TheoremBench: Evaluating LLMs on Theorem Proving in Formal Mathematics
Pith reviewed 2026-06-27 16:17 UTC · model grok-4.3
The pith
Explicit premises raise success rates for Lean4 theorem provers on classical theorems
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
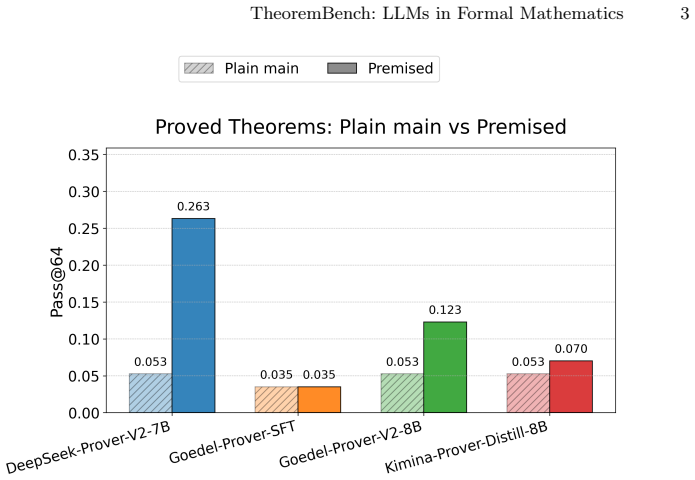
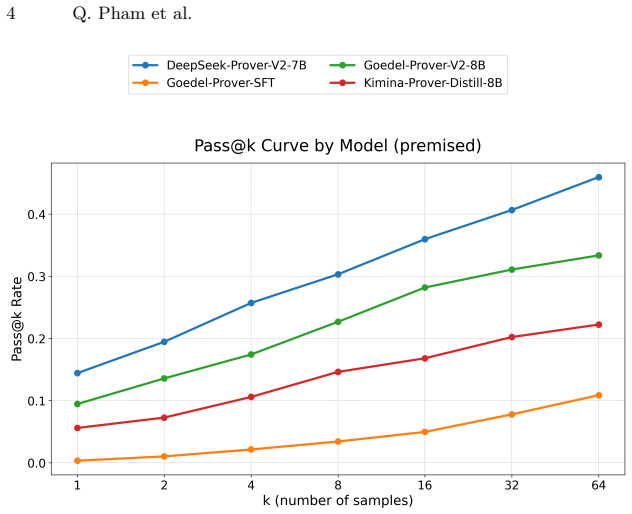
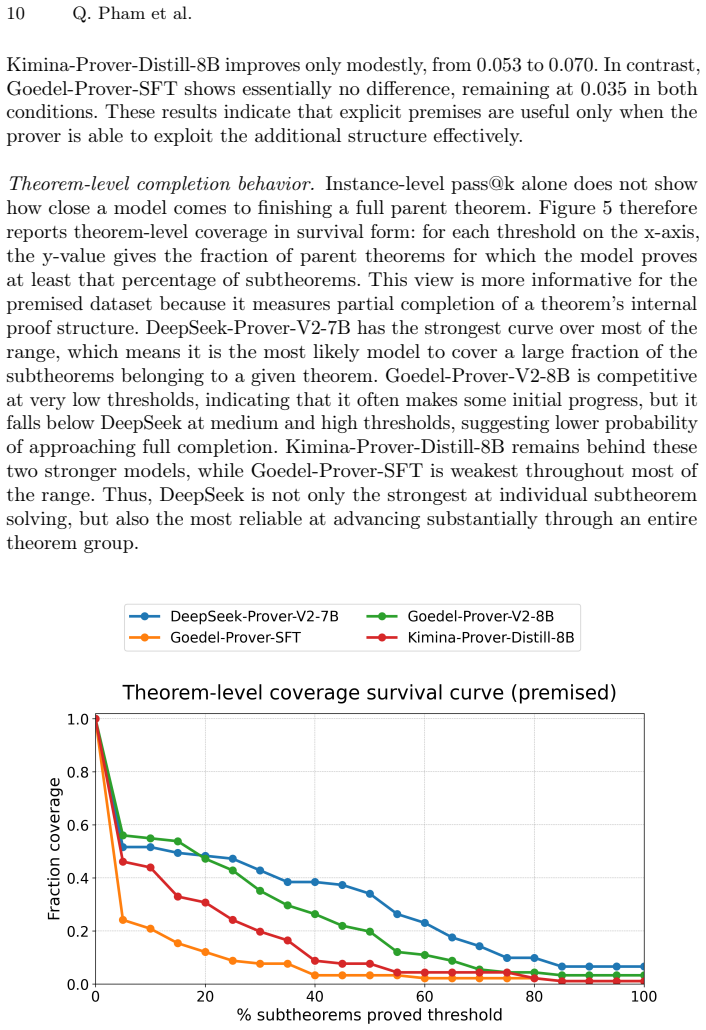
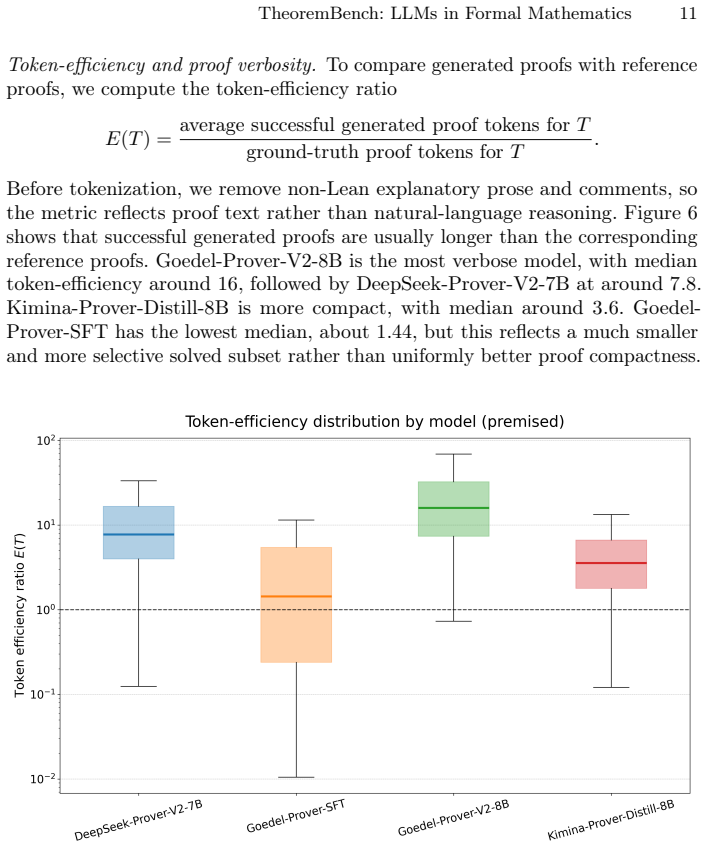
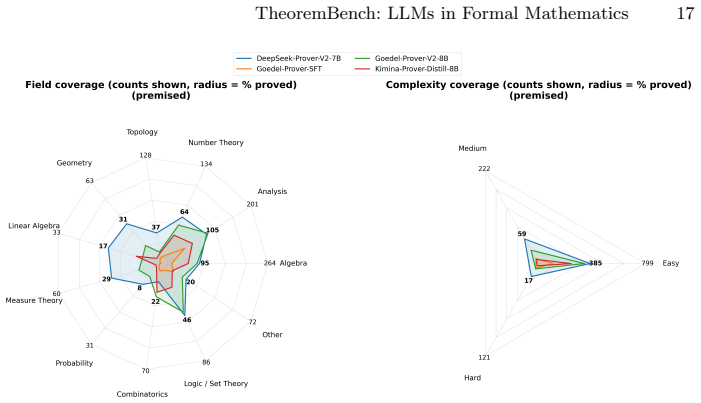
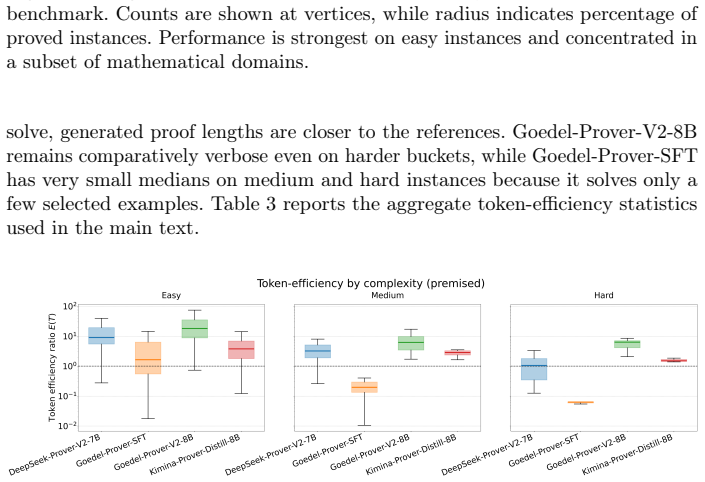
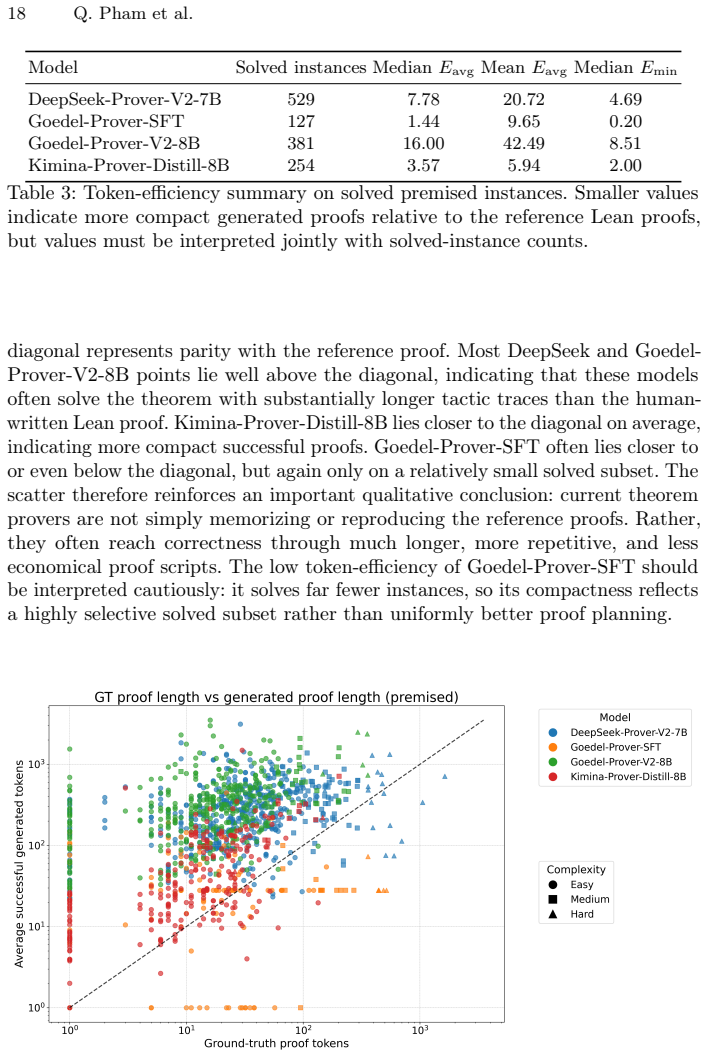
TheoremBench supplies classical theorems in a plain version and a premised version built from automatically extracted supporting subtheorems. Lean4 prover models record markedly higher proof rates on the premised versions. The same models remain biased toward easy subtheorems and solve tasks via long, inefficient tactic traces rather than compact proof plans. Theorem-level coverage and token-efficiency metrics make these qualitative differences measurable.
What carries the argument
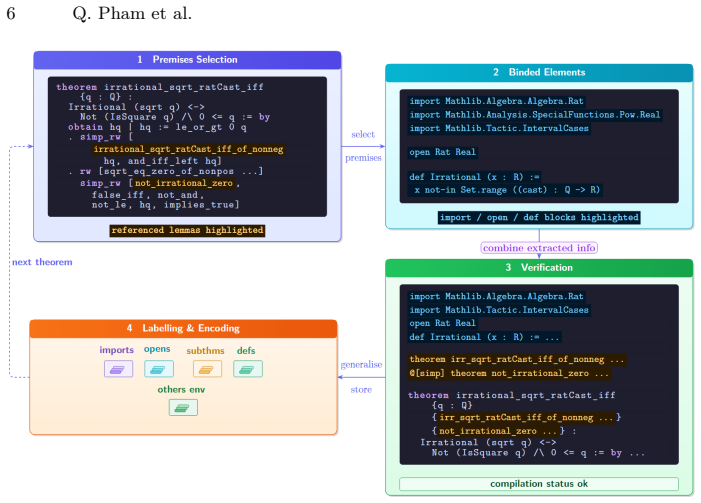
TheoremBench premised version, which expands each target theorem into a structured family of the main statement plus its automatically extracted supporting subtheorems
If this is right
- Models record higher proof success when given explicit supporting subtheorems.
- Provers exhibit clear bias toward easy subtheorems over harder ones.
- Proof generation favors long tactic traces rather than compact plans.
- Coverage and token-efficiency metrics distinguish proof behavior beyond binary success or failure.
Where Pith is reading between the lines
- Benchmarks for formal theorem proving should include dependency information as a standard feature to expose structural reasoning limits.
- Refining the automatic extraction process could produce even larger gains if extraction accuracy improves.
- The observed bias toward easy subtheorems may appear in other formal systems when similar structured benchmarks are created.
Load-bearing premise
The automatically extracted supporting subtheorems correctly capture each theorem's internal proof dependencies without errors or irrelevant additions.
What would settle it
Manual inspection of the extracted subtheorems showing frequent inaccuracies or irrelevancies that directly explain the reported performance gains would falsify the claim that premises aid reasoning rather than supply shortcuts.
Figures

read the original abstract
LLMs have recently achieved strong results on formal proving benchmarks. However, existing evaluations remain heavily concentrated on competition-style problems and often fail to capture how models behave on longer, more dependency-rich mathematical developments. We introduce TheoremBench, a Lean4 benchmark designed to evaluate theorem provers beyond contest settings. The benchmark is built from nearly one hundred classical theorems and is released in two complementary forms: a plain main version containing one target theorem per instance, and a premised version that expands each theorem into a structured family of related proving tasks consisting of the main theorem together with automatically extracted supporting subtheorems. This design enables evaluation of not only whether the final theorem was proved from scratch, but also of partial progress through the internal proof structure of a theorem. Our experiments show that explicit premises substantially improve performance for Lean4-capable prover models. To provide a comprehensive evaluation, we introduce theorem-level coverage and token-efficiency metrics that expose qualitative differences in proof behavior. The results show that current provers remain strongly biased toward easy subtheorems and often solve theorems through long and inefficient tactic traces rather than compact proof plans. TheoremBench therefore provides a more fine-grained view of formal reasoning ability and highlights the importance of structural benchmark design for evaluating Lean4 theorem provers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TheoremBench, a Lean4 benchmark built from nearly 100 classical theorems, released in a plain main version and a premised version that augments each target with automatically extracted supporting subtheorems. Experiments claim that explicit premises substantially improve performance for Lean4-capable prover models; new theorem-level coverage and token-efficiency metrics reveal that current provers are biased toward easy subtheorems and produce long, inefficient tactic traces rather than compact proofs.
Significance. If the subtheorem extraction faithfully reflects internal proof dependencies, the benchmark supplies a structured, dependency-aware evaluation that goes beyond competition-style problems and exposes qualitative limitations in existing provers. The work is an empirical benchmark contribution with no machine-checked proofs or parameter-free derivations.
major comments (3)
- [Abstract / benchmark construction] Abstract and benchmark-construction description: the claim that 'explicit premises substantially improve performance' and that provers are 'strongly biased toward easy subtheorems' rests on the premised version faithfully decomposing each theorem into its actual proof dependencies. The text states only that subtheorems are 'automatically extracted' and provides no procedure, error analysis, comparison to human-curated Lean proofs, or validation that irrelevant lemmas or missing dependencies have not been introduced.
- [Experiments] Experiments and evaluation sections: no details are given on theorem selection criteria, the precise model versions or prover configurations tested, the number of runs, or statistical significance testing for the reported performance gains. These omissions leave the quantitative claims without verifiable support.
- [Metrics] Metrics definition: the new 'theorem-level coverage' and 'token-efficiency' metrics are introduced to expose qualitative differences, yet the paper does not demonstrate that these metrics are robust to variations in the (unvalidated) subtheorem extraction or that they correlate with human judgments of proof quality.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from an explicit statement of the total number of theorems and the distribution of their dependency depths.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on TheoremBench. The comments identify important gaps in documentation and validation that we will address in revision. Below we respond point-by-point to the three major comments.
read point-by-point responses
-
Referee: [Abstract / benchmark construction] Abstract and benchmark-construction description: the claim that 'explicit premises substantially improve performance' and that provers are 'strongly biased toward easy subtheorems' rests on the premised version faithfully decomposing each theorem into its actual proof dependencies. The text states only that subtheorems are 'automatically extracted' and provides no procedure, error analysis, comparison to human-curated Lean proofs, or validation that irrelevant lemmas or missing dependencies have not been introduced.
Authors: We agree that the manuscript currently provides insufficient detail on the automatic extraction process. The revised version will add a dedicated subsection describing the dependency-analysis algorithm used to extract supporting subtheorems, an error analysis performed on a random sample of theorems, and a direct comparison against manually inspected Lean proofs from standard mathematical libraries. These additions will substantiate that the extracted premises correspond to genuine proof dependencies. revision: yes
-
Referee: [Experiments] Experiments and evaluation sections: no details are given on theorem selection criteria, the precise model versions or prover configurations tested, the number of runs, or statistical significance testing for the reported performance gains. These omissions leave the quantitative claims without verifiable support.
Authors: We accept that the experimental protocol requires fuller specification. The revision will explicitly state the criteria used to select the classical theorems, list the exact model checkpoints and prover configurations, report the number of independent runs, and include statistical significance tests (e.g., bootstrap confidence intervals or paired tests) for all performance differences. revision: yes
-
Referee: [Metrics] Metrics definition: the new 'theorem-level coverage' and 'token-efficiency' metrics are introduced to expose qualitative differences, yet the paper does not demonstrate that these metrics are robust to variations in the (unvalidated) subtheorem extraction or that they correlate with human judgments of proof quality.
Authors: The metrics are intended as exploratory tools to surface qualitative behaviors not captured by binary success. We will add a short robustness analysis examining how coverage and efficiency scores change under controlled perturbations of the extracted premise sets, together with illustrative examples that align the metric values with human-readable notions of proof compactness. A comprehensive human correlation study lies beyond the scope of the current revision but can be noted as future work. revision: partial
Circularity Check
No circularity: empirical benchmark evaluation with direct observations
full rationale
The paper introduces TheoremBench as a new Lean4 dataset from classical theorems and reports performance metrics from running existing prover models on its plain and premised versions. No equations, fitted parameters, or derived predictions appear. The central claims (premises improve performance; bias toward easy subtheorems) are presented as direct empirical outcomes from the benchmark runs, not as outputs of any internal derivation or self-referential construction. Automatic subtheorem extraction is described at a high level but is not used to derive the reported results by construction; any validation gap is a correctness issue, not circularity. No self-citations are load-bearing for the main claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lean4 is a sound and usable formal system for expressing and checking mathematical theorems
invented entities (3)
-
TheoremBench (main and premised versions)
no independent evidence
-
theorem-level coverage metric
no independent evidence
-
token-efficiency metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Avigad, J., De Moura, L., Kong, S.: Theorem proving in lean (2021)
2021
- [2]
-
[3]
Azerbayev, Z., Schoelkopf, H., Paster, K., Dos Santos, M., McAleer, S., Jiang, A.Q., Deng, J., Biderman, S., Welleck, S.: Llemma: An open language model for mathematics (2023),https://arxiv.org/abs/2310.10631
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [4]
-
[5]
Research Re- port RT-0203, INRIA (May 1997),https://inria.hal.science/inria-00069968, projet COQ
Barras, B., Boutin, S., Cornes, C., Courant, J., Filliâtre, J.C., Giménez, E., Herbelin, H., Huet, G., Muñoz, C., Murthy, C., Parent, C., Paulin-Mohring, C., Saïbi, A., Werner, B.: The Coq Proof Assistant Reference Manual : Version 6.1. Research Re- port RT-0203, INRIA (May 1997),https://inria.hal.science/inria-00069968, projet COQ
1997
-
[6]
Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H.P., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F.P., Cummings, D., Plappert, M., Chan...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
mathlib Community, T.: The lean mathematical library. In: Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs. p. 367–381. CPP 2020, Association for Computing Machinery, New York, NY, USA (2020). https://doi.org/10.1145/3372885.3373824, https://doi.org/10. 1145/3372885.3373824
- [8]
-
[9]
Gauthier, T., Kaliszyk, C., Urban, J.: Learning to reason with hol4 tactics (2018), https://arxiv.org/abs/1804.00595
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [10]
-
[11]
Huang, D., Dhariwal, P., Song, D., Sutskever, I.: Gamepad: A learning environment for theorem proving (2018),https://arxiv.org/abs/1806.00608
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [12]
-
[13]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=SMa9EAovKMC
Jiang, A.Q., Welleck, S., Zhou, J.P., Lacroix, T., Liu, J., Li, W., Jamnik, M., Lample, G., Wu, Y.: Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=SMa9EAovKMC
2023
- [14]
- [15]
-
[16]
Li, Z., Sun, J., Murphy, L., Su, Q., Li, Z., Zhang, X., Yang, K., Si, X.: A survey on deep learning for theorem proving (2024),https://arxiv.org/abs/2404.09939 14 Q. Pham et al
- [17]
-
[18]
Lin, Y., Tang, S., Lyu, B., Yang, Z., Chung, J.H., Zhao, H., Jiang, L., Geng, Y., Ge, J., Sun, J., Wu, J., Gesi, J., Lu, X., Acuna, D., Yang, K., Lin, H., Choi, Y., Chen, D., Arora, S., Jin, C.: Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction (2025),https://arxiv.org/abs/2508.03613
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Liu, C., Shen, J., Xin, H., Liu, Z., Yuan, Y., Wang, H., Ju, W., Zheng, C., Yin, Y., Li, L., Zhang, M., Liu, Q.: Fimo: A challenge formal dataset for automated theorem proving (2023)
2023
-
[20]
Liu, J., Lin, X., Bayer, J., Dillies, Y., Jiang, W., Liang, X., Soletskyi, R., Wang, H., Xie, Y., Xiong, B., Yang, Z., Zhang, J., Zhi, L., Li, J., Liu, Z.: Combibench: Benchmarking llm capability for combinatorial mathematics (2025),https://arxiv. org/abs/2505.03171
- [21]
-
[22]
Moura, L.d., Ullrich, S.: The lean 4 theorem prover and programming language. In: Automated Deduction – CADE 28: 28th International Conference on Automated De- duction, Virtual Event, July 12–15, 2021, Proceedings. p. 625–635. Springer-Verlag, Berlin, Heidelberg (2021). https://doi.org/10.1007/978-3-030-79876-5_37, https://doi.org/10.1007/978-3-030-79876-5_37
- [23]
-
[24]
Lecture Notes in Computer Science, Springer (1994),https://books.google.ru/books?id=RxlhqG0-cGwC
Paulson, L.: Isabelle: A Generic Theorem Prover. Lecture Notes in Computer Science, Springer (1994),https://books.google.ru/books?id=RxlhqG0-cGwC
1994
-
[25]
Polu, S., Sutskever, I.: Generative language modeling for automated theorem proving (2020),https://arxiv.org/abs/2009.03393
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[26]
Ren, Z.Z., Shao, Z., Song, J., Xin, H., Wang, H., Zhao, W., Zhang, L., Fu, Z., Zhu, Q., Yang, D., Wu, Z.F., Gou, Z., Ma, S., Tang, H., Liu, Y., Gao, W., Guo, D., Ruan, C.: Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition (2025),https://arxiv.org/abs/2504.21801
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [27]
- [28]
- [29]
-
[30]
Wang, H., Unsal, M., Lin, X., Baksys, M., Liu, J., Santos, M.D., Sung, F., Vinyes, M., Ying, Z., Zhu, Z., Lu, J., Saxcé, H.d., Bailey, B., Song, C., Xiao, C., Zhang, D., Zhang, E., Pu, F., Zhu, H., Liu, J., Bayer, J., Michel, J., Yu, L., Dreyfus-Schmidt, L., Tunstall, L., Pagani, L., Machado, M., Bourigault, P., Wang, R., Polu, S., Barroyer, T., Li, W.D.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [31]
-
[32]
Weng, K., Du, L., Li, S., Lu, W., Sun, H., Liu, H., Zhang, T.: Autoformalization in the era of large language models: A survey (2025),https://arxiv.org/abs/2505. 23486
2025
-
[33]
Wiedijk, F.: 100 theorems in lean,https://leanprover-community.github.io/ 100.html
- [34]
- [35]
-
[36]
Xin, H., Ren, Z.Z., Song, J., Shao, Z., Zhao, W., Wang, H., Liu, B., Zhang, L., Lu, X., Du, Q., Gao, W., Zhang, H., Zhu, Q., Yang, D., Wu, Z.F., Luo, F., Ruan, C.: Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search (2024),https://arxiv.org/abs/2408.08152
- [37]
-
[38]
Yang, K., Deng, J.: Learning to prove theorems via interacting with proof assistants (2019),https://arxiv.org/abs/1905.09381
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [39]
- [40]
- [41]
- [42]
-
[43]
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics
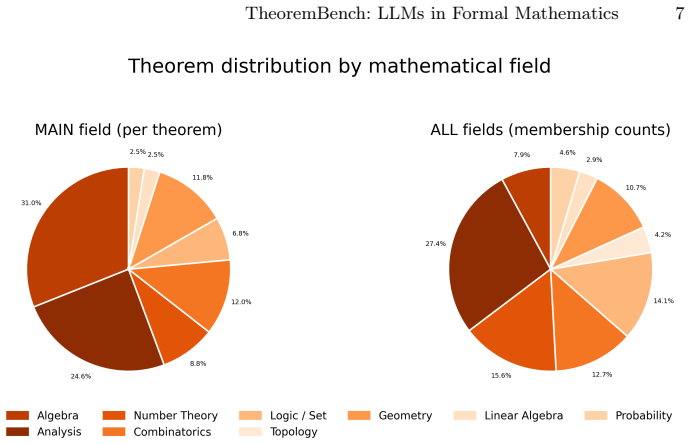
Zheng, K., Han, J.M., Polu, S.: Minif2f: a cross-system benchmark for formal olympiad-level mathematics (2022),https://arxiv.org/abs/2109.00110 16 Q. Pham et al. A Appendix A.1 Dataset Distribution In total, TheoremBench contains 1,142 Lean4 proving instances across the processed theorem groups. Table 2 summarizes the size of the extracted proof structure...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.