Adaptive directional gradients for parameterised quantum circuits
Pith reviewed 2026-06-27 16:29 UTC · model grok-4.3
The pith
Forward-mode directional derivatives yield unbiased gradient estimates for parameterised quantum circuits at tunable measurement cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
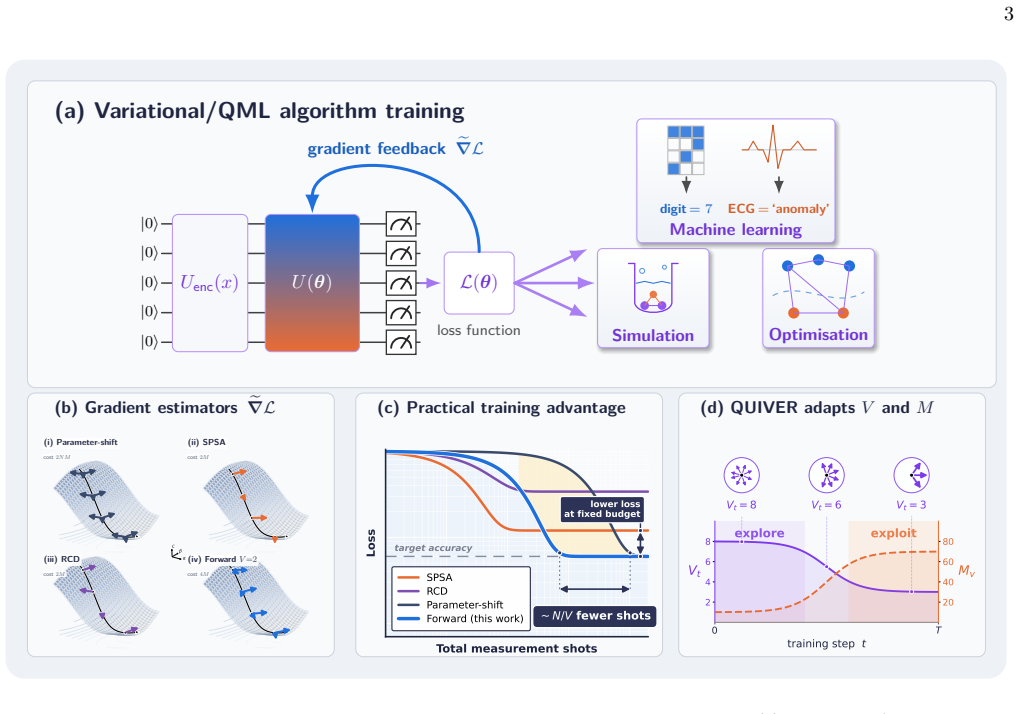
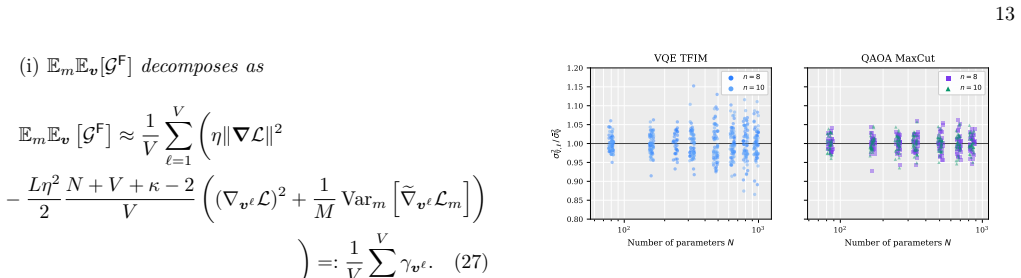
A framework of forward gradient estimators for PQCs, based on the forward mode of automatic differentiation, yields an unbiased estimator of the gradient by averaging a freely tunable number of random directional derivatives and recovers SPSA, random coordinate descent, and the parameter-shift rule as limiting cases, with no ancilla qubits or controlled-gate overhead. Stochastic quantum forward gradient descent converges under standard assumptions, with an explicit second-moment expansion that interpolates between the single-direction extreme of SPSA and the full-gradient extreme of parameter-shift. Within this framework the authors derive QUIVER, an adaptive optimiser whose update rule foll
What carries the argument
The stochastic forward gradient estimator obtained by averaging a tunable number of random directional derivatives of the circuit output expectation value.
If this is right
- Stochastic forward gradient descent converges under the same assumptions used for classical SGD.
- The variance of the estimator interpolates continuously between the SPSA and parameter-shift extremes.
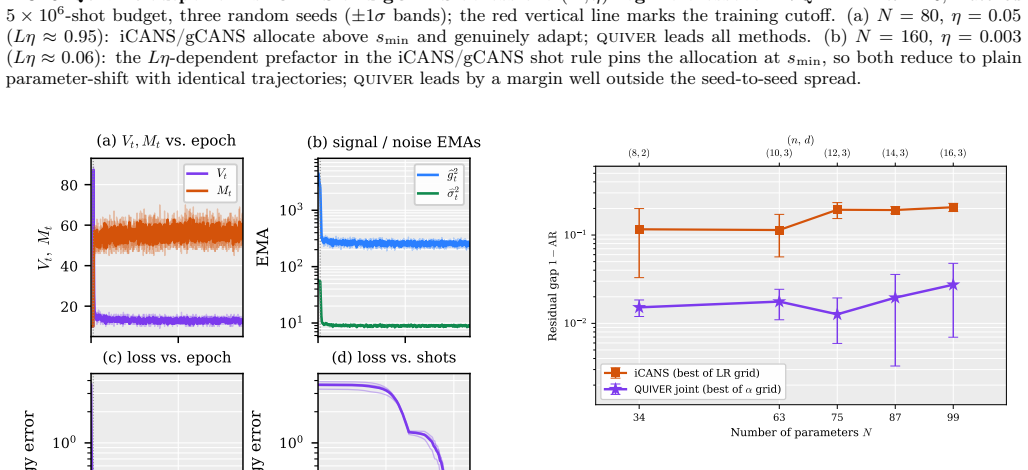
- QUIVER's closed-form shot allocation minimises total measurement cost for a target variance.
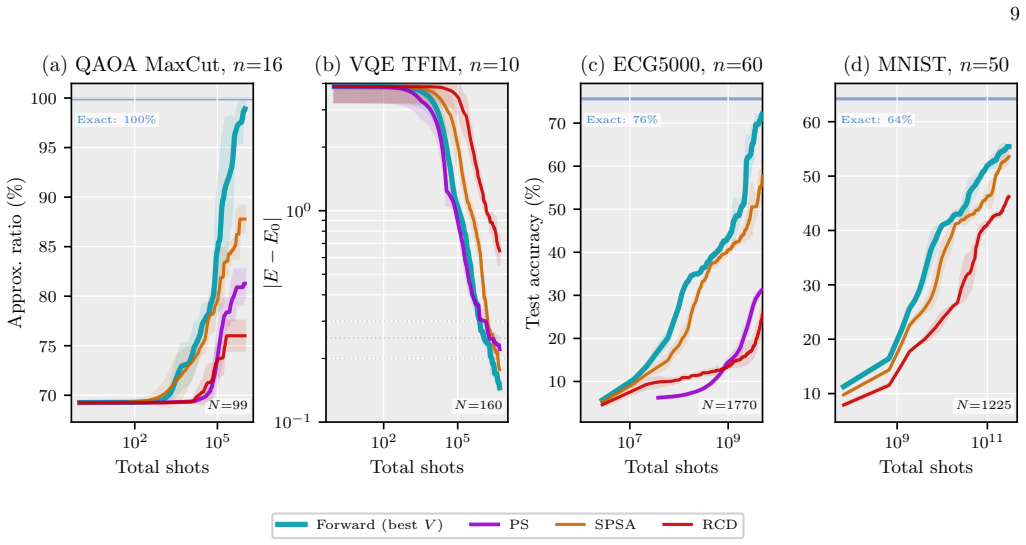
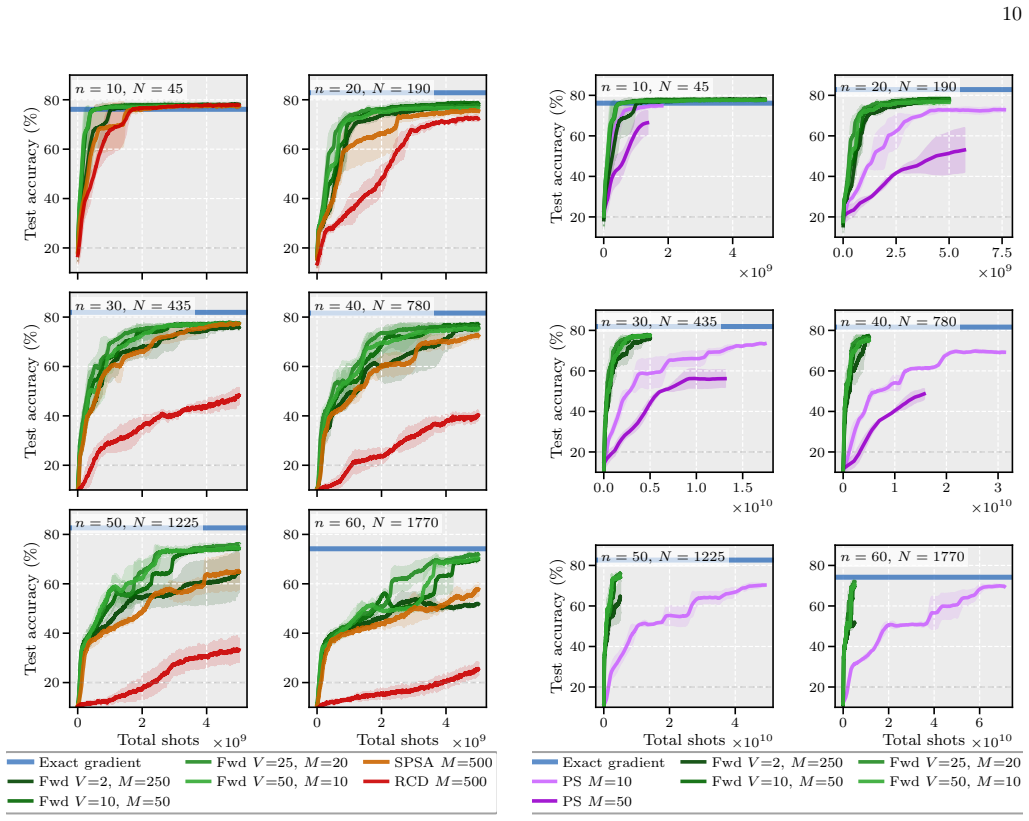
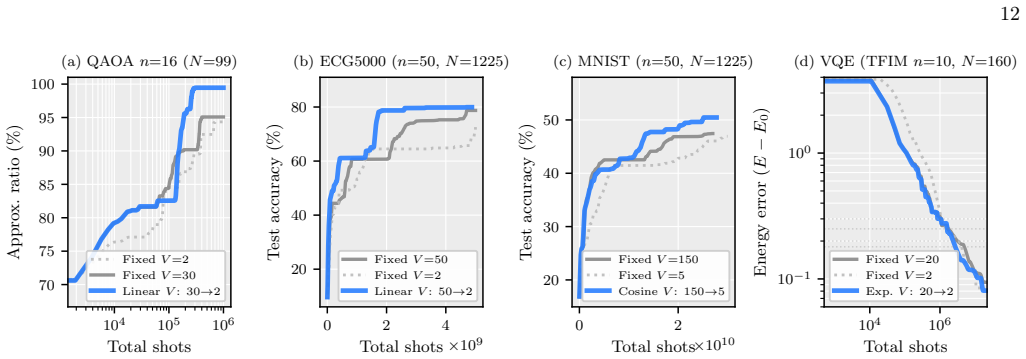
- Circuits with 60 qubits and 1770 parameters train orders of magnitude faster than with the parameter-shift rule.
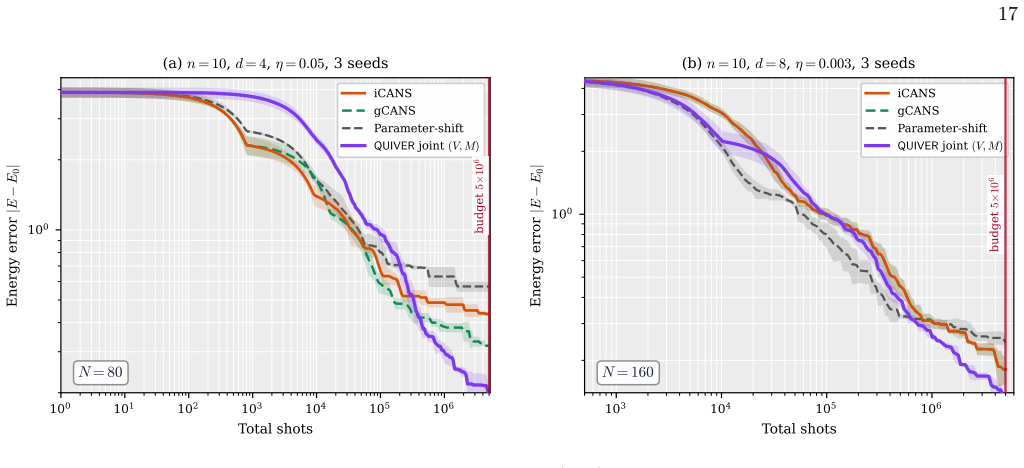
- QUIVER outperforms iCANS and gCANS on QAOA and VQE benchmark problems.
Where Pith is reading between the lines
- The same directional-derivative construction could be applied to any variational quantum algorithm whose cost function is an expectation value.
- Because the method is ancilla-free it may combine directly with existing error-mitigation protocols without increasing circuit depth.
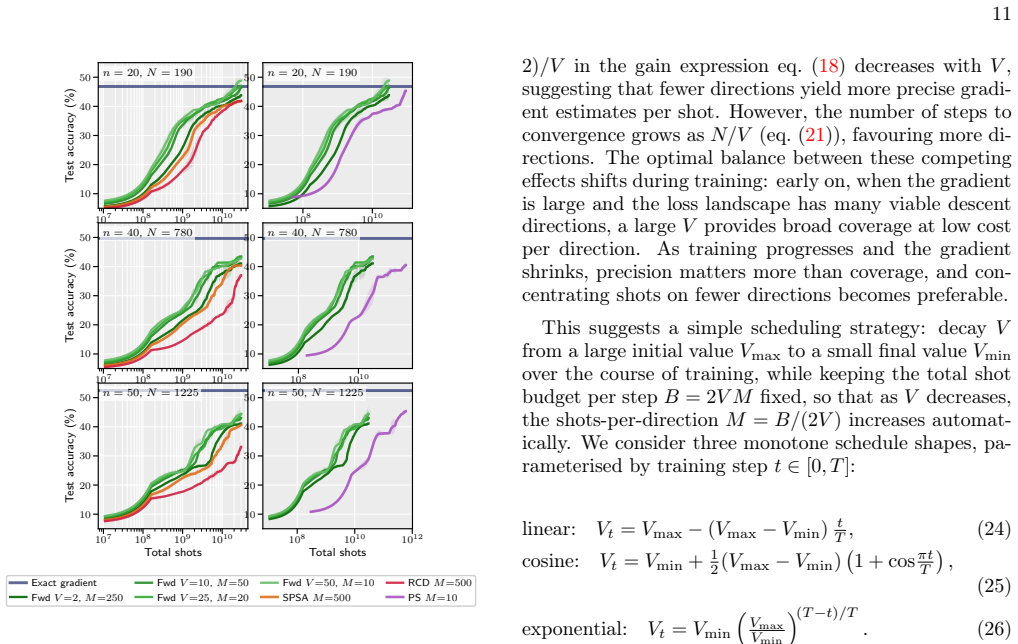
- At large parameter counts the optimal number of directions may become a hyper-parameter that itself needs adaptive tuning.
- If the variance model holds, similar cost-optimal allocation rules could be derived for other stochastic estimators used in quantum machine learning.
Load-bearing premise
That the second-moment expansion of the directional-derivative estimator correctly predicts variance under the measurement-cost model used to derive QUIVER's allocation rule.
What would settle it
Compute the empirical bias of the averaged directional derivative estimator on a single-parameter circuit whose analytic gradient is known; the bias must remain zero for any finite number of directions.
Figures
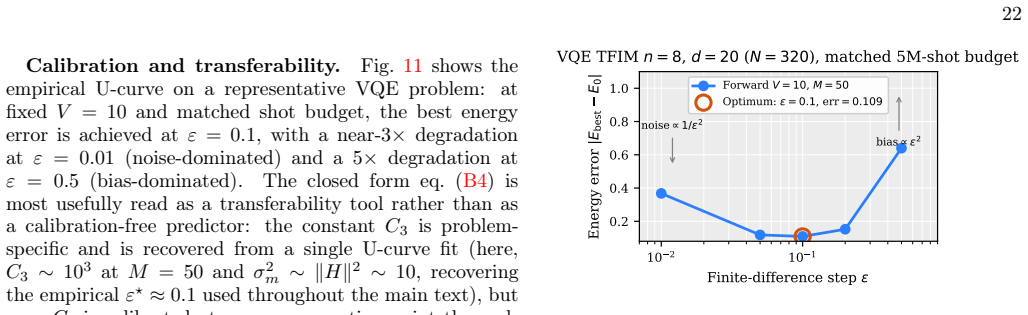
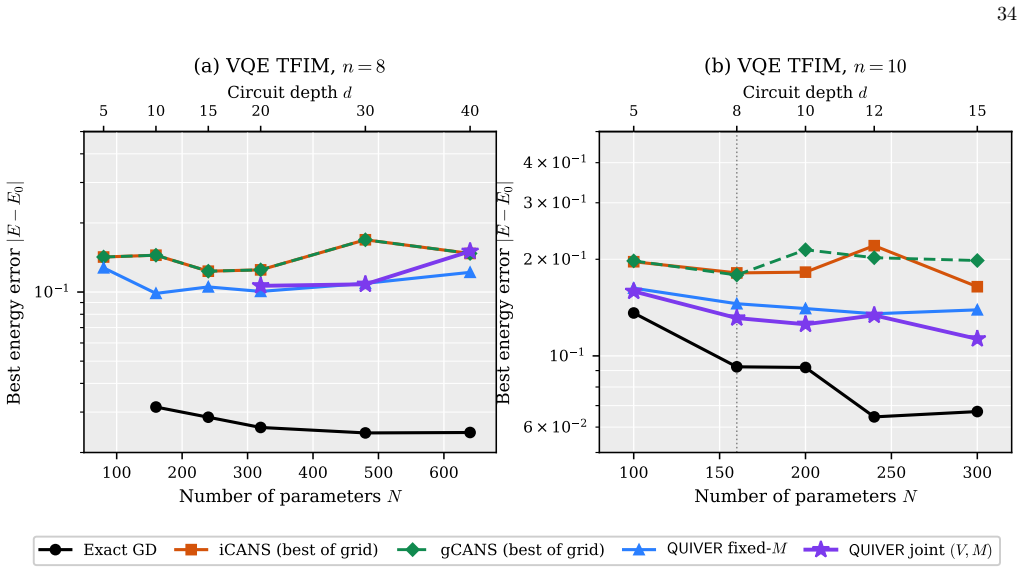
read the original abstract
Training parameterised quantum circuits (PQCs) on quantum hardware is bottlenecked by the measurement cost of gradient estimation, which under the parameter-shift rule scales linearly in the number of trainable parameters and dominates the total shot budget of training at scale. In this work, we propose a framework of forward gradient estimators for PQCs, based on the forward mode of automatic differentiation, that yields an unbiased estimator of the gradient by averaging a freely tunable number of random directional derivatives and recovers SPSA, random coordinate descent, and the parameter-shift rule as limiting cases, with no ancilla qubits or controlled-gate overhead. We prove that stochastic quantum forward gradient descent converges under standard assumptions, with an explicit second-moment expansion that interpolates between the single-direction extreme of SPSA and the full-gradient extreme of parameter-shift. Within this framework we derive QUIVER (Quantum Iterative V-adaptive Estimator Rule), an adaptive optimiser for parameterised circuits whose update rule follows from a closed-form minimum measurement-cost allocation. We show numerically that forward gradients train Hamming-weight-preserving orthogonal quantum neural networks with up to 60 qubits and 1770 parameters on the ECG5000 and MNIST datasets orders of magnitude more efficiently than the parameter-shift rule. We also demonstrate that our proposed QUIVER optimiser can outperform iCANS and gCANS measurement-frugal optimisers on optimisation problems using the quantum approximate optimisation algorithm and quantum simulation with the variational quantum eigensolver.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework of forward gradient estimators for parameterised quantum circuits based on forward-mode automatic differentiation. It constructs an unbiased gradient estimator by averaging a tunable number of random directional derivatives, recovering SPSA, random coordinate descent, and the parameter-shift rule as limiting cases without ancilla qubits or controlled gates. The authors prove convergence of stochastic forward gradient descent under standard assumptions, supply an explicit second-moment expansion of the estimator, and derive the QUIVER adaptive optimizer from a closed-form minimum-measurement-cost allocation rule. Large-scale numerical results are presented for training up to 60-qubit, 1770-parameter Hamming-weight-preserving orthogonal quantum neural networks on ECG5000 and MNIST, as well as comparisons on QAOA and VQE problems against iCANS and gCANS.
Significance. If the central claims hold, the work provides a tunable, ancilla-free alternative to the parameter-shift rule that can substantially reduce measurement overhead for large PQCs. The explicit convergence proof for stochastic quantum forward gradient descent and the large-scale numerical demonstrations on circuits with 1770 parameters constitute clear strengths. The QUIVER rule offers a principled adaptive strategy whose practical advantage, however, is tied to the validity of the underlying variance model.
major comments (1)
- [section deriving the QUIVER allocation rule and second-moment expansion] The second-moment expansion used to derive the closed-form QUIVER allocation rule assumes a specific measurement-cost model under which the variance interpolates between the SPSA (single-direction) and parameter-shift (full-basis) extremes. For general PQCs this scaling may be violated by circuit-specific correlations, non-independent shot noise, or the multi-frequency dependence of f(θ + t v) when v is non-coordinate; in that case the derived allocation ceases to be optimal and the headline measurement-efficiency claims for QUIVER no longer follow. This assumption is load-bearing for the adaptive optimizer and the numerical advantage reported in the experiments.
minor comments (1)
- [Abstract and numerical experiments] The abstract and experimental sections report large efficiency gains but omit error bars, dataset splits, and explicit variance-model parameters; adding these would strengthen verifiability of the comparisons.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the key assumptions in the QUIVER derivation. We respond to the major comment below.
read point-by-point responses
-
Referee: The second-moment expansion used to derive the closed-form QUIVER allocation rule assumes a specific measurement-cost model under which the variance interpolates between the SPSA (single-direction) and parameter-shift (full-basis) extremes. For general PQCs this scaling may be violated by circuit-specific correlations, non-independent shot noise, or the multi-frequency dependence of f(θ + t v) when v is non-coordinate; in that case the derived allocation ceases to be optimal and the headline measurement-efficiency claims for QUIVER no longer follow. This assumption is load-bearing for the adaptive optimizer and the numerical advantage reported in the experiments.
Authors: The second-moment expansion is derived under the explicit assumption of independent additive shot noise with variance scaling as 1/M per direction. This produces the stated interpolation and the closed-form allocation. We agree that circuit-specific correlations, non-independent noise, or multi-frequency effects in non-coordinate directions can violate the model, rendering the allocation suboptimal in those cases. The estimator itself remains unbiased for any choice of directions. The reported numerical advantages are observed on the specific circuits tested (Hamming-weight-preserving QNNs, QAOA, VQE). We will revise the manuscript to state the variance-model assumptions more prominently, add a limitations paragraph discussing potential violations, and qualify the optimality claims for general PQCs. This is a partial revision. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The core estimator is obtained directly from forward-mode automatic differentiation and is unbiased by construction. The second-moment expansion is stated to be explicit and derived from the estimator itself, interpolating between known limits. QUIVER follows from a closed-form allocation rule under an explicitly stated measurement-cost model; this is a derivation under assumptions rather than a reduction of the result to its inputs by definition or by fitting. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no known empirical patterns are merely renamed. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of random directions
axioms (2)
- domain assumption Standard assumptions for convergence of stochastic gradient descent
- domain assumption Measurement cost is linear in the number of directional derivative estimates and independent of circuit depth
Reference graph
Works this paper leans on
-
[1]
Cerezo, A
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, Variational quantum algo- rithms, Nat Rev Phys3, 625 (2021)
2021
-
[2]
Bhartiet al., Noisy intermediate-scale quantum algo- rithms, Rev
K. Bhartiet al., Noisy intermediate-scale quantum algo- rithms, Rev. Mod. Phys.94, 015004 (2022)
2022
-
[3]
Larocca, N
M. Larocca, N. Ju, D. García-Martín, P. J. Coles, and M. Cerezo, Theory of overparametrization in quantum neural networks, Nat Comput Sci3, 542 (2023)
2023
-
[4]
A. Delgado, F. Rios, and K. E. Hamilton, Identifying overparameterizationinQuantumCircuitBornMachines (2023), arXiv:2307.03292
-
[5]
García-Martín, M
D. García-Martín, M. Larocca, and M. Cerezo, Effects of noise on the overparametrization of quantum neural networks, Phys. Rev. Res.6, 013295 (2024)
2024
-
[6]
Holmes, K
Z. Holmes, K. Sharma, M. Cerezo, and P. J. Coles, Con- necting ansatz expressibility to gradient magnitudes and barren plateaus, PRX Quantum3, 010313 (2022)
2022
-
[7]
Schuld and N
M. Schuld and N. Killoran, Is quantum advantage the right goal for quantum machine learning?, PRX Quan- tum3, 030101 (2022)
2022
-
[8]
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, Learningrepresentationsbyback-propagatingerrors,Na- ture323, 533 (1986)
1986
-
[9]
A. G. Baydin, B. A. Pearlmutter, A. A. Radul, and J. M. Siskind, Automatic Differentiation in Machine Learning: a Survey, Journal of Machine Learning Research18, 1 (2018)
2018
- [10]
-
[11]
Bowles, D
J. Bowles, D. Wierichs, and C.-Y. Park, Backpropagation scaling in parameterised quantum circuits, Quantum9, 1873 (2025)
2025
- [12]
-
[13]
Chinzei, S
K. Chinzei, S. Yamano, Q. H. Tran, Y. Endo, and H. Oshima, Trade-off between Gradient Measurement Ef- ficiency and Expressivity in Deep Quantum Neural Net- works, npj Quantum Inf.11, 79 (2025)
2025
-
[14]
J.Spall,Multivariatestochasticapproximationusingasi- multaneous perturbation gradient approximation, IEEE Transactions on Automatic Control37, 332 (1992). 19
1992
-
[15]
Z. Ding, T. Ko, J. Yao, L. Lin, and X. Li, Random coor- dinate descent: A simple alternative for optimizing pa- rameterized quantum circuits, Phys. Rev. Res.6, 033029 (2024)
2024
- [16]
-
[17]
Silver, A
D. Silver, A. Goyal, I. Danihelka, M. Hessel, and H. v. Hasselt, Learning by Directional Gradient Descent, in International Conference on Learning Representations (2022)
2022
-
[18]
SEGA: Variance Reduction via Gradient Sketching
F. Hanzely, K. Mishchenko, and P. Richtarik, SEGA: Variance Reduction via Gradient Sketching, inAdvances in Neural Information Processing Systems, Vol. 31 (2018) arXiv:1809.03054
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Hinton, The Forward-Forward Algorithm: Some Pre- liminary Investigations (2022), arXiv:2212.13345
G. Hinton, The Forward-Forward Algorithm: Some Pre- liminary Investigations (2022), arXiv:2212.13345
-
[20]
L. Fournier, S. Rivaud, E. Belilovsky, M. Eickenberg, and E. Oyallon, Can Forward Gradient Match Backpropaga- tion?, inFortieth International Conference on Machine Learning(2023) arXiv:2306.06968
- [21]
-
[22]
Coupling Adaptive Batch Sizes with Learning Rates
L. Balles, J. Romero, and P. Hennig, Coupling Adaptive Batch Sizes with Learning Rates, inUncertainty in Ar- tificial Intelligence(2017) arXiv:1612.05086
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
J. M. Kübler, A. Arrasmith, L. Cincio, and P. J. Coles, An Adaptive Optimizer for Measurement-Frugal Varia- tional Algorithms, Quantum4, 263 (2020)
2020
- [24]
-
[25]
Landman, N
J. Landman, N. Mathur, Y. Y. Li, M. Strahm, S. Kazdaghli, A. Prakash, and I. Kerenidis, Quantum Methods for Neural Networks and Application to Medi- cal Image Classification, Quantum6, 881 (2022)
2022
-
[26]
Monbroussou, J
L. Monbroussou, J. Landman, A. B. Grilo, R. Kukla, and E. Kashefi, Trainability and Expressivity of Hamming- Weight Preserving Quantum Circuits for Machine Learn- ing, Quantum9, 1745 (2025)
2025
-
[27]
D. P. Kingma and J. Ba, Adam: A Method for Stochastic Optimization, inInternational Conference on Learning Representations(2015) arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Bradbury, R
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. Van- derPlas, S. Wanderman-Milne, and Q. Zhang, JAX: com- posable transformations of Python+NumPy programs (2018)
2018
-
[29]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszkeet al., PyTorch: An Imperative Style, High-Performance Deep Learning Library (2019), arXiv:1912.01703
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[30]
Martín Abadiet al., TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems (2015), software available from tensorflow.org
2015
-
[31]
Griewank, K
A. Griewank, K. Kulshreshtha, and A. Walther, On the numerical stability of algorithmic differentiation, Com- puting94, 125 (2012)
2012
-
[32]
Schmidhuber, Deep learning in neural networks: An overview, Neural Networks61, 85 (2015)
J. Schmidhuber, Deep learning in neural networks: An overview, Neural Networks61, 85 (2015)
2015
-
[33]
Pérez-Salinas, A
A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, Data re-uploading for a universal quantum classifier, Quantum4, 226 (2020)
2020
-
[34]
Romero, R
J. Romero, R. Babbush, J. R. McClean, C. Hempel, P. J. Love, and A. Aspuru-Guzik, Strategies for quantum com- puting molecular energies using the unitary coupled clus- ter ansatz, Quantum Sci. Technol.4, 014008 (2018)
2018
-
[35]
Classification with Quantum Neural Networks on Near Term Processors
E. Farhi and H. Neven, Classification with Quan- tum Neural Networks on Near Term Processors (2018), arXiv:1802.06002
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Mitarai, M
K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Quan- tum circuit learning, Phys. Rev. A98, 032309 (2018)
2018
-
[37]
D.Wierichs, J.Izaac, C.Wang,andC.Y.-Y.Lin,General parameter-shift rules for quantum gradients, Quantum6, 677 (2022)
2022
-
[38]
Kyriienko and V
O. Kyriienko and V. E. Elfving, Generalized quantum circuit differentiation rules, Phys. Rev. A104, 052417 (2021)
2021
-
[39]
G.-L. R. Anselmetti, D. Wierichs, C. Gogolin, and R. M. Parrish, Local, expressive, quantum-number-preserving VQE ansätze for fermionic systems, New J. Phys.23, 113010 (2021)
2021
-
[40]
Sweke, F
R. Sweke, F. Wilde, J. Meyer, M. Schuld, P. K. Faehrmann, B. Meynard-Piganeau, and J. Eisert, Stochastic gradient descent for hybrid quantum-classical optimization, Quantum4, 314 (2020)
2020
-
[41]
C.Moussa, M.H.Gordon, M.Baczyk, M.Cerezo, L.Cin- cio, and P. J. Coles, Resource frugal optimizer for quan- tum machine learning, Quantum Sci. Technol.8, 045019 (2023)
2023
-
[42]
J. C. Spall, A Stochastic Approximation Technique for Generating Maximum Likelihood Parameter Estimates, in1987 American Control Conference(1987) pp. 1161– 1167
1987
-
[43]
Bhatnagar, H
S. Bhatnagar, H. Prasad, and L. Prashanth, Stochastic Approximation Algorithms, inStochastic Recursive Al- gorithms for Optimization(Springer, 2013) pp. 17–28
2013
-
[44]
C. Cade, L. Mineh, A. Montanaro, and S. Stanisic, Strategies for solving the Fermi-Hubbard model on near- term quantum computers, Phys. Rev. B102, 235122 (2020)
2020
-
[45]
Gacon, C
J. Gacon, C. Zoufal, G. Carleo, and S. Woerner, Simul- taneous Perturbation Stochastic Approximation of the Quantum Fisher Information, Quantum5, 567 (2021)
2021
-
[46]
N. Jain, B. Coyle, E. Kashefi, and N. Kumar, Graph neu- ral network initialisation of quantum approximate opti- misation, Quantum6, 861 (2022)
2022
-
[47]
Sauvage and F
F. Sauvage and F. Mintert, Optimal quantum control with poor statistics, PRX Quantum1, 020322 (2020)
2020
-
[48]
X. Bonet-Monroig, H. Wang, D. Vermetten, B. Senjean, C. Moussa, T. Bäck, V. Dunjko, and T. E. O’Brien, Per- formance comparison of optimization methods on vari- ational quantum algorithms, Physical Review A107, 032407 (2023), arXiv:2111.13454 [quant-ph]
-
[49]
Nesterov, Efficiency of Coordinate Descent Methods on Huge-Scale Optimization Problems, SIAM J
Y. Nesterov, Efficiency of Coordinate Descent Methods on Huge-Scale Optimization Problems, SIAM J. Optim. 22, 341 (2012)
2012
-
[50]
Richtárik and M
P. Richtárik and M. Takáč, Iteration complexity of ran- domized block-coordinate descent methods for minimiz- ing a composite function, Math. Program.144, 1 (2014)
2014
-
[51]
A. Arrasmith, L. Cincio, R. D. Somma, and P. J. Coles, Operator Sampling for Shot-frugal Optimization in Vari- ational Algorithms (2020), arXiv:2004.06252
-
[52]
van Straaten and B
B. van Straaten and B. Koczor, Measurement cost of metric-aware variational quantum algorithms, PRX Quantum2, 030324 (2021). 20
2021
-
[53]
Boyd and B
G. Boyd and B. Koczor, Training variational quantum circuits with CoVaR: Covariance root finding with clas- sical shadows, Phys. Rev. X12, 041022 (2022)
2022
-
[54]
G.García-Pérez, M.A.C.Rossi, B.Sokolov, F.Tacchino, P. K. Barkoutsos, G. Mazzola, I. Tavernelli, and S. Man- iscalco, Learning to measure: Adaptive informationally complete generalized measurements for quantum algo- rithms, PRX Quantum2, 040342 (2021)
2021
-
[55]
S. Pramanik and M. G. Chandra, Stochastic Shadow Descent: Training Parametrized Quantum Circuits with Shadows of Gradients (2025), arXiv:2511.12168
- [56]
-
[57]
Bos and J
T. Bos and J. Schmidt-Hieber, Convergence guarantees for forward gradient descent in the linear regression model, Journal of Statistical Planning and Inference233, 106174 (2024)
2024
-
[58]
N. Dexheimer and J. Schmidt-Hieber, Improving the Convergence Rates of Forward Gradient Descent with Repeated Sampling (2024), arXiv:2411.17567
-
[59]
U. Singhal, B. Cheung, K. Chandra, J. Ragan-Kelley, J. B. Tenenbaum, T. A. Poggio, and S. X. Yu, How to guess a gradient (2023), arXiv:2312.04709
- [60]
-
[61]
K. Panchal, S. Choudhary, Y. Brun, and H. Guan, The Cost of Avoiding Backpropagation (2025), arXiv:2506.21833
- [62]
-
[63]
Y. Yu, R. Xia, Q. Ma, M. Lengyel, and G. Hennequin, Second-Order Forward-Mode Optimization of Recurrent Neural Networks for Neuroscience, inAdvances in Neural Information Processing Systems, Vol. 37 (2024)
2024
-
[64]
Stokes, J
J. Stokes, J. Izaac, N. Killoran, and G. Carleo, Quantum Natural Gradient, Quantum4, 269 (2020)
2020
-
[65]
A. Mari, T. R. Bromley, and N. Killoran, Estimating the gradient and higher-order derivatives on quantum hard- ware, Physical Review A103, 012405 (2021)
2021
- [66]
-
[67]
M. M. Wolf,Mathematical Foundations of Supervised Learning(Lecture notes, Technical University of Munich, 2023)
2023
-
[68]
Talagrand, Concentration of measure and isoperimet- ric inequalities in product spaces, Publications Mathé- matiques de l’IHÉS81, 73 (1995)
M. Talagrand, Concentration of measure and isoperimet- ric inequalities in product spaces, Publications Mathé- matiques de l’IHÉS81, 73 (1995)
1995
-
[69]
Cerezo, A
M. Cerezo, A. Sone, T. Volkoff, L. Cincio, and P. J. Coles, Cost function dependent barren plateaus in shal- low parametrized quantum circuits, Nature Communica- tions12, 1791 (2021)
2021
-
[70]
Kandala, A
A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, and J. M. Gambetta, Hardware- efficient variational quantum eigensolver for small molecules and quantum magnets, Nature549, 242 (2017)
2017
-
[71]
A Quantum Approximate Optimization Algorithm
E. Farhi, J. Goldstone, and S. Gutmann, A quan- tum approximate optimization algorithm (2014), arXiv:1411.4028 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[72]
R. Herrman, P. C. Lotshaw, J. Ostrowski, T. S. Humble, and G. Siopsis, Multi-angle quantum approximate opti- mization algorithm, Scientific Reports12, 6781 (2022), arXiv:2109.11455. Appendix A: Unbiasedness of the forward gradient estimator We prove that theV-direction,M-shot forward gradient estimator eq. (A2) is unbiased in theε→0limit, adapting the cla...
-
[73]
IfE[∥g (t)(θ)∥2]≤γ 2 for allθ, tandη∈[0,1/(2µ)], then E[f(θ (T) )]−f(θ ⋆)≤(1−2µη) T f(θ (0))−f(θ ⋆) + Lη γ2 4µ .(D5)
-
[74]
A,E[ egF(θ)] =∇f(θ), so the estimator is unbiased
IfE[∥g (t)(θ)∥2]≤β 2∥∇f(θ)∥ 2 for allθ, tandη= 1/(Lβ 2), then E[f(θ (T) )]−f(θ ⋆)≤ 1− µ Lβ2 T f(θ (0))−f(θ ⋆) .(D6) Proof of Proposition 4.Part (i).By App. A,E[ egF(θ)] =∇f(θ), so the estimator is unbiased. By Lemma 4 with κ= 1(Rademacher), E ∥egF∥2 = N+V−1 V ∥∇f∥2 =:β 2 ∥∇f∥2. This is the bounded relative second moment condition of part 2 of Lemma 5. Set...
-
[75]
Lemma 6(Variance-with-measurement decomposition).With unbiased single-shot estimatorsE m[e∇vℓ Lm] =∇ vℓ L and i.i.d
Variance decomposition over measurements Toexpressthegaininaformwhereeachrandomdirectioncontributesaseparatesignalandnoisetermwedecompose the measurement-side expectation of the directional-derivative variance. Lemma 6(Variance-with-measurement decomposition).With unbiased single-shot estimatorsE m[e∇vℓ Lm] =∇ vℓ L and i.i.d. measurement trials, Em h Varv...
-
[76]
Per-direction gain and learning-rate criterion Substituting Lemma 1 and Lemma 6 into eq. (E1): E[GF] =η∥∇L∥ 2 − Lη2 2 E h ∥e∇ F L∥2 i ≈η∥∇L∥ 2 − Lη2 2 · N+V+κ−2 V · 1 V VX ℓ=1 (∇vℓ L)2 + Varm[e∇vℓ Lm] M = 1 V VX ℓ=1 η∥∇L∥ 2 − Lη2 2 N+V+κ−2 V (∇vℓ L)2 + Varm[e∇vℓ Lm] M | {z } =:γ vℓ , where the second line uses Lemma 1 for the second-moment term and Lemma ...
-
[77]
(E3) becomes a function ofMℓ alone
Optimal per-direction shot allocation Allowing the number of shots to depend on the direction,M→M ℓ, the per-direction gainγ vℓ from eq. (E3) becomes a function ofMℓ alone. Maximising the gain-per-shotγ vℓ /Mℓ overM ℓ and rearranging yields the optimal per-direction allocation referenced from Section VIIA. Lemma 7(Optimal per-direction shot allocation).Le...
-
[78]
For isotropic zero-mean unit-variance directions,E v[(∇vℓ L)2] =∥∇L∥ 2
Fixed-MoptimalV Under Assumption 1 the per-direction measurement variance concentrates,Var m[e∇vℓ Lm]≈¯σ 2 ∇ for allℓ. For isotropic zero-mean unit-variance directions,E v[(∇vℓ L)2] =∥∇L∥ 2. Taking this expectation in the per-direction gain eq. (E3) and averaging over theVdirections: E[GF]≈η∥∇L∥ 2 − Lη2 2 N+V+κ−2 V ∥∇L∥2 + ¯σ2 ∇ M .(E6) WithMfixed, the ga...
-
[79]
(35)) is MSE(V, M) = (N−1)∥g∥ 2 V + N¯σ2 ∇ V M ,(I4) and the cost-minimisation problem is min V, M >0 2V Ms.t.MSE(V, M)≤τ 2, M≥M min.(I5) The proof has five steps
Proof of Theorem 1: optimal allocation Setup.The MSE of the Rademacher forward gradient estimator withVdirections andMshots per direction (eq. (35)) is MSE(V, M) = (N−1)∥g∥ 2 V + N¯σ2 ∇ V M ,(I4) and the cost-minimisation problem is min V, M >0 2V Ms.t.MSE(V, M)≤τ 2, M≥M min.(I5) The proof has five steps. Proof.1.EliminateV.The MSE constraint in eq. (I5) ...
-
[80]
First we establish the Cramér–Rao lower bound eq
Proof of Corollary 1: CRB-level optimality The proof has two parts. First we establish the Cramér–Rao lower bound eq. (40) on the MSE of any unbiased estimator ofgthat queries the shot-noise oracle a total ofBtimes. Second we show that the forward-gradient estimator at the optimal allocation of Theorem 1 attains this bound up to a constant that vanishes a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.