ERBench: A Benchmark and Testsuite for Equation Discovery Algorithms
Pith reviewed 2026-06-27 17:03 UTC · model grok-4.3
The pith
ERBench supplies a large suite of groundtruth equations and systematic robustness tests to evaluate symbolic regression algorithms for equation discovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
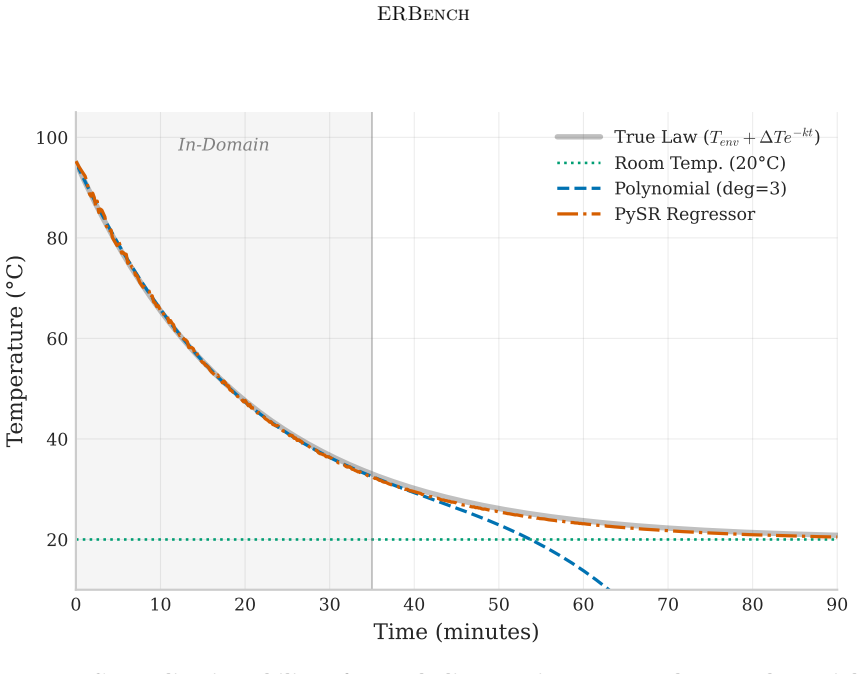
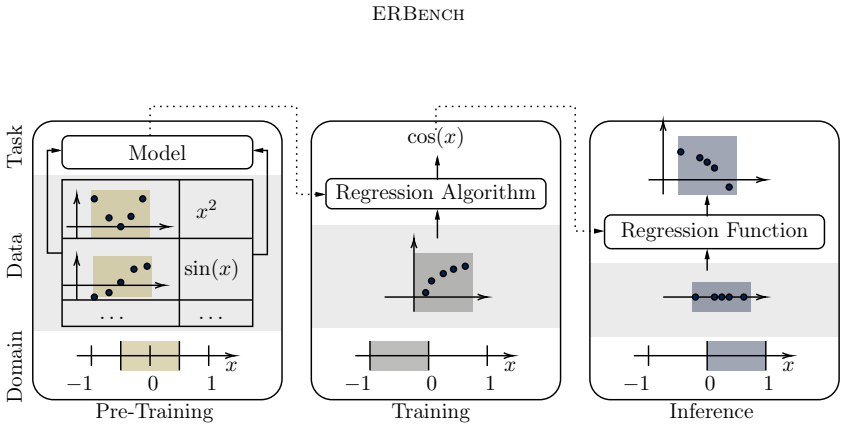
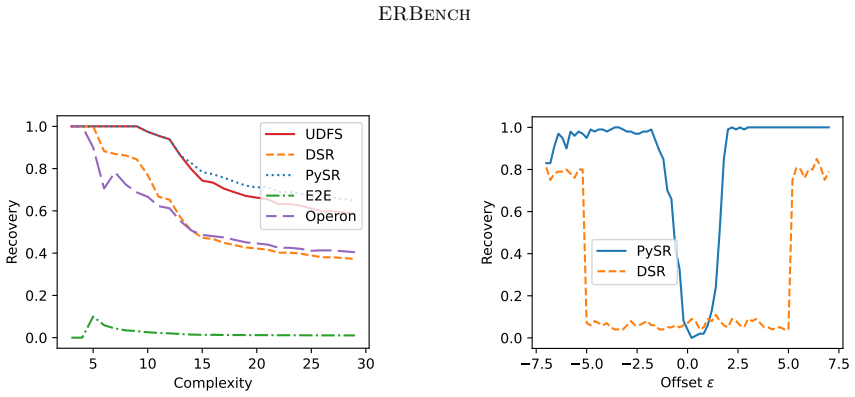
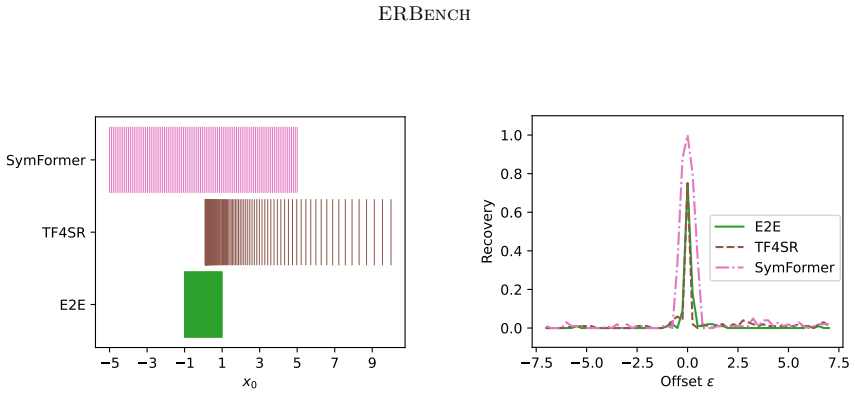
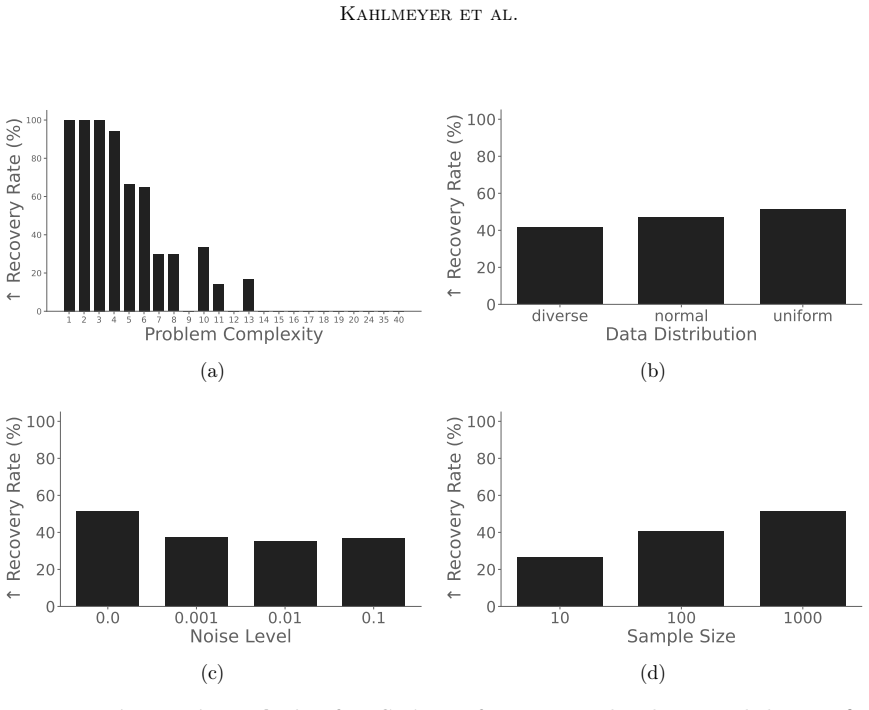
Equation discovery is best evaluated by how reliably symbolic regression recovers known groundtruth formulas rather than by in-domain prediction accuracy alone; ERBench implements this by supplying many groundtruth equations together with controlled variations in dimensionality, sampling size, sampling distribution, sampling domain, and noise levels.
What carries the argument
ERBench, an evaluation framework that measures equation recovery performance under controlled changes in data conditions.
If this is right
- Practitioners can rank symbolic regression methods by their robustness to realistic variations in data rather than by interpolation performance.
- Development of new algorithms can target explicit recovery metrics instead of test-set accuracy alone.
- Benchmarks can expand by adding more groundtruth equations without changing the evaluation protocol.
- Comparisons across papers become standardized when all methods are tested on the same recovery tasks with the same condition variations.
Where Pith is reading between the lines
- The benchmark could be extended to include partial or incomplete observations to test discovery under missing data regimes common in experiments.
- If recovery correlates with discovery success, the same test suite could serve as a filter before deploying methods on high-stakes scientific modeling problems.
- Standardized recovery scores might accelerate consensus on which algorithmic components (operators, search strategies, regularization) actually drive discovery performance.
Load-bearing premise
Algorithms that recover known groundtruth formulas well will also succeed at discovering unknown equations from real data.
What would settle it
An experiment in which the algorithms that score highest on ERBench recovery tasks fail to recover or discover accurate equations on a fresh collection of scientific datasets not included in the benchmark.
Figures
read the original abstract
Equation discovery aims to automate the discovery of scientific models in the form of mathematical equations from data. Technically, equation discovery is implemented by symbolic regression algorithms. Performance of symbolic regression for equation discovery is measured along two dimensions: Prediction accuracy on test data, and recovery of known groundtruth formulas. For standard regression, accuracy is typically measured on in-domain test data, for instance, by splitting a data set randomly into training and test data. While this makes sense for in-domain interpolation, which is the common goal in ordinary regression, it can be a misleading proxy for true model discovery and generalization. The obvious alternative is to measure out-of-domain accuracy. However, obtaining challenging out-of-domain test data is a non-trivial problem. Therefore, we focus on equation recovery for evaluating symbolic regression algorithms for equation discovery. The rationale is that symbolic regression algorithms that perform well in recovering known groundtruth formulas are good candidates to perform well in unknown equation discovery. Existing benchmarks for symbolic regression include equation recovery tasks, however, with only a small number of groundtruth formulas that are publicly known. Moreover, these benchmarks place less emphasis on evaluating the robustness of algorithms in terms of their behavior under changing dimensionality, sampling size, sampling distribution and sampling domain. This, however, is of central importance to practitioners wanting to discover equations for modeling natural phenomena, since data is almost certainly noisy and comes from diverse domains, distributions, and sample sizes. To fill this gap, we introduce the Equation Recovery Benchmark (ERBench), a new evaluation framework designed to rigorously assess algorithms explicitly targeting the task of equation discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ERBench, a benchmark and testsuite for evaluating symbolic regression algorithms on equation discovery. It centers evaluation on recovery of known groundtruth formulas rather than out-of-domain prediction accuracy, on the grounds that recovery success is a suitable proxy for discovery capability on unknown models. The design emphasizes robustness testing across dimensionality, sample size, sampling distribution, and domain, while critiquing prior benchmarks for limited public formulas and insufficient robustness coverage.
Significance. If the proxy assumption can be justified and the benchmark implemented with reproducible test suites, ERBench could provide a standardized, practitioner-oriented evaluation framework that prioritizes robustness properties relevant to scientific modeling. The focus on multiple data regimes is a constructive direction for the field.
major comments (1)
- [Abstract] Abstract (and introduction): The central design choice rests on the claim that 'symbolic regression algorithms that perform well in recovering known groundtruth formulas are good candidates to perform well in unknown equation discovery.' No argument, citation, or preliminary result is supplied to support transfer from recovery of public formulas to novel scientific models; if recovery can be achieved by overfitting to the finite set of known expressions, the benchmark would not rigorously assess discovery capability.
minor comments (1)
- The abstract presents the benchmark rationale and motivation but contains no implementation details, validation experiments, or quantitative results. A dedicated section describing the concrete test-suite construction, ground-truth selection criteria, and planned evaluation protocol would strengthen the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the central design choice of ERBench. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and introduction): The central design choice rests on the claim that 'symbolic regression algorithms that perform well in recovering known groundtruth formulas are good candidates to perform well in unknown equation discovery.' No argument, citation, or preliminary result is supplied to support transfer from recovery of public formulas to novel scientific models; if recovery can be achieved by overfitting to the finite set of known expressions, the benchmark would not rigorously assess discovery capability.
Authors: We agree that the manuscript states the rationale for using recovery of known groundtruth formulas as a proxy without supplying supporting citations, arguments, or preliminary results. The provided text motivates the choice primarily by noting the difficulty of obtaining challenging out-of-domain test data. In the revised manuscript we will expand the abstract and introduction to include additional discussion of this assumption, reference prior symbolic regression benchmarks that similarly rely on recovery metrics, and explicitly address the limitation of potential overfitting to the finite set of public expressions. We will also note how the benchmark's emphasis on robustness across dimensionality, sample size, distribution, and domain is intended to mitigate some of these risks. revision: yes
Circularity Check
No circularity: benchmark proposal with no derived results or self-referential steps
full rationale
The paper introduces ERBench as an evaluation framework for symbolic regression algorithms. Its justification rests on an explicit rationale statement rather than any derivation, equation, fitted parameter, or self-citation chain. No load-bearing step reduces to its own inputs by construction; the work contains no predictions, uniqueness theorems, or ansatzes that could exhibit circularity. This is the expected outcome for a benchmark proposal that does not claim to derive new scientific results from its own data or prior outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption symbolic regression algorithms that perform well in recovering known groundtruth formulas are good candidates to perform well in unknown equation discovery
Reference graph
Works this paper leans on
-
[1]
International Joint Conferences on Artificial Intelligence Organization, 8 2024. doi: 10.24963/ijcai.2024/471. URLhttps://doi.org/10.24963/ijcai.2024/471. Main Track. Paul Kahlmeyer, Markus Fischer, and Joachim Giesen. Dimension reduction for symbolic regression. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17707–17714...
-
[2]
URLhttps://cavalab.org/srbench/competition-2022/. Florian Lalande, Yoshitomo Matsubara, Naoya Chiba, Tatsunori Taniai, Ryo Igarashi, and Yoshitaka Ushiku. A transformer model for symbolic regression towards scientific discovery. InNeurIPS 2023 AI for Science Workshop, 2023. URLhttps://openreview.net/forum? id=AIfqWNHKjo. Guillaume Lample and François Char...
-
[3]
Randal Olson, William La Cava, Patryk Orzechowski, Ryan Urbanowicz, and Jason Moore
[Online; accessed 24-April-2025]. Randal Olson, William La Cava, Patryk Orzechowski, Ryan Urbanowicz, and Jason Moore. Pmlb: A large benchmark suite for machine learning evaluation and comparison.BioData Mining, 10, 12 2017. doi: 10.1186/s13040-017-0154-4. Patryk Orzechowski, William La Cava, and Jason H. Moore. Where are we now? a large benchmark study o...
-
[4]
doi:https://doi.org/10.1038/s41592-019-0686-2 , journal =
doi: 10.1038/s41592-019-0686-2. [Online; accessed 24-April-2025]. Ekaterina (Katya) Vladislavleva, Guido Smits, and Dick den Hertog. Order of nonlinearity as a complexity measure for models generated by symbolic regression via pareto genetic programming.Evolutionary Computation, IEEE Transactions on, 13:333 – 349, 05 2009. doi: 10.1109/TEVC.2008.926486. W...
-
[5]
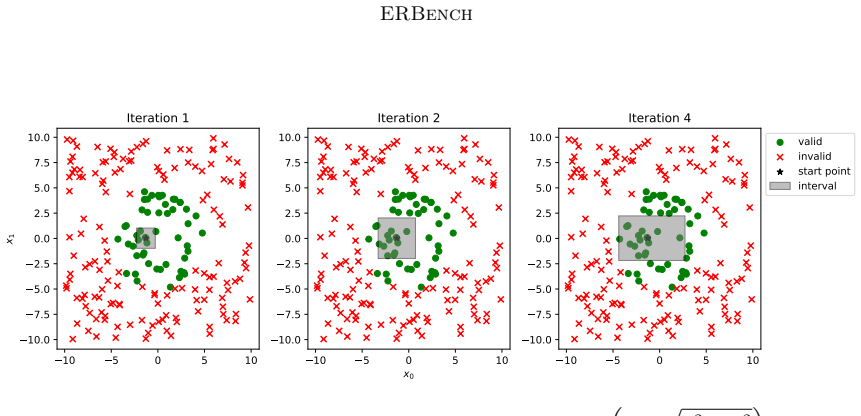
Set the initial box to the box of zero-width located at this point
Sample from a large box and find one valid point. Set the initial box to the box of zero-width located at this point
-
[6]
For each expansion, sample from the additional space and check the validity of the samples
From the current box, gradually expand the space around each dimension. For each expansion, sample from the additional space and check the validity of the samples
-
[7]
If an expansion fails, the step size is reduced until a minimum step size is reached or if the expansion is valid
-
[8]
Based upon this algorithm, we were able to generate valid intervals for all the SynEq formulas
If any dimension has been expanded and the maximum number of expansions is not exceeded, goto 2. Based upon this algorithm, we were able to generate valid intervals for all the SynEq formulas. Sampling Points.In Section 2 of the paper, we discussed the dependency of pre-training based algorithms on their pre-training distribution. A consequence of this de...
2022
-
[9]
Sample the number of mixture partsk∼Cat(1, K)
-
[10]
Sample the mixture weights[wi ∼U(0,1)] i=1,...,k
-
[11]
Normalize the weight vectorw:=w/||w||
-
[12]
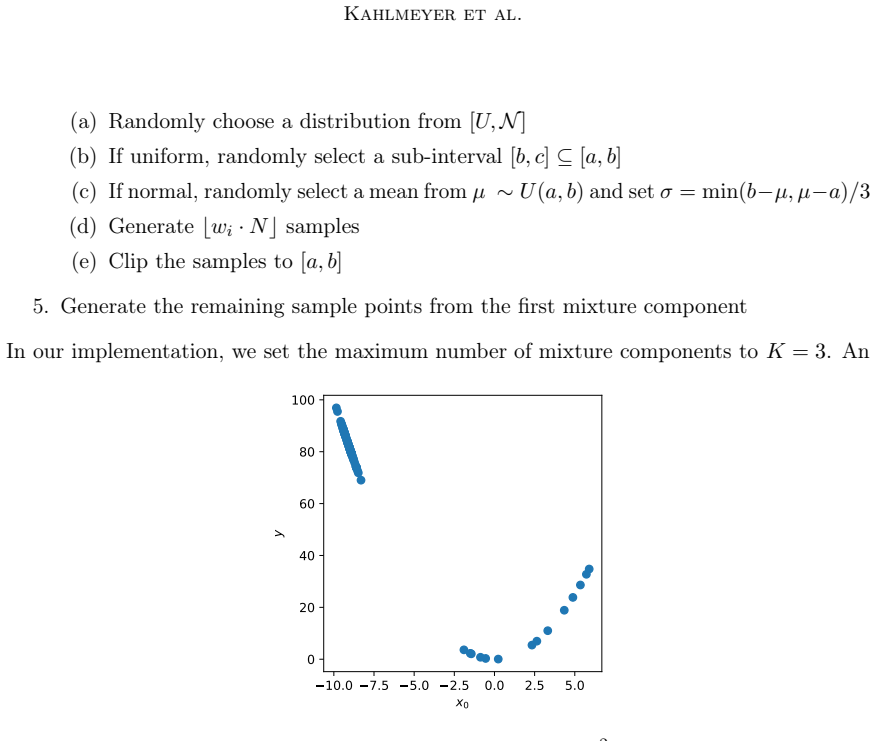
For each mixture component: 35 Kahlmeyer et al. (a) Randomly choose a distribution from[U,N] (b) If uniform, randomly select a sub-interval[b, c]⊆[a, b] (c) If normal, randomly select a mean fromµ∼U (a, b)and set σ = min(b−µ, µ−a)/3 (d) Generate⌊w i ·N⌋samples (e) Clip the samples to[a, b]
-
[13]
An 10.0 7.5 5.0 2.5 0.0 2.5 5.0 x0 0 20 40 60 80 100y Figure 9: Samples from the diverse sampling strategy fory = x2
Generate the remaining sample points from the first mixture component In our implementation, we set the maximum number of mixture components toK = 3. An 10.0 7.5 5.0 2.5 0.0 2.5 5.0 x0 0 20 40 60 80 100y Figure 9: Samples from the diverse sampling strategy fory = x2
-
[14]
example of samples generated for the functiony=x2 0 is shown in Figure 9
Points are sampled from a mixture model, where the mixture components are either uniform or gaussian. example of samples generated for the functiony=x2 0 is shown in Figure 9. 36
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.