BrainSurgery: Reproducible and Reliable Declarative Weight Manipulations for Model Editing and Upcycling
Pith reviewed 2026-06-27 16:53 UTC · model grok-4.3
The pith
BrainSurgery replaces ad-hoc Python scripts with declarative YAML plans for editing neural network weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
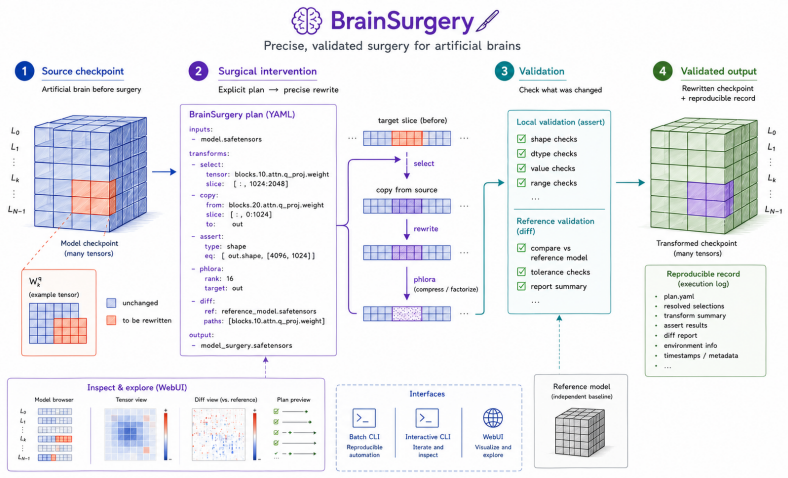
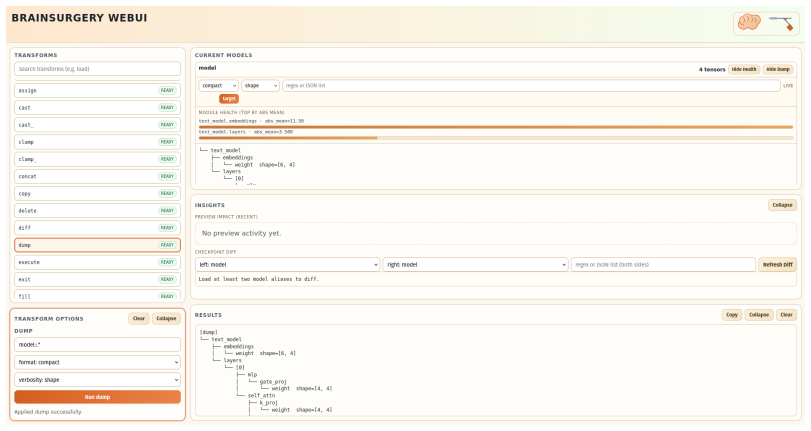
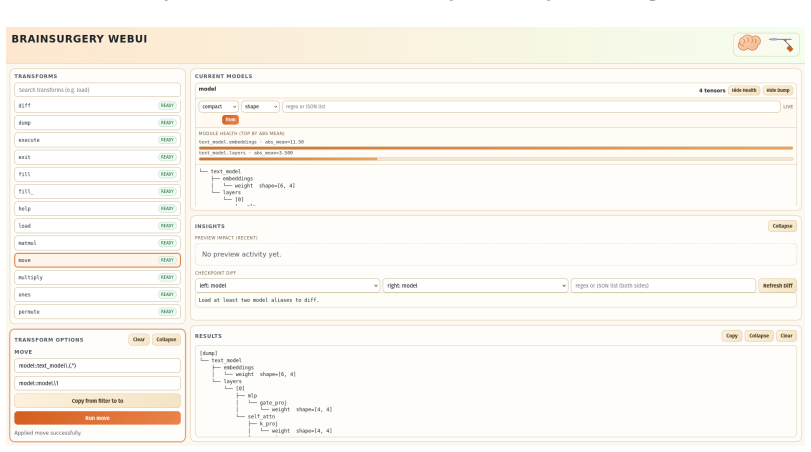
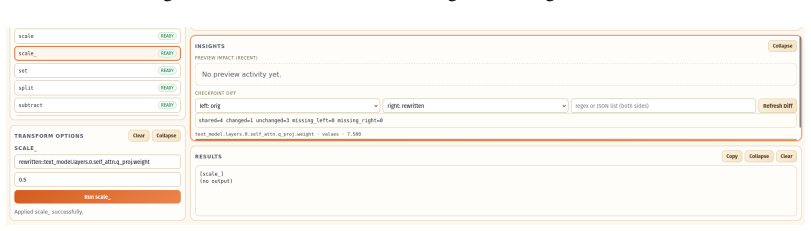
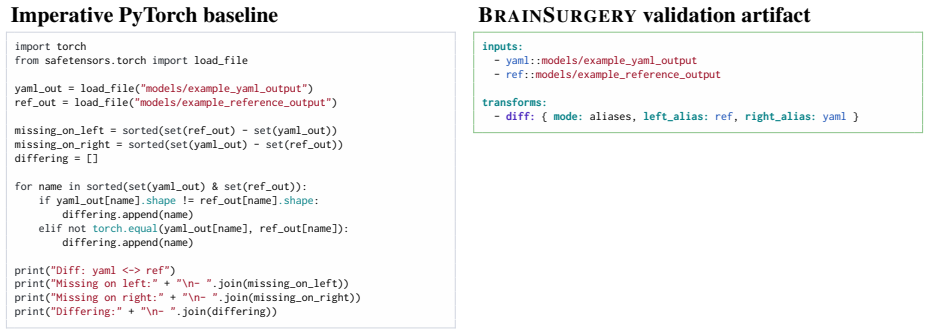
BrainSurgery executes complex transformations through declarative YAML plans. It supports structural modifications, mathematical transformations, and tensor reshaping through expressive regex and structural targeting, while built-in assertions validate tensor shapes, data types, and values to prevent silent errors.
What carries the argument
Declarative YAML plans that abstract storage formats and memory management, using regex and structural targeting to select and alter tensors.
If this is right
- Layer restructuring and precision changes can be documented in shareable YAML files instead of scattered code.
- Assertions reduce the chance that shape or type mismatches go unnoticed during upcycling workflows.
- LoRA extraction and similar adapter operations become repeatable across different base models.
Where Pith is reading between the lines
- If YAML plans prove general enough, they could serve as a common interchange format for recording weight changes in published models.
- Version-control systems could track the YAML plans themselves, creating an auditable history of model modifications.
Load-bearing premise
The declarative YAML plans and their abstractions can express the full range of needed transformations without users reverting to custom scripts, and the assertions will catch all relevant errors during real use.
What would settle it
A standard editing operation such as merging two checkpoints or applying low-rank updates that cannot be written as a YAML plan or that passes all assertions yet yields an incorrect resulting model.
Figures








read the original abstract
As deep learning models scale, managing, inspecting, and modifying large checkpoints has become increasingly challenging. Researchers often need to alter model weights for layer restructuring, precision casting, low-rank factorization, and architectural debugging, yet these workflows often rely on fragile ad-hoc Python scripts. Here, we introduce BrainSurgery, a tool for robust and reproducible "tensor surgery" on neural network checkpoints, and provide a system demonstration covering four examples and three case studies from model upcycling to LoRA extraction. By abstracting storage formats and memory management, BrainSurgery executes complex transformations through declarative YAML plans. It supports structural modifications, mathematical transformations, and tensor reshaping through expressive regex and structural targeting, while built-in assertions validate tensor shapes, data types, and values to prevent silent errors. We envision that BrainSurgery will provide a strong foundation for future research through its reproducible and validated operations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents BrainSurgery, a tool for reproducible and reliable declarative weight manipulations on neural network checkpoints. It abstracts storage formats and memory management to enable complex transformations (structural modifications, mathematical operations, tensor reshaping) via expressive regex and structural targeting in YAML plans, with built-in assertions for validating shapes, dtypes, and values to avoid silent errors. The work provides four examples and three case studies covering model upcycling and LoRA extraction.
Significance. If the central claims hold, the tool offers a practical advance by replacing ad-hoc Python scripts with validated, declarative workflows, which could improve reproducibility in model editing and upcycling research. The emphasis on assertions and abstractions for storage/memory is a concrete strength; the inclusion of multiple case studies demonstrates utility beyond toy examples.
major comments (2)
- [Case studies and examples sections] The claim that regex+structural targeting in YAML plans plus the storage/memory abstractions suffice for the full range of practical transformations (layer restructuring, low-rank factorization, etc.) without fallback to ad-hoc scripts is load-bearing for the paper's contribution, yet the demonstrations provide only positive examples rather than a systematic enumeration or boundary test of supported vs. unsupported operations.
- [Assertions and validation description] The assertion system is presented as preventing silent errors, but no evidence is given on its coverage (e.g., which classes of shape/dtype/value errors arise in the case studies and whether they are all caught), which is required to substantiate the reliability claim.
minor comments (2)
- Clarify the distinction between the four examples and three case studies, and consider adding a summary table of supported YAML operations.
- The manuscript would benefit from explicit discussion of limitations or operations that remain outside the declarative interface.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments correctly identify areas where additional evidence would strengthen the manuscript's claims. We outline targeted revisions below.
read point-by-point responses
-
Referee: [Case studies and examples sections] The claim that regex+structural targeting in YAML plans plus the storage/memory abstractions suffice for the full range of practical transformations (layer restructuring, low-rank factorization, etc.) without fallback to ad-hoc scripts is load-bearing for the paper's contribution, yet the demonstrations provide only positive examples rather than a systematic enumeration or boundary test of supported vs. unsupported operations.
Authors: We agree that the current presentation relies on positive demonstrations and does not systematically delineate supported versus unsupported operations. In revision we will add a new subsection that enumerates the transformation classes expressible via the YAML syntax and abstractions (structural targeting, regex-based selection, arithmetic and reshaping primitives), provides concrete examples of each, and explicitly notes classes of operations (e.g., certain dynamic control-flow or architecture-specific low-rank updates) that still require fallback scripts. This will make the scope and limitations of the declarative approach transparent. revision: yes
-
Referee: [Assertions and validation description] The assertion system is presented as preventing silent errors, but no evidence is given on its coverage (e.g., which classes of shape/dtype/value errors arise in the case studies and whether they are all caught), which is required to substantiate the reliability claim.
Authors: We concur that concrete evidence of assertion coverage is needed. The revised manuscript will include an analysis (new table and accompanying text) that logs every assertion executed across the three case studies, reports the specific shape, dtype, and value mismatches that were caught, and discusses error classes that the current assertion set does not yet address. We will also expand the methods section to describe the assertion API and its design rationale more explicitly. revision: yes
Circularity Check
No circularity: tool description with no derivations or fitted predictions
full rationale
The paper is a system demonstration of a software tool for model editing via declarative YAML plans. It contains no equations, no first-principles derivations, no fitted parameters presented as predictions, and no uniqueness theorems or self-citation chains that bear load on any claimed result. All content consists of feature descriptions, examples, and case studies whose validity rests on external reproducibility rather than internal reduction to inputs. This is the expected non-finding for a non-mathematical engineering paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Eleventh International Conference on Learning Representations , year =
Editing Models with Task Arithmetic , author =. The Eleventh International Conference on Learning Representations , year =
-
[2]
and Bansal, Mohit , booktitle =
Yadav, Prateek and Tam, Derek and Choshen, Leshem and Raffel, Colin A. and Bansal, Mohit , booktitle =. 2023 , url =
2023
-
[3]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[4]
IEEE transactions on pattern analysis and machine intelligence , volume=
Structured pruning for deep convolutional neural networks: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2023 , publisher=
2023
-
[5]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2024 , publisher=
2024
-
[6]
Proceedings of the National Academy of Sciences , volume =
Overcoming Catastrophic Forgetting in Neural Networks , author =. Proceedings of the National Academy of Sciences , volume =. 2017 , doi =
2017
-
[7]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
A Continual Learning Survey: Defying Forgetting in Classification Tasks , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2022 , doi =
2022
-
[8]
ACM Computing Surveys , volume=
Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportunities , author=. ACM Computing Surveys , volume=. 2026 , publisher=
2026
-
[9]
arXiv preprint arXiv:2309.00244 , year=
NeuroSurgeon: A Toolkit for Subnetwork Analysis , author=. arXiv preprint arXiv:2309.00244 , year=. doi:10.48550/arXiv.2309.00244 , url=
-
[10]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. arXiv preprint arXiv:2303.08112 , year=. doi:10.48550/arXiv.2303.08112 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08112
-
[11]
2022 , howpublished=
TransformerLens , author=. 2022 , howpublished=
2022
-
[12]
arXiv preprint arXiv:2403.13257 , year=
Arcee's MergeKit: A Toolkit for Merging Large Language Models , author=. arXiv preprint arXiv:2403.13257 , year=. doi:10.48550/arXiv.2403.13257 , url=
-
[13]
Findings of the Association for Computational Linguistics: EMNLP 2024 , month = nov, year =
A Unified Framework for Model Editing , author =. Findings of the Association for Computational Linguistics: EMNLP 2024 , month = nov, year =. doi:10.18653/v1/2024.findings-emnlp.903 , url =
-
[14]
Interpreto: An Explainability Library for Transformers
Interpreto: An Explainability Library for Transformers , author=. arXiv preprint arXiv:2512.09730 , year=. doi:10.48550/arXiv.2512.09730 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.09730
-
[15]
arXiv preprint arXiv:2407.14561 , year=
NNsight and NDIF: Democratizing Access to Open-Weight Foundation Model Internals , author=. arXiv preprint arXiv:2407.14561 , year=. doi:10.48550/arXiv.2407.14561 , url=
-
[16]
arXiv preprint arXiv:2511.14465 , year=
nnterp: A Standardized Interface for Mechanistic Interpretability of Transformers , author=. arXiv preprint arXiv:2511.14465 , year=. doi:10.48550/arXiv.2511.14465 , url=
-
[17]
Advances in Neural Information Processing Systems 35 (NeurIPS 2022) , year=
Locating and Editing Factual Associations in GPT , author=. Advances in Neural Information Processing Systems 35 (NeurIPS 2022) , year=
2022
-
[18]
Mass-Editing Memory in a Transformer
Mass-Editing Memory in a Transformer , author=. arXiv preprint arXiv:2210.07229 , year=. doi:10.48550/arXiv.2210.07229 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.07229
-
[19]
Zhao, Haiyan and Chen, Hanjie and Yang, Fan and Liu, Ninghao and Deng, Huiqi and Cai, Hengyi and Wang, Shuaiqiang and Yin, Dawei and Du, Mengnan , title =. ACM Trans. Intell. Syst. Technol. , month = feb, articleno =. 2024 , issue_date =. doi:10.1145/3639372 , abstract =
-
[20]
2026 , eprint=
A Comprehensive Survey of Mixture-of-Experts: Algorithms, Theory, and Applications , author=. 2026 , eprint=
2026
-
[21]
2025 , eprint=
OLMoE: Open Mixture-of-Experts Language Models , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
FlexOlmo: Open Language Models for Flexible Data Use , author=. 2025 , eprint=
2025
-
[23]
2026 , eprint=
FlexMoRE: A Flexible Mixture of Rank-heterogeneous Experts for Efficient Federatedly-trained Large Language Models , author=. 2026 , eprint=
2026
-
[24]
2025 , eprint=
PHLoRA: data-free Post-hoc Low-Rank Adapter extraction from full-rank checkpoint , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.