Evaluating the Representation Space of Diffusion Models via Self-Supervised Principles
Pith reviewed 2026-06-27 17:37 UTC · model grok-4.3
The pith
Diffusion models reach peak invariance at intermediate noise levels that optimize classification, with a new ratio detecting memorization from training features alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
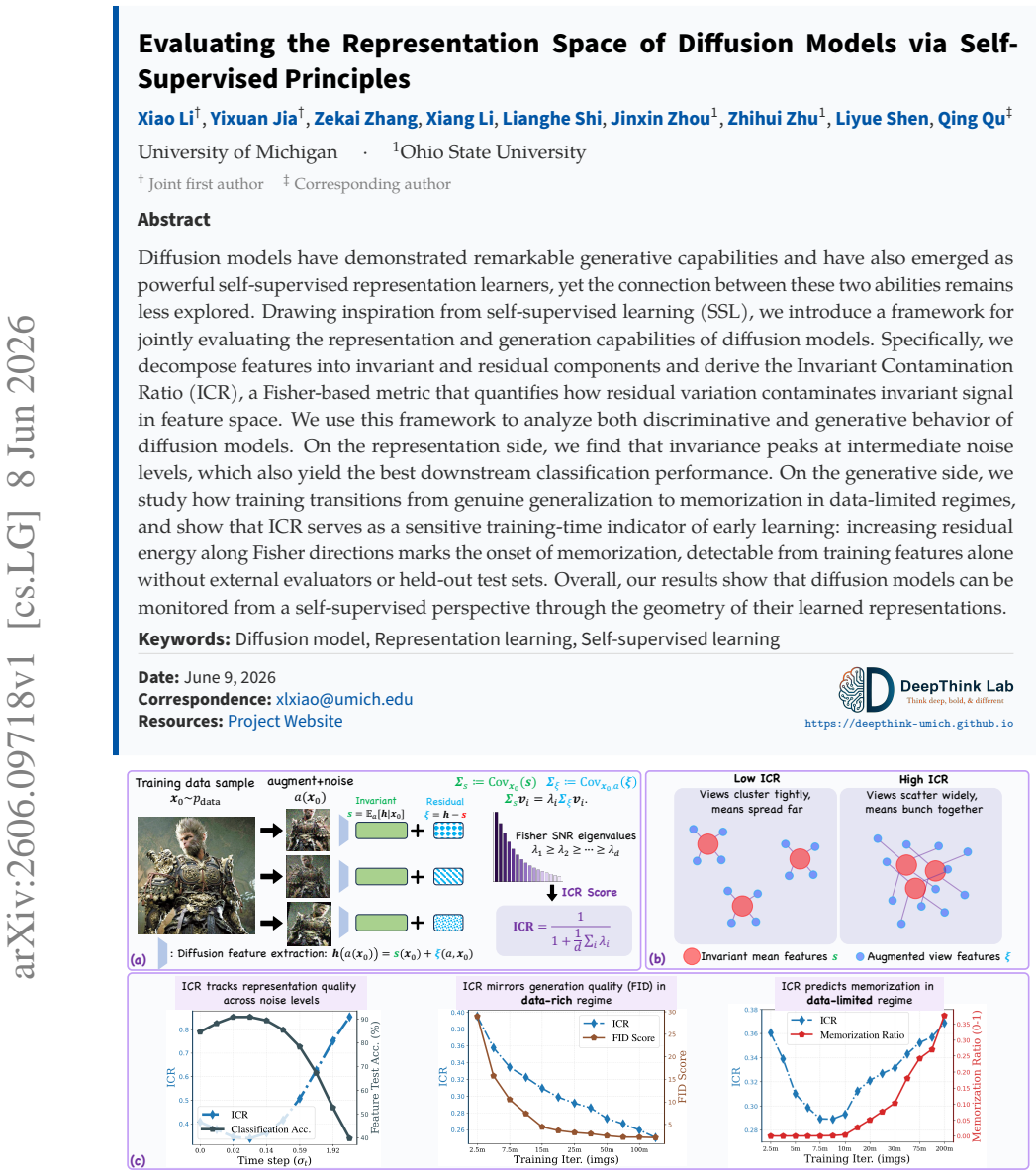
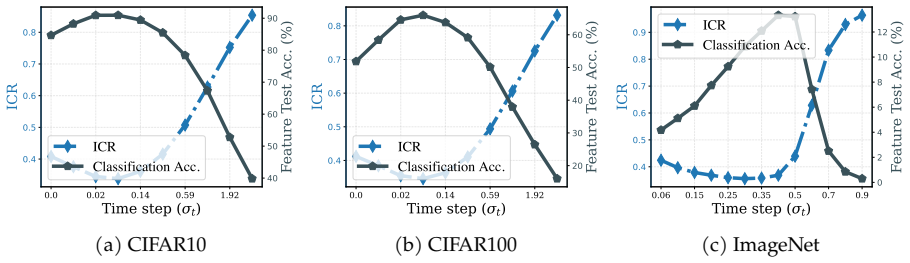
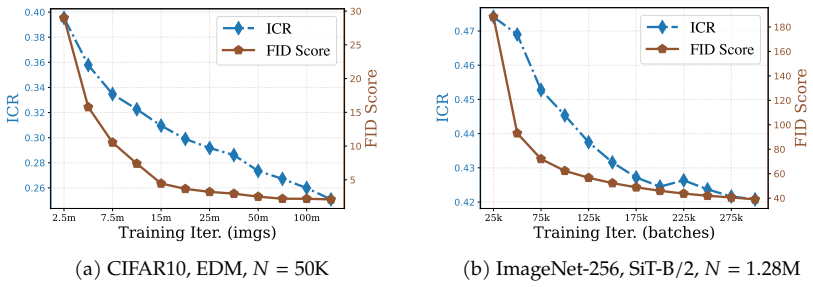
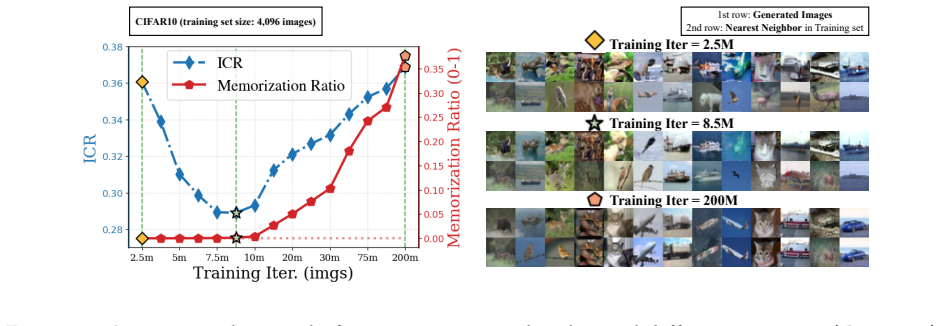
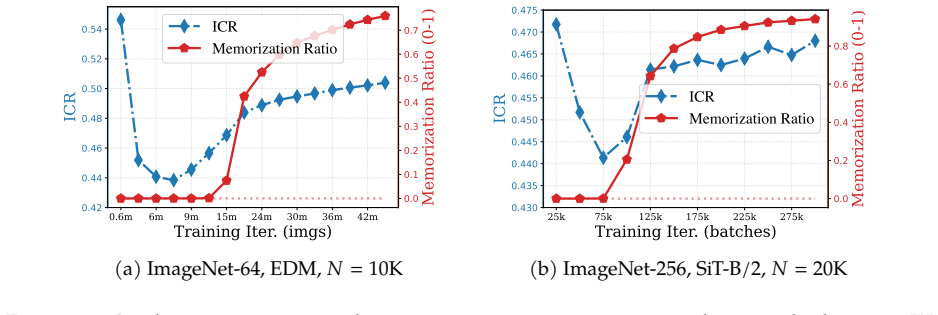
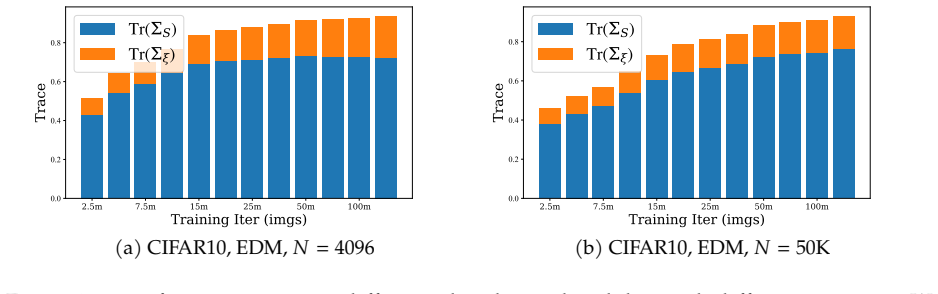
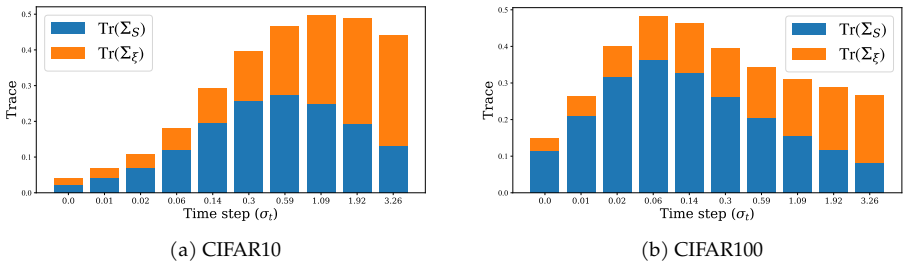
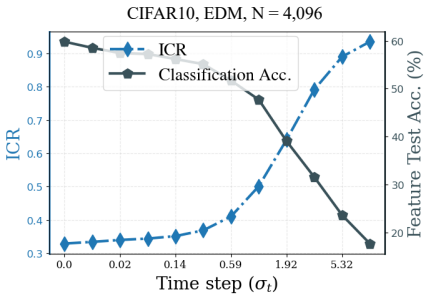
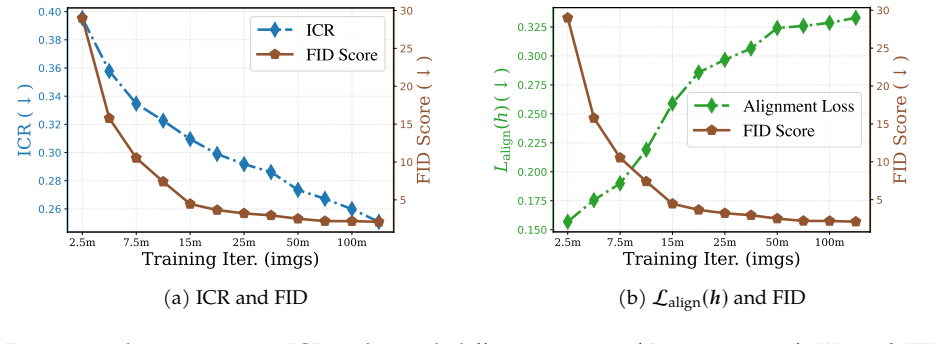
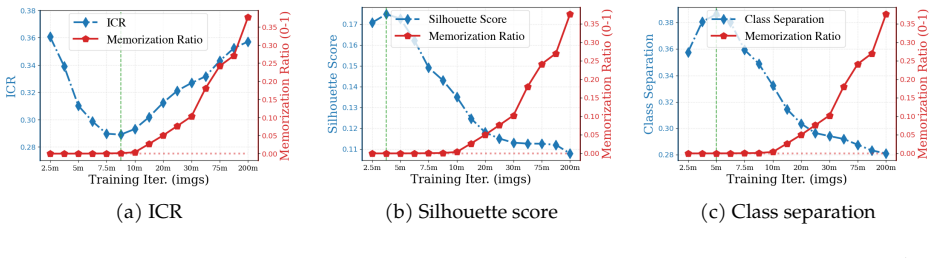
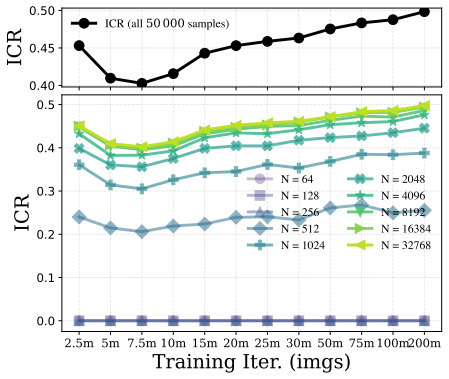
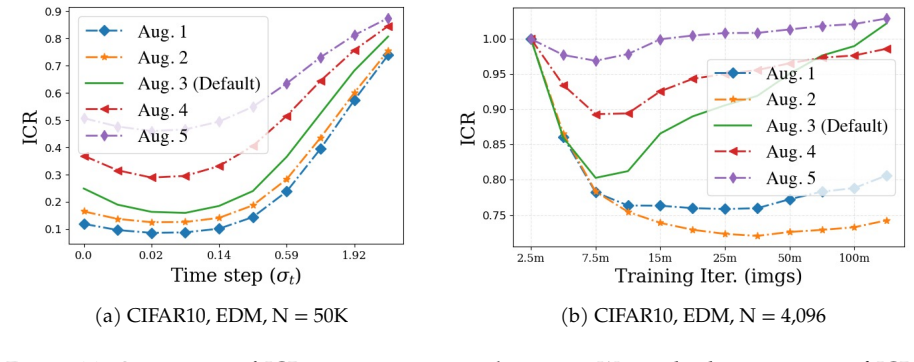
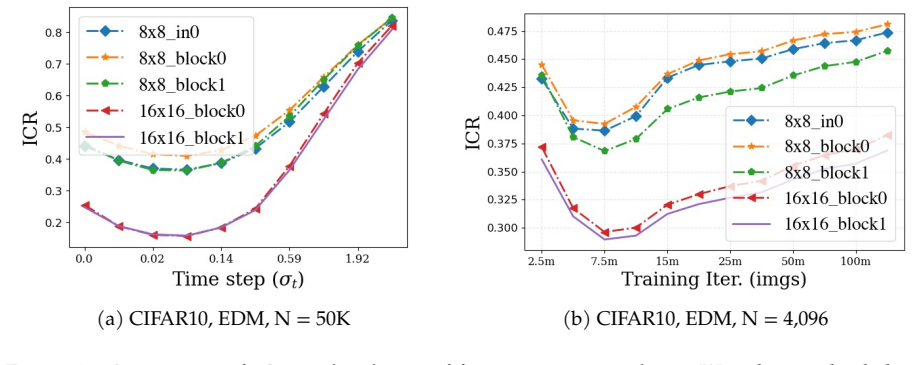
We decompose features extracted from diffusion models into invariant and residual components and introduce the Invariant Contamination Ratio (ICR), a Fisher-based metric quantifying contamination of invariant signal by residual variation. This framework reveals that invariance is maximized at intermediate noise levels, which also produce the highest accuracy in downstream classification. On the generative side, increasing residual energy along Fisher directions in ICR indicates the transition from generalization to memorization in data-limited settings, and this can be detected solely from features during training.
What carries the argument
The Invariant Contamination Ratio (ICR), a Fisher-based metric that quantifies how residual variation contaminates invariant signal in the feature space of diffusion models.
If this is right
- Invariance peaks at intermediate noise levels coincide with the best downstream classification performance.
- Rising residual energy along Fisher directions in ICR marks the onset of memorization during training.
- Memorization can be detected using only training features without external evaluators or held-out test sets.
- Diffusion models can be monitored jointly for representation and generation quality through the geometry of their learned representations.
Where Pith is reading between the lines
- The alignment between invariance peaks and classification performance could guide selection of noise levels when using diffusion models as fixed feature extractors for other tasks.
- Early ICR-based detection of memorization might support training interventions that preserve generalization in data-scarce regimes.
- The self-supervised decomposition approach could be tested on whether it reveals similar invariance-memorization patterns in non-diffusion generative models.
- The framework provides a way to study how noise schedules affect both generative fidelity and representation utility without separate evaluation pipelines.
Load-bearing premise
The decomposition of features into invariant and residual components accurately isolates signal causally relevant to classification performance and memorization without being driven by the same Fisher directions used to define the metric.
What would settle it
Measure whether the noise level that maximizes invariance also maximizes classification accuracy on a held-out validation set, or whether ICR begins rising before test-set performance drops confirm the start of memorization.
Figures


read the original abstract
Diffusion models have demonstrated remarkable generative capabilities and have also emerged as powerful self-supervised representation learners, yet the connection between these two abilities remains less explored. Drawing inspiration from self-supervised learning (SSL), we introduce a framework for jointly evaluating the representation and generation capabilities of diffusion models. Specifically, we decompose features into invariant and residual components and derive the Invariant Contamination Ratio (ICR), a Fisher-based metric that quantifies how residual variation contaminates invariant signal in feature space. We use this framework to analyze both discriminative and generative behavior of diffusion models. On the representation side, we find that invariance peaks at intermediate noise levels, which also yield the best downstream classification performance. On the generative side, we study how training transitions from genuine generalization to memorization in data-limited regimes, and show that ICR serves as a sensitive training-time indicator of early learning: increasing residual energy along Fisher directions marks the onset of memorization, detectable from training features alone without external evaluators or held-out test sets. Overall, our results show that diffusion models can be monitored from a self-supervised perspective through the geometry of their learned representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a self-supervised framework for diffusion models that decomposes learned features into invariant and residual components, then defines the Invariant Contamination Ratio (ICR) as a Fisher-information-based metric quantifying residual contamination of invariant signal. It reports that invariance peaks at intermediate noise levels, which also produce the strongest downstream classification accuracy, and that rising residual energy along Fisher directions in ICR serves as an early, training-only indicator of the transition from generalization to memorization in data-limited regimes.
Significance. If the invariant/residual decomposition is shown to be independent of the Fisher geometry later used for ICR, the framework would supply a geometry-driven, self-supervised diagnostic for both representation quality and memorization onset that requires no held-out data or external probes. This could be useful for monitoring diffusion training dynamics and for linking generative and discriminative behavior through representation geometry.
major comments (2)
- [Abstract / Method] Abstract and method description: the decomposition of features into invariant and residual components is presented prior to the definition of ICR, yet no explicit statement or equation shows that the split is performed without reference to the same Fisher directions subsequently used to compute residual energy in ICR. If the decomposition step employs Fisher information (or equivalent geometry) to identify invariant directions, the subsequent claim that ICR independently tracks classification performance and memorization onset is at risk of being true by construction rather than by isolating causally relevant signal.
- [Results / Memorization analysis] Results on memorization detection: the claim that ICR marks the onset of memorization from training features alone rests on the assumption that the invariant/residual split isolates signal causally relevant to both downstream classification and memorization behavior. No ablation or alternative decomposition (e.g., random or PCA-based splits) is referenced to test whether the observed correlation with memorization is specific to the proposed split or would appear under any residual-energy metric.
minor comments (2)
- [Method] Notation for the invariant and residual components should be introduced with explicit equations rather than descriptive text only.
- [Abstract] The abstract states that invariance peaks at intermediate noise levels; the corresponding figure or table reporting the peak location and its alignment with classification accuracy should be cited in the abstract or introduction.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on the independence of the invariant/residual decomposition and the specificity of the memorization results. We address both points below.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the decomposition of features into invariant and residual components is presented prior to the definition of ICR, yet no explicit statement or equation shows that the split is performed without reference to the same Fisher directions subsequently used to compute residual energy in ICR. If the decomposition step employs Fisher information (or equivalent geometry) to identify invariant directions, the subsequent claim that ICR independently tracks classification performance and memorization onset is at risk of being true by construction rather than by isolating causally relevant signal.
Authors: The invariant/residual decomposition is derived from self-supervised principles inspired by SSL and the structure of the diffusion process (feature consistency across noise levels), without reference to Fisher information. Fisher geometry is introduced only later to define ICR as a contamination measure. This ordering is already indicated in the abstract and Section 3, but we agree an explicit clarifying statement and equation would remove ambiguity. We will add this in the revised method section. revision: yes
-
Referee: [Results / Memorization analysis] Results on memorization detection: the claim that ICR marks the onset of memorization from training features alone rests on the assumption that the invariant/residual split isolates signal causally relevant to both downstream classification and memorization behavior. No ablation or alternative decomposition (e.g., random or PCA-based splits) is referenced to test whether the observed correlation with memorization is specific to the proposed split or would appear under any residual-energy metric.
Authors: We note that the manuscript already shows ICR correlates with independently measured downstream classification accuracy on held-out data, which is external to the Fisher-based ICR computation and supports that the split isolates causally relevant signal. For the memorization analysis, we will add a discussion paragraph explaining the theoretical motivation for the self-supervised split and why random or PCA-based alternatives would not be expected to produce the same training-only early-warning behavior. However, we do not have the requested ablations in the current work. revision: partial
Circularity Check
No circularity: decomposition and ICR presented as independent construction without shown reduction
full rationale
The provided abstract and description introduce a decomposition of features into invariant/residual components followed by derivation of ICR as a Fisher-based metric quantifying residual contamination. No equations are shown that would allow verification of whether the decomposition step itself is performed using the same Fisher directions later used to compute ICR. The claims about invariance peaking at intermediate noise levels and ICR tracking memorization are presented as empirical findings from the framework rather than tautological outputs of a fitted quantity. Per the rules, without a quotable reduction (e.g., Eq. X defined in terms of the same Fisher geometry used for the ratio), no circular step is exhibited. The derivation chain is therefore treated as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” inInternational conference on machine learning, pp. 2256–2265, pmlr, 2015
2015
-
[2]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
2020
-
[3]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learning Representations, 2021
2021
-
[4]
Diffusion-based adversarial purification for robust deep mri reconstruction,
I. Alkhouri, S. Liang, R. Wang, Q. Qu, and S. Ravishankar, “Diffusion-based adversarial purification for robust deep mri reconstruction,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 12841–12845, IEEE, 2024
2024
-
[5]
ForcingDAS: Unified and Robust Data Assimilation via Diffusion Forcing
Y. Jia, S. Chen, Y. Pan, X. Li, L. Shi, C. Jung, H. Yuan, I. Alkhouri, Y. C. Wu, S. Ravishankar,et al., “Forcingdas: Unifiedandrobustdataassimilationviadiffusionforcing,”arXivpreprintarXiv:2605.14285, 2026. 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Solving inverse problems with latent diffusion models via hard data consistency,
B. Song, S. M. Kwon, Z. Zhang, X. Hu, Q. Qu, and L. Shen, “Solving inverse problems with latent diffusion models via hard data consistency,” inInternational Conference on Learning Representations, vol. 2024, pp. 7624–7654, 2024
2024
-
[7]
Decoupled data consistency with diffusion purification for image restoration,
X. Li, S. M. Kwon, S. Liang, I. R. Alkhouri, S. Ravishankar, and Q. Qu, “Decoupled data consistency with diffusion purification for image restoration,”arXiv preprint arXiv:2403.06054, 2024
-
[8]
De novo design of protein structure and function with rfdiffusion,
J. L. Watson, D. Juergens, N. R. Bennett, B. L. Trippe, J. Yim, H. E. Eisenach, W. Ahern, A. J. Borst, R. J. Ragotte, L. F. Milles,et al., “De novo design of protein structure and function with rfdiffusion,”Nature, 2023
2023
-
[9]
Discrete diffusion modeling by estimating the ratios of the data distribution,
A. Lou, C. Meng, and S. Ermon, “Discrete diffusion modeling by estimating the ratios of the data distribution,” inInternational Conference on Machine Learning, pp. 32819–32848, PMLR, 2024
2024
-
[10]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,
B. F. Labs, S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulal, K. Lacey, Y. Levi, C. Li, D. Lorenz, J. Müller, D. Podell, R. Rombach, H. Saini, A. Sauer, and L. Smith, “Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,”arXiv preprint, 2025
2025
-
[11]
Veo 3: Google’s most capable video generation model,
Google, “Veo 3: Google’s most capable video generation model,” tech. rep., Google, 2025
2025
-
[12]
Label-efficient semantic segmen- tation with diffusion models,
D. Baranchuk, A. Voynov, I. Rubachev, V. Khrulkov, and A. Babenko, “Label-efficient semantic segmen- tation with diffusion models,” inInternational Conference on Learning Representations, 2022
2022
-
[13]
Denoising diffusion autoencoders are unified self- supervisedlearners,
W. Xiang, H. Yang, D. Huang, and Y. Wang, “Denoising diffusion autoencoders are unified self- supervisedlearners,”inProceedingsoftheIEEE/CVFInternationalConferenceonComputerVision,pp.15802– 15812, 2023
2023
-
[14]
Diffusion models beat gans on image classification,
S.Mukhopadhyay,M.Gwilliam,V.Agarwal,N.Padmanabhan,A.Swaminathan,S.Hegde,T.Zhou,and A. Shrivastava, “Diffusion models beat gans on image classification,”arXiv preprint arXiv:2307.08702, 2023
-
[15]
Deconstructing denoising diffusion models for self-supervised learning,
X. Chen, Z. Liu, S. Xie, and K. He, “Deconstructing denoising diffusion models for self-supervised learning,” inInternational Conference on Learning Representations, vol. 2025, pp. 55458–55472, 2025
2025
-
[16]
Emergentcorrespondencefromimagediffusion,
L.Tang,M.Jia,Q.Wang,C.P.Phoo,andB.Hariharan,“Emergentcorrespondencefromimagediffusion,” Advances in Neural Information Processing Systems, vol. 36, pp. 1363–1389, 2023
2023
-
[17]
Dinov2: Learning robust visual features without supervision,
M.Oquab,T.Darcet,T.Moutakanni,H.Vo,M.Szafraniec,V.Khalidov,P.Fernandez,D.Haziza,F.Massa, A. El-Nouby,et al., “Dinov2: Learning robust visual features without supervision,”Transactions on Machine Learning Research, 2024
2024
-
[18]
Maskedautoencodersarescalablevisionlearners,
K.He,X.Chen,S.Xie,Y.Li,P.Dollár,andR.Girshick,“Maskedautoencodersarescalablevisionlearners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16000–16009, 2022
2022
-
[19]
Representation alignment for genera- tion: Training diffusion transformers is easier than you think,
S. Yu, S. Kwak, H. Jang, J. Jeong, J. Huang, J. Shin, and S. Xie, “Representation alignment for genera- tion: Training diffusion transformers is easier than you think,” inInternational Conference on Learning Representations, 2025
2025
-
[20]
What matters for repre- sentation alignment: Global information or spatial structure?,
J. Singh, X. Leng, Z. Wu, L. Zheng, R. Zhang, E. Shechtman, and S. Xie, “What matters for repre- sentation alignment: Global information or spatial structure?,” inInternational Conference on Learning Representations, 2026
2026
-
[21]
Vicreg: Variance-invariance-covariance regularization for self- supervised learning,
A. Bardes, J. Ponce, and Y. LeCun, “Vicreg: Variance-invariance-covariance regularization for self- supervised learning,” inInternational Conference on Learning Representations, 2022
2022
-
[22]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational conference on machine learning, pp. 1597–1607, PMLR, 2020. 14
2020
-
[23]
Exploring low-dimensional subspace in diffusionmodelsforcontrollableimageediting,
S. Chen, H. Zhang, M. Guo, Y. Lu, P. Wang, and Q. Qu, “Exploring low-dimensional subspace in diffusionmodelsforcontrollableimageediting,”Advancesinneuralinformationprocessingsystems,vol.37, pp. 27340–27371, 2024
2024
-
[24]
Barlow twins: Self-supervised learning via redun- dancy reduction,
J. Zbontar, L. Jing, I. Misra, Y. LeCun, and S. Deny, “Barlow twins: Self-supervised learning via redun- dancy reduction,” inInternational conference on machine learning, pp. 12310–12320, PMLR, 2021
2021
-
[25]
Diffusion models learn low-dimensional distributions via subspace clustering,
P. Wang, H. Zhang, Z. Zhang, S. Chen, Y. Ma, and Q. Qu, “Diffusion models learn low-dimensional distributions via subspace clustering,”arXiv preprint, 2024
2024
-
[26]
Understanding representation dynamics of diffusion models via low-dimensional modeling,
X. Li, Z. Zhang, X. Li, S. Chen, Z. Zhu, P. Wang, and Q. Qu, “Understanding representation dynamics of diffusion models via low-dimensional modeling,”Advances in Neural Information Processing Systems, vol. 38, pp. 107365–107404, 2026
2026
-
[27]
On the generalization properties of diffusion models,
P. Li, Z. Li, H. Zhang, and J. Bian, “On the generalization properties of diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 2097–2127, 2023
2097
-
[28]
Understanding generalizability of diffusion models requires rethinking the hidden gaussian structure,
X. Li, Y. Dai, and Q. Qu, “Understanding generalizability of diffusion models requires rethinking the hidden gaussian structure,”Advances in neural information processing systems, vol. 37, pp. 57499–57538, 2024
2024
-
[29]
Understanding generalization in diffusion models via probability flow distance,
H. Zhang, Z. Huang, S. Chen, J. Zhou, Z. Zhang, P. Wang, and Q. Qu, “Understanding generalization in diffusion models via probability flow distance,”arXiv preprint arXiv:2505.20123, 2025
-
[30]
Memorizationandregularization in generative diffusion models,
R.Baptista,A.Dasgupta,N.B.Kovachki,A.Oberai,andA.M.Stuart,“Memorizationandregularization in generative diffusion models,”arXiv preprint arXiv:2501.15785, 2025
-
[31]
Why diffusion models don’t memorize: The role of implicit dynamical regularization in training,
T. Bonnaire, R. Urfin, G. Biroli, and M. Mézard, “Why diffusion models don’t memorize: The role of implicit dynamical regularization in training,”Advances in Neural Information Processing Systems, vol. 38, pp. 141266–141286, 2026
2026
-
[32]
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models,
G.Stein, J.Cresswell, R.Hosseinzadeh, Y.Sui, B. Ross, V. Villecroze, Z.Liu, A.L.Caterini, E.Taylor, and G. Loaiza-Ganem, “Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 3732–3784, 2023
2023
-
[33]
A self-supervised descriptor for image copy detection,
E. Pizzi, S. D. Roy, S. N. Ravindra, P. Goyal, and M. Douze, “A self-supervised descriptor for image copy detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14532–14542, 2022
2022
-
[34]
The emergence of reproducibility and consistency in diffusion models,
H. Zhang, J. Zhou, Y. Lu, M. Guo, P. Wang, L. Shen, and Q. Qu, “The emergence of reproducibility and consistency in diffusion models,” inInternational Conference on Machine Learning, pp. 60558–60590, PMLR, 2024
2024
-
[35]
Reverse-time diffusion equation models,
B. D. Anderson, “Reverse-time diffusion equation models,”Stochastic Processes and their Applications, vol. 12, no. 3, pp. 313–326, 1982
1982
-
[36]
Tweedie’s formula and selection bias,
B. Efron, “Tweedie’s formula and selection bias,”Journal of the American Statistical Association, 2011
2011
-
[37]
Generalization in diffusion models arises from geometry-adaptive harmonic representations,
Z. Kadkhodaie, F. Guth, E. Simoncelli, and S. Mallat, “Generalization in diffusion models arises from geometry-adaptive harmonic representations,” inInternational Conference on Learning Representations, vol. 2024, pp. 46543–46567, 2024
2024
-
[38]
U-net: Convolutionalnetworksforbiomedicalimagesegmenta- tion,
O.Ronneberger,P.Fischer,andT.Brox,“U-net: Convolutionalnetworksforbiomedicalimagesegmenta- tion,”inInternationalConferenceonMedicalimagecomputingandcomputer-assistedintervention,pp.234–241, Springer, 2015
2015
-
[39]
Elucidating the design space of diffusion-based generative models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models,”Advances in neural information processing systems, vol. 35, pp. 26565–26577, 2022. 15
2022
-
[40]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers,
N. Ma, M. Goldstein, M. S. Albergo, N. M. Boffi, E. Vanden-Eijnden, and S. Xie, “Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers,” inEuropean Conference on Computer Vision, pp. 23–40, Springer, 2024
2024
-
[41]
Diffusionmodelsandrepresentation learning: A survey,
M.Fuest,P.Ma,M.Gui,J.Schusterbauer,V.T.Hu,andB.Ommer,“Diffusionmodelsandrepresentation learning: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[42]
Momentum contrast for unsupervised visual repre- sentation learning,
K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual repre- sentation learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9729–9738, 2020
2020
-
[43]
Bootstrap your own latent-a new approach to self-supervised learning,
J.-B.Grill, F.Strub, F.Altché, C.Tallec, P.Richemond, E.Buchatskaya, C.Doersch, B.AvilaPires, Z.Guo, M. Gheshlaghi Azar,et al., “Bootstrap your own latent-a new approach to self-supervised learning,” Advances in neural information processing systems, vol. 33, pp. 21271–21284, 2020
2020
-
[44]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
Understanding contrastive representation learning through alignment and uniformity on the hypersphere,
T. Wang and P. Isola, “Understanding contrastive representation learning through alignment and uniformity on the hypersphere,” inInternational conference on machine learning, pp. 9929–9939, PMLR, 2020
2020
-
[46]
Fukunaga,Introduction to Statistical Pattern Recognition
K. Fukunaga,Introduction to Statistical Pattern Recognition. Academic Press, 2 ed., 1990. Second edition
1990
-
[47]
R. A. Horn and C. R. Johnson,Matrix analysis. Cambridge university press, 2012
2012
-
[48]
The use of multiple measurements in taxonomic problems,
R. A. Fisher, “The use of multiple measurements in taxonomic problems,”Annals of Eugenics, vol. 7, no. 2, pp. 179–188, 1936
1936
-
[49]
Learningmultiplelayersoffeaturesfromtinyimages,
A.Krizhevsky,“Learningmultiplelayersoffeaturesfromtinyimages,”tech.rep.,UniversityofToronto, 2009
2009
-
[50]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition, pp. 248–255, Ieee, 2009
2009
-
[51]
B. Wang and J. J. Vastola, “Diffusion models generate images like painters: an analytical theory of outline first, details later,”arXiv preprint arXiv:2303.02490, 2023
-
[52]
Ganstrainedbyatwotime-scale update rule converge to a local nash equilibrium,
M.Heusel,H.Ramsauer,T.Unterthiner,B.Nessler,andS.Hochreiter,“Ganstrainedbyatwotime-scale update rule converge to a local nash equilibrium,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[53]
Going deeper with convolutions,
C.Szegedy,W.Liu,Y.Jia,P.Sermanet,S.Reed,D.Anguelov,D.Erhan,V.Vanhoucke,andA.Rabinovich, “Going deeper with convolutions,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 1–9, 2015
2015
-
[54]
Generalization of diffusion models arises with a balanced representation space,
Z. Zhang, X. Li, X. Li, L. Shi, M. Wu, M. Tao, and Q. Qu, “Generalization of diffusion models arises with a balanced representation space,” inInternational Conference on Learning Representations, 2026
2026
-
[55]
Learningdatarepresentationswithjointdiffusionmodels,
K.Deja,T.Trzciński,andJ.M.Tomczak,“Learningdatarepresentationswithjointdiffusionmodels,”in JointEuropeanConferenceonMachineLearningandKnowledgeDiscoveryinDatabases,pp.543–559,Springer, 2023
2023
-
[56]
A tale of two features: Stablediffusioncomplementsdinoforzero-shotsemanticcorrespondence,
J. Zhang, C. Herrmann, J. Hur, L. Polania Cabrera, V. Jampani, D. Sun, and M.-H. Yang, “A tale of two features: Stablediffusioncomplementsdinoforzero-shotsemanticcorrespondence,”AdvancesinNeural Information Processing Systems, vol. 36, pp. 45533–45547, 2023. 16
2023
-
[57]
Dragdiffusion: Harnessing diffusion models for interactive point-based image editing,
Y. Shi, C. Xue, J. H. Liew, J. Pan, H. Yan, W. Zhang, V. Y. Tan, and S. Bai, “Dragdiffusion: Harnessing diffusion models for interactive point-based image editing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8839–8849, 2024
2024
-
[58]
Diffaug: A diffuse-and-denoise augmentation for training robust classifiers,
C. S. Sastry, S. H. Dumpala, and S. Oore, “Diffaug: A diffuse-and-denoise augmentation for training robust classifiers,”Advances in Neural Information Processing Systems, 2024
2024
-
[59]
Diffusion model as representation learner,
X. Yang and X. Wang, “Diffusion model as representation learner,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 18938–18949, 2023
2023
-
[60]
Dreamteacher: Pretraining image backbones with deep generative models,
D. Li, H. Ling, A. Kar, D. Acuna, S. W. Kim, K. Kreis, A. Torralba, and S. Fidler, “Dreamteacher: Pretraining image backbones with deep generative models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 16698–16708, 2023
2023
-
[61]
Cleandift: Diffusion features without noise,
N. Stracke, S. A. Baumann, K. Bauer, F. Fundel, and B. Ommer, “Cleandift: Diffusion features without noise,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 117–127, 2025
2025
-
[62]
Diffusionhyperfeatures: Searchingthrough time and space for semantic correspondence,
G.Luo, L.Dunlap, D.H.Park, A.Holynski, andT.Darrell, “Diffusionhyperfeatures: Searchingthrough time and space for semantic correspondence,”Advances in Neural Information Processing Systems, vol. 36, pp. 47500–47510, 2023
2023
-
[63]
Diffusionbasedrepresentationlearning,
S.Mittal,K.Abstreiter,S.Bauer,B.Schölkopf,andA.Mehrjou,“Diffusionbasedrepresentationlearning,” inInternational conference on machine learning, pp. 24963–24982, PMLR, 2023
2023
-
[64]
Infodiffusion: Representa- tion learning using information maximizing diffusion models,
Y. Wang, Y. Schiff, A. Gokaslan, W. Pan, F. Wang, C. De Sa, and V. Kuleshov, “Infodiffusion: Representa- tion learning using information maximizing diffusion models,” inInternational Conference on Machine Learning, pp. 36336–36354, PMLR, 2023
2023
-
[65]
Soda: Bottleneck diffusion models for representation learning,
D.A.Hudson, D.Zoran, M.Malinowski, A.K.Lampinen, A.Jaegle, J.L.McClelland, L.Matthey, F.Hill, and A. Lerchner, “Soda: Bottleneck diffusion models for representation learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 23115–23127, 2024
2024
-
[66]
Diffusion autoencoders: Toward a meaningful and decodable representation,
K. Preechakul, N. Chatthee, S. Wizadwongsa, and S. Suwajanakorn, “Diffusion autoencoders: Toward a meaningful and decodable representation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10619–10629, 2022
2022
-
[67]
Can diffusion models learn hidden inter-feature rules behind images?,
Y. Han, A. Han, W. Huang, C. Lu, and D. Zou, “Can diffusion models learn hidden inter-feature rules behind images?,” inInternational Conference on Machine Learning, pp. 21704–21732, PMLR, 2025
2025
-
[68]
Revisiting spectral representations in generative diffusion models,
Y. Wang, P. Wang, H. Jiang, Z. Yang, Q. Huang, and Z. Wang, “Revisiting spectral representations in generative diffusion models,” 2026
2026
-
[69]
𝛼-req : Assessing representation quality in self-supervised learning by measuring eigenspectrum decay,
K. K. Agrawal, A. K. Mondal, A. Ghosh, and B. Richards, “𝛼-req : Assessing representation quality in self-supervised learning by measuring eigenspectrum decay,”Advances in Neural Information Processing Systems, vol. 35, pp. 17626–17638, 2022
2022
-
[70]
Rankme: Assessing the downstream performance ofpretrainedself-supervisedrepresentationsbytheirrank,
Q. Garrido, R. Balestriero, L. Najman, and Y. Lecun, “Rankme: Assessing the downstream performance ofpretrainedself-supervisedrepresentationsbytheirrank,”inInternationalconferenceonmachinelearning, pp. 10929–10974, PMLR, 2023
2023
-
[71]
Lidar: Sensing linear probing performance in joint embedding ssl architectures,
V. Thilak, C. Huang, O. Saremi, L. Dinh, H. Goh, P. Nakkiran, J. Susskind, and E. Littwin, “Lidar: Sensing linear probing performance in joint embedding ssl architectures,” inInternational Conference on Learning Representations, vol. 2024, pp. 56726–56765, 2024
2024
-
[72]
An analytic theory of creativity in convolutional diffusion models,
M. Kamb and S. Ganguli, “An analytic theory of creativity in convolutional diffusion models,” in International Conference on Machine Learning, pp. 28795–28831, PMLR, 2025. 17
2025
-
[73]
A closer look at model collapse: From a generalization-to-memorization perspective,
L. Shi, M. Wu, H. Zhang, Z. Zhang, M. Tao, and Q. Qu, “A closer look at model collapse: From a generalization-to-memorization perspective,”Advances in Neural Information Processing Systems, vol. 38, pp. 40658–40691, 2026
2026
-
[74]
Losing dimensions: Geometric memorization in generative diffusion,
B.Achilli,E.Ventura,G.Silvestri,B.Pham,G.Raya,D.Krotov,C.Lucibello,andL.Ambrogioni,“Losing dimensions: Geometric memorization in generative diffusion,”arXiv preprint arXiv:2410.08727, 2024
-
[75]
On the edge of memorization in diffusion models,
S. Buchanan, D. Pai, Y. Ma, and V. De Bortoli, “On the edge of memorization in diffusion models,” Advances in Neural Information Processing Systems, vol. 38, pp. 96113–96157, 2026
2026
-
[76]
The two clocks and the innovation window: When and how generative models learn rules
B. Wang, E. L. B. Finn, and B. Liu, “The two clocks and the innovation window: When and how generative models learn rules,”arXiv preprint arXiv:2605.10019, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[77]
An analytical theory of spectral bias in the learning dynamics of diffusion models,
B. Wang and C. Pehlevan, “An analytical theory of spectral bias in the learning dynamics of diffusion models,”Advances in Neural Information Processing Systems, vol. 38, pp. 95865–95963, 2026
2026
-
[78]
Bigger isn’t always memorizing: Early stopping overparameter- ized diffusion models,
A. Favero, A. Sclocchi, and M. Wyart, “Bigger isn’t always memorizing: Early stopping overparameter- ized diffusion models,”arXiv preprint arXiv:2505.16959, 2025
-
[79]
Towards a mechanistic explanation of diffusion model generalization,
M. Niedoba, B. Zwartsenberg, K. P. Murphy, and F. Wood, “Towards a mechanistic explanation of diffusion model generalization,” inForty-second International Conference on Machine Learning, 2025
2025
-
[80]
Locality in image diffusion models emerges from data statistics,
A. Lukoianov, C. Yuan, J. Solomon, and V. Sitzmann, “Locality in image diffusion models emerges from data statistics,”Advances in Neural Information Processing Systems, vol. 38, pp. 95121–95157, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.