FMplex: Model Virtualization for Serving Extensible Foundation Models
Pith reviewed 2026-06-27 14:48 UTC · model grok-4.3
The pith
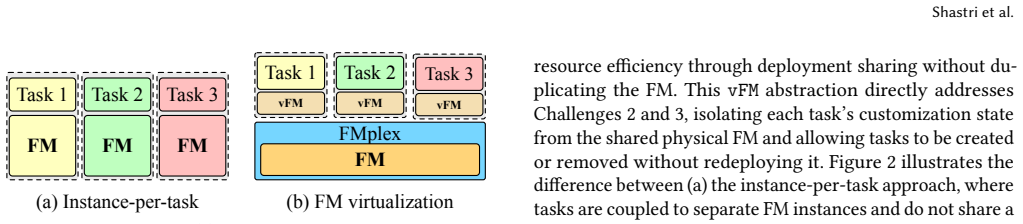
FMplex virtualizes foundation model backbones so customized tasks can share one instance while keeping their own extensions and isolation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
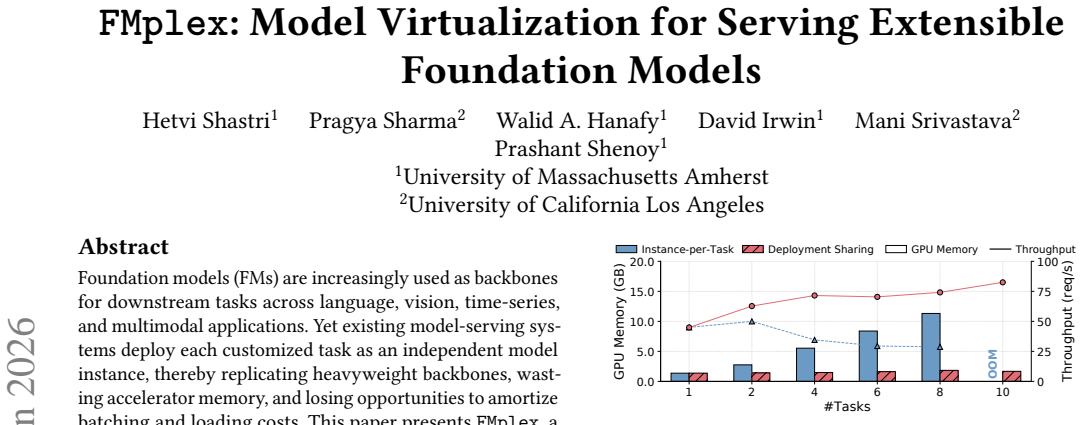
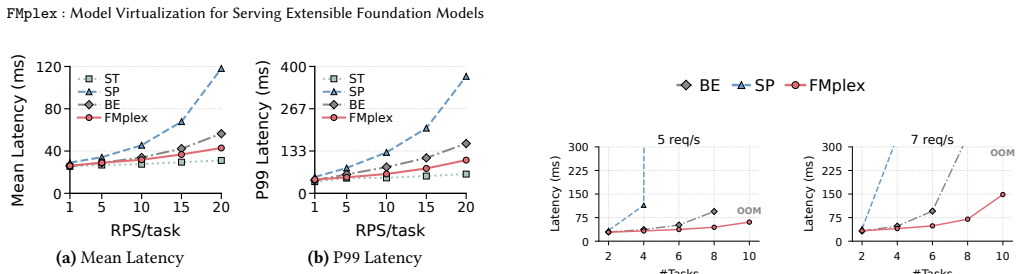
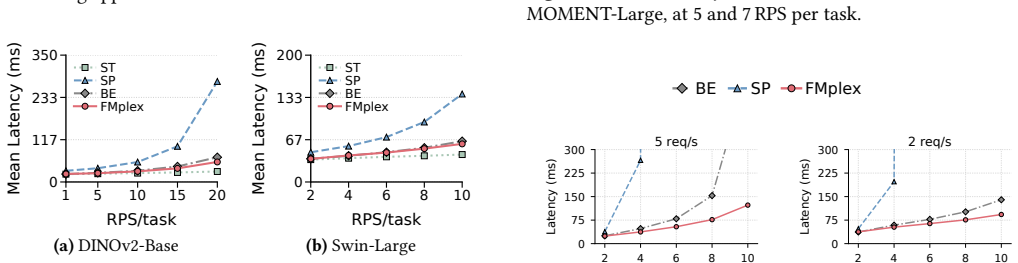
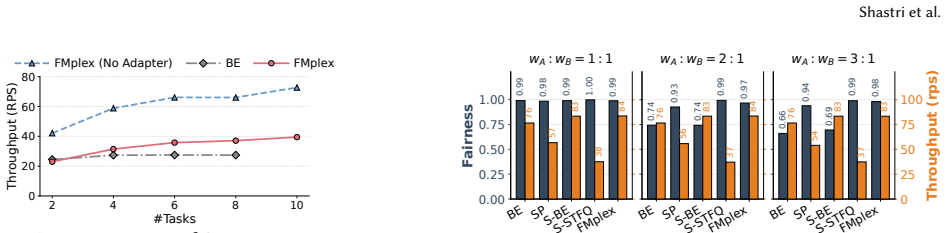
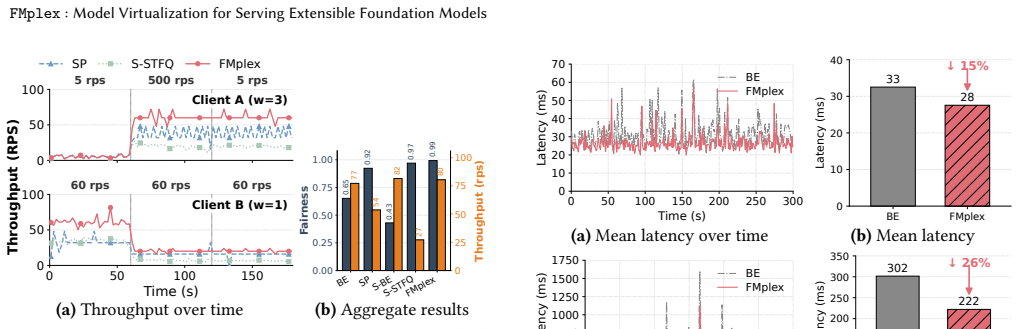
FMplex presents each task with a virtual foundation model (vFM), a logically private FM instance backed by a shared physical FM. This abstraction lets independently customized tasks share a backbone while preserving task-specific extensions, independent lifecycles, and task-level isolation. A batch-aware fair-queueing scheduler combines weighted task-level sharing with inter- and intra-task batching across colocated tasks. Across 7 FM backbones (16 variants) and 92 downstream tasks, FMplex reduces latency by up to 80% over spatial partitioning and 33.3% over best-effort co-location, while hosting up to 6x more tasks at cluster scale.
What carries the argument
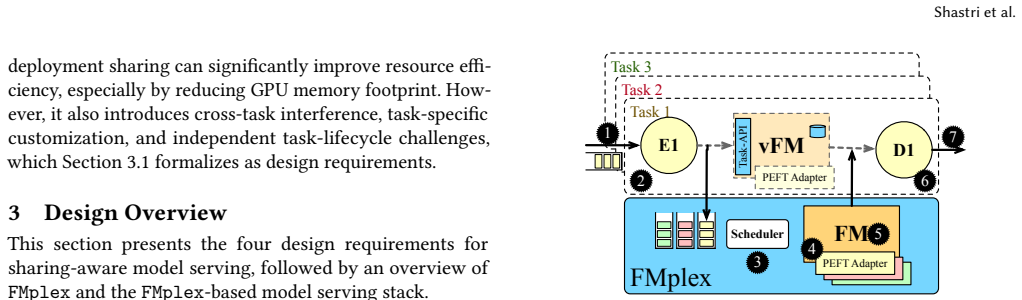
The virtual foundation model (vFM) abstraction backed by a shared physical FM, together with the batch-aware fair-queueing scheduler that mixes weighted sharing and batching.
If this is right
- Tasks can start, stop, or update independently without reloading or duplicating the shared backbone.
- Batching and loading costs are amortized across many tasks instead of being paid per instance.
- Accelerator memory holds many more active tasks because only one copy of the heavyweight backbone is needed.
- Cluster operators can increase served task count without adding proportional hardware.
- Task isolation remains at the individual-task level even though the backbone is shared.
Where Pith is reading between the lines
- The same sharing approach could let operators add or remove tasks dynamically without restarting the shared model.
- Energy use per task could fall because fewer full model copies run in parallel.
- Task developers might begin designing extensions to take advantage of sharing rather than assuming a private full model.
- The pattern might apply to other large shared components such as embedding tables or feature extractors in production pipelines.
Load-bearing premise
The added virtualization layer and scheduler can deliver the reported latency and density gains without new interference or overhead that would cancel the benefits of sharing.
What would settle it
A measurement showing that average per-task latency or total tasks per accelerator drops to the level of spatial partitioning once task extensions or fairness constraints are enforced at scale.
Figures





read the original abstract
Foundation models (FMs) are increasingly used as backbones for downstream tasks across language, vision, time-series, and multimodal applications. Yet existing model-serving systems deploy each customized task as an independent model instance, thereby replicating heavyweight backbones, wasting accelerator memory, and losing opportunities to amortize batching and loading costs. This paper presents FMplex, a serving system that treats FM backbones as a virtualization substrate for deployment sharing. FMplex presents each task with a virtual foundation model (vFM), a logically private FM instance backed by a shared physical FM. This abstraction lets independently customized tasks share a backbone while preserving task-specific extensions, independent lifecycles, and task-level isolation. In addition, we propose a batch-aware fair-queueing scheduler that combines weighted task-level sharing with inter- and intra-task batching across colocated tasks. We implement a FMplex-based serving stack spanning task construction, sharing-aware deployment, and runtime execution. Across 7 FM backbones (16 variants) and 92 downstream tasks, FMplex reduces latency by up to 80% over spatial partitioning and 33.3% over best-effort co-location, while hosting up to 6x more tasks at cluster scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FMplex, a serving system for foundation models that introduces virtual foundation models (vFM) as a virtualization abstraction allowing multiple independently customized downstream tasks to share a physical FM backbone while preserving task-specific extensions, independent lifecycles, and isolation. It also proposes a batch-aware fair-queueing scheduler enabling inter- and intra-task batching. The system is implemented as a full serving stack, and evaluation across 7 FM backbones (16 variants) and 92 downstream tasks reports latency reductions of up to 80% versus spatial partitioning and 33.3% versus best-effort co-location, plus the ability to host up to 6x more tasks at cluster scale.
Significance. If the empirical results hold after addressing measurement gaps, the work would be significant for distributed ML serving: it directly targets memory waste and batching under-utilization when deploying many task-specific FM variants, offering a practical path to higher density without sacrificing per-task customization. The virtualization substrate idea and combined scheduler are novel contributions in the model-serving literature.
major comments (2)
- [Evaluation section (results on 7 backbones / 92 tasks)] The strongest claims (80% latency reduction, 33.3% improvement over co-location, 6x task density) are load-bearing on the assertion that vFM virtualization and the batch-aware scheduler introduce negligible interference or overhead. The manuscript provides no dedicated overhead breakdown (e.g., context-switch cost, memory-mapping overhead, or batching-efficiency loss due to isolation) in the evaluation; without such quantification relative to the reported gains, it is impossible to confirm the net benefit.
- [Scheduler design and runtime execution sections] The scheduler description claims weighted task-level sharing combined with inter/intra-task batching, but the manuscript does not show how the fair-queueing policy interacts with task-specific extensions or isolation enforcement; if isolation prevents full batch merging, the latency and density claims would be undermined. A concrete example or micro-benchmark isolating this interaction is needed.
minor comments (2)
- [Abstract] The abstract states performance numbers without error bars, number of runs, or exact workload characteristics; adding these in the evaluation tables would improve clarity.
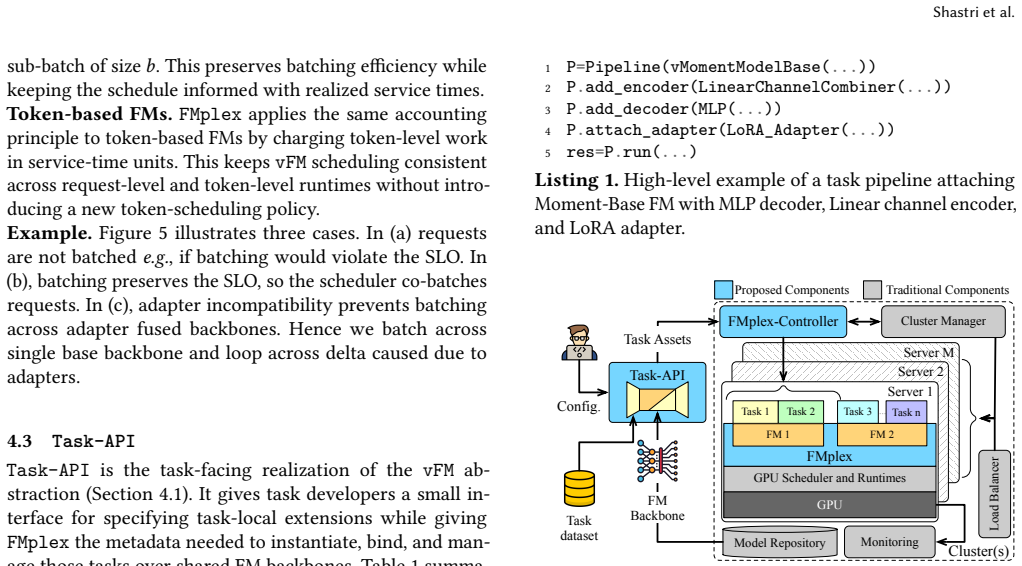
- [Introduction / System overview] Notation for vFM and the physical FM mapping could be formalized earlier (e.g., with a small diagram or equations) to aid readers unfamiliar with virtualization concepts in ML serving.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of FMplex. We address each major comment below and will revise the manuscript accordingly to strengthen the evaluation.
read point-by-point responses
-
Referee: [Evaluation section (results on 7 backbones / 92 tasks)] The strongest claims (80% latency reduction, 33.3% improvement over co-location, 6x task density) are load-bearing on the assertion that vFM virtualization and the batch-aware scheduler introduce negligible interference or overhead. The manuscript provides no dedicated overhead breakdown (e.g., context-switch cost, memory-mapping overhead, or batching-efficiency loss due to isolation) in the evaluation; without such quantification relative to the reported gains, it is impossible to confirm the net benefit.
Authors: We agree that a dedicated overhead breakdown is needed to fully substantiate the negligible-interference claim. In the revised manuscript we will add micro-benchmarks that quantify context-switch cost, memory-mapping overhead, and any batching-efficiency loss attributable to isolation, presented relative to the end-to-end gains already reported. revision: yes
-
Referee: [Scheduler design and runtime execution sections] The scheduler description claims weighted task-level sharing combined with inter/intra-task batching, but the manuscript does not show how the fair-queueing policy interacts with task-specific extensions or isolation enforcement; if isolation prevents full batch merging, the latency and density claims would be undermined. A concrete example or micro-benchmark isolating this interaction is needed.
Authors: The scheduler batches requests at the shared physical backbone before task-specific extensions are applied, allowing inter-task batching while isolation is maintained via separate extension layers. We will add both a concrete scheduling example and an isolating micro-benchmark to the revised scheduler section to demonstrate this interaction explicitly. revision: yes
Circularity Check
No circularity; empirical system evaluation with independent benchmarks
full rationale
The paper describes an implemented serving system (FMplex) with vFM virtualization and a batch-aware fair-queueing scheduler, then reports measured latency reductions (up to 80% vs spatial partitioning, 33.3% vs best-effort co-location) and task density gains (up to 6x) from running 92 downstream tasks on 7 FM backbones. These outcomes are presented as direct results of the prototype evaluation rather than any derivation, fitted parameter, or self-citation chain that reduces the numbers to the inputs by construction. No equations, uniqueness theorems, ansatzes, or renamings appear in the provided text; the central claims rest on external benchmark data and are therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation model backbones can be extended for downstream tasks while the core weights remain shareable without task interference
invented entities (1)
-
virtual foundation model (vFM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Friedman, Thomas Williams, Ramesh K
Sohaib Ahmad, Hui Guan, Brian D. Friedman, Thomas Williams, Ramesh K. Sitaraman, and Thomas Woo. 2024. Proteus: A High- Throughput Inference-Serving System with Accuracy Scaling. InPro- ceedings of the 29th ACM International Conference on Architectural Sup- port for Programming Languages and Operating Systems, Volume 1(La Jolla, CA, USA)(ASPLOS ’24). 318–...
-
[2]
Amazon Web Services. 2026. Amazon Bedrock.https://aws.amazon. com/bedrock/. Accessed: 2026-05-14
2026
-
[3]
Maddix, Michael W
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Syndar Ranga- puram, Sebastian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Yuyang Wang. 2024. Chronos: Learning the Language of...
2024
-
[4]
Joshua Bakita and James H Anderson. 2023. Hardware Compute Partitioning on NVIDIA GPUs. InProceedings of the 29th IEEE Real- Time and Embedded Technology and Applications Symposium. 54–66
2023
-
[5]
Charith Chandra Sai Balne, Sreyoshi Bhaduri, Tamoghna Roy, Vinija Jain, and Aman Chadha. 2024. Parameter Efficient Fine Tuning: A Com- prehensive Analysis Across Applications. arXiv:2404.13506 [cs.LG] https://arxiv.org/abs/2404.13506
arXiv 2024
-
[6]
Ozan Baris, Yizhuo Chen, Gaofeng Dong, Liying Han, Tomoyoshi Kimura, Pengrui Quan, Ruijie Wang, Tianchen Wang, Tarek Ab- delzaher, Mario Bergés, Paul Pu Liang, and Mani Srivastava. 2025. Foundation Models for CPS-IoT: Opportunities and Challenges. arXiv:2501.16368 [cs.LG]https://arxiv.org/abs/2501.16368
arXiv 2025
-
[7]
Rishi Bommasani et al . 2021. On the Opportunities and Risks of Foundation Models.ArXiv(2021).https://crfm.stanford.edu/assets/ report.pdf
2021
-
[8]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
Pith/arXiv arXiv 2020
-
[9]
Shiyi Cao, Yichuan Wang, Ziming Mao, Pin-Lun Hsu, Liangsheng Yin, Tian Xia, Dacheng Li, Shu Liu, Yineng Zhang, Yang Zhou, Ying Sheng, Joseph Gonzalez, and Ion Stoica. 2025. Locality-aware Fair Scheduling in LLM Serving. arXiv:2501.14312 [cs.DC]https://arxiv.org/abs/2501. 14312
arXiv 2025
-
[10]
Lequn Chen, Zihao Ye, Yongji Wu, Danyang Zhuo, Luis Ceze, and Arvind Krishnamurthy. 2024. Punica: Multi-Tenant LoRA Serving. In Proceedings of Machine Learning and Systems (MLSys)
2024
-
[11]
Franklin, Joseph E
Daniel Crankshaw, Xin Wang, Guilio Zhou, Michael J. Franklin, Joseph E. Gonzalez, and Ion Stoica. 2017. Clipper: A Low-Latency Online Prediction Serving System. In14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). USENIX As- sociation, Boston, MA, 613–627.https://www.usenix.org/conference/ nsdi17/technical-sessions/presentatio...
2017
-
[12]
R. J. Creasy. 1981. The Origin of the VM/370 Time-Sharing System. IBM Journal of Research and Development25, 5 (1981), 483–490. doi:10. 1147/rd.255.0483
1981
-
[13]
A. Demers, S. Keshav, and S. Shenker. 1989. Analysis and Simulation of a Fair Queueing Algorithm.SIGCOMM Comput. Commun. Rev.19, 4 (aug 1989), 1–12. doi:10.1145/75247.75248
-
[14]
Haoyu Dong, Hanxue Gu, Yaqian Chen, Jichen Yang, Yuwen Chen, and Maciej A. Mazurowski. 2024. Segment anything model 2: an application to 2D and 3D medical images. arXiv:2408.00756 [cs.CV] 13 Shastri et al. https://arxiv.org/abs/2408.00756
arXiv 2024
-
[15]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations (ICLR).ht...
2021
-
[16]
R. Elliott. 2002. A measure of fairness of service for scheduling algo- rithms in multiuser systems. InIEEE CCECE2002. Canadian Confer- ence on Electrical and Computer Engineering. Conference Proceedings (Cat. No.02CH37373), Vol. 3. 1583–1588 vol.3. doi:10.1109/CCECE.2002. 1012991
-
[17]
Vasilii Feofanov, Songkang Wen, Marius Alonso, Romain Ilbert, Hongbo Guo, Malik Tiomoko, Lujia Pan, Jianfeng Zhang, and Iev- gen Redko. 2025. Mantis: Lightweight Calibrated Foundation Model for User-Friendly Time Series Classification.arXiv preprint arXiv:2502.15637(2025)
arXiv 2025
-
[18]
Théo Gnassounou, Yessin Moakher, Shifeng Xie, Vasilii Feofanov, and Ievgen Redko. 2025. Leveraging Generic Time Series Foundation Models for EEG Classification. arXiv:2510.27522 [cs.LG]https://arxiv. org/abs/2510.27522
arXiv 2025
-
[19]
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. 2024. MOMENT: A Family of Open Time-series Foundation Models. InInternational Conference on Machine Learning
2024
-
[20]
Pawan Goyal, Harrick M. Vin, and Haichen Cheng. 1997. Start-Time Fair Queueing: A Scheduling Algorithm for Integrated Services Packet Switching Networks.IEEE/ACM Trans. Netw.5, 5 (oct 1997), 690–704. doi:10.1109/90.649569
-
[21]
gRPC Authors. 2026. gRPC: A high performance open-source universal RPC framework.https://grpc.io/. Accessed: 2026-03-26
2026
-
[22]
Arpan Gujarati, Reza Karimi, Safya Alzayat, Wei Hao, Antoine Kauf- mann, Ymir Vigfusson, and Jonathan Mace. 2020. Serving DNNs like Clockwork: Performance Predictability from the Bottom Up. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association, 443–462.https://www.usenix.org/ conference/osdi20/presentation/gujarati
2020
-
[23]
Daya Guo, Dejian Yang, et al. 2025. DeepSeek-R1 incentivizes reason- ing in LLMs through Reinforcement Learning.Nature645, 8081 (Sept. 2025), 633–638. doi:10.1038/s41586-025-09422-z
-
[24]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. InProceedings of the IEEE conference on computer vision and pattern recognition (CVPR)
2016
-
[25]
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-Efficient Transfer Learning for NLP. In Proceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaud- huri and Ruslan Sal...
2019
-
[26]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. LoRA: Low-Rank Adaptation of Large Language Models.ICLR1, 2 (2022), 3
2022
-
[27]
Nan Huang, Haishuai Wang, Zihuai He, Marinka Zitnik, and Xi- ang Zhang. 2025. Repurposing Foundation Model for Generaliz- able Medical Time Series Classification. arXiv:2410.03794 [cs.LG] https://arxiv.org/abs/2410.03794
arXiv 2025
-
[28]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
Pith/arXiv arXiv 2023
-
[29]
Anuj Kumar, Harish Kumar Saravanan, Shivam Dwivedi, and Pan- darasamy Arjunan. 2025. MixForecast: Mixer-Enhanced Foundation Model for Load Forecasting. InProceedings of the 2nd International Workshop on Foundation Models for Cyber-Physical Systems & Inter- net of Things(Irvine, CA, USA)(FMSys). 25–30. doi:10.1145/3722565. 3727193
-
[30]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[31]
InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
-
[32]
Gonzalez, and Ion Stoica
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). 663–679
2023
-
[33]
Hanafy, Ahmed Ali-Eldin, and Prashant Shenoy
Qianlin Liang, Walid A. Hanafy, Ahmed Ali-Eldin, and Prashant Shenoy. 2023. Model-Driven Cluster Resource Management for AI Workloads in Edge Clouds.ACM Transactions on Autonomous and Adaptive Systems18, 1, Article 2 (mar 2023), 26 pages. doi:10.1145/ 3582080
2023
-
[34]
Hanafy, Noman Bashir, David Irwin, and Prashant Shenoy
Qianlin Liang, Walid A. Hanafy, Noman Bashir, David Irwin, and Prashant Shenoy. 2023. Energy Time Fairness: Balancing Fair Alloca- tion of Energy and Time for GPU Workloads. In2023 IEEE/ACM Sym- posium on Edge Computing (SEC). 53–66. doi:10.1145/3583740.3628435
-
[35]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. InProceedings of the 37th International Con- ference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Article 1516, 25 pages
2023
-
[36]
Shikun Liu, Edward Johns, and Andrew J. Davison. 2019. End-To-End Multi-Task Learning With Attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2019
-
[37]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv:2103.14030 [cs.CV] https://arxiv.org/abs/2103.14030
Pith/arXiv arXiv 2021
-
[38]
LXC Contributors. 2026. LXC: Linux Containers.https:// linuxcontainers.org/. Accessed: 2026-04-14
2026
-
[39]
Diptyaroop Maji, Kang Yang, Prashant Shenoy, Ramesh K Sitaraman, and Mani Srivastava. 2025. CarbonX: An Open-Source Tool for Com- putational Decarbonization Using Time Series Foundation Models. arXiv:2510.01521 [cs.LG]https://arxiv.org/abs/2510.01521
arXiv 2025
-
[40]
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, Benjamin Bossan, and Marian Tietz. 2022. PEFT: State-of- the-art Parameter-Efficient Fine-Tuning methods.https://github.com/ huggingface/peft
2022
-
[41]
Dirk Merkel. 2014. Docker: Lightweight Linux Containers for Consis- tent Development and Deployment.Linux Journal2014, 239 (2014)
2014
-
[42]
Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al . 2024. Gemma: Open Models Based on Gemini Research and Technology.arXiv preprint arXiv:2403.08295(2024)
Pith/arXiv arXiv 2024
-
[43]
Meta. 2024. Llama 3.2 Vision models.https://www.llama.com/docs/ model-cards-and-prompt-formats/llama3_2/. Accessed: 2026-03-05
2024
-
[44]
Nathan Ng, Abel Souza, Ahmed Ali-Eldin, David Irwin, Don Towsley, and Prashant Shenoy. 2024. TailClipper: Reducing Tail Response Time of Distributed Services Through System-Wide Scheduling. In Proceedings of the 2024 ACM Symposium on Cloud Computing (SoCC ’24). 398–414. doi:10.1145/3698038.3698554
-
[45]
David Nigenda, Zohar Karnin, Muhammad Bilal Zafar, Raghu Rame- sha, Alan Tan, Michele Donini, and Krishnaram Kenthapadi. 2022. Amazon SageMaker Model Monitor: A System for Real-Time Insights into Deployed Machine Learning Models. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Washington DC, USA)(KDD ’22). Associati...
-
[46]
NVIDIA. 2024. Triton Inference Server.https://developer.nvidia.com/ triton-inference-serverAccessed: 2025-04-13
2024
-
[47]
2026.CUDA Driver API: Green Contexts
NVIDIA Corporation. 2026.CUDA Driver API: Green Contexts. NVIDIA Corporation.https://docs.nvidia.com/cuda/cuda-driver-api/group_ _CUDA__GREEN__CONTEXTS.htmlAccessed: 2026-03-27
2026
-
[48]
NVIDIA Corporation. 2026. NVIDIA Multi-Instance GPU (MIG).https: //www.nvidia.com/en-us/technologies/multi-instance-gpu/Accessed: 2026-03-27
2026
-
[49]
2026.NVIDIA Multi-Process Service
NVIDIA Corporation. 2026.NVIDIA Multi-Process Service. NVIDIA Corporation.https://docs.nvidia.com/deploy/mps/index.html
2026
-
[50]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Fran- cisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wo- jciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick...
2024
-
[51]
A.K. Parekh and R.G. Gallager. 1993. A generalized processor sharing approach to flow control in integrated services networks: the single- node case.IEEE/ACM Transactions on Networking1, 3 (1993), 344–357. doi:10.1109/90.234856
-
[52]
2019.PyTorch: an imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chil- amkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019.PyTorch: an imperative style, high-p...
2019
-
[53]
Arvind Pillai, Dimitris Spathis, Fahim Kawsar, and Mohammad Malekzadeh. 2025. PaPaGei: Open Foundation Models for Optical Physiological Signals. arXiv:2410.20542 [cs.LG]https://arxiv.org/abs/ 2410.20542
arXiv 2025
-
[54]
Gerald J. Popek and Robert P. Goldberg. 1974. Formal Requirements for Virtualizable Third Generation Architectures.Commun. ACM17, 7 (1974), 412–421. doi:10.1145/361011.361073
-
[55]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learn- ing Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th International Conference on Machine Learning (Proceedings of Machi...
2021
-
[56]
Varun Rao, Youran Sun, Mahendra Kumar, Tejas Mutneja, Agastya Mukherjee, and Haizhao Yang. 2025. LLMs Meet Finance: Fine- Tuning Foundation Models for the Open FinLLM Leaderboard. arXiv:2504.13125 [cs.CL]https://arxiv.org/abs/2504.13125
arXiv 2025
-
[57]
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi
-
[58]
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 779–788
-
[59]
Yadwadkar, and Christos Kozyrakis
Francisco Romero, Qian Li, Neeraja J. Yadwadkar, and Christos Kozyrakis. 2021. INFaaS: Automated Model-less Inference Serv- ing. In2021 USENIX Annual Technical Conference (USENIX ATC 21). USENIX Association, 397–411.https://www.usenix.org/conference/ atc21/presentation/romero
2021
-
[60]
Senior, and Françoise Beaufays
Hasim Sak, Andrew W. Senior, and Françoise Beaufays. 2014. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. InINTERSPEECH. 338–342
2014
-
[61]
Mahadev Satyanarayanan, Nathan Beckmann, Grace A. Lewis, and Brandon Lucia. 2021. The Role of Edge Offload for Hardware- Accelerated Mobile Devices. InProceedings of the 22nd International Workshop on Mobile Computing Systems and Applications(Virtual, United Kingdom)(HotMobile ’21). 22–29. doi:10.1145/3446382.3448360
-
[62]
Mohammad Shahrad, Rodrigo Fonseca, Inigo Goiri, Gohar Chaudhry, Paul Batum, Jason Cooke, Eduardo Laureano, Colby Tresness, Mark Russinovich, and Ricardo Bianchini. 2020. Serverless in the Wild: Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider. In2020 USENIX Annual Technical Conference (USENIX ATC 20). USENIX Association, 205...
2020
-
[63]
Ao Shen, Zhiyao Li, and Mingyu Gao. 2024. FastSwitch: Optimizing Context Switching Efficiency in Fairness-aware Large Language Model Serving. arXiv:2411.18424 [cs.LG]https://arxiv.org/abs/2411.18424
arXiv 2024
-
[64]
Haichen Shen, Lequn Chen, Yuchen Jin, Liangyu Zhao, Bingyu Kong, Matthai Philipose, Arvind Krishnamurthy, and Ravi Sundaram. 2019. Nexus: A GPU Cluster Engine for Accelerating DNN-Based Video Analysis. InProceedings of the 27th ACM Symposium on Operating Systems Principles(Huntsville, Ontario, Canada)(SOSP ’19). Asso- ciation for Computing Machinery, New ...
-
[65]
2025.EdgeLoRA: An Efficient Multi-Tenant LLM Serving System on Edge Devices
Zheyu Shen, Yexiao He, Ziyao Wang, Yuning Zhang, Guoheng Sun, Wanghao Ye, and Ang Li. 2025.EdgeLoRA: An Efficient Multi-Tenant LLM Serving System on Edge Devices. Association for Computing Machinery, New York, NY, USA, 138–153.https://doi.org/10.1145/ 3711875.3729141
arXiv 2025
-
[66]
Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, Joseph E. Gonzalez, and Ion Stoica. 2024. S-LoRA: Serving Thousands of Concurrent LoRA Adapters. arXiv:2311.03285 [cs.LG] https://arxiv.org/abs/2311.03285
arXiv 2024
-
[67]
Gonzalez, and Ion Stoica
Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E. Gonzalez, and Ion Stoica. 2024. Fairness in Serving Large Language Models. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 965–988. https://www.usenix.org/conference/osdi24/presentation/sheng
2024
-
[68]
Yu Shi, Zongliang Fu, Shuo Chen, Bohan Zhao, Wei Xu, Chang- shui Zhang, and Jian Li. 2025. Kronos: A Foundation Model for the Language of Financial Markets. arXiv:2508.02739 [q-fin.ST] https://arxiv.org/abs/2508.02739
arXiv 2025
-
[69]
Shakhrul Iman Siam, Hyunho Ahn, Li Liu, Samiul Alam, Hui Shen, Zhichao Cao, Ness Shroff, Bhaskar Krishnamachari, Mani Srivastava, and Mi Zhang. 2025. Artificial Intelligence of Things: A Survey.ACM Trans. Sen. Netw.21, 1, Article 9 (Jan. 2025), 75 pages. doi:10.1145/ 3690639
2025
-
[70]
Luigi Simeone. 2026. Time Series Foundation Models for Energy Load Forecasting on Consumer Hardware: A Multi-Dimensional Zero-Shot Benchmark. arXiv:2602.10848 [cs.LG]https://arxiv.org/abs/2602.10848
arXiv 2026
-
[71]
Sitaraman, and Prashant Shenoy
Michael Sindelar, Ramesh K. Sitaraman, and Prashant Shenoy. 2011. Sharing-aware algorithms for virtual machine colocation(SPAA ’11). Association for Computing Machinery, New York, NY, USA, 367–378. doi:10.1145/1989493.1989554
-
[72]
J.E. Smith and Ravi Nair. 2005. The architecture of Virtual Machines. Computer38, 5 (2005), 32–38. doi:10.1109/MC.2005.173
-
[73]
Trevor Standley, Amir Zamir, Dawn Chen, Leonidas Guibas, Jitendra Malik, and Silvio Savarese. 2020. Which tasks should be learned together in multi-task learning?. InProceedings of the 37th International Conference on Machine Learning (ICML’20). JMLR.org, Article 846, 13 pages
2020
-
[74]
Mingxing Tan and Quoc Le. 2019. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97). PMLR, 6105–6114.https://proceedings. mlr.press/v97/tan19a.html
2019
-
[75]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie- Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard 15 Shastri et al. Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 [cs.CL]https://arxiv. org/abs...
Pith/arXiv arXiv 2023
-
[76]
Carl A Waldspurger and William E Weihl. 1994. Lottery scheduling: Flexible Proportional-share Resource Management. InProceedings of the 1st USENIX conference on Operating Systems Design and Implemen- tation. 1–es
1994
-
[77]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. arXiv:2409.12191 [cs.CV]https://a...
Pith/arXiv arXiv 2024
-
[78]
Timothy Wood, Gabriel Tarasuk-Levin, Prashant Shenoy, Peter Desnoyers, Emmanuel Cecchet, and Mark D. Corner. 2009. Mem- ory buddies: exploiting page sharing for smart colocation in virtu- alized data centers.SIGOPS Oper. Syst. Rev.43, 3 (July 2009), 27–36. doi:10.1145/1618525.1618529
-
[79]
Bingyang Wu, Ruidong Zhu, Zili Zhang, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. dLoRA: Dynamically Orchestrating Requests and Adapters for LoRA LLM Serving. In18th USENIX Symposium on Oper- ating Systems Design and Implementation (OSDI 24)
2024
-
[80]
Lingling Xu, Haoran Xie, Si-Zhao Joe Qin, Xiaohui Tao, and Fu Lee Wang. 2023. Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment. arXiv:2312.12148 [cs.CL]https://arxiv.org/abs/2312.12148
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.