In-Context Learning for the Imputation of Public Opinion Data with Large Language Models
Pith reviewed 2026-06-27 16:27 UTC · model grok-4.3
The pith
Large language models using in-context learning impute missing public opinion survey responses more accurately than MICE PMM, especially under non-random missingness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In-context learning with large language models consistently reduces absolute error in imputing missing survey responses compared to MICE PMM across all missingness mechanisms, with the largest gains under MNAR. The best-performing specification using gpt-oss-120b and 100 in-context examples achieves near-nominal aggregate coverage approaching 95 percent while producing confidence intervals two to five times narrower than MICE PMM.
What carries the argument
In-context learning (ICL) applied to LLMs, where complete response examples are supplied in the prompt to predict and fill missing opinion variable values.
If this is right
- ICL reduces absolute error under MCAR, MAR, and MNAR missingness mechanisms.
- The largest error reductions occur under MNAR.
- gpt-oss-120b with 100 in-context examples yields the narrowest intervals while maintaining coverage near 95 percent.
- The method supports deployment via an sklearn-like Python package for both local and proprietary models.
Where Pith is reading between the lines
- The same ICL setup could be tested on surveys covering different topics or time periods to check consistency.
- If the LLM was trained on data with its own demographic skews, imputed values might shift subgroup patterns in ways MICE does not.
- Researchers could examine whether increasing the number of examples beyond 100 continues to improve coverage or begins to add noise.
Load-bearing premise
That the in-context examples supplied to the LLM are sufficient for the model to recover the conditional distribution of the missing responses without introducing systematic biases that differ from those of the statistical baseline.
What would settle it
A direct comparison on a dataset with known true values where LLM imputations show larger systematic error than MICE PMM within a demographic subgroup not represented in the provided examples.
Figures


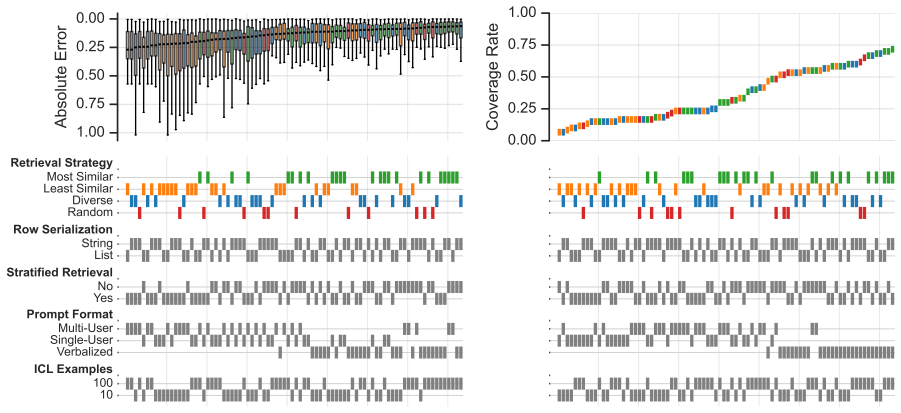
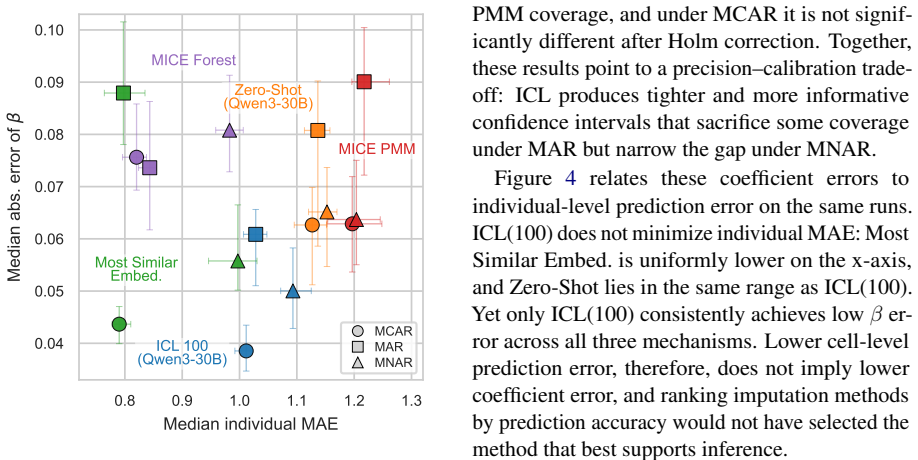
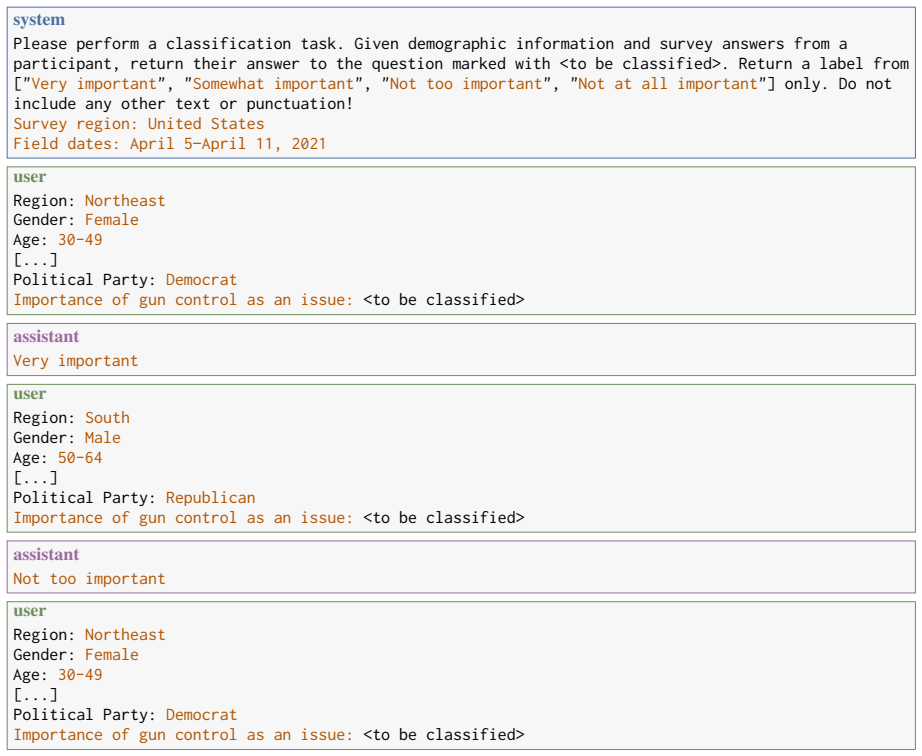
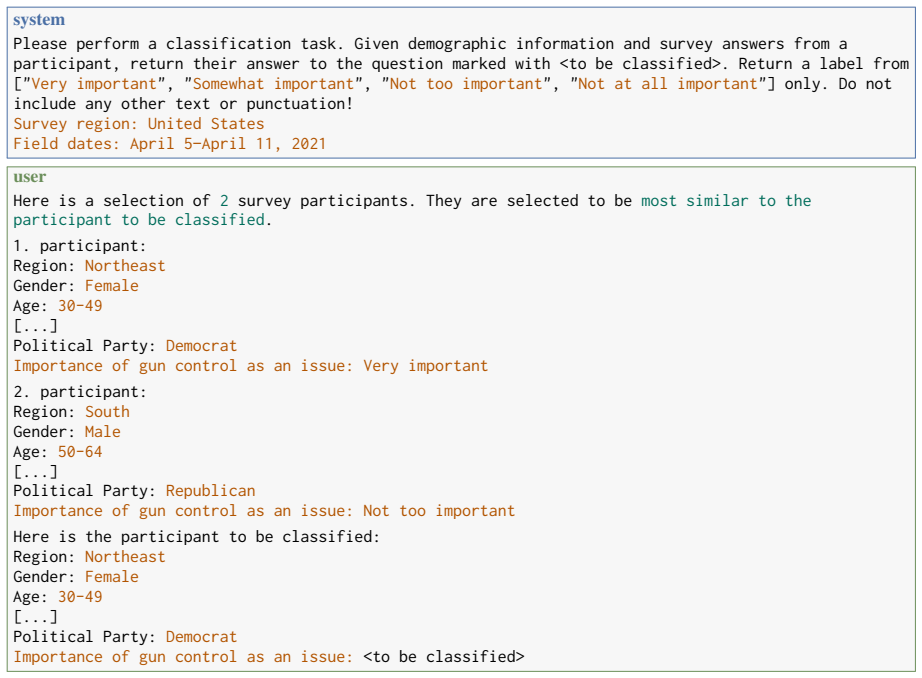
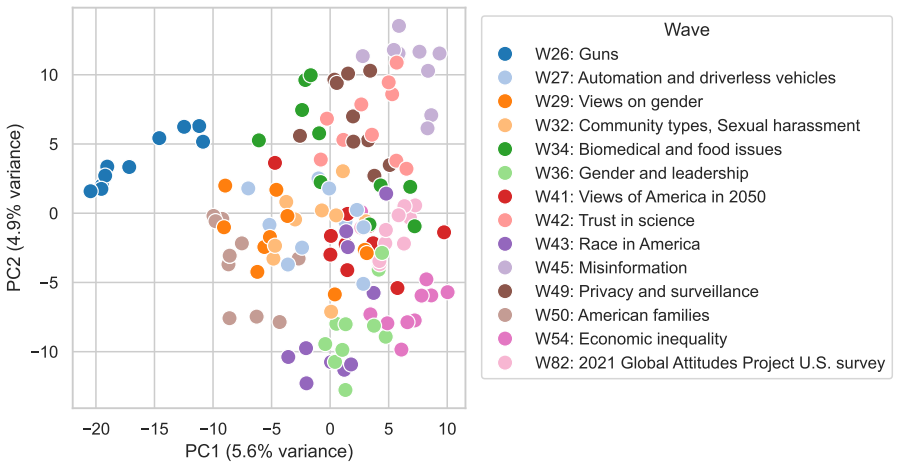
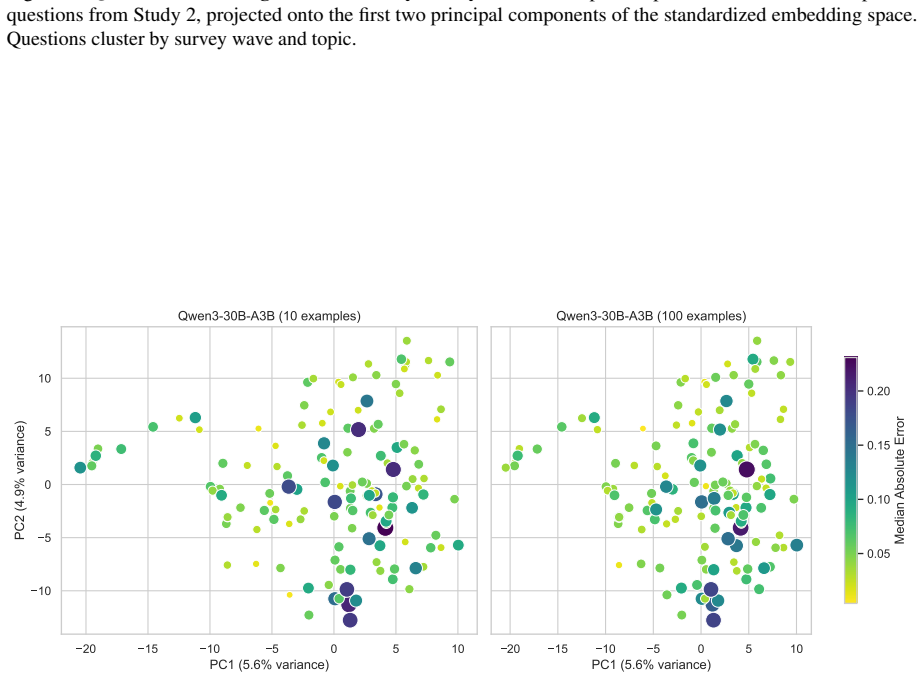
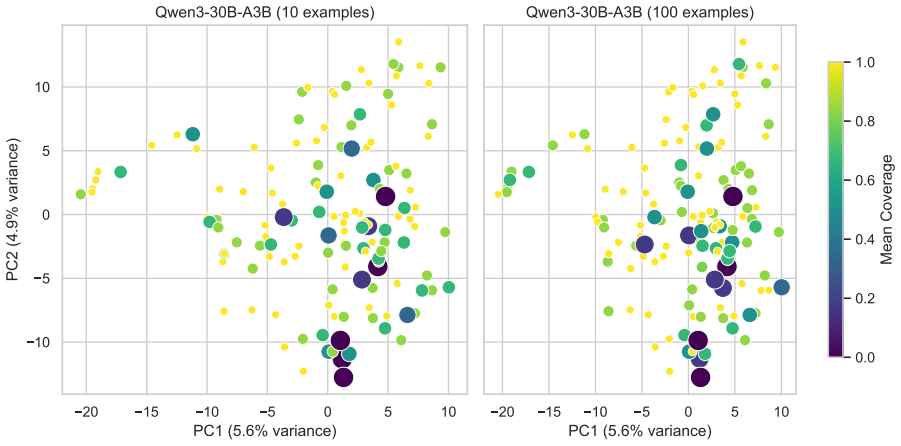
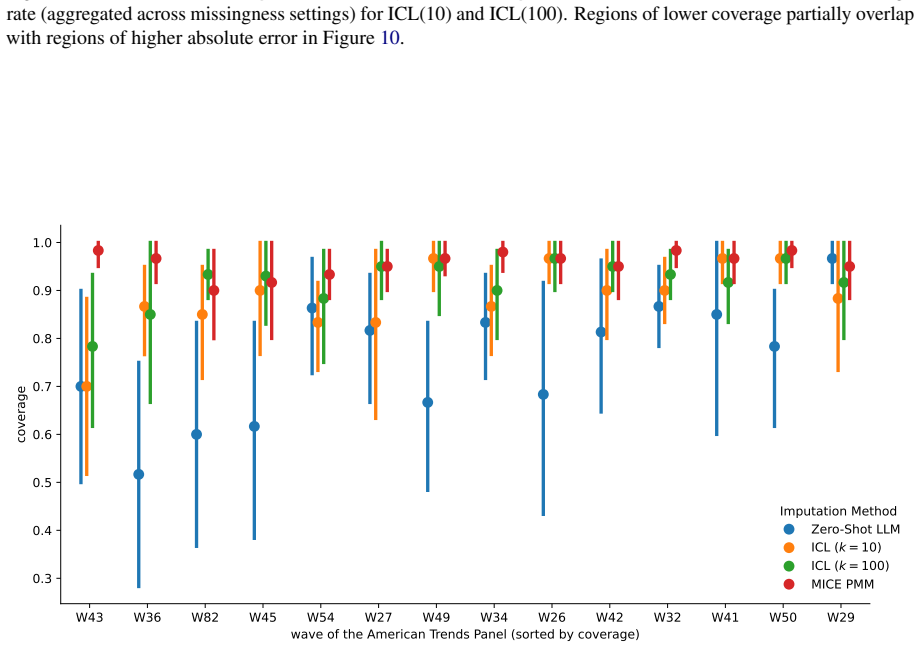
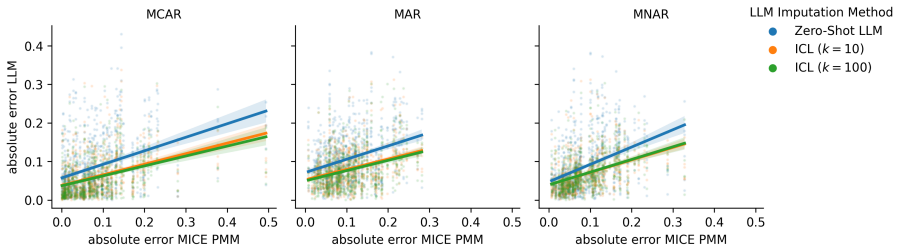
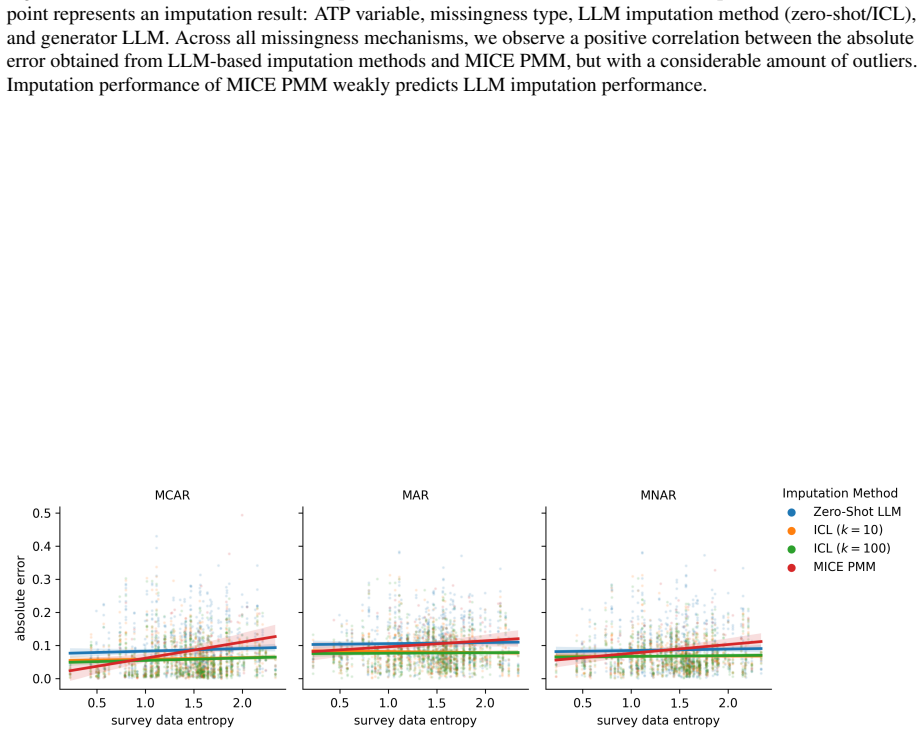
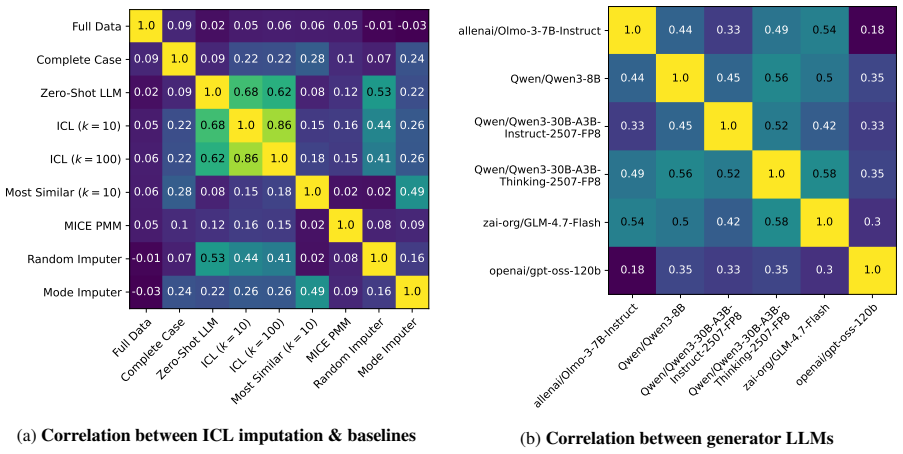
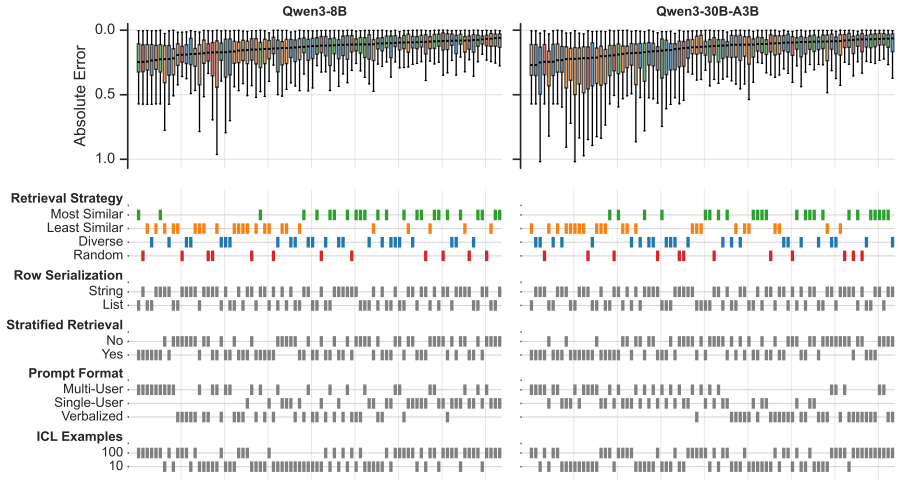
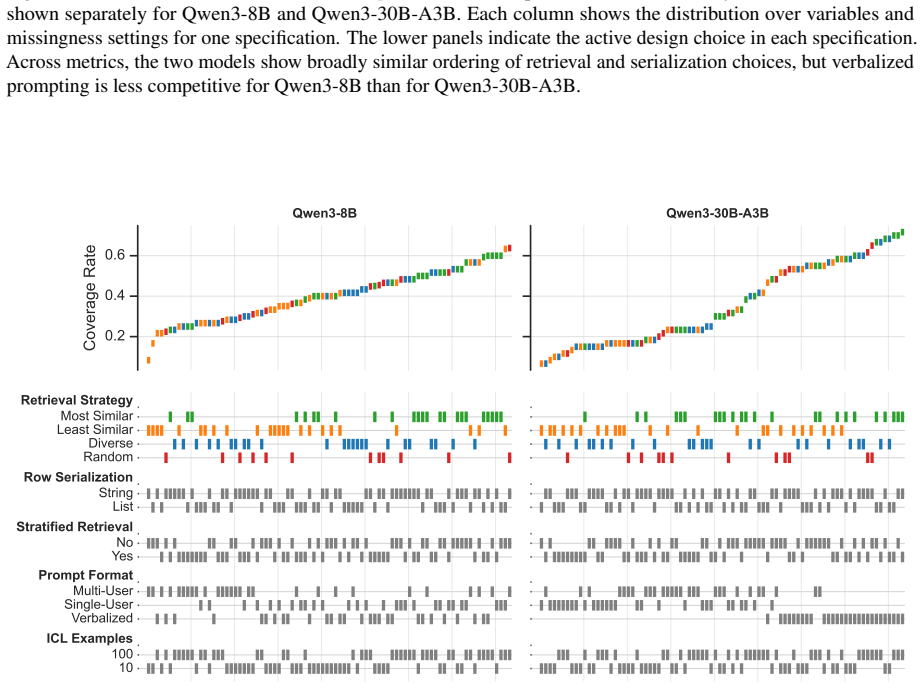
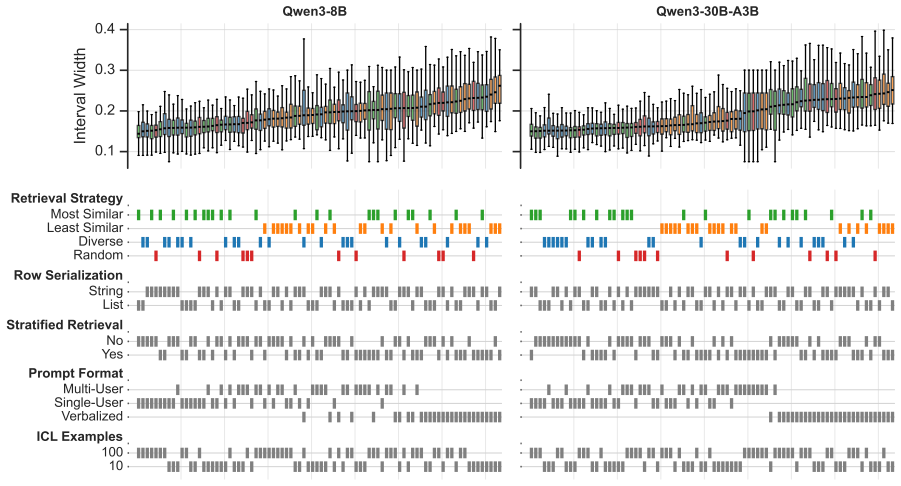
read the original abstract
Large language models have been widely evaluated as simulators of individual survey responses. In practice, however, fully unobserved responses are rare; the dominant problem is partial non-response. Imputation aims to restore the overall structure of a survey dataset by filling in these missing values. It has its own well-defined evaluation criteria and differs fundamentally from prediction. We propose to impute missing survey data through in-context learning (ICL). We systematically evaluate ICL design choices across different missingness mechanisms (MCAR, MAR, MNAR) on 150 opinion variables spanning 15 waves of the American Trends Panel. Compared to well-established statistical methods for data imputation like MICE PMM, our ICL approach consistently reduces absolute error across all missingness mechanisms, with the largest gains under non-random missingness (MNAR). Notably, the best-performing specification (gpt-oss-120b with 100 in-context examples) achieves near-nominal aggregate coverage (approaching the 95% level) with confidence intervals two to five times narrower than MICE PMM. We publish a Python package with an sklearn-like API to enable easy deployment of our method using local and proprietary LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using in-context learning (ICL) with large language models to impute partially missing responses in public opinion survey data. It evaluates this approach systematically across MCAR, MAR, and MNAR missingness mechanisms on 150 opinion variables from 15 waves of the American Trends Panel, claiming consistent reductions in absolute error relative to MICE PMM (with largest gains under MNAR), near-nominal aggregate coverage approaching 95%, and confidence intervals two to five times narrower for the best specification (gpt-oss-120b with 100 in-context examples). A Python package implementing an sklearn-like API is released to support deployment with local or proprietary LLMs.
Significance. If the reported gains prove robust, the work offers a practical alternative for survey imputation that may better capture complex response patterns under non-random missingness than standard statistical methods. The release of reproducible code with a familiar API is a clear strength that lowers barriers to adoption and enables direct comparison in future studies.
major comments (2)
- [Evaluation / Results] Evaluation details (likely §3 or §4): the abstract and results claim comparative performance but provide no information on per-variable sample sizes, exact prompting templates, selection of the 100 in-context examples, or construction of confidence intervals and coverage rates. These omissions are load-bearing for assessing whether the MNAR error reductions and narrower intervals are reproducible or sensitive to design choices.
- [MNAR results] MNAR experiments (likely §4.3): the headline claim of largest gains under MNAR requires that the LLM recovers the true conditional distribution P(Y|X, missingness) from observed (selected) examples. No explicit handling of the selection process is described, unlike selection-model extensions of MICE; if the model simply reproduces the biased observed marginal, the reported coverage and error reductions could be artifacts rather than genuine imputation of the missing tail.
minor comments (1)
- [Abstract] The abstract refers to 'gpt-oss-120b' without clarifying whether this is an open-source model or a typo for a known variant; consistent naming would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each point below and will revise the manuscript to improve reproducibility and address methodological concerns.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation details (likely §3 or §4): the abstract and results claim comparative performance but provide no information on per-variable sample sizes, exact prompting templates, selection of the 100 in-context examples, or construction of confidence intervals and coverage rates. These omissions are load-bearing for assessing whether the MNAR error reductions and narrower intervals are reproducible or sensitive to design choices.
Authors: We agree these details are essential and currently insufficient in the manuscript. The data section provides only aggregate sample sizes, prompting is described at a high level without exact templates, example selection is not specified, and CI/coverage methods are not detailed. We will add a dedicated experimental setup subsection in Section 4 (and expand Appendix B) with per-variable sample sizes in a table, verbatim prompting templates, explicit description of selecting the 100 examples via random sampling from observed cases, and bootstrap (1000 resamples) procedure for intervals and aggregate coverage. These changes will be made in the revision. revision: yes
-
Referee: [MNAR results] MNAR experiments (likely §4.3): the headline claim of largest gains under MNAR requires that the LLM recovers the true conditional distribution P(Y|X, missingness) from observed (selected) examples. No explicit handling of the selection process is described, unlike selection-model extensions of MICE; if the model simply reproduces the biased observed marginal, the reported coverage and error reductions could be artifacts rather than genuine imputation of the missing tail.
Authors: This is a substantive concern. Our MNAR mechanism (Section 4.3) induces missingness as a direct function of Y (e.g., higher values more likely missing). ICL conditions on the observed (selected) examples without an explicit selection model. The empirical gains suggest the LLM infers useful conditional patterns from the biased sample, but we acknowledge the risk that results partly reflect reproduction of the observed marginal rather than recovery of the full distribution. We will add a limitations paragraph in the Discussion comparing to selection-model MICE extensions, noting this as an implicit rather than explicit approach, and include distribution diagnostics in the revision. revision: partial
Circularity Check
No circularity: empirical comparison of ICL imputation to MICE on held-out survey data
full rationale
The paper reports an empirical evaluation of LLM in-context learning for imputing missing survey responses, measuring absolute error and coverage against MICE PMM baselines across MCAR/MAR/MNAR mechanisms on American Trends Panel data. No equations, fitted parameters, or self-referential definitions are present that would render the reported error reductions or coverage improvements tautological by construction. The method is positioned as an external alternative evaluated on real data splits, with no load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work. The central claims rest on observable performance differences rather than any reduction to the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can recover the conditional distribution of survey responses from a modest number of in-context examples.
Reference graph
Works this paper leans on
-
[1]
Vera, Henrique Schechter and Dua, Sahil and Zhang, Biao and Salz, Daniel and Mullins, Ryan and Panyam, Sindhu Raghuram and Smoot, Sara and Naim, Iftekhar and Zou, Joe and Chen, Feiyang and Cer, Daniel and Lisak, Alice and Choi, Min and Gonzalez, Lucas and Sanseviero, Omar and Cameron, Glenn and Ballantyne, Ian and Black, Kat and Chen, Kaifeng and Wang, We...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.20354
-
[2]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
Olmo 3 , author=. 2025 , eprint=
2025
-
[6]
Using Simulation Studies to Evaluate Statistical Methods , author =. Statistics in Medicine , volume =. doi:10.1002/sim.8086 , abstract =
-
[7]
and Royston, Patrick and Wood, Angela M
White, Ian R. and Royston, Patrick and Wood, Angela M. , year = 2011, month = feb, journal =. Multiple Imputation Using Chained Equations:. doi:10.1002/sim.4067 , abstract =
-
[8]
2025 , eprint=
Survey Response Generation: Generating Closed-Ended Survey Responses In-Silico with Large Language Models , author=. 2025 , eprint=
2025
-
[9]
Benchmarking Distributional Alignment of Large Language Models
Meister, Nicole and Guestrin, Carlos and Hashimoto, Tatsunori. Benchmarking Distributional Alignment of Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.2
-
[10]
Schouten, Rianne Margaretha and Lugtig, Peter and Vink, Gerko , year = 2018, month = oct, journal =. Generating Missing Values for Simulation Purposes: A Multivariate Amputation Procedure , shorttitle =. doi:10.1080/00949655.2018.1491577 , urldate =
-
[11]
Journal of statistical software , volume=
mice: Multivariate imputation by chained equations in R , author=. Journal of statistical software , volume=
-
[12]
2018 , publisher=
Flexible Imputation of Missing Data, Second Edition , author=. 2018 , publisher=
2018
-
[13]
Statistical Horizons , year=
Imputation by predictive mean matching: Promise & peril , author=. Statistical Horizons , year=
-
[14]
Journal of the American statistical Association , volume=
Models for nonresponse in sample surveys , author=. Journal of the American statistical Association , volume=. 1982 , publisher=
1982
-
[15]
Journal of the American Statistical Association , volume=
The problem of non-response in sample surveys , author=. Journal of the American Statistical Association , volume=. 1946 , publisher=
1946
-
[16]
International Journal of Public Opinion Quarterly , volume=
Nonresponse rates and nonresponse bias in household surveys , author=. International Journal of Public Opinion Quarterly , volume=. 2006 , publisher=
2006
-
[17]
, title =
Rubin, Donald B. , title =. 1987 , isbn =
1987
-
[18]
Little, Roderick J. A. and Rubin, Donald B. , title =. 2019 , isbn =
2019
-
[19]
Little, Roderick J. A. , title =. Journal of Business & Economic Statistics , year =
-
[20]
Rubin , journal =
Donald B. Rubin , journal =. Inference and Missing Data , urldate =
-
[21]
Santurkar, Shibani and Durmus, Esin and Ladhak, Faisal and Lee, Cinoo and Liang, Percy and Hashimoto, Tatsunori , year =. Whose. doi:10.48550/arXiv.2303.17548 , urldate =. 2303.17548 , primaryclass =
-
[22]
AI-Augmented Surveys: Leveraging Large Language Models and Surveys for Opinion Prediction
Kim, Junsol and Lee, Byungkyu , year =. doi:10.48550/arXiv.2305.09620 , urldate =. 2305.09620 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.09620
-
[23]
Out of one, many: Using language models to simulate human samples , author=. Political Analysis , volume=. doi:10.1017/pan.2023.2 , year=
-
[24]
2025 , eprint=
Learning from Convenience Samples: A Case Study on Fine-Tuning LLMs for Survey Non-response in the German Longitudinal Election Study , author=. 2025 , eprint=
2025
-
[25]
Future Internet , volume=
Predicting Missing Values in Survey Data Using Prompt Engineering for Addressing Item Non-Response , author=. Future Internet , volume=. 2024 , publisher=
2024
-
[26]
Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval , pages=
Reciprocal rank fusion outperforms condorcet and individual rank learning methods , author=. Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval , pages=. 2009 , doi=
2009
-
[27]
Information Systems , volume=
Fast and eager k-medoids clustering: O (k) runtime improvement of the PAM, CLARA, and CLARANS algorithms , author=. Information Systems , volume=. 2021 , publisher=
2021
-
[28]
Specializing large language models to simulate survey response distributions for global populations
Cao, Yong and Liu, Haijiang and Arora, Arnav and Augenstein, Isabelle and R. Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 20...
-
[29]
Language Model Fine-Tuning on Scaled Survey Data for Predicting Distributions of Public Opinions
Suh, Joseph and Jahanparast, Erfan and Moon, Suhong and Kang, Minwoo and Chang, Serina. Language Model Fine-Tuning on Scaled Survey Data for Predicting Distributions of Public Opinions. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1028
-
[30]
Knowledge of cultural moral norms in large language models
Ramezani, Aida and Xu, Yang. Knowledge of cultural moral norms in large language models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.26
-
[31]
doi:10.5281/zenodo.7428632 , url=
2022 , publisher=. doi:10.5281/zenodo.7428632 , url=
-
[32]
Zhao, Jianpeng and Yuan, Chenyu and Luo, Weiming and Xie, Haoling and Zhang, Guangwei and Quan, Steven Jige and Yuan, Zixuan and Wang, Pengyang and Zhang, Denghui , month = sep, year =. Large. doi:10.48550/arXiv.2509.06337 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.06337
-
[33]
Krsteski, Stefan and Russo, Giuseppe and Chang, Serina and West, Robert and Gligori. Valid. Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics , publisher =. 2026 , url =
2026
-
[34]
and Bates, Stephen and Fannjiang, Clara and Jordan, Michael I
Angelopoulos, Anastasios N. and Bates, Stephen and Fannjiang, Clara and Jordan, Michael I. and Zrnic, Tijana , month = nov, year =. Prediction-powered inference , volume =. Science , publisher =. doi:10.1126/science.adi6000 , abstract =
-
[35]
Using Imperfect Surrogates for Downstream Inference: Design-based Supervised Learning for Social Science Applications of Large Language Models , author =. 2024 , journal =. doi:10.48550/arXiv.2306.04746 , url =
-
[36]
2025 , journal =
The Mixed Subjects Design: Treating Large Language Models as Potentially Informative Observations , author =. 2025 , journal =
2025
-
[37]
Valid Inference with Imperfect Synthetic Data , author =. 2025 , publisher =. doi:10.48550/arXiv.2508.06635 , url =. 2508.06635 , archivePrefix =
-
[38]
Demystifying prediction powered inference
Demystifying Prediction Powered Inference , author =. 2026 , publisher =. doi:10.48550/arXiv.2601.20819 , url =. 2601.20819 , archivePrefix =
-
[39]
The Fourteenth International Conference on Learning Representations , year =
Hu, Tiancheng and Baumann, Joachim and Lupo, Lorenzo and Collier, Nigel and Hovy, Dirk and R. The Fourteenth International Conference on Learning Representations , year =
-
[40]
Miao Xiong and Zhiyuan Hu and Xinyang Lu and YIFEI LI and Jie Fu and Junxian He and Bryan Hooi , booktitle=. Can. 2024 , url=
2024
-
[41]
Synthetic Replacements for Human Survey Data? The Perils of Large Language Models , author=. Political Analysis , year=. doi:10.1017/pan.2024.5 , publisher=
-
[42]
Sociological Methods & Research , year=
Machine Bias: How Do Generative Language Models Answer Opinion Polls? , author=. Sociological Methods & Research , year=. doi:10.1177/00491241251330582 , publisher=
-
[43]
LLMs as Implicit Imputers: Uncertainty Should Scale with Missing Information
van Buuren, Stef , month = may, year =. doi:10.48550/arXiv.2605.13188 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.13188
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.