LEAF: A Learning-Enabled ADMM Framework for Accelerated Convex Optimization
Pith reviewed 2026-06-27 17:35 UTC · model grok-4.3
The pith
Approximating the Moreau envelope with an input convex neural network accelerates ADMM while preserving convergence rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
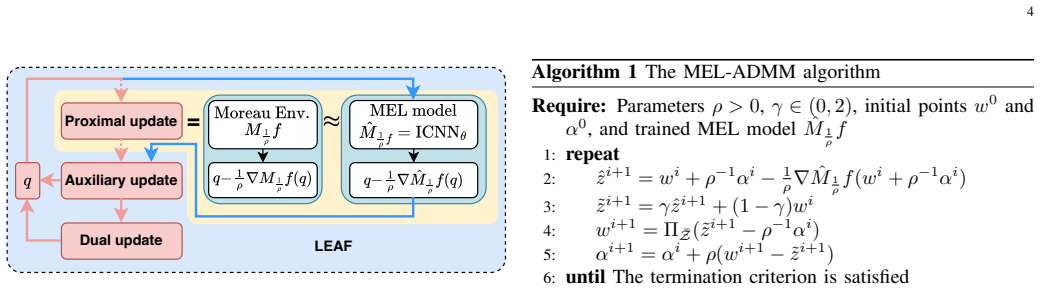
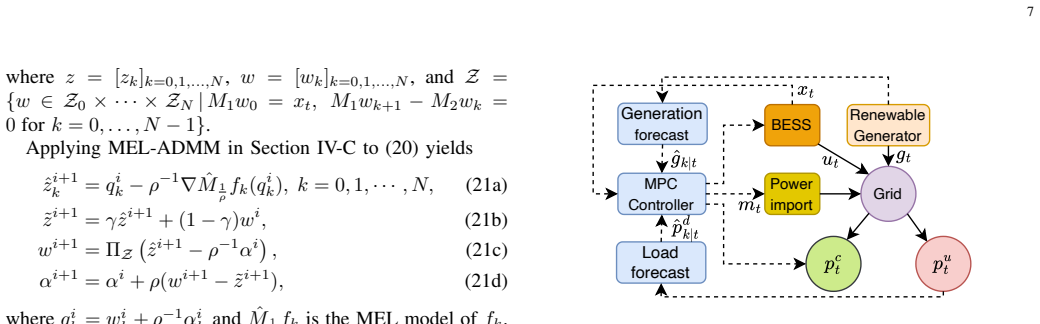
LEAF approximates the Moreau envelope of the objective with an input convex neural network, yielding a learned scalar model that preserves convexity and smoothness. Substituting this model into the ADMM iteration produces MEL-ADMM and its splitting form sMEL-ADMM, both equipped with convergence and feasibility guarantees under the learned operator. The framework applies to convex problems with smooth or nonsmooth objectives and achieves rates comparable to classical ADMM at reduced per-iteration cost.
What carries the argument
The ICNN approximation of the Moreau envelope, a scalar-valued convex function learned from data and substituted into the ADMM proximal step to lower computational cost per iteration.
If this is right
- MEL-ADMM and sMEL-ADMM achieve convergence rates comparable to classical ADMM.
- Per-iteration computational cost is lower than that of standard ADMM or direct operator-learning baselines.
- The methods remain feasible when the learned model replaces the exact Moreau envelope.
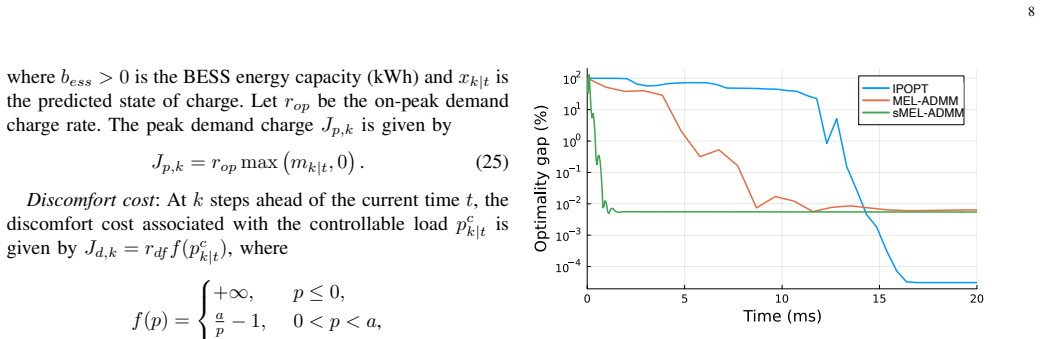
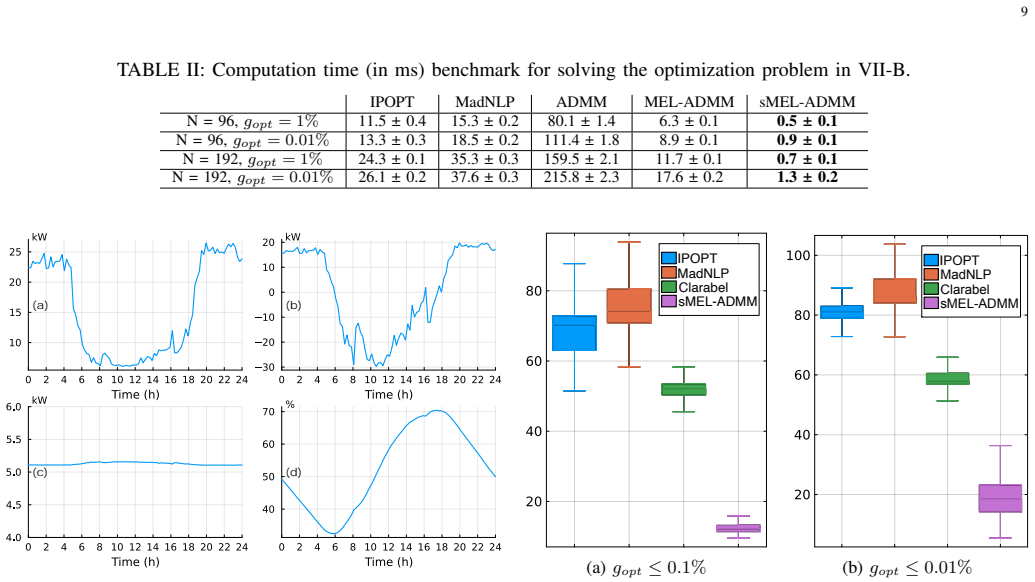
- Numerical tests show up to an order-of-magnitude reduction in runtime while keeping optimality gaps low across a range of convex problems.
Where Pith is reading between the lines
- The scalar form of the learned envelope may allow a single trained network to be reused across problem instances that share the same objective structure but differ in dimension or data.
- If the same ICNN construction can be applied to other first-order methods that rely on proximal mappings, the framework could reduce tuning effort for a broader family of splitting algorithms.
- The explicit convexity constraint inside the network architecture may make it easier to certify safety properties when the learned optimizer is deployed inside a control loop.
Load-bearing premise
The learned ICNN must approximate the true Moreau envelope accurately enough that the substituted model still satisfies the convexity and smoothness conditions required by the convergence proofs.
What would settle it
A convex test problem on which the learned model produces iterates whose optimality gap grows or whose feasibility violation exceeds a fixed tolerance, while the same problem solved with the exact Moreau envelope converges normally.
Figures
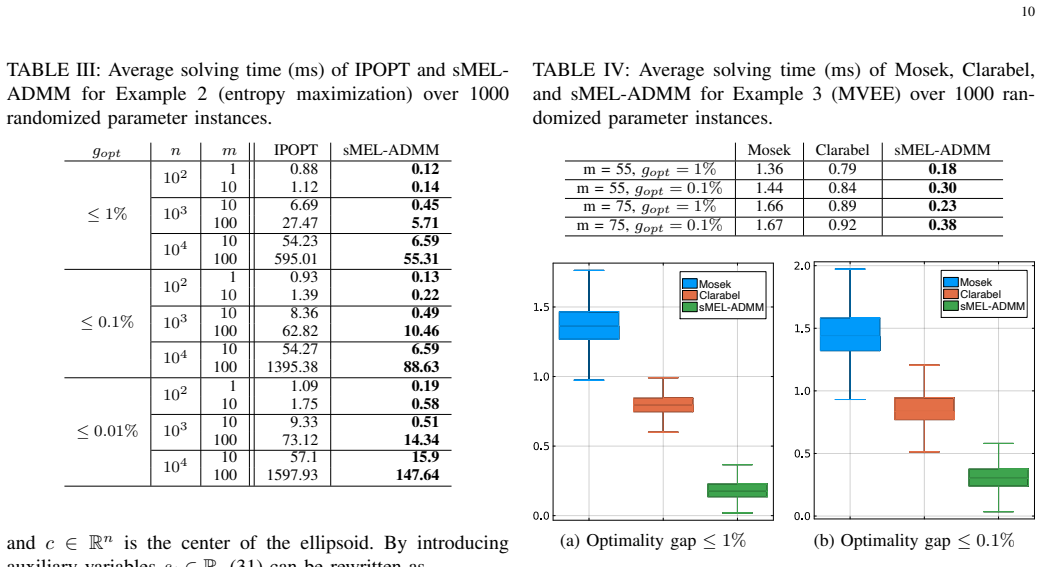
read the original abstract
We propose LEAF, a learning-enabled ADMM framework for accelerated convex optimization. The key idea is to approximate the Moreau envelope of the objective function using an Input Convex Neural Network (ICNN), resulting in a learned model that preserves convexity and smoothness. This leads to the proposed Moreau Envelope Learning ADMM (MEL-ADMM) and its splitting variant sMEL-ADMM. Unlike existing approaches that learn high-dimensional operators directly, LEAF learns a scalar-valued Moreau envelope, significantly reducing model complexity and improving data efficiency. The framework accommodates a broad class of convex problems with smooth and non-smooth objectives. By embedding convexity explicitly through the ICNN architecture, the proposed approach maintains high approximation accuracy while preserving key structural properties of the optimization problem. Both MEL-ADMM and sMEL-ADMM are developed with theoretical guarantees of convergence and feasibility under the learned model. Rigorous analysis shows that the proposed methods achieve convergence rates comparable to classical ADMM while reducing per-iteration computational cost. Numerical experiments demonstrate up to an order-of-magnitude speedup over state-of-the-art solvers while maintaining low optimality gaps
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LEAF, a learning-enabled ADMM framework that approximates the Moreau envelope of convex objectives via Input Convex Neural Networks (ICNNs) to obtain MEL-ADMM and its splitting variant sMEL-ADMM. The central claims are that the ICNN approximation preserves convexity and smoothness, that both variants admit convergence guarantees comparable to classical ADMM (including O(1/k) rates), and that numerical experiments show up to an order-of-magnitude speedup over state-of-the-art solvers while keeping low optimality gaps. The approach is positioned as more data-efficient than direct operator learning because it targets a scalar-valued envelope.
Significance. If the error-propagation analysis can be completed, the work would offer a principled route to data-driven acceleration of proximal algorithms for a broad class of convex problems, trading per-iteration cost for a learned model whose structural properties are architecturally enforced. The reduction from learning high-dimensional operators to learning a scalar Moreau envelope is a concrete complexity improvement that could be reusable beyond ADMM.
major comments (2)
- [Theoretical Analysis] Theoretical Analysis section: the convergence theorem for MEL-ADMM under the learned model asserts rates comparable to classical ADMM, yet provides no explicit tolerance on the ICNN approximation error ||f_learned - f_true|| (or on the induced proximal-operator error) that is sufficient to preserve the contraction or feasibility properties used in the proof. The argument therefore reduces to the classical case plus an unquantified perturbation claim.
- [Theoretical Analysis] § on sMEL-ADMM convergence: the splitting variant inherits the same unquantified error assumption; because the learned proximal step appears inside the ADMM iteration, an explicit propagation bound through the augmented-Lagrangian update is required to justify that the O(1/k) rate (or a controlled degradation) still holds.
minor comments (2)
- [Problem Formulation] The abstract states that the framework 'accommodates a broad class of convex problems with smooth and non-smooth objectives,' but the precise regularity assumptions (e.g., strong convexity modulus, Lipschitz constants) under which the ICNN training and convergence guarantees apply should be stated explicitly in the problem formulation section.
- [Experiments] Numerical experiments: the reported speedups are given relative to 'state-of-the-art solvers,' but the precise solver versions, stopping tolerances, and hardware configuration are not listed in the experimental protocol; adding a table of these parameters would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the theoretical analysis. The observations correctly identify that the convergence statements would be strengthened by explicit error tolerances. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical Analysis section: the convergence theorem for MEL-ADMM under the learned model asserts rates comparable to classical ADMM, yet provides no explicit tolerance on the ICNN approximation error ||f_learned - f_true|| (or on the induced proximal-operator error) that is sufficient to preserve the contraction or feasibility properties used in the proof. The argument therefore reduces to the classical case plus an unquantified perturbation claim.
Authors: We agree that an explicit tolerance on the approximation error is needed to make the perturbation argument rigorous. The current proof invokes the preserved convexity and smoothness of the ICNN but does not quantify how large the error ||f_learned - f_true|| may be while still guaranteeing the O(1/k) rate. In the revised manuscript we will insert a new lemma that derives the admissible error bound in terms of the ADMM penalty parameter and the strong-convexity modulus (when present), together with the resulting degradation in the convergence constant. revision: yes
-
Referee: [Theoretical Analysis] § on sMEL-ADMM convergence: the splitting variant inherits the same unquantified error assumption; because the learned proximal step appears inside the ADMM iteration, an explicit propagation bound through the augmented-Lagrangian update is required to justify that the O(1/k) rate (or a controlled degradation) still holds.
Authors: We concur that the error introduced by the learned proximal operator must be tracked through the augmented-Lagrangian updates for sMEL-ADMM. The revised version will contain an additional proposition that propagates the proximal error through one full ADMM iteration and shows that the same O(1/k) rate is retained provided the per-iteration error satisfies a summable bound derived from the dual step-size and the Lipschitz constant of the linear operator. revision: yes
Circularity Check
No circularity; derivation relies on external data-driven approximation and standard ADMM analysis
full rationale
The paper's core steps are (1) training an ICNN on data to approximate the Moreau envelope while enforcing convexity/smoothness via architecture, (2) substituting the learned model into ADMM iterations to obtain MEL-ADMM/sMEL-ADMM, and (3) providing convergence analysis under the learned model. None of these reduce by construction to their own inputs: the ICNN parameters are fitted from external samples rather than defined in terms of the target rates, the convergence claims are stated as holding for the approximate operator (with the approximation error treated as an external perturbation), and no self-citation chain or uniqueness theorem is invoked to force the result. The framework therefore remains self-contained against external benchmarks and data.
Axiom & Free-Parameter Ledger
free parameters (1)
- ICNN weights
axioms (1)
- domain assumption Input convex neural networks preserve convexity when used to model the Moreau envelope
Reference graph
Works this paper leans on
-
[1]
Learning to optimize: A primer and a benchmark,
T. Chen, X. Chen, W. Chen, H. Heaton, J. Liu, Z. Wang, and W. Yin, “Learning to optimize: A primer and a benchmark,”Journal of Machine Learning Research, vol. 23, no. 189, pp. 1–59, 2022. 11
2022
-
[2]
Learning to optimize in model predictive control,
J. Sacks and B. Boots, “Learning to optimize in model predictive control,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 10 549–10 556
2022
-
[3]
Admm-based algorithm for training fault tolerant rbf networks and selecting centers,
H. Wang, R. Feng, Z.-F. Han, and C.-S. Leung, “Admm-based algorithm for training fault tolerant rbf networks and selecting centers,”IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 8, pp. 3870–3878, 2017
2017
-
[4]
Collision-free minimum-time trajectory planning for mul- tiple vehicles based on admm,
T. B. Nguyen, T. Nguyen, T. Nghiem, L. Nguyen, J. Baca, P. Rangel, and H.-K. Song, “Collision-free minimum-time trajectory planning for mul- tiple vehicles based on admm,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, pp. 13 785–13 790
2022
-
[5]
Communication- efficient ADMM using Gaussian process regression and fully adaptive uniform quantization,
A. Duarte, B. Nguyen, T. X. Nghiem, and S. Wei, “Communication- efficient ADMM using Gaussian process regression and fully adaptive uniform quantization,”Franklin Open, vol. 15, p. 100587, 2026
2026
-
[6]
Des-inspired accelerated unfolded linearized admm networks for inverse problems,
W. An, Y . Liu, F. Shang, H. Liu, and L. Jiao, “Des-inspired accelerated unfolded linearized admm networks for inverse problems,”IEEE Trans- actions on Neural Networks and Learning Systems, vol. 36, no. 3, pp. 5319–5333, 2025
2025
-
[7]
ADMM Enhancement Techniques for Distributed Optimal Power Flow,
M. Hasanzadeh and A. Kargarian, “ADMM Enhancement Techniques for Distributed Optimal Power Flow,”IEEE Transactions on Power Systems, vol. 41, no. 2, pp. 1321–1333, Mar. 2026
2026
-
[8]
Qc-odkla: Quantized and communication- censored online decentralized kernel learning via lin- earized admm,
P. Xu, Y . Wang, X. Chen, and Z. Tian, “Qc-odkla: Quantized and communication- censored online decentralized kernel learning via lin- earized admm,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 12, pp. 17 987–17 999, 2024
2024
-
[9]
StructADMM: Achieving ultrahigh efficiency in structured pruning for DNNs,
T. Zhang, S. Ye, X. Feng, X. Ma, K. Zhang, Z. Li, J. Tang, S. Liu, X. Lin, Y . Liu, M. Fardad, and Y . Wang, “StructADMM: Achieving ultrahigh efficiency in structured pruning for DNNs,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 5, pp. 2259– 2273, 2022
2022
-
[10]
Connectivity-preserving distributed informative path planning for mo- bile robot networks,
B. Nguyen, T. X. Nghiem, L. Nguyen, H. M. La, and T. Nguyen, “Connectivity-preserving distributed informative path planning for mo- bile robot networks,”IEEE Robotics and Automation Letters, vol. 9, no. 3, pp. 2949–2956, 2024
2024
-
[11]
Machine learning for combinato- rial optimization: a methodological tour d’horizon,
Y . Bengio, A. Lodi, and A. Prouvost, “Machine learning for combinato- rial optimization: a methodological tour d’horizon,”European Journal of Operational Research, vol. 290, no. 2, pp. 405–421, 2021
2021
-
[12]
Koziel and L
S. Koziel and L. Leifsson,Surrogate-based modeling and optimization, 1st ed. Springer New York, NY , 2013
2013
-
[13]
Learning optimal solutions for extremely fast ac optimal power flow,
A. S. Zamzam and K. Baker, “Learning optimal solutions for extremely fast ac optimal power flow,” in2020 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids, Nov. 2020, pp. 1–6
2020
-
[14]
Constrained neural networks for approximate nonlinear model predictive control,
S. Adhau, V . V . Naik, and S. Skogestad, “Constrained neural networks for approximate nonlinear model predictive control,” in2021 60th IEEE Conference on Decision and Control (CDC), 2021, pp. 295–300
2021
-
[15]
KKT-based optimality con- ditions for neural network approximation,
V . Peiris, N. Sukhorukova, and J. Ugon, “KKT-based optimality con- ditions for neural network approximation,”arXiv preprint 2506.17305, 2025
-
[16]
DC3: A learning method for optimization with hard constraints,
P. L. Donti, D. Rolnick, and J. Z. Kolter, “DC3: A learning method for optimization with hard constraints,” inInternational Conference on Learning Representations, 2021
2021
-
[17]
FSNet: Feasibility-seeking neural network for constrained optimization with guarantees,
H. T. Nguyen and P. L. Donti, “FSNet: Feasibility-seeking neural network for constrained optimization with guarantees,” inAnnual Con- ference on Neural Information Processing Systems, 2026
2026
-
[18]
Learning warm-start points for AC Optimal Power Flow,
K. Baker, “Learning warm-start points for AC Optimal Power Flow,” in2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP), Oct. 2019, pp. 1–6
2019
-
[19]
Learning to warm- start fixed-point optimization algorithms,
R. Sambharya, G. Hall, B. Amos, and B. Stellato, “Learning to warm- start fixed-point optimization algorithms,”Journal of Machine Learning Research, vol. 25, no. 166, pp. 1–46, 2024
2024
-
[20]
Learning for constrained optimization: Identifying optimal active constraint sets,
S. Misra, L. Roald, and Y . Ng, “Learning for constrained optimization: Identifying optimal active constraint sets,”INFORMS Journal on Com- puting, vol. 34, no. 1, pp. 463–480, 2022
2022
-
[21]
One network to solve them all — solving linear inverse problems using deep projection models,
J. R. Chang, C.-L. Li, B. P ´oczos, B. Vijaya Kumar, and A. C. Sankara- narayanan, “One network to solve them all — solving linear inverse problems using deep projection models,” in2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 5889–5898
2017
-
[22]
Learning proximal operators: Using denoising networks for regularizing inverse imaging problems,
T. Meinhardt, M. Moller, C. Hazirbas, and D. Cremers, “Learning proximal operators: Using denoising networks for regularizing inverse imaging problems,” inProceedings of the IEEE International Confer- ence on Computer Vision, 2017, pp. 1781–1790
2017
-
[23]
Deep ADMM-Net for compressive sensing MRI,
J. Sun, H. Li, Z. Xuet al., “Deep ADMM-Net for compressive sensing MRI,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[24]
ADMM-CSNet: A deep learning approach for image compressive sensing,
Y . Yang, J. Sun, H. Li, and Z. Xu, “ADMM-CSNet: A deep learning approach for image compressive sensing,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 3, pp. 521–538, 2020
2020
-
[25]
Learning to learn by gradient descent by gradient descent,
M. Andrychowicz, M. Denil, S. Gomez, M. W. Hoffman, D. Pfau, T. Schaul, B. Shillingford, and N. De Freitas, “Learning to learn by gradient descent by gradient descent,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[26]
Learning to learn without gradient descent by gradient descent,
Y . Chen, M. W. Hoffman, S. G. Colmenarejo, M. Denil, T. P. Lillicrap, M. Botvinick, and N. Freitas, “Learning to learn without gradient descent by gradient descent,” inInternational Conference on Machine Learning. PMLR, 2017, pp. 748–756
2017
-
[27]
Self-supervised primal-dual learning for constrained optimization,
S. Park and P. Van Hentenryck, “Self-supervised primal-dual learning for constrained optimization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 4, 2023, pp. 4052–4060
2023
-
[28]
Y . Min and N. Azizan, “Hardnet: Hard-constrained neural networks with universal approximation guarantees,”arXiv preprint 2410.10807, 2024
-
[29]
R. T. Rockafellar,Convex analysis. Princeton University Press, 1997
1997
-
[30]
Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers,
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers,”Foundations and Trends in Machine Learning, vol. 3, no. 1, pp. 1–122, Jul. 2011
2011
-
[31]
A general analysis of the convergence of ADMM,
R. Nishihara, L. Lessard, B. Recht, A. Packard, and M. Jordan, “A general analysis of the convergence of ADMM,” inProceedings of the 32nd International Conference on Machine Learning, vol. 37. PMLR, 2015, pp. 343–352
2015
-
[32]
Operator-splitting methods for monotone affine variational inequalities, with a parallel application to optimal control,
J. Eckstein and M. C. Ferris, “Operator-splitting methods for monotone affine variational inequalities, with a parallel application to optimal control,”INFORMS Journal on Computing, vol. 10, no. 2, pp. 218–235, 1998
1998
-
[33]
H. H. Bauschke and P. L. Combettes,Convex analysis and monotone operator theory in Hilbert spaces, 2nd ed. Springer Cham, 2020
2020
-
[34]
D. P. Bertsekas,Convex Optimization Algorithms. Athena Scientific, 2015
2015
-
[35]
Learning proximal operators with gaussian processes,
T. X. Nghiem, G. Stathopoulos, and C. N. Jones, “Learning proximal operators with gaussian processes,” in2018 56th Annual Allerton Con- ference on Communication, Control, and Computing (Allerton). IEEE, 2018, pp. 935–942
2018
-
[36]
Input convex neural networks,
B. Amos, L. Xu, and J. Z. Kolter, “Input convex neural networks,” in International conference on machine learning, 2017, pp. 146–155
2017
-
[37]
Strongly Convex Functions, Moreau En- velopes, and the Generic Nature of Convex Functions with Strong Minimizers,
C. Planiden and X. Wang, “Strongly Convex Functions, Moreau En- velopes, and the Generic Nature of Convex Functions with Strong Minimizers,”SIAM Journal on Optimization, vol. 26, no. 2, pp. 1341– 1364, Jan. 2016
2016
-
[38]
Osqp: An operator splitting solver for quadratic programs,
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd, “Osqp: An operator splitting solver for quadratic programs,” in2018 UKACC 12th International Conference on Control (CONTROL), 2018, pp. 339–339
2018
-
[39]
Lipschitz regularity of deep neural net- works: analysis and efficient estimation,
A. Virmaux and K. Scaman, “Lipschitz regularity of deep neural net- works: analysis and efficient estimation,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[40]
Efficient and accurate estimation of lipschitz constants for deep neural networks,
M. Fazlyab, A. Robey, H. Hassani, M. Morari, and G. Pappas, “Efficient and accurate estimation of lipschitz constants for deep neural networks,” Advances in neural information processing systems, vol. 32, 2019
2019
-
[41]
Model predictive control: Recent developments and future promise,
D. Q. Mayne, “Model predictive control: Recent developments and future promise,”Automatica, vol. 50, no. 12, pp. 2967–2986, 2014
2014
-
[42]
On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear programming,
A. W ¨achter and L. T. Biegler, “On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear programming,” Mathematical programming, vol. 106, no. 1, pp. 25–57, 2006
2006
-
[43]
GPU-accelerated dynamic nonlinear optimiza- tion with ExaModels and MadNLP,
F. Pacaud and S. Shin, “GPU-accelerated dynamic nonlinear optimiza- tion with ExaModels and MadNLP,” in2024 IEEE 63rd Conference on Decision and Control (CDC). IEEE, 2024, pp. 5963–5968
2024
-
[44]
The MOSEK interior point opti- mizer for linear programming: an implementation of the homogeneous algorithm,
E. D. Andersen and K. D. Andersen, “The MOSEK interior point opti- mizer for linear programming: an implementation of the homogeneous algorithm,” inHigh performance optimization. Springer, 2000, pp. 197–232
2000
-
[45]
Clarabel: An interior-point solver for conic programs with quadratic objectives,
P. J. Goulart and Y . Chen, “Clarabel: An interior-point solver for conic programs with quadratic objectives,”arXiv preprint 2405.12762, 2024
-
[46]
Economic model predictive control for time-varying cost and peak demand charge optimization,
M. J. Risbeck and J. B. Rawlings, “Economic model predictive control for time-varying cost and peak demand charge optimization,”IEEE Transactions on Automatic Control, vol. 65, no. 7, pp. 2957–2968, 2020
2020
-
[47]
Economic MPC with an Online Reference Trajectory for Battery Scheduling Considering Demand Charge Management,
C. Cortes-Aguirre, Y .-A. Chen, A. Ghosh, J. Kleissl, and A. Khurram, “Economic MPC with an Online Reference Trajectory for Battery Scheduling Considering Demand Charge Management,”IEEE Trans- actions on Smart Grid, pp. 1–1, 2025
2025
-
[48]
Boyd and L
S. Boyd and L. Vandenberghe,Convex Optimization. Cambridge University Press, 2004
2004
-
[49]
Computing minimum-volume enclosing ellipsoids,
N. Bowman and M. T. Heath, “Computing minimum-volume enclosing ellipsoids,”Mathematical Programming Computation, vol. 15, no. 4, pp. 621–650, 2023
2023
-
[50]
R. T. Rockafellar and R. J. Wets,Variational analysis, 1st ed. Springer Berlin, Heidelberg, 1997. 12
1997
-
[51]
Borwein and A
J. Borwein and A. Lewis,Convex Analysis and Nonlinear Optimization: Theoryand Examples, 2nd ed. Springer New York, NY , 2005. APPENDIXA PROOF OFLEMMA2 We will show that∇ 2 xh(x)is uniformly bounded. We first derive the expressions for∇ xh(x)and∇ 2 xh(x). LetD j = diag ϕ′ j(yj) andE j = diag ϕ′′ j (yj) . The JacobianJ j = ∂vj ∂x is given by the chain rule ...
2005
-
[52]
Based on Lemma 6, the ME is a special case of infimal convolution with the functionq λ(x) = 1 2λ ∥x∥2
Therefore,f∈Γ 0(Rn). Based on Lemma 6, the ME is a special case of infimal convolution with the functionq λ(x) = 1 2λ ∥x∥2
-
[53]
Hence,M λf=g
Sinceq ⋆ λ(y) = λ 2 ∥y∥2 2, we have (Mλf) ⋆ =f ⋆ +q ⋆ λ =f ⋆ + λ 2 ∥.∥2 2 =g ⋆. Hence,M λf=g. Uniqueness:Assume there exists another ˆf∈Γ 0(Rn)such thatM λ ˆf=g. Using the same conjugate identity, g⋆ = (Mλ ˆf) ⋆ = ˆf ⋆ + λ 2 ∥.∥2 2. Thus ˆf ⋆ =g ⋆−λ 2 ∥.∥2 2 =f ⋆. By Lemma 4, ˆf= ˆf ⋆⋆ =f ⋆⋆ =f
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.