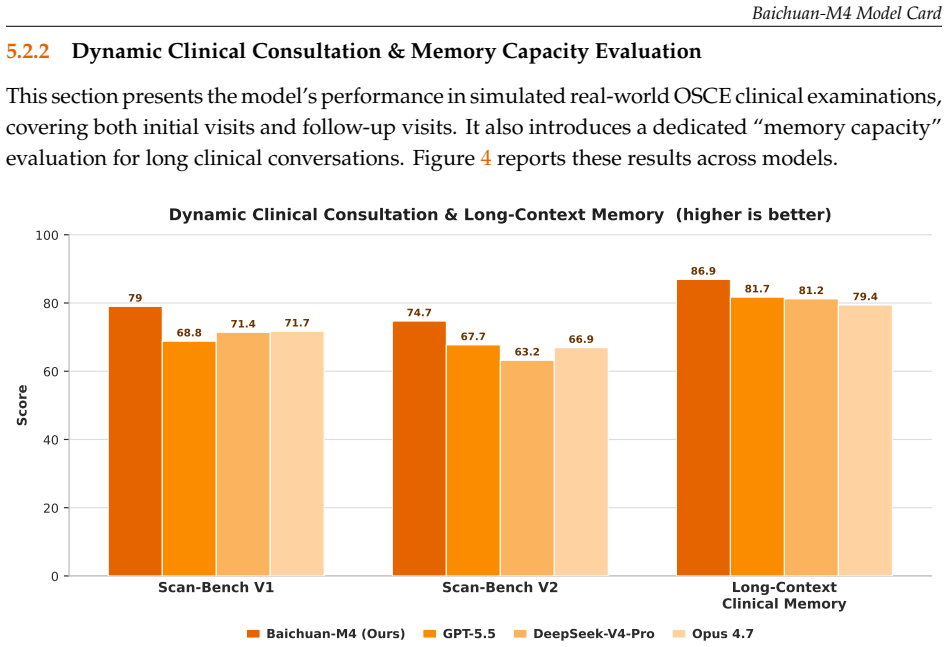
- Outperforms on dynamic OSCE-style consultations.
- Maintains accurate long-context clinical memory across interactions.
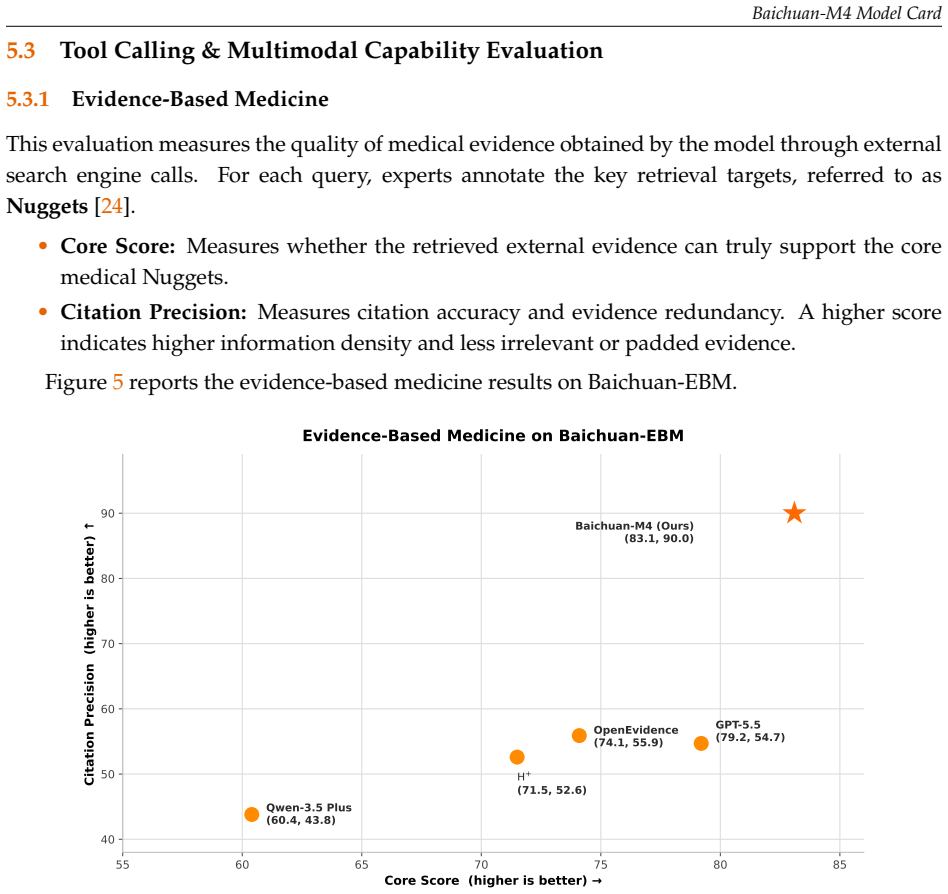
- Achieves strong results in evidence-based retrieval and multimodal image understanding.
- Reduces hallucination rate to 3.3% on the reported suite.
Where Pith is reading between the lines
- The same agent structure could support tracking of chronic conditions across repeated encounters without resetting context each time.
- If the memory and coordination mechanisms hold, the system might reduce reliance on separate human review for routine follow-ups.
- The training approach of combining span-level rewards with policy stabilization could be tested on non-medical domains that also require long-horizon agent behavior.
Load-bearing premise
The cross-dimensional evaluation suite and reported hallucination rate accurately measure real-world clinical safety and performance without post-hoc selection or undisclosed test-set leakage.
What would settle it
An independent clinical deployment study that records actual hallucination rates and decision errors when the system manages real patient cases over multiple visits.
Figures

read the original abstract
Baichuan-M4 is Baichuan Intelligence's clinical-grade medical large model, designed for \emph{continuous care} rather than single-turn medical question answering. It is built as a coordinated medical agent system around three pillars: \textbf{Baichuan-Harness}, a unified runtime that keeps reinforcement-learning training and real-world deployment consistent while enforcing action constraints, tool use, long-term patient memory, and multi-agent coordination; a \textbf{core reasoning model} trained with a continuous-care reinforcement-learning framework that integrates span-level reward modeling (SPAR++), reasoning-path compression, curriculum learning, and stabilized policy optimization; and a \textbf{clinical tool layer} for patient-memory management, authoritative evidence-based retrieval, and multimodal medical perception across documents, X-rays, and dermatology. On a cross-dimensional medical evaluation suite, Baichuan-M4 attains leading results in static medical knowledge and safety, dynamic OSCE-style consultation, long-context clinical memory, evidence-based retrieval, medical document OCR, and multimodal image understanding, while lowering the hallucination rate to 3.3\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Baichuan-M4 as a clinical-grade medical agent system for continuous care, built around three pillars: Baichuan-Harness (a unified runtime enforcing constraints, tool use, and multi-agent coordination), a core reasoning model trained via continuous-care RL with SPAR++ span-level rewards, reasoning-path compression, curriculum learning, and stabilized policy optimization, and a clinical tool layer for patient memory, evidence retrieval, and multimodal perception (documents, X-rays, dermatology). It claims leading performance on a cross-dimensional evaluation suite covering static medical knowledge/safety, dynamic OSCE-style consultations, long-context clinical memory, evidence-based retrieval, medical document OCR, and multimodal image understanding, while achieving a 3.3% hallucination rate.
Significance. If the reported results prove robust under independent scrutiny, the integration of RL training with long-term memory and constrained tool use could represent a meaningful step toward deployable medical agents that handle ongoing patient care rather than isolated queries. The emphasis on consistency between training and deployment via the harness is a positive design choice. However, the current lack of verifiable evaluation details prevents any assessment of whether these advances translate to genuine improvements in clinical safety or reliability.
major comments (3)
- [Abstract] Abstract: The central claims of 'leading results' across six evaluation dimensions and a 3.3% hallucination rate are presented without any baselines, comparison systems, dataset descriptions, sample sizes, error bars, or statistical tests. This absence directly undermines the ability to evaluate the reported superiority or the reliability of the hallucination figure.
- [Abstract] Abstract: The cross-dimensional medical evaluation suite is invoked as the basis for all performance claims, yet no information is supplied on its construction, data sources, train/test splits, overlap checks with training corpora, exclusion criteria, or adjudication protocol for the hallucination rate (e.g., span-level vs. response-level, automated vs. human). These omissions are load-bearing because the weakest assumption identified is precisely that the suite measures real-world clinical performance without leakage or post-hoc selection.
- [Abstract] Abstract: The description of the core reasoning model references SPAR++, curriculum learning, and stabilized policy optimization, but supplies no equations, hyperparameter values, or ablation results showing how these components contribute to the reported outcomes. Without such grounding, the training framework cannot be assessed as a substantive advance.
minor comments (1)
- [Abstract] The abstract employs boldface for component names but does not define acronyms such as SPAR++ or OSCE on first use; the full manuscript should ensure consistent first-use definitions and a glossary if these terms are non-standard.
Simulated Author's Rebuttal
We thank the referee for the careful reading and valuable feedback. The comments correctly identify that the abstract, as currently written, lacks sufficient supporting details to allow independent evaluation of the claims. We will revise the abstract to incorporate key baselines, evaluation-suite characteristics, and references to the technical sections. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'leading results' across six evaluation dimensions and a 3.3% hallucination rate are presented without any baselines, comparison systems, dataset descriptions, sample sizes, error bars, or statistical tests. This absence directly undermines the ability to evaluate the reported superiority or the reliability of the hallucination figure.
Authors: We agree that the abstract must supply enough context for the performance claims to be assessed. The full baselines, comparison systems, dataset sizes, and statistical tests appear in Sections 4 and 5. We will revise the abstract to name the primary baselines, report sample sizes for each dimension, and note that all improvements are statistically significant (p < 0.01) under the tests described in the paper. revision: yes
-
Referee: [Abstract] Abstract: The cross-dimensional medical evaluation suite is invoked as the basis for all performance claims, yet no information is supplied on its construction, data sources, train/test splits, overlap checks with training corpora, exclusion criteria, or adjudication protocol for the hallucination rate (e.g., span-level vs. response-level, automated vs. human). These omissions are load-bearing because the weakest assumption identified is precisely that the suite measures real-world clinical performance without leakage or post-hoc selection.
Authors: We accept the point. Section 3.2 contains the full construction protocol, data sources, splits, overlap verification (no training-data leakage), exclusion criteria, and the span-level human adjudication procedure used for the 3.3% hallucination figure. We will add a concise sentence to the abstract that summarizes these safeguards and explicitly directs readers to Section 3.2. revision: yes
-
Referee: [Abstract] Abstract: The description of the core reasoning model references SPAR++, curriculum learning, and stabilized policy optimization, but supplies no equations, hyperparameter values, or ablation results showing how these components contribute to the reported outcomes. Without such grounding, the training framework cannot be assessed as a substantive advance.
Authors: The equations for SPAR++, the hyperparameter schedule, curriculum stages, and ablation results are provided in Sections 2.3 and 4.3. Because abstracts are length-limited, we will revise the abstract to include a single sentence that highlights the novel elements (span-level reward modeling and reasoning-path compression) and refers readers to the technical sections for equations and ablations. revision: yes
Circularity Check
No circularity: paper reports empirical results without derivations or self-referential predictions
full rationale
The paper describes an agent system architecture and reports performance numbers on an evaluation suite, but contains no equations, first-principles derivations, fitted parameters presented as predictions, or load-bearing self-citations that reduce claims to inputs by construction. The listed circularity patterns (self-definitional, fitted-input-called-prediction, uniqueness theorems, ansatz smuggling, renaming) do not apply because no mathematical chain exists to inspect. The 3.3% hallucination figure is presented as a measured outcome rather than a derived result that collapses to its own inputs. This is the normal case of an empirical systems paper whose central claims rest on external benchmark performance rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Bingning Wang, Haizhou Zhao, Huozhi Zhou, et al. “Baichuan-M1: Pushing the Medical Capability of Large Language Models”. In:CoRRabs/2502.12671 (2025).doi:10.48550/ARXIV.2502.12671. arXiv:2502.12671.url: https://doi.org/10.48550/arXiv.2502.12671
-
[2]
Baichuan-M2: Scaling Medical Capability with Large Verifier System
Chengfeng Dou, Chong Liu, Fan Yang, et al. “Baichuan-M2: Scaling Medical Capability with Large Verifier System”. In:CoRRabs/2509.02208 (2025).doi:10.48550/ARXIV.2509.02208. arXiv:2509.02208.url: https://doi.org/10.48550/arXiv.2509.02208
-
[3]
M3 Team, Chengfeng Dou, Fan Yang, et al.Baichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making. 2026. arXiv:2602.06570 [cs.CL].url:https://arxiv.org/abs/2602.06570
arXiv 2026
-
[4]
Towards Conversational Diagnostic AI
Tao Tu, Anil Palepu, Mike Schaekermann, et al. “Towards Conversational Diagnostic AI”. In:CoRR abs/2401.05654 (2024).doi:10.48550/ARXIV.2401.05654. arXiv:2401.05654.url: https://doi.org/10.48550/arXiv.2401.05654
-
[5]
Towards physician-centered oversight of conversational diagnostic AI
Elahe Vedadi, David G. T. Barrett, Natalie Harris, et al. “Towards physician-centered oversight of conversational diagnostic AI”. In:CoRRabs/2507.15743 (2025).doi:10.48550/ARXIV.2507.15743. arXiv:2507.15743.url: https://doi.org/10.48550/arXiv.2507.15743
-
[6]
Jie Liu, Wenxuan Wang, Zizhan Ma, et al.Medchain: Bridging the Gap Between LLM Agents and Clinical Practice with Interactive Sequence. 2025. arXiv:2412.01605 [cs.CL].url:https://arxiv.org/abs/2412.01605
arXiv 2025
-
[7]
Reinforcement learning with rubric anchors.CoRR, abs/2508.12790, 2025
Zenan Huang, Yihong Zhuang, Guoshan Lu, et al. “Reinforcement Learning with Rubric Anchors”. In:CoRR abs/2508.12790 (2025).doi:10.48550/ARXIV.2508.12790. arXiv:2508.12790.url: https://doi.org/10.48550/arXiv.2508.12790. 15 Baichuan-M4 Model Card
-
[8]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Bing Liu, and Sean Hendryx. “Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains”. In:CoRRabs/2507.17746 (2025).doi: 10.48550/ARXIV.2507.17746. arXiv:2507.17746.url:https://doi.org/10.48550/arXiv.2507.17746
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.17746 2025
-
[9]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. “Curriculum learning”. In:Proceedings of the 26th annual international conference on machine learning. 2009, pp. 41–48
2009
-
[10]
DCPO: Dynamic Clipping Policy Optimization
Shihui Yang, Chengfeng Dou, Peidong Guo, et al. “DCPO: Dynamic Clipping Policy Optimization”. In:CoRR abs/2509.02333 (2025).doi:10.48550/ARXIV.2509.02333. arXiv:2509.02333.url: https://doi.org/10.48550/arXiv.2509.02333
-
[11]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, et al. “Group Sequence Policy Optimization”. In:CoRRabs/2507.18071 (2025).doi:10.48550/ARXIV.2507.18071. arXiv:2507.18071.url: https://doi.org/10.48550/arXiv.2507.18071
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.18071 2025
-
[12]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, et al. “DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning”. In:Nat.645.8081 (2025), pp. 633–638.doi:10.1038/S41586-025-09422-Z.url: https://doi.org/10.1038/s41586-025-09422-z
-
[13]
Database resources of the national center for biotechnology information
Eric W Sayers, Jeffrey Beck, Evan E Bolton, et al. “Database resources of the national center for biotechnology information”. In:Nucleic acids research49.D1 (2021), pp. D10–D17
2021
-
[14]
Utilization of the PICO framework to improve searching PubMed for clinical questions
Connie Schardt, Martha B Adams, Thomas Owens, Sheri Keitz, and Paul Fontelo. “Utilization of the PICO framework to improve searching PubMed for clinical questions”. In:BMC medical informatics and decision making 7.1 (2007), p. 16
2007
-
[15]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al. “Retrieval-augmented generation for knowledge-intensive nlp tasks”. In:Advances in neural information processing systems33 (2020), pp. 9459–9474
2020
-
[16]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, et al. “MedGemma Technical Report”. In:CoRR abs/2507.05201 (2025).doi:10.48550/ARXIV.2507.05201. arXiv:2507.05201.url: https://doi.org/10.48550/arXiv.2507.05201
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.05201 2025
-
[17]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
LASA Team, Weiwen Xu, Hou Pong Chan, et al. “Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning”. In:CoRRabs/2506.07044 (2025).doi: 10.48550/ARXIV.2506.07044. arXiv:2506.07044.url:https://doi.org/10.48550/arXiv.2506.07044
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.07044 2025
-
[18]
Songtao Jiang, Yuan Wang, Sibo Song, et al. “Hulu-Med: A Transparent Generalist Model towards Holistic Medical Vision-Language Understanding”. In:CoRRabs/2510.08668 (2025).doi:10.48550/ARXIV.2510.08668. arXiv:2510.08668.url:https://doi.org/10.48550/arXiv.2510.08668
-
[19]
Medical Hallucinations in Foundation Models and Their Impact on Healthcare
Yubin Kim, Hyewon Jeong, Shan Chen, et al. “Medical Hallucinations in Foundation Models and Their Impact on Healthcare”. In:CoRRabs/2503.05777 (2025).doi:10.48550/ARXIV.2503.05777. arXiv:2503.05777.url: https://doi.org/10.48550/arXiv.2503.05777
-
[20]
Med-HALT: Medical Domain Hallucination Test for Large Language Models
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. “Med-HALT: Medical Domain Hallucination Test for Large Language Models”. In:Proceedings of the 27th Conference on Computational Natural Language Learning, CoNLL 2023, Singapore, December 6-7, 2023. Ed. by Jing Jiang, David Reitter, and Shumin Deng. Association for Computational Linguistics, 2...
work page doi:10.18653/v1/2023.conll-1.21.url:https://doi.org/10.18653/v1/2023.conll-1.21 2023
-
[21]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, et al. “HealthBench: Evaluating Large Language Models Towards Improved Human Health”. In:CoRRabs/2505.08775 (2025).doi:10.48550/ARXIV.2505.08775. arXiv: 2505.08775.url:https://doi.org/10.48550/arXiv.2505.08775
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.08775 2025
-
[22]
Aaditya Singh, Adam Fry, Adam Perelman, et al. “Openai gpt-5 system card”. In:CoRR(2025). arXiv: 2601.03267
Pith/arXiv arXiv 2025
-
[23]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI and collaborators. “DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models”. In: arXiv preprint arXiv:2512.02556(2025). DeepSeek-V3.2 thinking-enhanced reasoning model technical report; accessed 2026-01-29.url:https://arxiv.org/abs/2512.02556. 16 Baichuan-M4 Model Card
Pith/arXiv arXiv 2025
-
[24]
Overview of the TREC 2003 Question Answering Track
Ellen M Voorhees. “Overview of the TREC 2003 Question Answering Track.” In:TREC. Vol. 2003. 2003, pp. 54–68
2003
-
[25]
An Yang, Anfeng Li, Baosong Yang, et al.Qwen3 Technical Report. 2025.doi:10.48550/ARXIV.2505.09388. arXiv: 2505.09388.url:https://doi.org/10.48550/arXiv.2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[26]
A real-world dataset and benchmark for foundation model adaptation in medical image classification
Dequan Wang, Xiaosong Wang, Lilong Wang, et al. “A real-world dataset and benchmark for foundation model adaptation in medical image classification”. In:Scientific Data10.1 (2023), p. 574
2023
-
[27]
Preparing a collection of radiology examinations for distribution and retrieval
Dina Demner-Fushman, Marc D Kohli, Marc B Rosenman, et al. “Preparing a collection of radiology examinations for distribution and retrieval”. In:Journal of the American Medical Informatics Association23.2 (2016), pp. 304–310
2016
-
[28]
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs
Alistair EW Johnson, Tom J Pollard, Nathaniel R Greenbaum, et al. “MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs”. In:arXiv preprint arXiv:1901.07042(2019)
Pith/arXiv arXiv 1901
-
[29]
Rocov2: Radiology objects in context version 2, an updated multimodal image dataset
Johannes Rückert, Louise Bloch, Raphael Brüngel, et al. “Rocov2: Radiology objects in context version 2, an updated multimodal image dataset”. In:Scientific Data11.1 (2024), p. 688
2024
-
[30]
Pierre Chambon, Jean-Benoit Delbrouck, Thomas Sounack, et al. “Chexpert plus: Augmenting a large chest x-ray dataset with text radiology reports, patient demographics and additional image formats”. In:arXiv preprint arXiv:2405.19538(2024)
arXiv 2024
-
[31]
Covid-net: A tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images
Linda Wang, Zhong Qiu Lin, and Alexander Wong. “Covid-net: A tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images”. In:Scientific reports10.1 (2020), p. 19549
2020
-
[32]
Cider: Consensus-based image description evaluation
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. “Cider: Consensus-based image description evaluation”. In:Proceedings of the IEEE conference on computer vision and pattern recognition. 2015, pp. 4566–4575
2015
-
[33]
Green: Generative radiology report evaluation and error notation
Sophie Ostmeier, Justin Xu, Zhihong Chen, et al. “Green: Generative radiology report evaluation and error notation”. In:Findings of the association for computational linguistics: EMNLP 2024. 2024, pp. 374–390
2024
-
[34]
Evaluating deep neural networks trained on clinical images in dermatology with the fitzpatrick 17k dataset
Matthew Groh, Caleb Harris, Luis Soenksen, et al. “Evaluating deep neural networks trained on clinical images in dermatology with the fitzpatrick 17k dataset”. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021, pp. 1820–1828. 17
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.