Decoding Pedestrian Crossing Intention from Egocentric Vision via Vision Language Models
Pith reviewed 2026-06-27 17:11 UTC · model grok-4.3
The pith
Vision language models fine-tuned on egocentric video decode pedestrian crossing intent with 14.5 percent higher accuracy than transformer baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
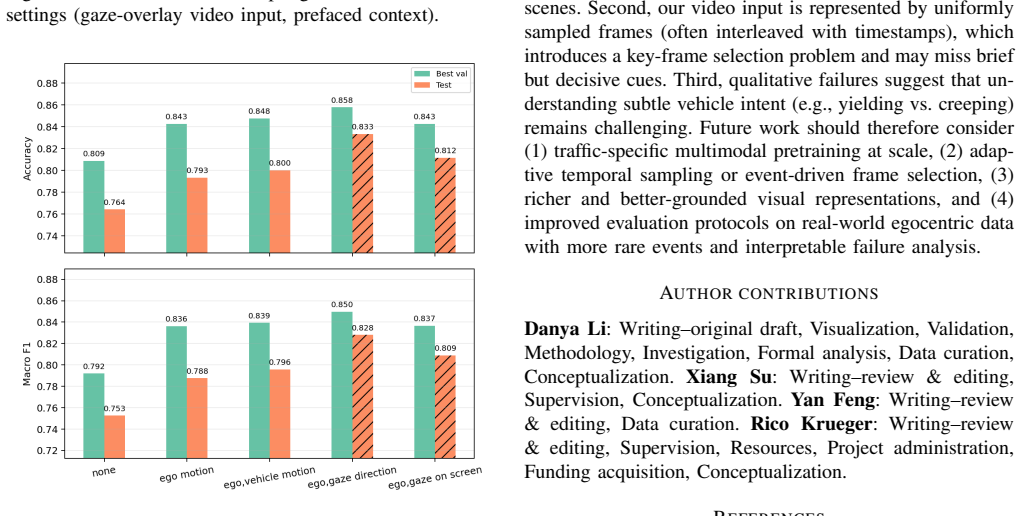
The authors establish that fine-tuned vision language models, in particular the Qwen3-VL-2B model supplied with eye gaze and ego-motion signals, achieve a 14.5 percent accuracy improvement over a transformer baseline on egocentric pedestrian intent prediction and thereby set a new state of the art for the task.
What carries the argument
Closed-ended visual question answering formulation of pedestrian intent combined with parameter-efficient fine-tuning of vision language models and the injection of contextual signals such as eye gaze and ego motion.
If this is right
- Zero-shot vision language models already exceed random guessing but fall short on higher-level traffic reasoning.
- Parameter-efficient fine-tuning delivers substantial accuracy lifts over both zero-shot and transformer baselines.
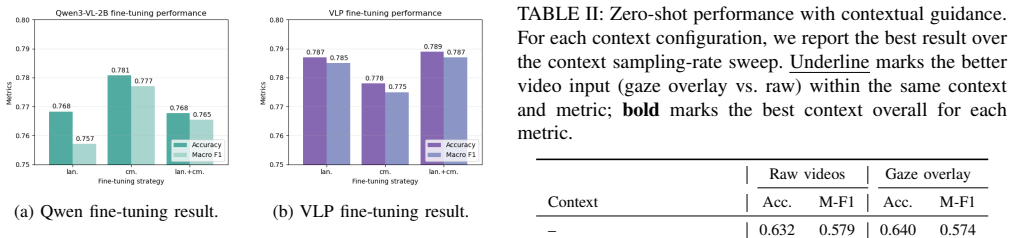
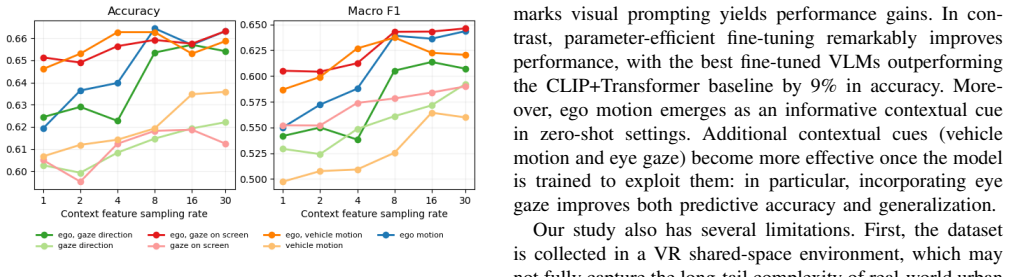
- Incorporating eye gaze, ego motion, and vehicle motion produces additional measurable gains on the intent prediction task.
- The best reported configuration establishes a new benchmark for egocentric pedestrian crossing intention decoding.
Where Pith is reading between the lines
- The same fine-tuning recipe could be tested on other first-person prediction problems such as driver intent or cyclist behavior.
- If the models truly learn intent rather than dataset patterns, they should retain accuracy when camera height, lighting, or cultural crossing norms change.
- Integration into real-time vehicle systems would require checking whether the added latency of the vision language model remains acceptable.
Load-bearing premise
The reported accuracy gains reflect genuine improvement in capturing pedestrian intent rather than dataset-specific fitting or artifacts of how the question is worded.
What would settle it
Running the same fine-tuned Qwen3-VL-2B model on an independent egocentric video dataset collected under different traffic conditions and finding that the 14.5 percent margin over the transformer baseline vanishes or reverses.
Figures



read the original abstract
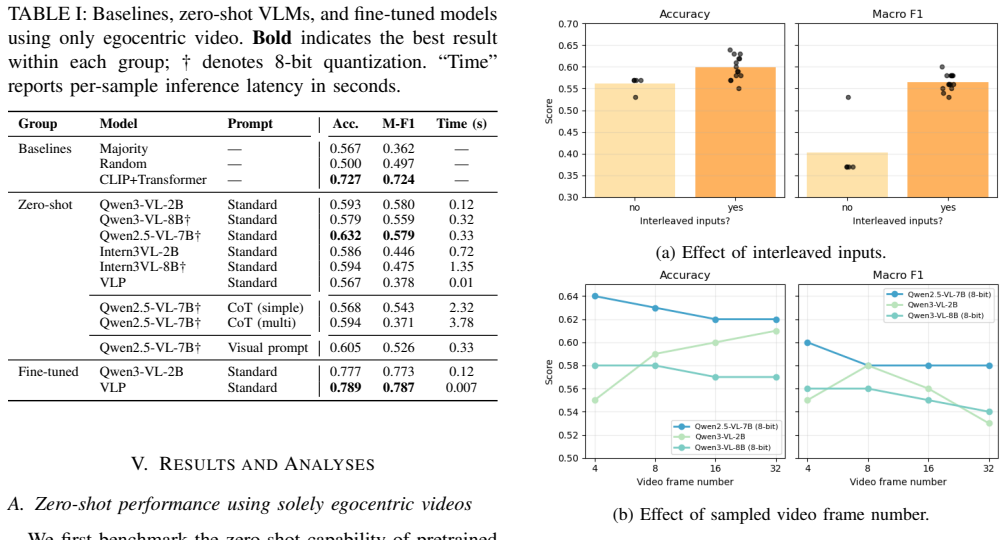
Egocentric vision offers a first-person view of human perception and decision making, yet its potential for traffic-safety prediction remains underexplored. In this work, we study the decoding of pedestrian crossing intentions from short egocentric video clips. We approach this by formulating the task as a closed-ended visual question answering (VQA) problem and leveraging vision language models (VLMs) to predict the pedestrians' intent. We first benchmark three families of state-of-the-art VLMs in a zero-shot setting, finding that they achieve moderate gains over random guessing but exhibit limited higher-level traffic reasoning. Motivated by these findings, we further adapt VLMs to the target task using parameter-efficient fine-tuning. Our results show that the fine-tuned models substantially outperform their zero-shot counterparts and achieve a 9\% accuracy improvement over a specialized transformer-based baseline. Finally, we demonstrate that incorporating additional contextual cues, including ego motion, vehicle motion, and eye gaze, further improves predictive performance. In particular, the fine-tuned Qwen3-VL-2B model guided by eye gaze and ego motion achieves a 14.5% accuracy improvement over the transformer baseline, establishing a new state of the art for egocentric pedestrian intent decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pedestrian crossing intention decoding from short egocentric video clips can be effectively addressed by reformulating the task as closed-ended visual question answering and leveraging vision-language models. Zero-shot VLMs achieve moderate gains over random guessing but show limited traffic reasoning; parameter-efficient fine-tuning yields a 9% accuracy improvement over a specialized transformer baseline; and adding contextual cues (ego motion, vehicle motion, eye gaze) further boosts performance, with the fine-tuned Qwen3-VL-2B model guided by eye gaze and ego motion delivering a 14.5% accuracy gain over the baseline and establishing a new state of the art.
Significance. If the reported gains are robustly validated, the work would be significant for showing how VLMs can be adapted via parameter-efficient fine-tuning and contextual cues for egocentric traffic-safety prediction, a domain where such models have been underexplored. The empirical benchmarking across VLM families and the demonstration that eye gaze and ego motion provide additive value are concrete contributions that could inform future multimodal intent-prediction systems.
major comments (1)
- [Abstract] Abstract: the central SOTA claim rests on stated accuracy improvements of 9% and 14.5% over the transformer baseline, yet the abstract (and by extension the results section) supplies no information on dataset size, number of test instances, statistical significance tests, error bars, or controls for data leakage; these omissions are load-bearing because they prevent assessment of whether the gains reflect genuine modeling advances rather than dataset-specific artifacts.
minor comments (2)
- [Methods] The exact wording of the closed-ended VQA questions and the precise integration mechanism for eye-gaze and ego-motion cues into the VLM input should be stated explicitly (likely in §3 or §4) to allow reproduction and to rule out prompt-engineering artifacts.
- [Experiments] Figure and table captions would benefit from including the exact evaluation metric (top-1 accuracy?) and the number of runs or seeds used for the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. We address the single major comment below regarding missing statistical and dataset details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central SOTA claim rests on stated accuracy improvements of 9% and 14.5% over the transformer baseline, yet the abstract (and by extension the results section) supplies no information on dataset size, number of test instances, statistical significance tests, error bars, or controls for data leakage; these omissions are load-bearing because they prevent assessment of whether the gains reflect genuine modeling advances rather than dataset-specific artifacts.
Authors: We agree that the abstract and results section should explicitly report dataset size, number of test instances, error bars, statistical significance, and data-leakage controls to allow proper evaluation of the claimed gains. In the revised version we will (1) add the dataset size and test-set cardinality to the abstract, (2) include error bars and the results of significance tests in the results section and tables, and (3) expand the experimental-setup subsection to detail the train/test split procedure and any leakage-prevention measures. These changes directly address the concern without altering the core claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical machine-learning study: zero-shot benchmarking of VLMs on an egocentric VQA task for pedestrian intent, followed by parameter-efficient fine-tuning and ablation of auxiliary inputs (eye gaze, ego motion). All reported gains are measured against an external transformer baseline on held-out data. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described methodology. The central claim (accuracy lift from fine-tuning plus context) is therefore an experimental outcome, not a quantity forced by construction from the inputs themselves.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pedestrian Behavior Prediction Using Deep Learning Methods for Urban Scenarios: A Review,
C. Zhang and C. Berger, “Pedestrian Behavior Prediction Using Deep Learning Methods for Urban Scenarios: A Review,”IEEE Transactions on Intelligent Transportation Systems, pp. 1–23, 2023
2023
-
[2]
Predicting Pedestrian Crossing Intention in Autonomous Vehicles: A Review,
F.-G. Landry and M. A. Akhloufi, “Predicting Pedestrian Crossing Intention in Autonomous Vehicles: A Review,”Neurocomputing, vol. 618, p. 129105, Feb. 2025
2025
-
[3]
EgoNav: Egocentric Scene- aware Human Trajectory Prediction,
W. Wang, C. K. Liu, and M. Kennedy, “EgoNav: Egocentric Scene- aware Human Trajectory Prediction,” Aug. 2024, arXiv:2403.19026 [cs]
-
[4]
Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision,
Y . He, Y . Huang, G. Chen, L. Lu, B. Pei, J. Xu, T. Lu, and Y . Sato, “Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision,”International Journal of Computer Vision, vol. 134, no. 2, p. 62, Jan. 2026
2026
-
[5]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liuet al., “Ego4d: Around the world in 3,000 hours of egocentric video,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18 995–19 012
2022
-
[6]
An outlook into the future of egocentric vision,
C. Plizzari, G. Goletto, A. Furnari, S. Bansal, F. Ragusa, G. M. Farinella, D. Damen, and T. Tommasi, “An outlook into the future of egocentric vision,”International Journal of Computer Vision, vol. 132, no. 11, pp. 4880–4936, 2024
2024
-
[7]
Egolife: Towards egocentric life assistant,
J. Yang, S. Liu, H. Guo, Y . Dong, X. Zhang, S. Zhang, P. Wang, Z. Zhou, B. Xie, Z. Wanget al., “Egolife: Towards egocentric life assistant,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 28 885–28 900
2025
-
[8]
EgoCogNav: Cognition-aware Human Egocentric Navigation
Z. Qiu, Z. Liu, W. Niu, T. Bhattacharjee, and S. Kalantari, “EgoCog- Nav: Cognition-aware Human Egocentric Navigation,” Nov. 2025, arXiv:2511.17581 [cs]. 8
work page internal anchor Pith review arXiv 2025
-
[9]
Lookout: Real-world humanoid egocentric navigation,
B. Pan, A. W. Harley, F. Engelmann, C. K. Liu, and L. J. Guibas, “Lookout: Real-world humanoid egocentric navigation,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 24 977–24 988
2025
-
[10]
Heads-up: Head- mounted egocentric dataset for trajectory prediction in blind assistance systems,
Y . Haghighi, C. Demonsant, P. Chalimourdas, M. T. Naeini, J. K. Munoz, B. Bacca, S. Suter, M. Gani, and A. Alahi, “Heads-up: Head- mounted egocentric dataset for trajectory prediction in blind assistance systems,”arXiv preprint arXiv:2409.20324, 2024
-
[11]
Egocentric human trajectory forecasting with a wearable camera and multi-modal fusion,
J. Qiu, L. Chen, X. Gu, F. P.-W. Lo, Y .-Y . Tsai, J. Sun, J. Liu, and B. Lo, “Egocentric human trajectory forecasting with a wearable camera and multi-modal fusion,”IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 8799–8806, 2022
2022
-
[12]
KrishnaCam: Using a longitudinal, single-person, egocentric dataset for scene understanding tasks,
K. K. Singh, K. Fatahalian, and A. A. Efros, “KrishnaCam: Using a longitudinal, single-person, egocentric dataset for scene understanding tasks,” in2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Mar. 2016, pp. 1–9
2016
-
[13]
Egocentric future localization,
H. S. Park, J.-J. Hwang, Y . Niu, and J. Shi, “Egocentric future localization,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4697–4705
2016
-
[14]
Pedestrian intention prediction for autonomous vehicles: A comprehensive survey,
N. Sharma, C. Dhiman, and S. Indu, “Pedestrian intention prediction for autonomous vehicles: A comprehensive survey,”Neurocomputing, vol. 508, pp. 120–152, 2022
2022
-
[15]
GPT-4V Takes the Wheel: Promises and Challenges for Pedestrian Behavior Prediction,
J. Huang, P. Jiang, A. Gautam, and S. Saripalli, “GPT-4V Takes the Wheel: Promises and Challenges for Pedestrian Behavior Prediction,” Proceedings of the AAAI Symposium Series, vol. 3, no. 1, pp. 134–142, May 2024
2024
-
[16]
OmniPredict: GPT-4o Enhanced Multi-modal Pedestrian Crossing Intention Prediction,
J.-S. Ham, J. Huang, P. Jiang, J. Moon, Y . Kwon, S. Saripalli, and C. Kim, “OmniPredict: GPT-4o Enhanced Multi-modal Pedestrian Crossing Intention Prediction,” Nov. 2024
2024
-
[17]
Seeing beyond frames: Zero-shot pedestrian intention prediction with raw temporal video and multimodal cues,
P. Zambare, V . N. Thanikella, and Y . Liu, “Seeing beyond frames: Zero-shot pedestrian intention prediction with raw temporal video and multimodal cues,” in2025 3rd International Conference on Artificial Intelligence, Blockchain, and Internet of Things (AIBThings). IEEE, 2025, pp. 1–5
2025
-
[18]
Pedestrian Intention Prediction via Vision-Language Foundation Models,
M. Azarmi, M. Rezaei, and H. Wang, “Pedestrian Intention Prediction via Vision-Language Foundation Models,” Jul. 2025
2025
-
[19]
Optimizing Vision-Language Model for Road Crossing Intention Estimation,
R. Uziel and O. Bialer, “Optimizing Vision-Language Model for Road Crossing Intention Estimation,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Feb. 2025, pp. 1702– 1712
2025
-
[20]
Pedestrian Vision Language Model for Intentions Prediction,
F. Munir, S. Azam, T. Mihaylova, V . Kyrki, and T. P. Kucner, “Pedestrian Vision Language Model for Intentions Prediction,”IEEE Open Journal of Intelligent Transportation Systems, vol. 6, pp. 393– 406, 2025
2025
-
[21]
H. Gao, L. Zhang, Y . Zhao, Z. Yang, and J. Cao, “Application of Vision-Language Model to Pedestrians Behavior and Scene Under- standing in Autonomous Driving,” Jul. 2025, arXiv:2501.06680 [cs]
-
[22]
Vlmped-cot: A large vision-language model with chain-of-thought mechanism for pedestrian crossing intention prediction,
Y . Ling, Z. Qin, L. Wang, Z. Liu, Y . Liu, and Z. Ma, “Vlmped-cot: A large vision-language model with chain-of-thought mechanism for pedestrian crossing intention prediction,”Communications in Trans- portation Research, 2026
2026
-
[23]
Scaling Egocentric Vision: The EPIC-KITCHENS Dataset
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray, “Scaling Egocentric Vision: The EPIC-KITCHENS Dataset,” Jul. 2018, arXiv:1804.02748 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Actor and observer: Joint modeling of first and third-person videos,
G. A. Sigurdsson, A. Gupta, C. Schmid, A. Farhadi, and K. Alahari, “Actor and observer: Joint modeling of first and third-person videos,” inproceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7396–7404
2018
-
[25]
Egovlpv2: Egocentric video-language pre-training with fusion in the backbone,
S. Pramanick, Y . Song, S. Nag, K. Q. Lin, H. Shah, M. Z. Shou, R. Chellappa, and P. Zhang, “Egovlpv2: Egocentric video-language pre-training with fusion in the backbone,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 5285–5297
2023
-
[26]
Egovideo: Exploring egocentric foundation model and downstream adaptation,
B. Pei, G. Chen, J. Xu, Y . He, Y . Liu, K. Pan, Y . Huang, Y . Wang, T. Lu, L. Wanget al., “Egovideo: Exploring egocentric foundation model and downstream adaptation,”arXiv preprint arXiv:2406.18070, 2024
-
[27]
Video question answering: Datasets, algorithms and challenges,
Y . Zhong, W. Ji, J. Xiao, Y . Li, W. Deng, and T.-S. Chua, “Video question answering: Datasets, algorithms and challenges,” inProceed- ings of the 2022 conference on empirical methods in natural language processing, 2022, pp. 6439–6455
2022
-
[28]
Video question answering via gradually refined attention over ap- pearance and motion,
D. Xu, Z. Zhao, J. Xiao, F. Wu, H. Zhang, X. He, and Y . Zhuang, “Video question answering via gradually refined attention over ap- pearance and motion,” inProceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1645–1653
2017
-
[29]
Tgif-qa: Toward spatio- temporal reasoning in visual question answering,
Y . Jang, Y . Song, Y . Yu, Y . Kim, and G. Kim, “Tgif-qa: Toward spatio- temporal reasoning in visual question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2758–2766
2017
-
[30]
Activitynet-qa: A dataset for understanding complex web videos via question answering,
Z. Yu, D. Xu, J. Yu, T. Yu, Z. Zhao, Y . Zhuang, and D. Tao, “Activitynet-qa: A dataset for understanding complex web videos via question answering,” inProceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 9127–9134
2019
-
[31]
Next-qa: Next phase of question-answering to explaining temporal actions,
J. Xiao, X. Shang, A. Yao, and T.-S. Chua, “Next-qa: Next phase of question-answering to explaining temporal actions,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 9777–9786
2021
-
[32]
Agqa: A benchmark for compositional spatio-temporal reasoning,
M. Grunde-McLaughlin, R. Krishna, and M. Agrawala, “Agqa: A benchmark for compositional spatio-temporal reasoning,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11 287–11 297
2021
-
[33]
From representation to reasoning: To- wards both evidence and commonsense reasoning for video question- answering,
J. Li, L. Niu, and L. Zhang, “From representation to reasoning: To- wards both evidence and commonsense reasoning for video question- answering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022
2022
-
[34]
Egotaskqa: Understanding human tasks in egocentric videos,
B. Jia, T. Lei, S.-C. Zhu, and S. Huang, “Egotaskqa: Understanding human tasks in egocentric videos,”Advances in Neural Information Processing Systems, vol. 35, pp. 3343–3360, 2022
2022
-
[35]
Intentqa: Context-aware video intent reasoning,
J. Li, P. Wei, W. Han, and L. Fan, “Intentqa: Context-aware video intent reasoning,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 11 963–11 974
2023
-
[36]
In the eye of mllm: Benchmarking egocentric video intent understanding with gaze-guided prompting,
T. Peng, J. Hua, M. Liu, and F. Lu, “In the eye of mllm: Benchmarking egocentric video intent understanding with gaze-guided prompting,” arXiv preprint arXiv:2509.07447, 2025
-
[37]
Q. Team, “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shaoet al., “Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models,”arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Grounded question-answering in long egocentric videos,
S. Di and W. Xie, “Grounded question-answering in long egocentric videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 934–12 943
2024
-
[40]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[41]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
J. Yang, H. Zhang, F. Li, X. Zou, C. Li, and J. Gao, “Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v,”arXiv preprint arXiv:2310.11441, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Fine-grained visual prompting,
L. Yang, Y . Wang, X. Li, X. Wang, and J. Yang, “Fine-grained visual prompting,”Advances in Neural Information Processing Systems, vol. 36, pp. 24 993–25 006, 2023
2023
-
[43]
Large language models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,”Advances in neural infor- mation processing systems, vol. 35, pp. 22 199–22 213, 2022
2022
-
[44]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Suet al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inEuropean conference on computer vision. Springer, 2024, pp. 38–55
2024
-
[45]
Simple online and realtime tracking,
A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” in2016 IEEE international conference on image processing (ICIP). Ieee, 2016, pp. 3464–3468
2016
-
[46]
Analyzing the behaviors of pedestrians and cyclists in interactions with autonomous systems using controlled experiments: A literature review,
D. Li, W. Mao, F. C. Pereira, Y . Xiao, X. Su, and R. Krueger, “Analyzing the behaviors of pedestrians and cyclists in interactions with autonomous systems using controlled experiments: A literature review,”Transportation Research Part F: Traffic Psychology and Behaviour, vol. 114, pp. 270–307, 2025
2025
-
[48]
Challenges and trends in egocentric vision: A survey,
X. Li, H. Qiu, L. Wang, H. Zhang, C. Qi, L. Han, H. Xiong, and H. Li, “Challenges and trends in egocentric vision: A survey,”Machine Intelligence Research, vol. 23, no. 1, pp. 1–33, 2026
2026
-
[49]
D. Li, Y . Feng, and R. Krueger, “Eye Gaze-Informed and Context-Aware Pedestrian Trajectory Prediction in Shared Spaces 9 with Automated Shuttles: A Virtual Reality Study,” Mar. 2026, arXiv:2603.19812 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[51]
Learning Transferable Visual Models From Natural Language Su- pervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning Transferable Visual Models From Natural Language Su- pervision,” inProceedings of the 38th International Conference on Machine Learning. PMLR, Jul. 2021, pp. 8748–8763
2021
-
[52]
A. Patel, V . Chitalia, and Y . Yang, “Advancing Egocentric Video Question Answering with Multimodal Large Language Models,” Apr. 2025, arXiv:2504.04550 [cs]
-
[53]
LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
Y . Dai, Z. Wu, B. Zeng, D. Hua, J. Liu, B. Li, Y . Wang, C. Tong, H. Liang, X. Maet al., “Latentomni: Rethinking omni-modal un- derstanding via unified audio-visual latent reasoning,”arXiv preprint arXiv:2605.22012, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Chrono: A simple blueprint for representing time in mllms,
B. Meinardus, H. G. Rodriguez, A. Batra, A. Rohrbach, and M. Rohrbach, “Chrono: A simple blueprint for representing time in mllms,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, October 2025, pp. 4151–4156. 10
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.