Emergence of Context Characteristics Sensitivity in Large Language Models
Pith reviewed 2026-06-27 16:22 UTC · model grok-4.3
The pith
Context sensitivity in large language models emerges and shifts during successive instruction fine-tuning stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
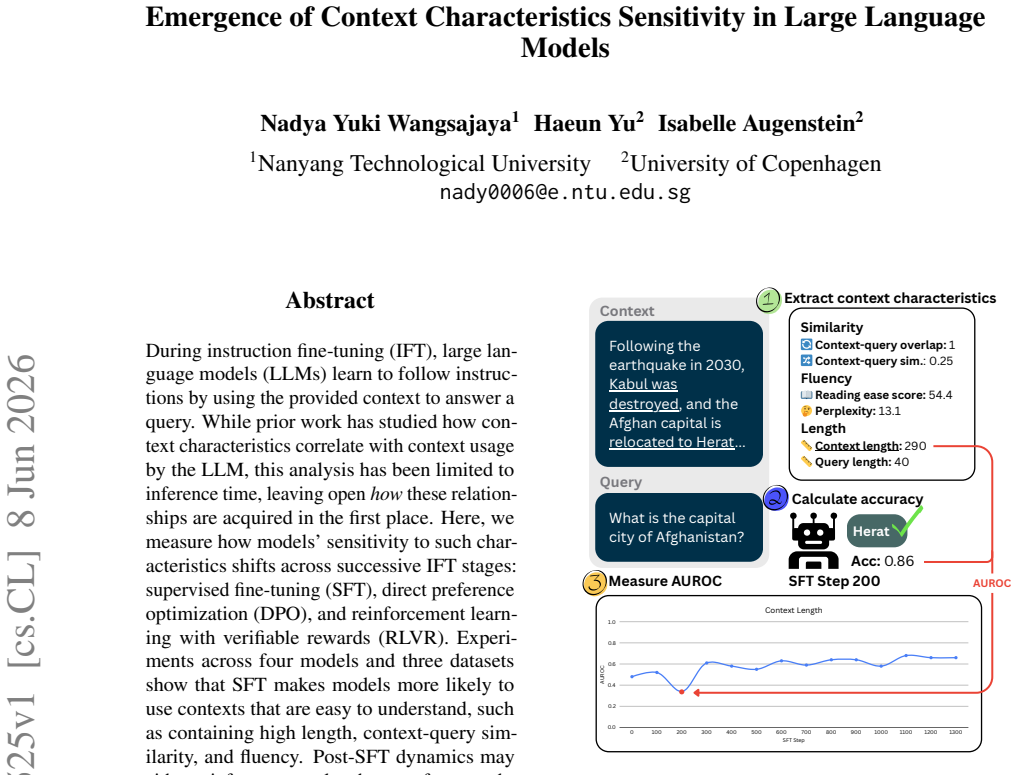
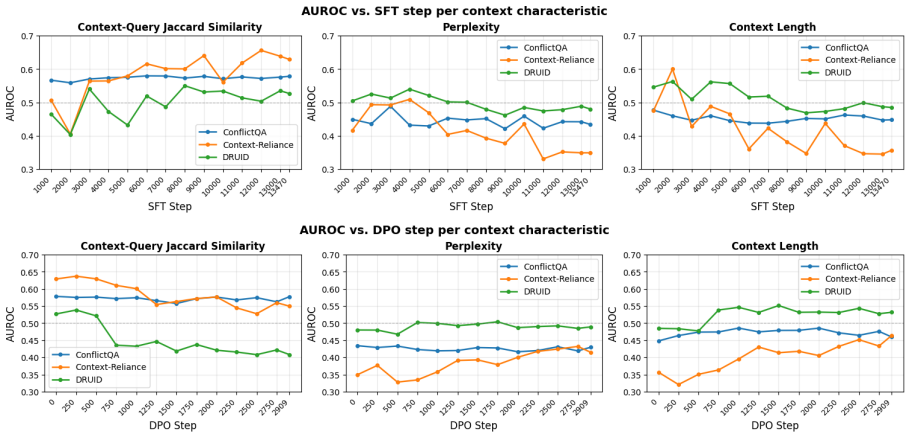
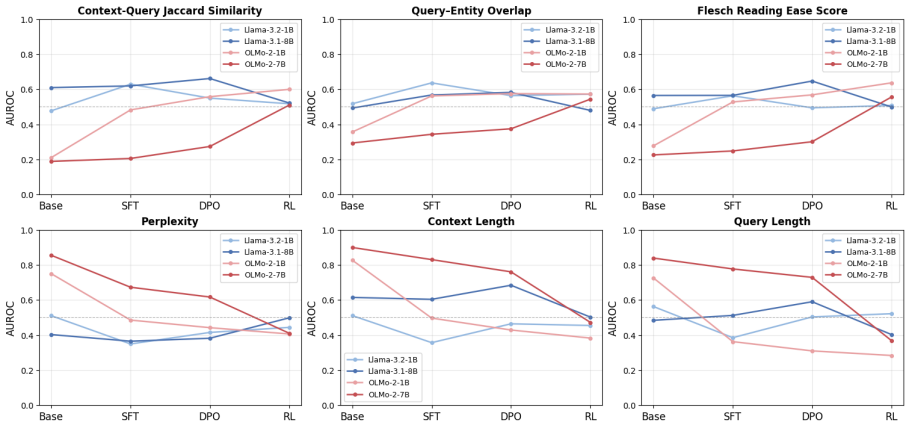
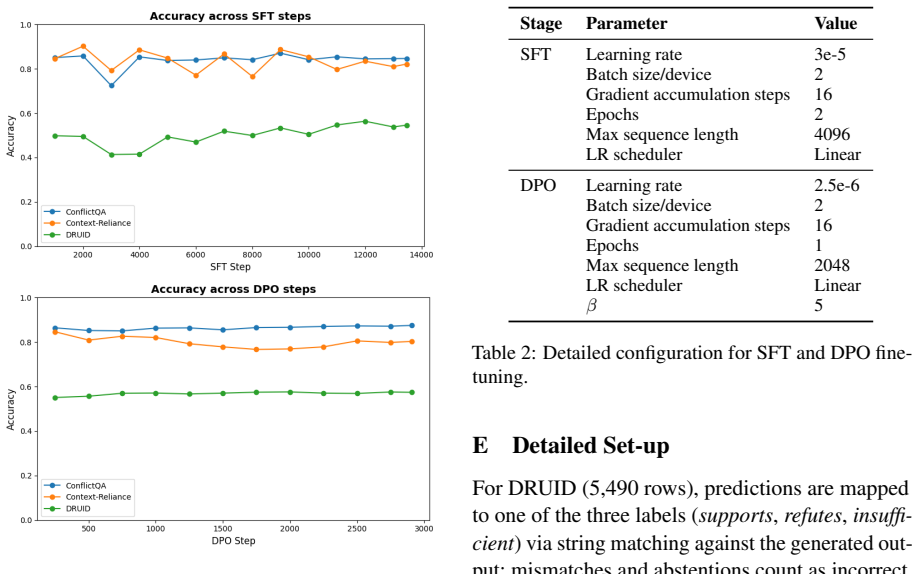
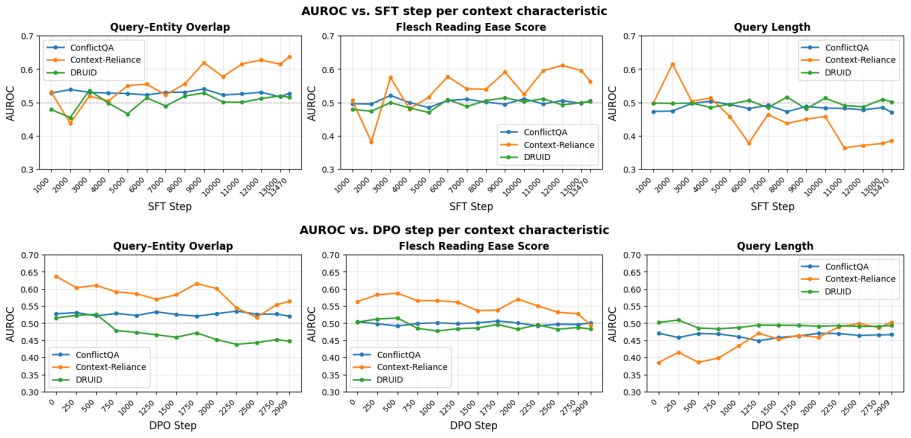
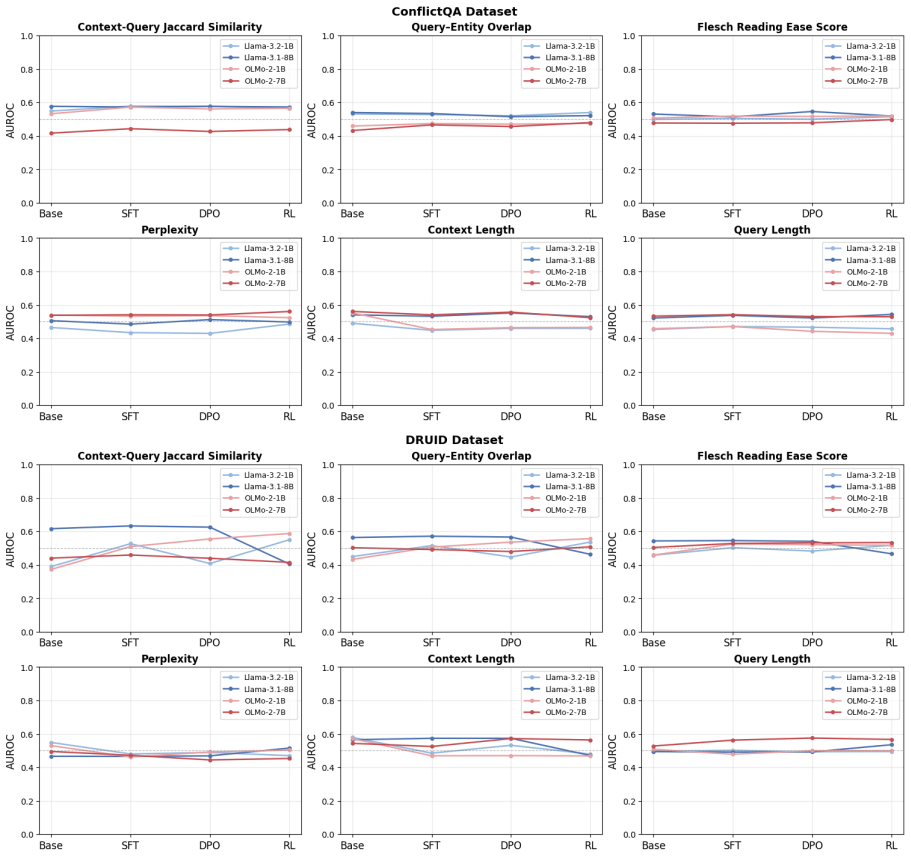
The central claim is that context usage is actively reshaped at each instruction fine-tuning stage. Supervised fine-tuning makes models more likely to use contexts that are easy to understand due to high length, context-query similarity, and fluency. The dynamics after SFT either reinforce or resolve these preferences depending on the training dataset. Thus, designing a balanced IFT dataset is important for robust context utilization in instruction-tuned models.
What carries the argument
The shifts in sensitivity to context characteristics (length, context-query similarity, fluency) measured across the stages of supervised fine-tuning, direct preference optimization, and reinforcement learning with verifiable rewards.
If this is right
- After supervised fine-tuning, models will show increased use of contexts with higher length, similarity, and fluency.
- Later stages of direct preference optimization or reinforcement learning can either strengthen or weaken these context preferences based on the data.
- Robust context utilization requires careful design of datasets at every instruction fine-tuning stage.
- Models' behavior on tasks requiring context can vary systematically with the sequence of fine-tuning applied.
Where Pith is reading between the lines
- Training sequences could be optimized to produce models that use context more uniformly regardless of its characteristics.
- These shifts might affect model performance on real-world tasks where context quality varies.
- If the measurement method holds, it opens the possibility of intervening at specific stages to correct undesired context biases.
Load-bearing premise
The metrics of context length, context-query similarity, and fluency, together with how sensitivity is quantified at each stage, correctly indicate actual reliance on the provided context instead of parametric knowledge.
What would settle it
An experiment showing that sensitivity patterns remain unchanged even when using a deliberately balanced IFT dataset across all stages would indicate the claim is incorrect.
Figures

read the original abstract
During instruction fine-tuning (IFT), large language models (LLMs) learn to follow instructions by using the provided context to answer a query. While prior work has studied how context characteristics correlate with context usage by the LLM, this analysis has been limited to inference time, leaving open how these relationships are acquired in the first place. Here, we measure how models' sensitivity to such characteristics shifts across successive IFT stages: supervised fine-tuning (SFT), direct preference optimization (DPO), and reinforcement learning with verifiable rewards (RLVR). Experiments across four models and three datasets show that SFT makes models more likely to use contexts that are easy to understand, such as containing high length, context-query similarity, and fluency. Post-SFT dynamics may either reinforce or resolve these preferences depending on the training dataset. Our findings reveal that context usage is actively reshaped at each IFT stage, and designing a balanced IFT dataset is important in ensuring robust context utilization of instruction-tuned models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs' sensitivity to context characteristics (length, context-query similarity, fluency) shifts across IFT stages (SFT, DPO, RLVR). Experiments on four models and three datasets indicate SFT increases use of easier contexts (high length/similarity/fluency), while later stages reinforce or resolve these preferences depending on the dataset; the central claim is that context usage is actively reshaped at each stage and balanced IFT datasets are needed for robust utilization.
Significance. If the measured shifts are reliable, the work offers observational evidence that IFT stages actively influence context utilization patterns, with implications for dataset design in instruction tuning. The multi-model, multi-dataset scope is a strength for generality, though the purely correlational nature on proxy metrics limits causal claims about actual context usage versus parametric knowledge.
major comments (2)
- [Abstract] Abstract: the reported shifts across stages are presented without error bars, statistical tests, exclusion criteria, or raw counts, which undermines assessment of whether the observed changes in sensitivity are statistically reliable or practically meaningful.
- [Results] Results/Methods: the sensitivity metrics (length, similarity, fluency) are used as proxies for context usage, but without explicit validation (e.g., controlled ablations showing these characteristics causally affect answer accuracy when context is required), the interpretation that IFT 'reshapes' usage rather than other behaviors remains tentative.
minor comments (2)
- [Methods] Provide the exact formulas or procedures used to compute context-query similarity and fluency scores.
- [Experimental Setup] Clarify the three datasets and four models by name and size in the experimental setup for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical presentation and metric validation. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported shifts across stages are presented without error bars, statistical tests, exclusion criteria, or raw counts, which undermines assessment of whether the observed changes in sensitivity are statistically reliable or practically meaningful.
Authors: We agree that the absence of error bars, statistical tests, and raw counts limits evaluation of reliability. In the revised version we will: (i) add error bars (standard error across seeds or bootstrap) to all sensitivity plots, (ii) report paired statistical tests (e.g., Wilcoxon signed-rank) on the per-stage differences, (iii) include raw counts of contexts retained after filtering, and (iv) detail exclusion criteria in the Methods section. These additions will be reflected in both the abstract and results. revision: yes
-
Referee: [Results] Results/Methods: the sensitivity metrics (length, similarity, fluency) are used as proxies for context usage, but without explicit validation (e.g., controlled ablations showing these characteristics causally affect answer accuracy when context is required), the interpretation that IFT 'reshapes' usage rather than other behaviors remains tentative.
Authors: The study is explicitly observational and reports correlations between IFT stage and sensitivity to established proxy metrics drawn from prior context-usage literature. We do not claim direct causality. We will revise the discussion and limitations sections to state more explicitly that the metrics are proxies, that alternative behaviors cannot be ruled out without controlled ablations, and that the multi-model, multi-dataset consistency provides only correlational support. Performing new causal ablations is outside the scope of a revision; therefore we treat this as a clarification rather than a full experimental addition. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper reports purely observational experimental results on shifts in model sensitivity to context characteristics (length, similarity, fluency) across IFT stages (SFT, DPO, RLVR). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. All claims rest on direct measurements from four models and three datasets rather than any self-referential construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard statistical significance testing is sufficient to establish shifts across training stages
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =. Advances in Neural Information Processing Systems , editor =
-
[2]
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , doi =
-
[3]
2024 , eprint=
Retrieval-Augmented Generation for Large Language Models: A Survey , author=. 2024 , eprint=
2024
-
[4]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[5]
and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael I
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios N. and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael I. and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[6]
A Reality Check on Context Utilisation for Retrieval-Augmented Generation
Hagstr. A Reality Check on Context Utilisation for Retrieval-Augmented Generation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.968
-
[7]
The Twelfth International Conference on Learning Representations , year=
Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts , author=. The Twelfth International Conference on Learning Representations , year=
-
[8]
Knowledge conflicts for LLMs: A survey
Xu, Rongwu and Qi, Zehan and Guo, Zhijiang and Wang, Cunxiang and Wang, Hongru and Zhang, Yue and Xu, Wei. Knowledge Conflicts for LLM s: A Survey. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.486
-
[9]
In-context Learning: A Fair Comparison and Evaluation
Mosbach, Marius and Pimentel, Tiago and Ravfogel, Shauli and Klakow, Dietrich and Elazar, Yanai. Few-shot Fine-tuning vs. In-context Learning: A Fair Comparison and Evaluation. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.779
-
[10]
Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLM s
Ovadia, Oded and Brief, Menachem and Mishaeli, Moshik and Elisha, Oren. Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLM s. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.15
-
[11]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[12]
Second Conference on Language Modeling , year=
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=. Second Conference on Language Modeling , year=
-
[13]
The Thirteenth International Conference on Learning Representations , year=
Context-Parametric Inversion: Why Instruction Finetuning May Not Actually Improve Context Reliance , author=. The Thirteenth International Conference on Learning Representations , year=
-
[14]
and Yoon, Seunghyun and Schuetze, Hinrich , booktitle =
Modarressi, Ali and Deilamsalehy, Hanieh and Dernoncourt, Franck and Bui, Trung and Rossi, Ryan A. and Yoon, Seunghyun and Schuetze, Hinrich , booktitle =. 2025 , editor =
2025
-
[15]
Du, Mengnan and He, Fengxiang and Zou, Na and Tao, Dacheng and Hu, Xia , title =. Commun. ACM , month = dec, pages =. 2023 , issue_date =. doi:10.1145/3596490 , abstract =
-
[16]
Adversarial Examples for Evaluating Reading Comprehension Systems
Jia, Robin and Liang, Percy. Adversarial Examples for Evaluating Reading Comprehension Systems. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017. doi:10.18653/v1/D17-1215
-
[17]
A New Readability Yardstick , author =. Journal of Applied Psychology , volume =. doi:10.1037/h0057532 , abstract =
-
[18]
A Lexicon-Based Approach for Detecting Hedges in Informal Text
Islam, Jumayel and Xiao, Lu and Mercer, Robert E. A Lexicon-Based Approach for Detecting Hedges in Informal Text. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[19]
2024 , eprint=
Large Language Models are Inconsistent and Biased Evaluators , author=. 2024 , eprint=
2024
-
[20]
The Twelfth International Conference on Learning Representations , year=
Retrieval meets Long Context Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[21]
First Conference on Language Modeling , year=
Length-Controlled AlpacaEval: A Simple Debiasing of Automatic Evaluators , author=. First Conference on Language Modeling , year=
-
[22]
2025 , eprint=
Value Drifts: Tracing Value Alignment During LLM Post-Training , author=. 2025 , eprint=
2025
-
[23]
Large language models can be easily distracted by irrelevant context , year =
Shi, Freda and Chen, Xinyun and Misra, Kanishka and Scales, Nathan and Dohan, David and Chi, Ed and Sch\". Large language models can be easily distracted by irrelevant context , year =. Proceedings of the 40th International Conference on Machine Learning , articleno =
-
[24]
2026 , eprint=
CUB: Benchmarking Context Utilisation Techniques for Language Models , author=. 2026 , eprint=
2026
-
[25]
On the Risk of Misinformation Pollution with Large Language Models
Pan, Yikang and Pan, Liangming and Chen, Wenhu and Nakov, Preslav and Kan, Min-Yen and Wang, William. On the Risk of Misinformation Pollution with Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.97
-
[26]
Bulletin de la Société Vaudoise des Sciences Naturelles
Etude comparative de la distribution florale dans une portion des Alpes et des Jura , booktitle="Bulletin de la Société Vaudoise des Sciences Naturelles", author=. 1901. doi:https://doi.org/10.5169/seals-266450
-
[27]
2024 , eprint=
2 OLMo 2 Furious , author=. 2024 , eprint=
2024
-
[28]
2002 , eprint=
NLTK: The Natural Language Toolkit , author=. 2002 , eprint=
2002
-
[29]
Qi, Peng and Zhang, Yuhao and Zhang, Yuhui and Bolton, Jason and Manning, Christopher D. S tanza: A Python Natural Language Processing Toolkit for Many Human Languages. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 2020. doi:10.18653/v1/2020.acl-demos.14
-
[30]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , booktitle =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.