Benchmarking Empirical Privacy Protection for Adaptations of Large Language Models
Pith reviewed 2026-06-27 17:12 UTC · model grok-4.3
The pith
The closer adaptation data is to an LLM's pretraining distribution, the higher its practical privacy risk under differential privacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
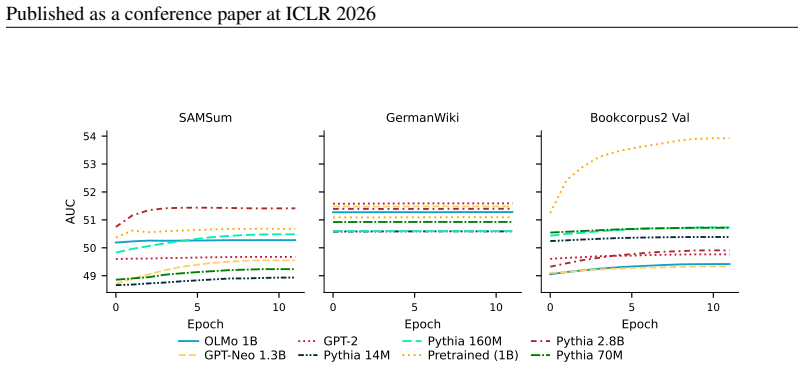
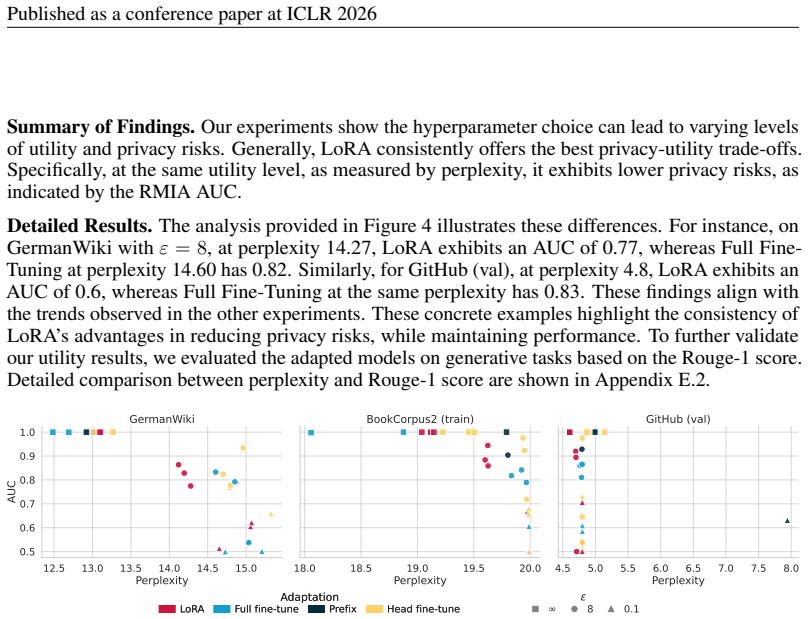
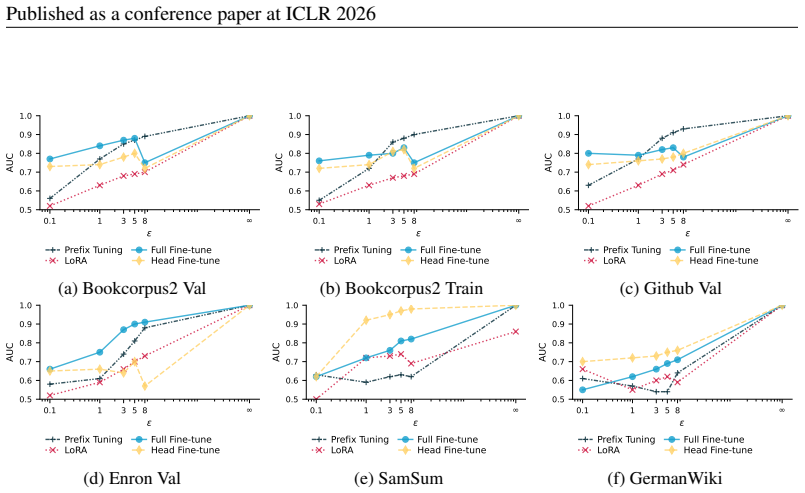
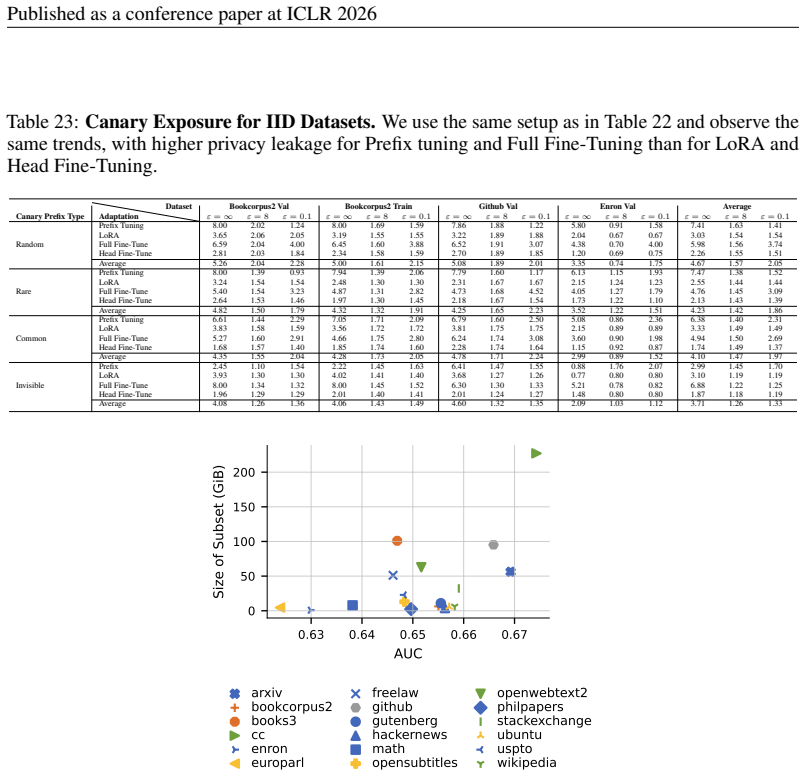
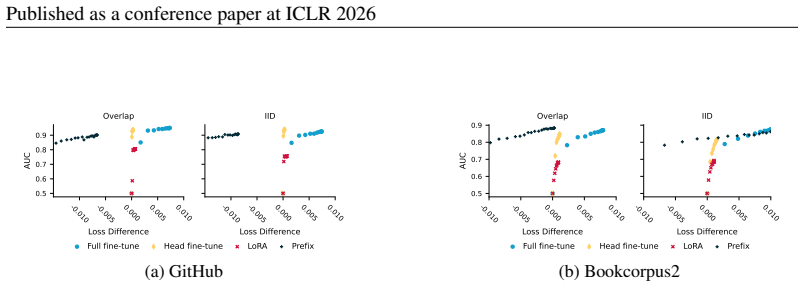
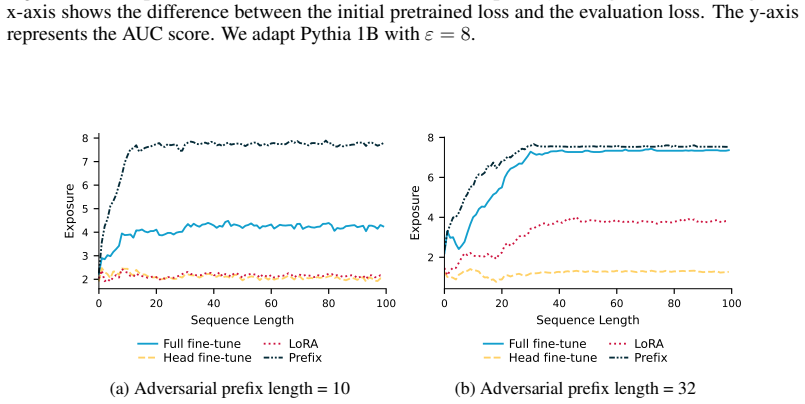
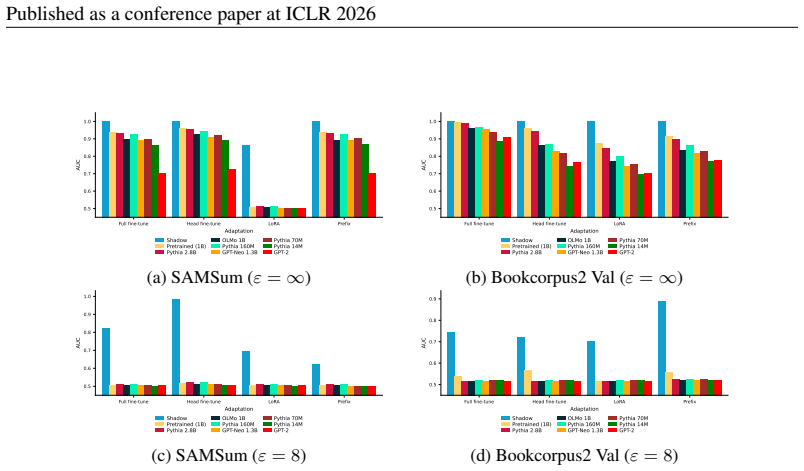
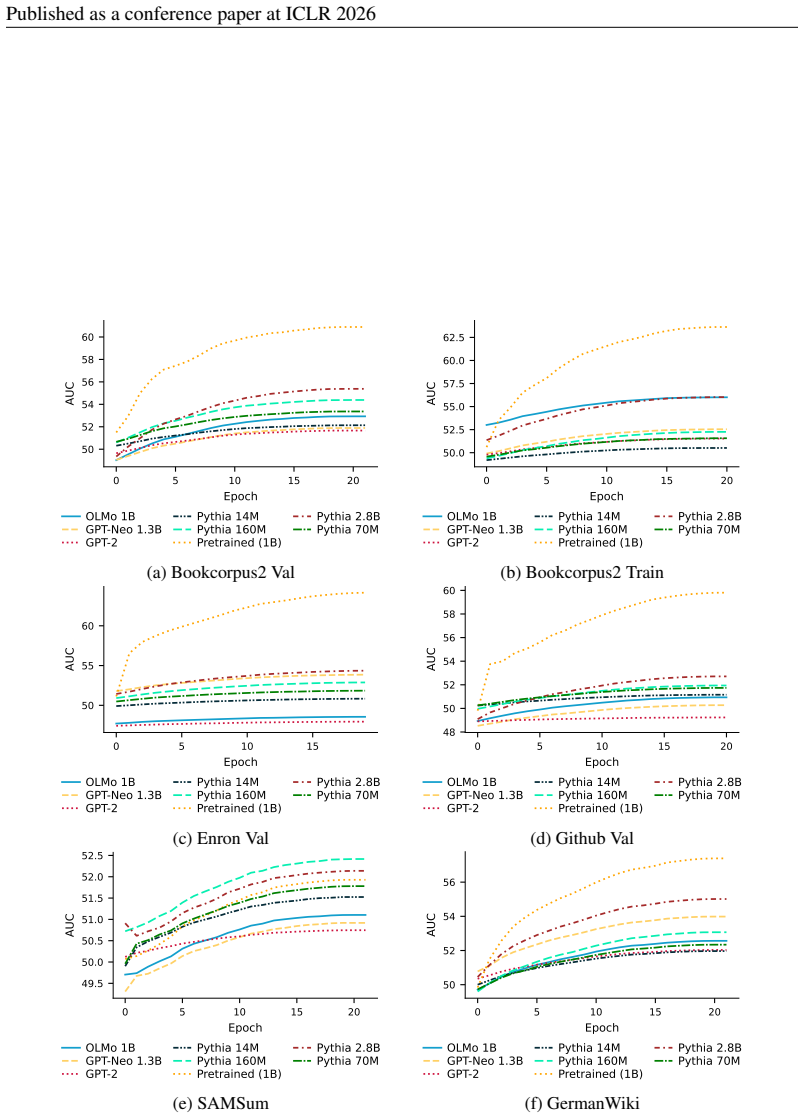
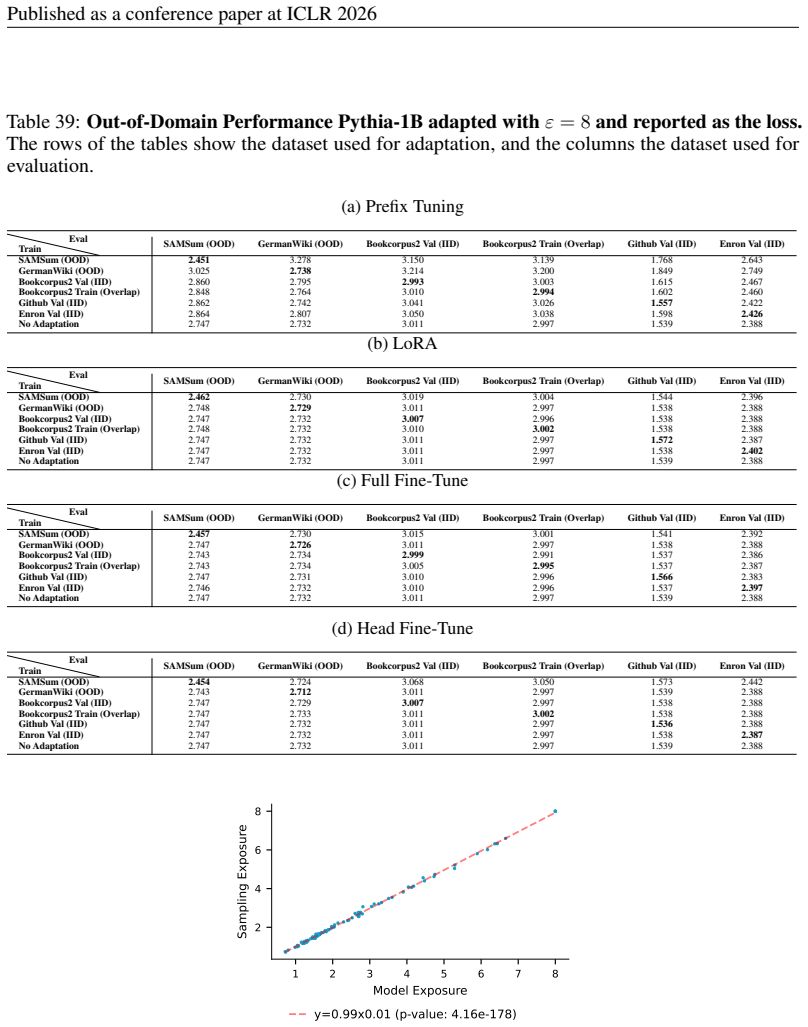
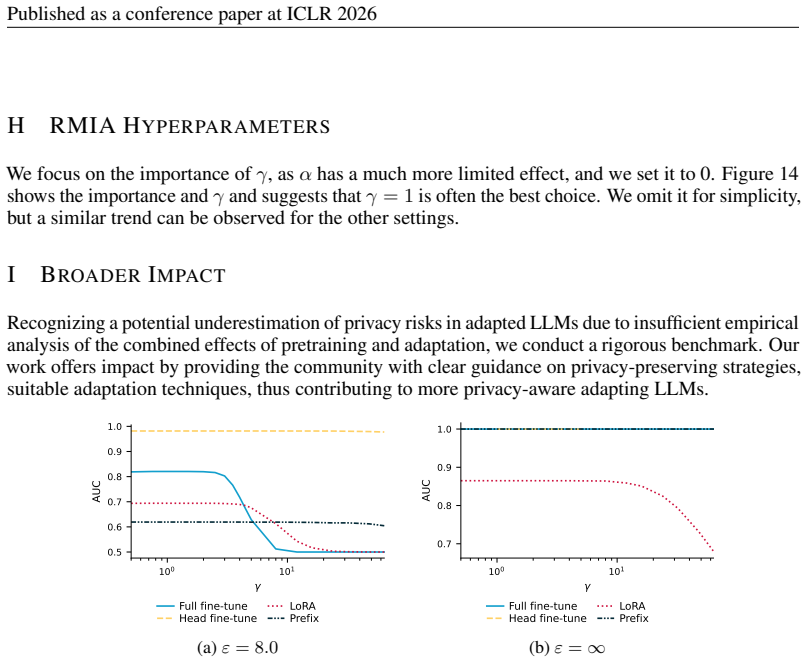
Distribution shifts strongly influence privacy vulnerability: the closer the adaptation data is to the pretraining distribution, the higher the practical privacy risk at the same theoretical guarantee, even without direct data overlap. Parameter-efficient fine-tuning methods such as LoRA achieve the highest empirical privacy protection for OOD data.
What carries the argument
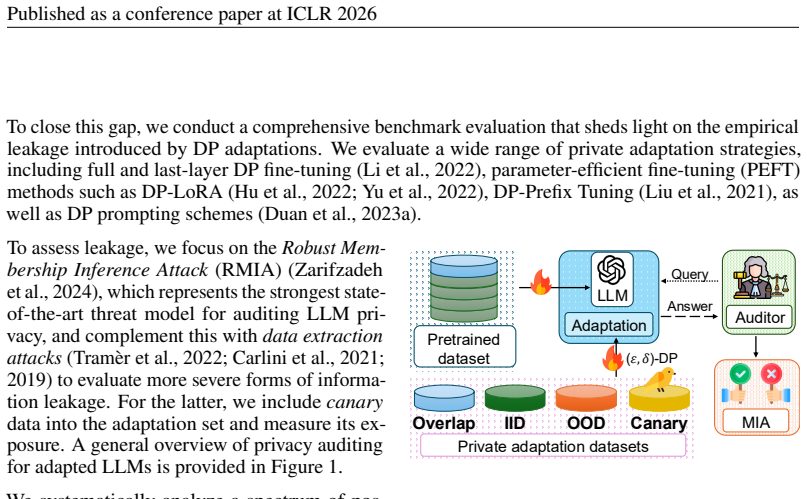
Controlled variation of adaptation data distribution (exact overlap, IID, OOD) combined with robust membership inference and canary extraction attacks to measure leakage after DP adaptation.
If this is right
- Practical privacy in DP LLM adaptation depends on how close the fine-tuning data is to pretraining data, not only on the privacy budget.
- LoRA and similar parameter-efficient methods deliver better empirical protection than full fine-tuning when adaptation data is out-of-distribution.
- Different adaptation methods and privacy regimes produce measurably different leakage under the same theoretical guarantee.
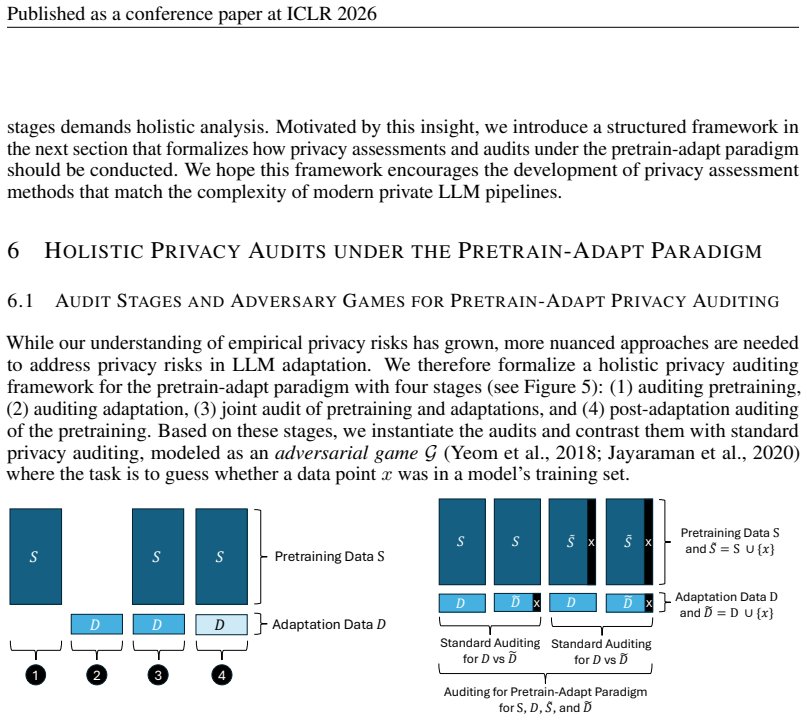
- A structured assessment that covers the full pretrain-adapt pipeline is needed to catch risks that adaptation-only checks miss.
Where Pith is reading between the lines
- Privacy evaluations for deployed LLMs should routinely test adaptation sets against estimated pretraining distributions rather than assuming uniform risk.
- If distribution closeness drives leakage, then techniques that deliberately push adaptation data further out-of-distribution could reduce risk without tightening the privacy budget.
- The proposed holistic framework could be applied to measure whether post-adaptation quantization or deployment steps introduce additional leakage channels.
Load-bearing premise
The chosen attacks reliably detect the extra leakage caused by distribution closeness, and distribution shift is the main driver of that leakage beyond the formal privacy parameter.
What would settle it
An experiment in which membership inference or canary extraction success rates show no increase as adaptation data moves closer to the pretraining distribution at fixed privacy budgets.
Figures

read the original abstract
Recent work has applied differential privacy (DP) to adapt large language models (LLMs) for sensitive applications, offering theoretical guarantees. However, its practical effectiveness remains unclear, partly due to LLM pretraining, where overlaps and interdependencies with adaptation data can undermine privacy despite DP efforts. To analyze this issue in practice, we investigate privacy risks under DP adaptations in LLMs using state-of-the-art attacks such as robust membership inference and canary data extraction. We benchmark these risks by systematically varying the adaptation data distribution, from exact overlaps with pretraining data, through in-distribution (IID) cases, to entirely out-of-distribution (OOD) examples. Additionally, we evaluate how different adaptation methods and different privacy regimes impact the vulnerability. Our results show that distribution shifts strongly influence privacy vulnerability: the closer the adaptation data is to the pretraining distribution, the higher the practical privacy risk at the same theoretical guarantee, even without direct data overlap. We find that parameter-efficient fine-tuning methods, such as LoRA, achieve the highest empirical privacy protection for OOD data. Our benchmark identifies key factors for achieving practical privacy in DP LLM adaptation, providing actionable insights for deploying customized models in sensitive settings. Looking forward, we propose a structured framework for holistic privacy assessment beyond adaptation privacy, to identify and evaluate risks across the full pretrain-adapt pipeline of LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical benchmarking study of privacy risks in differentially private (DP) adaptations of large language models. Using robust membership inference and canary data extraction attacks, it systematically varies adaptation data distributions (exact pretraining overlaps, IID, and OOD) while holding theoretical DP guarantees fixed, and also examines adaptation methods (e.g., LoRA) and privacy regimes. The central claim is that closer proximity of adaptation data to the pretraining distribution increases practical privacy leakage even without direct overlap, with LoRA providing the strongest empirical protection for OOD cases; a framework for holistic pretrain-adapt privacy assessment is proposed.
Significance. If the empirical patterns hold after full verification of methods and statistics, the work would be significant for sensitive LLM deployments: it demonstrates that theoretical DP epsilon is insufficient to predict practical risk and identifies distribution shift as a key modulator, offering concrete guidance on method choice (e.g., LoRA for OOD) and motivating broader pipeline-level privacy evaluation beyond adaptation alone.
major comments (2)
- [Abstract / Experimental Setup] Abstract and experimental design: the distribution-shift claim rests on the attacks surfacing genuine residual leakage rather than artifacts, yet the provided description lacks full attack implementations, data-overlap quantification, controls for adaptation hyperparameters (step count, LoRA rank), and statistical tests; these details are load-bearing for substantiating that proximity to pretraining increases empirical risk at fixed epsilon.
- [Results] Results reporting: directional trends are noted but without raw success rates, confidence intervals, or ablation on whether varying distribution is the dominant factor (vs. other confounders), the cross-distribution comparison cannot yet be treated as conclusive evidence.
minor comments (1)
- [Conclusion] The proposed holistic privacy framework is mentioned only at a high level; a concrete outline or pseudocode would improve actionability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical benchmarking of privacy risks in DP-adapted LLMs. We agree that greater transparency in attack details, data quantification, hyperparameter controls, statistical tests, and raw results reporting is needed to substantiate the distribution-shift claims. We will revise the manuscript to incorporate these elements.
read point-by-point responses
-
Referee: [Abstract / Experimental Setup] Abstract and experimental design: the distribution-shift claim rests on the attacks surfacing genuine residual leakage rather than artifacts, yet the provided description lacks full attack implementations, data-overlap quantification, controls for adaptation hyperparameters (step count, LoRA rank), and statistical tests; these details are load-bearing for substantiating that proximity to pretraining increases empirical risk at fixed epsilon.
Authors: We appreciate this observation. The manuscript describes the membership inference attack (loss-based with shadow models) and canary extraction (perplexity ranking), but we will expand the experimental setup with: full pseudocode in an appendix; quantitative overlap metrics (token Jaccard and 5-gram overlap between adaptation and pretraining sets); fixed controls (adaptation steps=5000, LoRA rank=8, same optimizer across all distribution variants); and paired t-tests with p-values on success rates. These additions will confirm the leakage differences arise from distribution proximity at fixed ε rather than implementation artifacts. revision: yes
-
Referee: [Results] Results reporting: directional trends are noted but without raw success rates, confidence intervals, or ablation on whether varying distribution is the dominant factor (vs. other confounders), the cross-distribution comparison cannot yet be treated as conclusive evidence.
Authors: We agree the current presentation focuses on trends. The revision will add tables reporting raw rates (MIA AUC/precision, canary extraction fraction), 95% bootstrap confidence intervals, and an ablation holding model, ε, steps, and rank fixed while varying only distribution (exact overlap vs. IID vs. OOD). This isolates distribution shift as the primary factor and strengthens the cross-distribution evidence. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical benchmarking study that evaluates privacy risks in DP-adapted LLMs by running membership inference and canary extraction attacks across controlled variations in adaptation data distribution (exact overlap, IID, OOD) while holding the theoretical DP guarantee fixed. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described experimental design; the central claim follows directly from the attack outcomes on the adapted models rather than reducing to any input quantity by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Differential privacy mechanisms applied during adaptation provide a quantifiable theoretical privacy guarantee that can be probed by membership inference and extraction attacks.
- domain assumption The pretraining distribution of the base LLM is fixed and known enough to allow controlled construction of adaptation datasets at varying distances from it.
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2024 , eprint=
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
2024
-
[5]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[6]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[7]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[8]
2024 , eprint=
2 OLMo 2 Furious , author=. 2024 , eprint=
2024
-
[9]
Preprint , year=
OLMo: Accelerating the Science of Language Models , author=. Preprint , year=
-
[10]
PrivAuditor: Benchmarking Data Protection Vulnerabilities in LLM Adaptation Techniques , url =
Zhu, Derui and Chen, Dingfan and Wu, Xiongfei and Geng, Jiahui and Li, Zhuo and Grossklags, Jens and Ma, Lei , booktitle =. PrivAuditor: Benchmarking Data Protection Vulnerabilities in LLM Adaptation Techniques , url =
-
[11]
2021 , eprint=
Bad Characters: Imperceptible NLP Attacks , author=. 2021 , eprint=
2021
-
[12]
2024 , eprint=
Detecting Pretraining Data from Large Language Models , author=. 2024 , eprint=
2024
-
[13]
32nd USENIX Security Symposium (USENIX Security 23) , pages=
Extracting training data from diffusion models , author=. 32nd USENIX Security Symposium (USENIX Security 23) , pages=
-
[14]
Proceedings of the 41st International Conference on Machine Learning , pages =
Position: Considerations for Differentially Private Learning with Large-Scale Public Pretraining , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[15]
Reynolds, Douglas. Gaussian Mixture Models. Encyclopedia of Biometrics. 2009. doi:10.1007/978-0-387-73003-5_196
-
[16]
Algorithmic Learning Theory , publisher =
Learning with Deep Cascades , isbn =. Algorithmic Learning Theory , publisher =. doi:10.1007/978-3-319-24486-0_17 , series =
-
[17]
Koltchinskii and D
V. Koltchinskii and D. Panchenko , title =. The Annals of Statistics , number =. 2002 , doi =
2002
-
[18]
Performance Measures for Neyman–Pearson Classification , volume =
Scott, Clayton , date =. Performance Measures for Neyman–Pearson Classification , volume =. doi:10.1109/TIT.2007.901152 , abstract =
-
[19]
arXiv preprint arXiv:1606.06565 , year=
Concrete problems in AI safety , author=. arXiv preprint arXiv:1606.06565 , year=
-
[20]
arXiv preprint arXiv:1807.01697 , year=
Benchmarking neural network robustness to common corruptions and surface variations , author=. arXiv preprint arXiv:1807.01697 , year=
-
[21]
arXiv preprint arXiv:1901.10513 , year=
Adversarial examples are a natural consequence of test error in noise , author=. arXiv preprint arXiv:1901.10513 , year=
Pith/arXiv arXiv 1901
-
[22]
Advances in Neural Information Processing Systems , volume=
Failing loudly: An empirical study of methods for detecting dataset shift , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Learning with Rejection , volume =
Cortes, Corinna and. Learning with Rejection , volume =. Algorithmic Learning Theory , publisher =. doi:10.1007/978-3-319-46379-7_5 , note =
-
[24]
2024 , note =
GPT-Image-1 , author =. 2024 , note =
2024
-
[25]
Scott, C. and Nowak, R. , date =. A Neyman-Pearson approach to statistical learning , volume =. doi:10.1109/TIT.2005.856955 , abstract =
-
[26]
Beyond Perturbations: Learning Guarantees with Arbitrary Adversarial Test Examples , url =
Goldwasser, Shafi and Kalai, Adam Tauman and Kalai, Yael and Montasser, Omar , booktitle =. Beyond Perturbations: Learning Guarantees with Arbitrary Adversarial Test Examples , url =
-
[27]
2019 , eprint=
Combining p-values via averaging , author=. 2019 , eprint=
2019
-
[28]
International Conference on Learning Representations , year=
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. International Conference on Learning Representations , year=
-
[29]
Fleet , title =
Sara Sabour and Yanshuai Cao and Fartash Faghri and David J. Fleet , title =. 4th International Conference on Learning Representations,. 2016 , url =
2016
-
[30]
International Conference on Machine Learning , pages=
On calibration of modern neural networks , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[31]
international conference on machine learning , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. international conference on machine learning , pages=. 2016 , organization=
2016
-
[32]
International Conference on Machine Learning , pages=
Weight uncertainty in neural network , author=. International Conference on Machine Learning , pages=. 2015 , organization=
2015
-
[33]
International Conference on Learning Representations , year=
DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION , author=. International Conference on Learning Representations , year=
-
[34]
arXiv preprint arXiv:2402.12819 , year=
Fine-Tuning, Prompting, In-Context Learning and Instruction-Tuning: How Many Labelled Samples Do We Need? , author=. arXiv preprint arXiv:2402.12819 , year=
-
[35]
arXiv preprint arXiv:2310.10508 , year=
Prompt Engineering or Fine Tuning: An Empirical Assessment of Large Language Models in Automated Software Engineering Tasks , author=. arXiv preprint arXiv:2310.10508 , year=
-
[36]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[37]
University of Cambridge , volume=
Uncertainty in deep learning , author=. University of Cambridge , volume=
-
[38]
arXiv preprint arXiv:1612.01474 , year=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. arXiv preprint arXiv:1612.01474 , year=
-
[39]
2019 IEEE Security and Privacy Workshops (SPW) , pages=
On the robustness of deep k-nearest neighbors , author=. 2019 IEEE Security and Privacy Workshops (SPW) , pages=. 2019 , organization=
2019
-
[40]
2020 IEEE Security and Privacy Workshops (SPW) , pages=
Minimum-Norm Adversarial Examples on KNN and KNN based Models , author=. 2020 IEEE Security and Privacy Workshops (SPW) , pages=. 2020 , organization=
2020
-
[41]
Summer school on machine learning , pages=
Gaussian processes in machine learning , author=. Summer school on machine learning , pages=. 2003 , organization=
2003
-
[42]
Evasion Attacks against Machine Learning at Test Time
Biggio, Battista and Corona, Igino and Maiorca, Davide and Nelson, Blaine and S rndi \' c , Nedim and Laskov, Pavel and Giacinto, Giorgio and Roli, Fabio. Evasion Attacks against Machine Learning at Test Time. Machine Learning and Knowledge Discovery in Databases. 2013
2013
-
[43]
arXiv preprint arXiv:1412.6572 , year=
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
-
[44]
Proceedings of the 36th International Conference on Machine Learning , pages =
The Odds are Odd: A Statistical Test for Detecting Adversarial Examples , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[45]
2014 , URL =
Intriguing properties of neural networks , author =. 2014 , URL =
2014
-
[46]
International Conference on Learning Representations , year=
Understanding the failure modes of out-of-distribution generalization , author=. International Conference on Learning Representations , year=
-
[47]
McDaniel , title =
Nicolas Papernot and Patrick D. McDaniel , title =. CoRR , volume =. 2018 , url =
2018
-
[48]
2009 , isbn =
Koller, Daphne and Friedman, Nir , title =. 2009 , isbn =
2009
-
[49]
Proceedings of the 36th International Conference on Machine Learning , pages =
Analyzing and Improving Representations with the Soft Nearest Neighbor Loss , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[50]
arXiv preprint arXiv:1610.02136 , year=
A baseline for detecting misclassified and out-of-distribution examples in neural networks , author=. arXiv preprint arXiv:1610.02136 , year=
-
[51]
arXiv preprint arXiv:2007.15147 , year=
Detecting Anomalous Inputs to DNN Classifiers By Joint Statistical Testing at the Layers , author=. arXiv preprint arXiv:2007.15147 , year=
arXiv 2007
-
[52]
, author=
To Trust Or Not To Trust A Classifier. , author=. NeurIPS , pages=
-
[53]
arXiv preprint arXiv:1910.00727 , year=
Analyzing and Improving Neural Networks by Generating Semantic Counterexamples through Differentiable Rendering , author=. arXiv preprint arXiv:1910.00727 , year=
arXiv 1910
-
[54]
arXiv preprint arXiv:2101.06549 , year=
AdvSim: Generating Safety-Critical Scenarios for Self-Driving Vehicles , author=. arXiv preprint arXiv:2101.06549 , year=
-
[55]
arXiv preprint arXiv:2103.07403 , year=
Generating and Characterizing Scenarios for Safety Testing of Autonomous Vehicles , author=. arXiv preprint arXiv:2103.07403 , year=
-
[56]
International Conference on Machine Learning , pages=
Delayed impact of fair machine learning , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[57]
arXiv preprint arXiv:1809.04684 , year=
Fair lending needs explainable models for responsible recommendation , author=. arXiv preprint arXiv:1809.04684 , year=
-
[58]
Black Hat , year=
Evading machine learning malware detection , author=. Black Hat , year=
-
[59]
arXiv preprint arXiv:1402.1389 , year=
Distributed variational inference in sparse Gaussian process regression and latent variable models , author=. arXiv preprint arXiv:1402.1389 , year=
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
Evaluating scalable bayesian deep learning methods for robust computer vision , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , pages=
-
[61]
arXiv preprint arXiv:2102.12967 , year=
Statistical Testing for Efficient Out of Distribution Detection in Deep Neural Networks , author=. arXiv preprint arXiv:2102.12967 , year=
-
[62]
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks , url =
Lee, Kimin and Lee, Kibok and Lee, Honglak and Shin, Jinwoo , booktitle =. A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks , url =
-
[63]
Llama3, https://ai.meta.com/blog/meta-llama-3/
-
[64]
Claude3, https://www.anthropic.com/news/claude-3-family
Anthropic , year=. Claude3, https://www.anthropic.com/news/claude-3-family
-
[65]
Cohere, https://cohere.ai
-
[66]
OpenAI, https://openai.com
-
[67]
2025 IEEE Security and Privacy Workshops (SPW) , pages=
Membership Inference Attacks on Sequence Models , author=. 2025 IEEE Security and Privacy Workshops (SPW) , pages=. 2025 , organization=
2025
-
[68]
ICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models , year=
Privacy Auditing for Large Language Models with Natural Identifiers , author=. ICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models , year=
2025
-
[69]
International Conference on Artificial Intelligence and Statistics , pages=
On the privacy risks of algorithmic recourse , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[70]
Auditing f -differential privacy in one run , author=
-
[71]
Sujet-finance-instruct-177k dataset
-
[72]
RunPod GPU Cloud pricing, https://www.runpod.io/gpu-instance/pricing
-
[73]
Zhang and A
Florian Tramèr and F. Zhang and A. Juels and M. Reiter and T. Ristenpart. , title=. USENIX Security Symposium , year=
-
[74]
Courville and P
Yoshua Bengio and A. Courville and P. Vincent. , title=. ArXiv , year=
-
[75]
Uchida and S
Yuki Nagai and Y. Uchida and S. Sakazawa and Shin’ichi Satoh. , title=. International Journal of Multimedia Information Retrieval, 7:3–16 , year=
-
[76]
Hengrui Jia and C. A. Choquette-Choo and V. Chandrasekaran and N. Papernot. , title=. USENIX Security Symposium , year=
-
[77]
Kornblith and M
Ting Chen and S. Kornblith and M. Norouzi and G. Hinton. , title=. International Conference on Machine Learning , year=
-
[78]
Fan and Y
Kaiming He and H. Fan and Y. Wu and S. Xie and R. Girshick. , title=. Computer Vision and Pattern Recognition , year=
-
[79]
Strub and F
Jean-Bastien Grill and F. Strub and F. Altché and C. Tallec and P. H. Richemond and E. Buchatskaya and C. Doersch and B. A. Pires and Z. D. Guo and M. G. Azar and B. Piot and K. Kavukcuoglu and R. Munos and M. Valko. , title=. Computer Vision and Pattern Recognition , year=
-
[80]
Jialong Zhang and Zhongshu Gu and Jiyong Jang and Hui Wu and M. P. Stoecklin and H. Huang and I. Molloy. , title=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.