Capability-Aligned Hierarchical Learning for Tool-Augmented LLMs
Pith reviewed 2026-06-27 16:41 UTC · model grok-4.3
The pith
Joint optimization of planner and executor policies via RLVR produces better alignment than separate training in tool-augmented LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
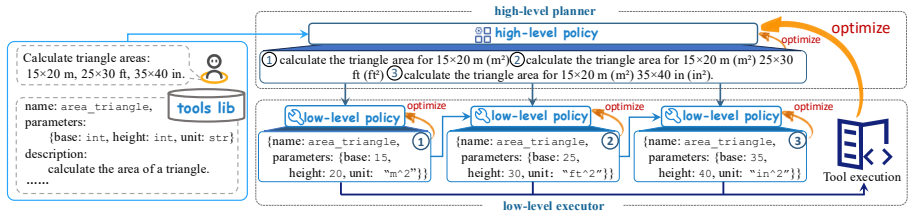
The paper claims that separate optimization of the high-level planner and low-level executor creates planner-executor misalignment that limits performance. By using RLVR to jointly optimize both policies, CAHL achieves better alignment between the planner and the executor, which improves results on tool-use tasks.
What carries the argument
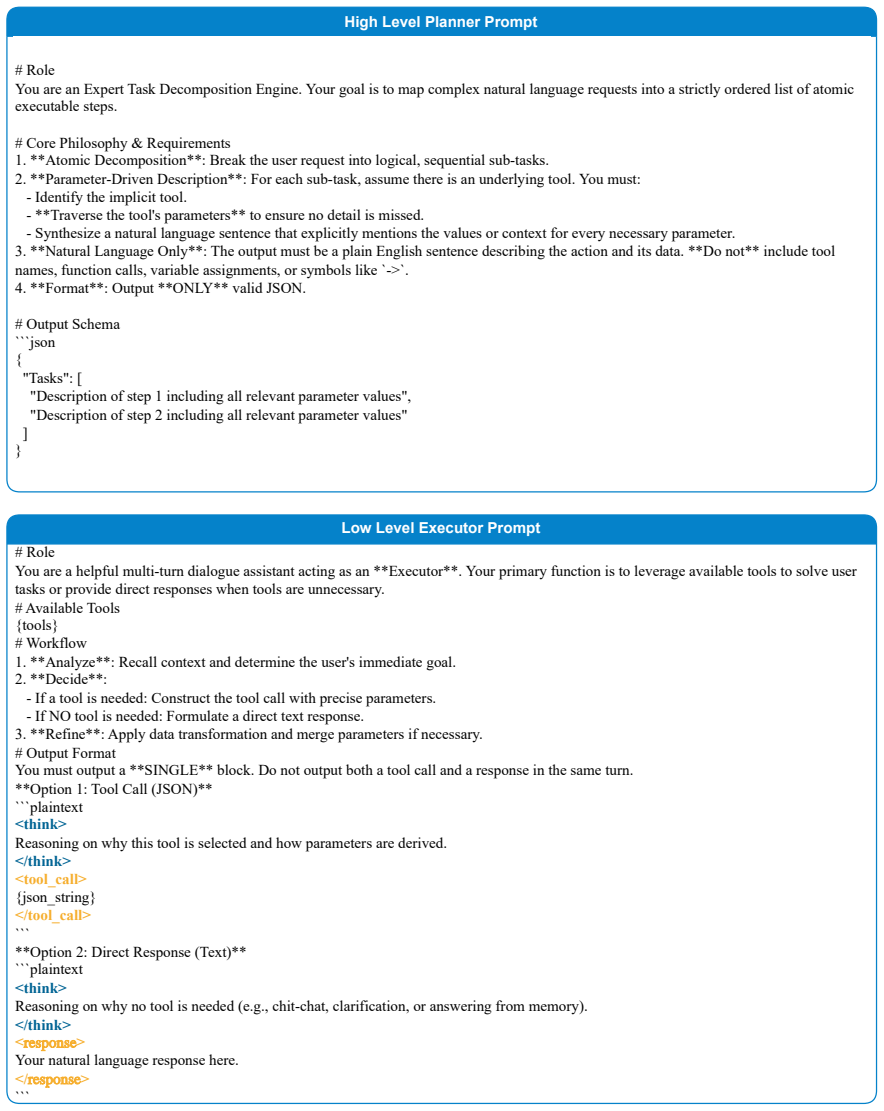
Capability-Aligned Hierarchical Learning (CAHL) that applies RLVR for joint optimization of the high-level planner and low-level executor policies.
If this is right
- Higher success rates on constrained tool-use benchmarks such as API-Bank and BFCL.
- Improved performance in open-ended environments such as Bamboogle.
- Reduced mismatch between high-level task decomposition and low-level tool invocations.
- A general route to stronger tool-use behavior through aligned rather than independent policy training.
Where Pith is reading between the lines
- The same joint-optimization pattern could be tested in other hierarchical LLM agents that separate planning from action.
- One could measure alignment directly by checking whether the sub-tasks chosen by the planner are actually solvable by the executor on held-out cases.
- If the gains depend on the specific form of RLVR, swapping in other joint-training signals would test whether alignment itself is the active ingredient.
- Dynamic tool sets that change between training and test time would reveal whether the learned alignment transfers beyond fixed benchmarks.
Load-bearing premise
Joint optimization through RLVR actually creates genuine alignment between the planner's and executor's capabilities rather than simply fitting the training examples in the chosen benchmarks.
What would settle it
A controlled comparison on a fresh tool-use benchmark whose task distribution differs from API-Bank, BFCL, and Bamboogle, showing no gain from joint optimization over separate training, would falsify the alignment claim.
Figures


read the original abstract
Tool learning enables LLMs to invoke external tools to accomplish tasks. Prior studies have demonstrated the effectiveness of a hierarchical structure: a high-level policy handles global planning and decomposes tasks into manageable sub-tasks, and a low-level policy focuses on invoking tools to solve these sub-tasks. However, these works typically optimize the high-level and low-level policies separately, leading to planner-executor misalignment and limiting LLM performance on tool-use tasks. In this paper, we propose a method called Capability-Aligned Hierarchical Learning (CAHL), which leverages RLVR to jointly optimize both policies, enabling better alignment between the high-level planner and the low-level executor. Experiments on constrained tool-use benchmarks (API-Bank and BFCL) and an open-ended environment (Bamboogle) demonstrate the effectiveness of CAHL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that separate optimization of high-level planner and low-level executor policies in hierarchical tool-augmented LLMs produces misalignment that limits performance. It proposes Capability-Aligned Hierarchical Learning (CAHL), which applies RLVR to jointly optimize both policies for improved alignment. Experiments on the constrained benchmarks API-Bank and BFCL plus the open-ended Bamboogle environment are reported to demonstrate effectiveness, with ablations comparing joint versus separate optimization.
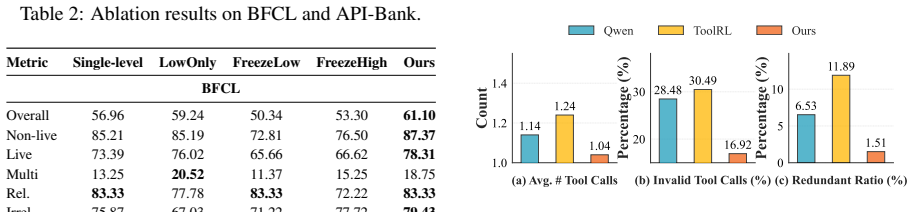
Significance. If the reported gains hold, the work addresses a concrete limitation in existing hierarchical tool-use methods by showing that joint RLVR optimization yields measurable improvements across both constrained and open-ended settings. The inclusion of ablations that isolate the joint-optimization component and the coverage of multiple benchmark types provide direct support for the alignment claim on the paper's own terms.
minor comments (3)
- [§4] §4 (Method): the precise definition and hyperparameter schedule of RLVR should be stated explicitly, including how the joint reward is constructed from planner and executor signals.
- [Tables 2-3] Table 2 and Table 3: report the number of random seeds and standard deviations for all metrics so that the magnitude of the joint-optimization gains can be assessed for robustness.
- [§5.3] §5.3 (Ablations): the separate-optimization baseline should be described with the same training budget and hyperparameter search effort as the joint CAHL run to ensure the comparison is controlled.
Simulated Author's Rebuttal
We thank the referee for the positive review, accurate summary of our contributions, and recommendation for minor revision. The assessment correctly identifies the core issue of planner-executor misalignment from separate optimization and the role of joint RLVR optimization in CAHL.
Circularity Check
No significant circularity; empirical method with independent experimental validation
full rationale
The paper proposes CAHL as a joint RLVR optimization procedure for planner-executor alignment in tool-augmented LLMs and supports the claim via experiments on API-Bank, BFCL, and Bamboogle with ablations comparing joint vs. separate optimization. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or method description that reduce any reported result to an input by construction. The derivation is self-contained as an empirical training procedure whose performance claims rest on external benchmark outcomes rather than definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- RLVR training hyperparameters
axioms (1)
- domain assumption Hierarchical decomposition plus separate optimization produces planner-executor misalignment that limits performance
Reference graph
Works this paper leans on
-
[1]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[2]
Frontiers of Computer Science , volume=
Tool learning with large language models: A survey , author=. Frontiers of Computer Science , volume=. 2025 , publisher=
2025
-
[3]
Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages=
StepTool: Enhancing Multi-Step Tool Usage in LLMs via Step-Grained Reinforcement Learning , author=. Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages=
-
[4]
Advances in Neural Information Processing Systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
ACM Computing Surveys , volume=
Tool learning with foundation models , author=. ACM Computing Surveys , volume=. 2024 , publisher=
2024
-
[6]
2024 , booktitle=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. 2024 , booktitle=
2024
-
[7]
2025 , booktitle=
ToolACE: Winning the Points of LLM Function Calling , author=. 2025 , booktitle=
2025
-
[8]
NAACL (Long Papers) , year=
xLAM: A Family of Large Action Models to Empower AI Agent Systems , author=. NAACL (Long Papers) , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Can a single model master both multi-turn conversations and tool use? coalm: A unified conversational agentic language model , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
2024
-
[12]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Agenttuning: Enabling generalized agent abilities for llms , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[13]
Torl: Scaling tool-integrated rl , author=. arXiv preprint arXiv:2503.23383 , year=
-
[14]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Sft memorizes, rl generalizes: A comparative study of foundation model post-training , author=. arXiv preprint arXiv:2501.17161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
ToolRL: Reward is All Tool Learning Needs
Toolrl: Reward is all tool learning needs , author=. arXiv preprint arXiv:2504.13958 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Tool Zero: Training Tool-Augmented LLMs via Pure RL from Scratch , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[19]
arXiv preprint arXiv:2509.14718 , year=
Toolsample: Dual dynamic sampling methods with curriculum learning for rl-based tool learning , author=. arXiv preprint arXiv:2509.14718 , year=
-
[20]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
itool: Reinforced fine-tuning with dynamic deficiency calibration for advanced tool use , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[21]
arXiv preprint arXiv:2410.04587 , year=
Hammer: Robust function-calling for on-device language models via function masking , author=. arXiv preprint arXiv:2410.04587 , year=
-
[22]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[23]
Nemotron-Research-Tool-N1: Exploring Tool-Using Language Models with Reinforced Reasoning , author=. arXiv preprint arXiv:2505.00024 , year=
-
[24]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[26]
It Takes Two: Your GRPO Is Secretly DPO
It Takes Two: Your GRPO Is Secretly DPO , author=. arXiv preprint arXiv:2510.00977 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Augmented Language Models: a Survey
Augmented language models: a survey , author=. arXiv preprint arXiv:2302.07842 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[29]
arXiv preprint arXiv:2403.15452 , year=
What are tools anyway? a survey from the language model perspective , author=. arXiv preprint arXiv:2403.15452 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Language models can solve computer tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
ART: Automatic multi-step reasoning and tool-use for large language models
Art: Automatic multi-step reasoning and tool-use for large language models , author=. arXiv preprint arXiv:2303.09014 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint arXiv:2203.05115 , year=
Internet-augmented language models through few-shot prompting for open-domain question answering , author=. arXiv preprint arXiv:2203.05115 , year=
-
[33]
Berkeley function calling leaderboard , author=
-
[34]
Easytool: Enhancing llm-based agents with concise tool instruction , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[35]
arXiv preprint arXiv:2510.01279 , year=
Tumix: Multi-agent test-time scaling with tool-use mixture , author=. arXiv preprint arXiv:2510.01279 , year=
-
[36]
Proceedings of the 34th ACM SIGPLAN International Conference on Compiler Construction , pages=
Llm compiler: Foundation language models for compiler optimization , author=. Proceedings of the 34th ACM SIGPLAN International Conference on Compiler Construction , pages=
-
[37]
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
Rewoo: Decoupling reasoning from observations for efficient augmented language models , author=. arXiv preprint arXiv:2305.18323 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Adapt: As-needed decomposition and planning with language models , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[39]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[40]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Measuring and narrowing the compositionality gap in language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.