Large Language Models as Virtual Survey Respondents: Evaluating Sociodemographic Response Generation
Pith reviewed 2026-05-18 18:43 UTC · model grok-4.3
The pith
Large language models can generate sociodemographic survey responses with consistent patterns across different models and prompt settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Partial Attribute Simulation (PAS) lets models predict missing attributes from incomplete respondent profiles, while Full Attribute Simulation (FAS) has models create complete synthetic datasets with or without additional context. Using the LLM-S^3 benchmark of eleven public datasets, evaluations of GPT-3.5/4 Turbo and LLaMA 3 models reveal consistent performance trends across model families and show that context and prompt design influence how closely the generated responses match real distributions.
What carries the argument
The PAS and FAS task abstractions framed as diagnostic tools for assessing LLM simulation of sociodemographic responses on a multi-domain benchmark.
If this is right
- Adding context to prompts tends to increase how well the generated responses align with real survey data distributions.
- Models from different families display similar trends in their simulation accuracy on both partial and full attribute tasks.
- Generating structured outputs like formatted datasets remains unreliable and is a key limitation.
- Prompt design choices have a direct impact on the fidelity of the simulated survey responses.
Where Pith is reading between the lines
- Such simulations could allow researchers to test survey questions on synthetic populations before running costly real surveys.
- Comparing LLM outputs to real data might help identify and mitigate demographic biases in language models.
- Extending the approach to new domains could provide quick insights into public opinion on emerging issues.
Load-bearing premise
That how closely the model outputs match the distributions in these eleven chosen datasets indicates whether they would produce useful and unbiased results in actual social science work.
What would settle it
Collect responses from a fresh survey on a topic outside the benchmark datasets and compare the conclusions drawn from real data versus LLM-generated data on the same questions.
Figures








read the original abstract
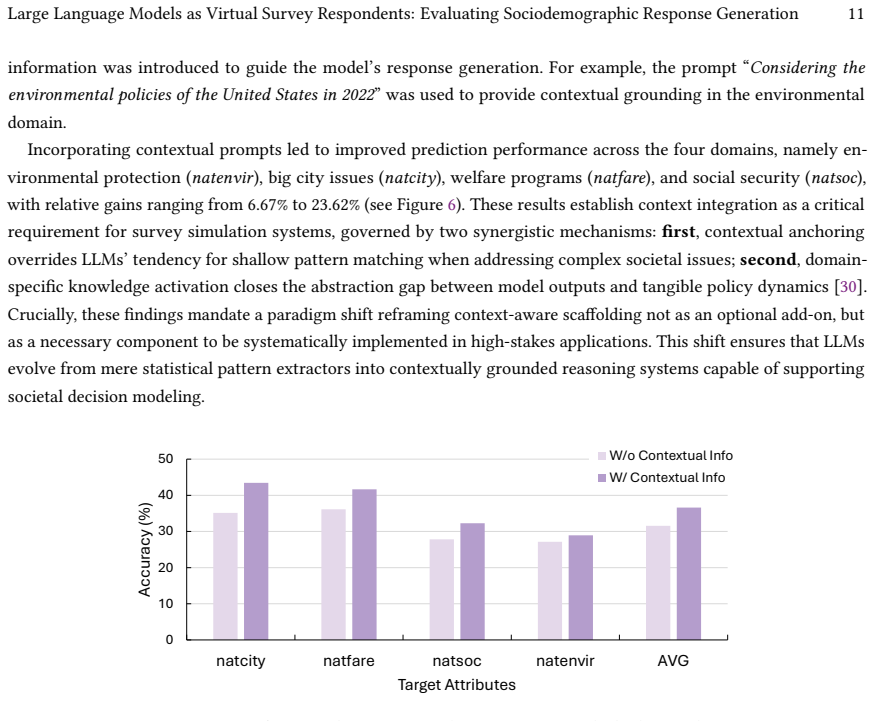
Questionnaire-based surveys are foundational to social science research and public policymaking, yet traditional survey methods remain costly, time-consuming, and often limited in scale. Although prior work has explored large language models (LLMs) as virtual survey respondents, existing studies often address narrow task settings, focus on single sociological domains, or lack a unified evaluation framework that enables systematic comparison across diverse datasets and models. To address these gaps, we introduce two complementary task abstractions: Partial Attribute Simulation (PAS), where LLMs predict missing attributes from incomplete respondent profiles, and Full Attribute Simulation (FAS), where LLMs generate complete synthetic datasets under zero-context and context-enhanced conditions. Both are framed as diagnostic and exploratory tools rather than replacements for human data collection. We curate LLM-S^3 (Large Language Model-based Sociodemographic Survey Simulation), a benchmark spanning 11 real-world public datasets across four sociological domains, and evaluate GPT-3.5/4 Turbo and LLaMA 3.0/3.1-8B under zero-shot and few-shot settings. Our evaluation reveals consistent performance trends across model families, highlights failure modes in structured output generation, and demonstrates how context and prompt design affect simulation fidelity. Our code and dataset are available at: https://github.com/dart-lab-research/LLM-S-Cube-Benchmark
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Partial Attribute Simulation (PAS) and Full Attribute Simulation (FAS) tasks to evaluate LLMs as virtual survey respondents. It curates the LLM-S^3 benchmark with 11 real-world public datasets across four sociological domains and evaluates GPT-3.5/4 Turbo and LLaMA 3.0/3.1-8B models under zero-shot and few-shot prompting, reporting consistent performance trends across model families, effects of context and prompt design on fidelity, and failure modes in structured output generation. The work positions these as diagnostic tools rather than replacements for human surveys, with public code and data released.
Significance. If the central empirical findings hold, the unified PAS/FAS framework and LLM-S^3 benchmark would provide a reproducible basis for comparing LLMs on sociodemographic simulation tasks, with value for identifying prompting strategies and output failures. The open release of code and datasets is a clear strength that supports follow-on work. However, the significance for social-science applications hinges on whether marginal distribution matching serves as a sufficient proxy for preserving joint distributions and avoiding LLM-induced biases.
major comments (2)
- [§4 and §5] §4 (Evaluation Framework) and §5 (Results): The fidelity metrics for both PAS and FAS appear to emphasize per-attribute accuracy or marginal distribution matches against the 11 source datasets. No results are shown for preservation of joint distributions (e.g., correlation matrices between sociodemographic variables or conditional probabilities). This is load-bearing for the claim of 'simulation fidelity' because marginal agreement can coexist with distorted correlations, which would limit utility in actual survey simulation.
- [§5.2] §5.2 (FAS experiments): The paper reports performance trends and prompt-design effects but does not include statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) on the differences across models, zero-shot vs. few-shot, or zero-context vs. context-enhanced conditions. Without these, it is difficult to determine whether the 'consistent performance trends' are robust or could be explained by prompt sensitivity.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the exact metrics (accuracy, KL divergence, etc.) used to quantify 'simulation fidelity' so readers can immediately assess the evaluation scope.
- [Results figures] Table captions and axis labels in the results figures should clarify whether reported values are averages over all 11 datasets or broken down by domain, to improve interpretability of the cross-model trends.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important aspects of evaluation that can strengthen the manuscript. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Evaluation Framework) and §5 (Results): The fidelity metrics for both PAS and FAS appear to emphasize per-attribute accuracy or marginal distribution matches against the 11 source datasets. No results are shown for preservation of joint distributions (e.g., correlation matrices between sociodemographic variables or conditional probabilities). This is load-bearing for the claim of 'simulation fidelity' because marginal agreement can coexist with distorted correlations, which would limit utility in actual survey simulation.
Authors: We agree that marginal distribution matching alone is insufficient to fully substantiate claims of simulation fidelity, as distorted correlations or conditional relationships could undermine utility for downstream survey applications. The current evaluation framework in §§4–5 prioritizes per-attribute accuracy and marginal matches to establish baseline performance across the heterogeneous LLM-S^3 benchmark. We will add joint-distribution analyses (correlation matrices and selected conditional probabilities) to the revised §5, computed on the same 11 datasets, to address this limitation directly. revision: yes
-
Referee: [§5.2] §5.2 (FAS experiments): The paper reports performance trends and prompt-design effects but does not include statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) on the differences across models, zero-shot vs. few-shot, or zero-context vs. context-enhanced conditions. Without these, it is difficult to determine whether the 'consistent performance trends' are robust or could be explained by prompt sensitivity.
Authors: The referee correctly notes that formal statistical tests would better establish the robustness of the reported trends. While the patterns held consistently across 11 datasets and multiple model families, we did not include significance testing in the original submission. In the revision we will add paired t-tests and bootstrap confidence intervals to the comparisons in §5.2, quantifying differences between models, zero-shot/few-shot settings, and context conditions. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation on external datasets
full rationale
The paper defines PAS and FAS as task abstractions, curates the LLM-S^3 benchmark from 11 independent real-world public datasets across sociological domains, and reports observed performance trends, failure modes, and effects of context/prompt design under zero-shot and few-shot settings for specific LLMs. No equations, fitted parameters renamed as predictions, self-citations, uniqueness theorems, or ansatzes appear in the provided text; all claims rest on direct comparison to external ground-truth distributions rather than any reduction to the paper's own inputs or prior author work. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world public survey datasets provide ground-truth distributions against which LLM outputs can be meaningfully compared.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce two complementary task abstractions: Partial Attribute Simulation (PAS) ... and Full Attribute Simulation (FAS) ... evaluated using a KL-based score ... and accuracy
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KL-Based Score ... Accuracy ... context and prompt design affect simulation fidelity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
From Demographics to Survey Anchors: Evaluating LLM Agents for Modeling Retirement Attitudes
Demographic-only LLM agents for retirement survey prediction exhibit central tendency bias, fail to reproduce incorrect or 'don't know' answers, and miss factor interactions in regressions, unlike survey-anchored agents.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
Lisa P. Argyle, Ethan C. Busby, Nancy Fulda, Joshua Gubler, Christopher Michael Rytting, and David Wingate. 2022. Out of One, Many: Using Language Models to Simulate Human Samples. CoRR abs/2209.06899 (2022). arXiv:2209.06899 doi:10.48550/ARXIV.2209.06899
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901
work page 2020
-
[5]
Yong Cao, Haijiang Liu, Arnav Arora, Isabelle Augenstein, Paul Röttger, and Daniel Hershcovich. 2025. Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies...
- [6]
-
[7]
Jin Chen, Zheng Liu, Xu Huang, Chenwang Wu, Qi Liu, Gangwei Jiang, Yuanhao Pu, Yuxuan Lei, Xiaolong Chen, Xingmei Wang, Kai Zheng, Defu Lian, and Enhong Chen. 2024. When large language models meet personalization: perspectives of challenges and opportunities. World Wide Web (WWW) 27, 4 (2024), 42. doi:10.1007/S11280-024-01276-1
-
[8]
Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Xia, Huanzhi Mao, et al. 2025. The danger of overthinking: Examining the reasoning-action dilemma in agentic tasks. arXiv preprint arXiv:2502.08235 (2025). Manuscript submitted to ACM Large Language Models as Virtual Survey Respondents...
-
[9]
Danica Dillion, Niket Tandon, Yuling Gu, and Kurt Gray. 2023. Can AI language models replace human participants? Trends in Cognitive Sciences 27, 7 (2023), 597–600
work page 2023
-
[10]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. 2024. A Survey on In-context Learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Compu...
-
[11]
Naoki Egami, Musashi Hinck, Brandon M Stewart, and Hanying Wei. 2024. Using Large Language Model Annotations for the Social Sciences: A General Framework of Using Predicted Variables in Downstream Analyses. ”. (2024)
work page 2024
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
-
[15]
Bernard J Jansen, Soon-gyo Jung, and Joni Salminen. 2023. Employing large language models in survey research. Natural Language Processing Journal 4 (2023), 100020
work page 2023
-
[16]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[17]
Junsol Kim and Byungkyu Lee. 2023. AI-Augmented Surveys: Leveraging Large Language Models and Surveys for Opinion Prediction. arXiv preprint arXiv:2305.09620 (2023)
work page Pith review arXiv 2023
-
[18]
Ehsan Lotfi, Maxime De Bruyn, Jeska Buhmann, and Walter Daelemans. 2024. PersonalityChat: Conversation Distillation for Personalized Dialog Modeling with Facts and Traits. CoRR abs/2401.07363 (2024). arXiv:2401.07363 doi:10.48550/ARXIV.2401.07363
-
[19]
Xinyi Mou, Xuanwen Ding, Qi He, Liang Wang, Jingcong Liang, Xinnong Zhang, Libo Sun, Jiayu Lin, Jie Zhou, Xuanjing Huang, and Zhongyu Wei
-
[20]
From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-based Agents. CoRR abs/2412.03563 (2024). arXiv:2412.03563 doi:10.48550/ARXIV.2412.03563
-
[21]
Man Tik Ng, Hui Tung Tse, Jen-tse Huang, Jingjing Li, Wenxuan Wang, and Michael R. Lyu. 2024. How Well Can LLMs Echo Us? Evaluating AI Chatbots’ Role-Play Ability with ECHO. CoRR abs/2404.13957 (2024). arXiv:2404.13957 doi:10.48550/ARXIV.2404.13957
-
[22]
Mateusz Ochal, Massimiliano Patacchiola, Jose Vazquez, Amos Storkey, and Sen Wang. 2023. Few-Shot Learning With Class Imbalance. IEEE Transactions on Artificial Intelligence 4, 5 (2023), 1348–1358. doi:10.1109/TAI.2023.3298303
-
[23]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems 35 (2022), 27730–27744
work page 2022
- [24]
-
[25]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Joon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie J. Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S. Bernstein. 2024. Generative Agent Simulations of 1,000 People. CoRR abs/2411.10109 (2024). arXiv:2411.10109 doi:10.48550/ARXIV.2411.10109
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.10109 2024
- [26]
-
[27]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems 36 (2023), 53728–53741
work page 2023
- [28]
- [29]
-
[30]
Hannes Rosenbusch, Claire E Stevenson, and Han LJ van der Maas. 2023. How accurate are GPT-3’s hypotheses about social science phenomena? Digital Society 2, 2 (2023), 26
work page 2023
-
[31]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications. CoRR abs/2402.07927 (2024). arXiv:2402.07927 doi:10.48550/ARXIV.2402.07927
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.07927 2024
-
[32]
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2024. LaMP: When Large Language Models Meet Personalization. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Associa...
work page 2024
-
[33]
Seungjong Sun, Eungu Lee, Dongyan Nan, Xiangying Zhao, Wonbyung Lee, Bernard J. Jansen, and Jang-Hyun Kim. 2024. Random Silicon Sampling: Simulating Human Sub-Population Opinion Using a Large Language Model Based on Group-Level Demographic Information. CoRR abs/2402.18144 (2024). arXiv:2402.18144 doi:10.48550/ARXIV.2402.18144 Manuscript submitted to ACM 1...
- [34]
- [35]
-
[36]
Xintao Wang, Yunze Xiao, Jen-tse Huang, Siyu Yuan, Rui Xu, Haoran Guo, Quan Tu, Yaying Fei, Ziang Leng, Wei Wang, et al. 2024. Incharacter: Evaluating personality fidelity in role-playing agents through psychological interviews. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1840–1873
work page 2024
-
[37]
Qiujie Xie, Qiming Feng, Tianqi Zhang, Qingqiu Li, Linyi Yang, Yuejie Zhang, Rui Feng, Liang He, Shang Gao, and Yue Zhang. 2025. Human Simulacra: Benchmarking the Personification of Large Language Models. In The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=BCP5nAHXqs
work page 2025
- [38]
-
[39]
Kaiqi Yang, Hang Li, Hongzhi Wen, Tai-Quan Peng, Jiliang Tang, and Hui Liu. 2024. Are Large Language Models (LLMs) Good Social Predictors?. In Findings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 2718–2730. doi:10.186...
-
[40]
Jiashu Yao, Heyan Huang, Zeming Liu, Haoyu Wen, Wei Su, Boao Qian, and Yuhang Guo. 2025. ReFF: Reinforcing Format Faithfulness in Language Models Across Varied Tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25660–25668
work page 2025
- [41]
-
[42]
Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Personalizing Dialogue Agents: I have a dog, do you have pets too?. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Iryna Gurevych and Yusuke Miyao (Eds.). Association for Computational Linguisti...
-
[43]
Muzhi Zhou, Lu Yu, Xiaomin Geng, and Lan Luo. 2024. ChatGPT vs Social Surveys: Probing the Objective and Subjective Human Society. CoRR abs/2409.02601 (2024). arXiv:2409.02601 doi:10.48550/ARXIV.2409.02601
-
[44]
Caleb Ziems, William Held, Omar Shaikh, Jiaao Chen, Zhehao Zhang, and Diyi Yang. 2024. Can large language models transform computational social science? Computational Linguistics 50, 1 (2024), 237–291. Manuscript submitted to ACM Large Language Models as Virtual Survey Respondents: Evaluating Sociodemographic Response Generation 15 A Experimental Details ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.