SynIB: Informational Bottleneck for Maximizing Synergy in Multimodal Learning
Pith reviewed 2026-06-30 21:53 UTC · model grok-4.3
The pith
SynIB is a training objective that maximizes synergistic information by penalizing confident predictions from any single modality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
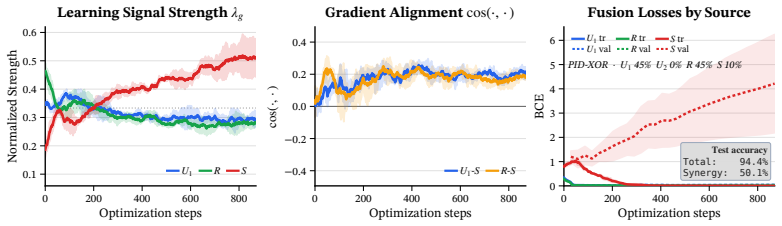
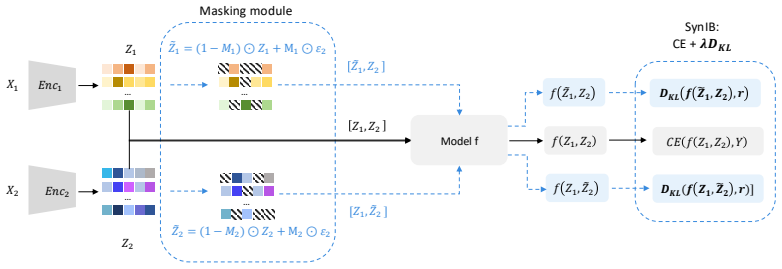
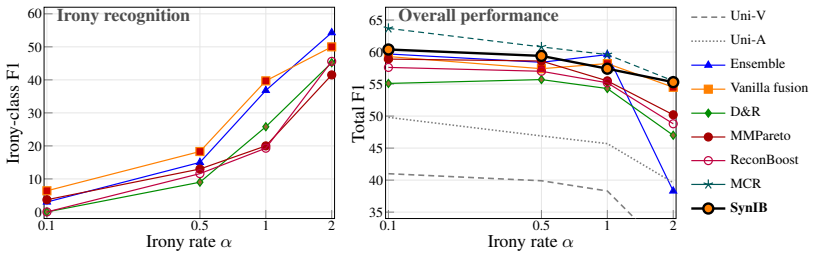
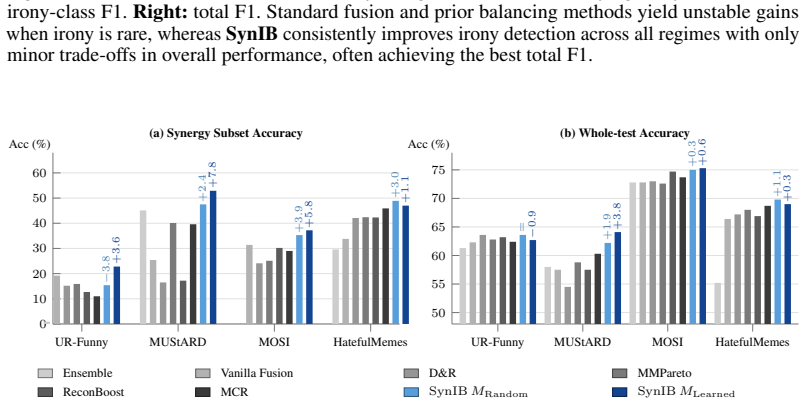
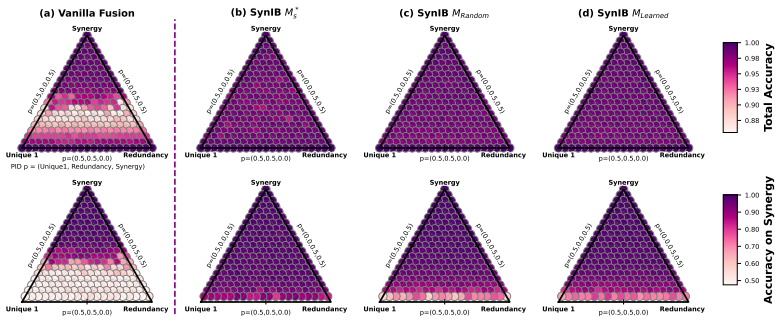
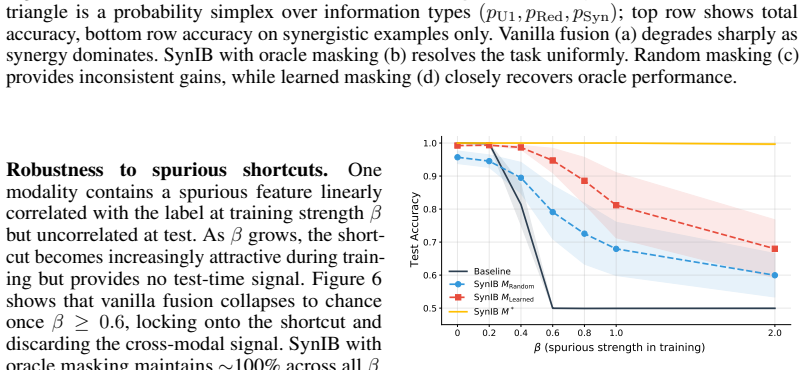
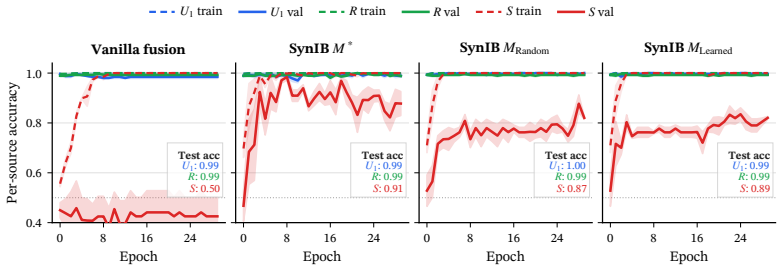
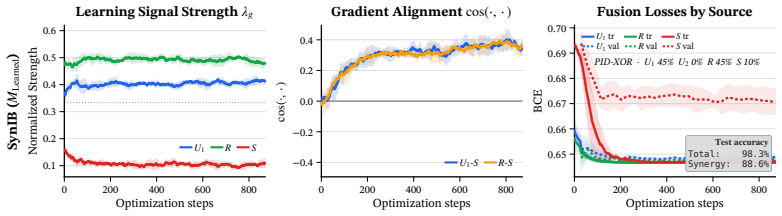
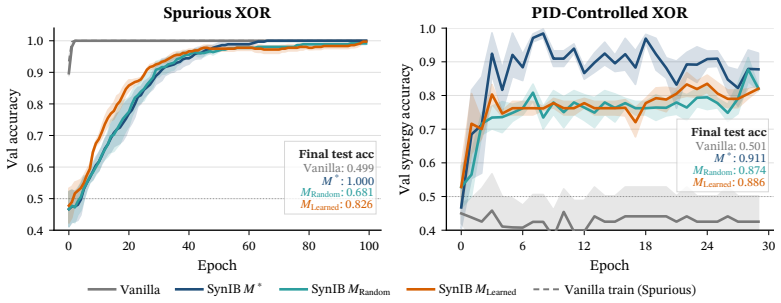
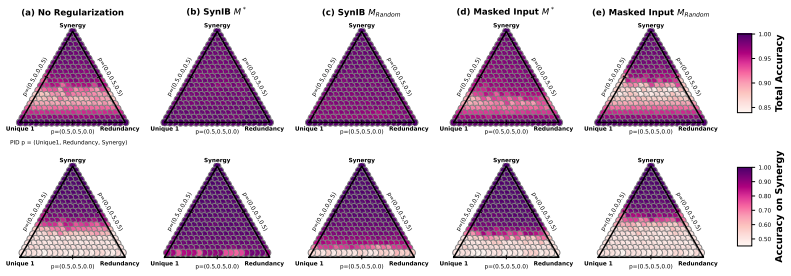
The Synergistic Information Bottleneck (SynIB) formalizes multimodal synergy in information-theoretic terms and augments the standard task loss with a term that penalizes remaining predictive confidence after any one modality is masked; this forces the model to extract information available only from the combination of modalities, recovering ground-truth synergy on constructed XOR tasks and raising accuracy on synergy-dependent examples in five real-world benchmarks.
What carries the argument
The Synergistic Information Bottleneck (SynIB) objective, which adds a penalty for confident predictions after masking individual modalities to isolate synergistic information.
If this is right
- Standard training leaves synergy-dependent examples under-served; SynIB closes that gap without altering the fusion architecture.
- On tasks with known ground-truth synergy such as the XOR constructions, SynIB recovers the joint signal that unimodal or redundant paths cannot provide.
- Accuracy on synergy-dependent subsets rises by up to 7.8 percent and overall accuracy by up to 3.8 percent across the tested benchmarks.
- The objective remains compatible with existing backbones and can be added to any multimodal pipeline that supports modality masking.
Where Pith is reading between the lines
- The same masking-penalty logic could be tested in non-modal multi-source settings such as multi-sensor time series or multi-view geometry.
- SynIB might be combined with architectural fusion improvements to produce additive rather than overlapping gains.
- By reducing dependence on single-modality shortcuts, the method could improve robustness when one modality is noisy or missing at test time.
Load-bearing premise
Penalizing remaining confidence after masking one modality specifically isolates and maximizes synergistic information rather than producing unrelated regularization or optimization changes.
What would settle it
If applying the SynIB penalty on the synthetic XOR tasks fails to recover the known synergistic label while standard training also fails, or if the real-world accuracy gains disappear when the penalty term is replaced by an equivalent amount of random noise in the loss.
Figures

read the original abstract
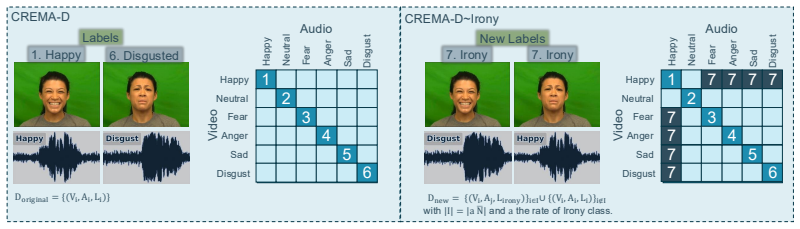
A central objective in multimodal learning is to capture synergy: task-relevant information that arises only from the joint use of multiple modalities, and is not available from any single modality alone. While most approaches operate at the architectural level through larger or more complex fusion models, we propose a complementary axis: shaping the training objective itself. Standard training often emphasizes unimodal or redundant information, falling short on examples that require cross-modal reasoning. We formalize multimodal synergy through information theory and introduce the Synergistic Information Bottleneck (SynIB), a scalable objective that targets synergy directly. To prioritize learning synergy, SynIB motivates the model to predict accurately from all modalities while penalizing confidence when information from any modality is withheld. Alongside the standard task loss, the model runs forward passes with one modality masked at a time and is penalized for remaining confident, which would indicate reliance on unimodal cues rather than cross-modal interactions. We validate SynIB in two regimes. On synthetic XOR tasks where the ground-truth synergy is known by construction, standard training fails to recover it while SynIB does. On five real-world benchmarks, including three MultiBench affective tasks, Hateful Memes with CLIP-ViT and DeBERTa backbones, and a controllable irony extension of CREMA-D we introduce, SynIB improves accuracy on synergy-dependent examples by up to 7.8% and overall accuracy by up to 3.8%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Synergistic Information Bottleneck (SynIB) objective, which augments the standard task loss with a penalty on model confidence in forward passes where one modality is masked. This is intended to discourage unimodal reliance and prioritize synergistic cross-modal information. Validation includes recovery of known synergy on synthetic XOR tasks and reported accuracy gains (up to 7.8% on synergy-dependent examples, 3.8% overall) on five real benchmarks including MultiBench tasks, Hateful Memes, and a CREMA-D irony extension.
Significance. If the objective can be shown to specifically maximize synergistic mutual information rather than generic regularization effects, the approach would provide a scalable, architecture-agnostic method for improving multimodal performance on tasks requiring joint reasoning. The synthetic XOR validation, where ground-truth synergy is known by construction, is a clear strength that grounds the method.
major comments (2)
- [Abstract] Abstract (paragraph describing the objective): the penalty on remaining confidence after masking one modality is asserted to isolate and maximize synergy, but no derivation is supplied showing that this term equals or bounds a formal synergy measure such as I(X;Y;Z) minus marginal terms. Without this, the 7.8% gains on real benchmarks cannot be attributed specifically to synergy maximization versus altered optimization or implicit dropout.
- [Real-world benchmarks] Real-world benchmarks (five tasks section): synergy-dependent examples lack ground-truth labels, so measured improvements rest on the untested assumption that the penalty targets the synergistic component; ablations or controls that vary only the penalty while holding other factors fixed are required to rule out complementary-cue or regularization explanations.
minor comments (2)
- Error bars, multiple random seeds, and statistical significance tests for the reported accuracy deltas are absent and should be added.
- Full methods, hyperparameter ranges, and data exclusion rules for the real benchmarks are referenced only at high level and should be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below with clarifications and commit to specific revisions that strengthen the attribution of results to synergy maximization.
read point-by-point responses
-
Referee: [Abstract] the penalty on remaining confidence after masking one modality is asserted to isolate and maximize synergy, but no derivation is supplied showing that this term equals or bounds a formal synergy measure such as I(X;Y;Z) minus marginal terms. Without this, the 7.8% gains on real benchmarks cannot be attributed specifically to synergy maximization versus altered optimization or implicit dropout.
Authors: We acknowledge that the abstract presents the objective at a high level. The main text motivates the penalty via information theory as discouraging unimodal mutual information to favor joint representations, but an explicit derivation bounding the term against interaction information I(X;Y;Z) or similar is not supplied. In the revision we will add a dedicated subsection deriving that the expected penalty provides a variational upper bound on the reduction of single-modality mutual information while preserving task-relevant joint information, thereby targeting synergy. This will support clearer attribution of the reported gains. revision: yes
-
Referee: [Real-world benchmarks] synergy-dependent examples lack ground-truth labels, so measured improvements rest on the untested assumption that the penalty targets the synergistic component; ablations or controls that vary only the penalty while holding other factors fixed are required to rule out complementary-cue or regularization explanations.
Authors: We agree that real-world synergy-dependent examples are identified indirectly via unimodal vs. multimodal performance gaps rather than ground-truth labels, and that this leaves room for alternative explanations. The synthetic XOR experiments remain the primary controlled validation. For the real benchmarks we will add ablations in the revision that hold all other factors fixed while varying only the SynIB penalty (including comparisons to equivalent dropout or generic confidence penalties) and report results on the same example subsets to isolate the contribution of the modality-masking structure. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and context describe SynIB as a new training objective (standard loss plus explicit penalty on post-masking confidence) motivated by an information-theoretic view of synergy. No equations, self-definitional loops, or fitted parameters renamed as predictions appear in the given text. The synthetic XOR validation uses externally known ground-truth synergy (not derived from the method itself), and real-benchmark gains are measured outcomes rather than forced by construction. No load-bearing self-citations or uniqueness theorems imported from prior author work are referenced. The central claim therefore remains an independent proposal whose correctness can be evaluated against external benchmarks without reducing to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard definitions of synergistic information from information theory
Reference graph
Works this paper leans on
-
[1]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
ACM Computing Surveys , volume=
Foundations & trends in multimodal machine learning: Principles, challenges, and open questions , author=. ACM Computing Surveys , volume=. 2024 , publisher=
2024
-
[3]
Advances in neural information processing systems , volume=
The im algorithm: a variational approach to information maximization , author=. Advances in neural information processing systems , volume=
-
[4]
Deep Learning , author =
-
[5]
Advances in Neural Information Processing Systems , volume =
A Simple Weight Decay Can Improve Generalization , author =. Advances in Neural Information Processing Systems , volume =
-
[6]
Journal of Machine Learning Research , volume =
Dropout: A Simple Way to Prevent Neural Networks from Overfitting , author =. Journal of Machine Learning Research , volume =
-
[7]
Advances in Neural Information Processing Systems , year =
Does Multimodal Learning Require Fusion? , author =. Advances in Neural Information Processing Systems , year =
-
[8]
AAAI Conference on Artificial Intelligence , year =
FiLM: Visual Reasoning with a General Conditioning Layer , author =. AAAI Conference on Artificial Intelligence , year =
-
[9]
IEEE Transactions on Information Theory , volume=
On the maximum entropy of the sum of two dependent random variables , author=. IEEE Transactions on Information Theory , volume=. 1994 , publisher=
1994
-
[10]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[11]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[12]
Machine learning proceedings 1992 , pages=
A practical approach to feature selection , author=. Machine learning proceedings 1992 , pages=. 1992 , publisher=
1992
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning not to learn: Training deep neural networks with biased data , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
2010 , publisher=
MNIST handwritten digit database , author=. 2010 , publisher=
2010
-
[15]
IEEE transactions on affective computing , volume=
Crema-d: Crowd-sourced emotional multimodal actors dataset , author=. IEEE transactions on affective computing , volume=. 2014 , publisher=
2014
-
[17]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
XSleepNet: Multi-view sequential model for automatic sleep staging , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2021 , publisher=
2021
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
What makes training multi-modal classification networks hard? , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Balanced multimodal learning via on-the-fly gradient modulation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
PMR: Prototypical Modal Rebalance for Multimodal Learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[21]
Ioord2018representationnternational Conference on Machine Learning , pages=
Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks , author=. Ioord2018representationnternational Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[22]
arXiv preprint arXiv:2208.10442 , year=
Image as a foreign language: Beit pretraining for all vision and vision-language tasks , author=. arXiv preprint arXiv:2208.10442 , year=
-
[23]
International Conference on Machine Learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[24]
arXiv preprint arXiv:2206.09852 , year=
M&m mix: A multimodal multiview transformer ensemble , author=. arXiv preprint arXiv:2206.09852 , year=
-
[25]
, author=
CoRe-Sleep: A Multimodal Fusion Framework for Time Series Robust to Imperfect Modalities. , author=. IEEE Transactions on Neural Systems and Rehabilitation Engineering , year=
-
[26]
International Conference on Machine Learning , pages=
Modality competition: What makes joint training of multi-modal network fail in deep learning?(provably) , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[27]
arXiv preprint arXiv:2305.01233 , year=
On Uni-Modal Feature Learning in Supervised Multi-Modal Learning , author=. arXiv preprint arXiv:2305.01233 , year=
-
[28]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
MMCosine: Multi-Modal Cosine Loss Towards Balanced Audio-Visual Fine-Grained Learning , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[29]
International Conference on Machine Learning , pages=
Penalizing gradient norm for efficiently improving generalization in deep learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[30]
Mathematical programming , volume=
On the limited memory BFGS method for large scale optimization , author=. Mathematical programming , volume=. 1989 , publisher=
1989
-
[31]
International Conference on Machine Learning , pages=
Sharpened quasi-newton methods: Faster superlinear rate and larger local convergence neighborhood , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Boosting Multi-modal Model Performance with Adaptive Gradient Modulation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Slowfast networks for video recognition , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[34]
Pattern Recognition: 5th Asian Conference, ACPR 2019, Auckland, New Zealand, November 26--29, 2019, Revised Selected Papers, Part II 5 , pages=
Modality-specific learning rate control for multimodal classification , author=. Pattern Recognition: 5th Asian Conference, ACPR 2019, Auckland, New Zealand, November 26--29, 2019, Revised Selected Papers, Part II 5 , pages=. 2020 , organization=
2019
-
[35]
Modality-specific Learning Rates for Effective Multimodal Additive Late-fusion
Yao, Yiqun and Mihalcea, Rada. Modality-specific Learning Rates for Effective Multimodal Additive Late-fusion. Findings of the Association for Computational Linguistics: ACL 2022. 2022
2022
-
[36]
Advances in Neural Information Processing Systems , volume=
Modulating early visual processing by language , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Proceedings of the European Conference on Computer Vision (ECCV) Workshops , pages=
Centralnet: a multilayer approach for multimodal fusion , author=. Proceedings of the European Conference on Computer Vision (ECCV) Workshops , pages=
-
[38]
Proceedings of the European conference on computer vision (ECCV) , pages=
Audio-visual event localization in unconstrained videos , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[39]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
UCF101: A dataset of 101 human actions classes from videos in the wild , author=. arXiv preprint arXiv:1212.0402 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[41]
Proceedings of the AAAI conference on artificial intelligence , volume=
Efficient large-scale multi-modal classification , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[42]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
2023 , eprint=
Improving Discriminative Multi-Modal Learning with Large-Scale Pre-Trained Models , author=. 2023 , eprint=
2023
-
[44]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[45]
IEEE transactions on pattern analysis and machine intelligence , volume=
Neural network ensembles , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 1990 , publisher=
1990
-
[46]
International Conference on Learning Representations (Workshop) , year=
Understanding intermediate layers using linear classifier probes , author=. International Conference on Learning Representations (Workshop) , year=
-
[47]
Advances in neural information processing systems , volume=
wav2vec 2.0: A framework for self-supervised learning of speech representations , author=. Advances in neural information processing systems , volume=
-
[48]
arXiv preprint arXiv:2005.08100 , year=
Conformer: Convolution-augmented transformer for speech recognition , author=. arXiv preprint arXiv:2005.08100 , year=
-
[49]
arXiv preprint arXiv:2305.07216 , year=
Versatile Audio-Visual Learning for Handling Single and Multi Modalities in Emotion Regression and Classification Tasks , author=. arXiv preprint arXiv:2305.07216 , year=
-
[50]
IEEE signal processing letters , volume=
Joint face detection and alignment using multitask cascaded convolutional networks , author=. IEEE signal processing letters , volume=. 2016 , publisher=
2016
-
[51]
International conference on machine learning , pages=
Efficientnet: Rethinking model scaling for convolutional neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[52]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Vivit: A video vision transformer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[53]
Transformers: State-of-the-Art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[54]
Advances in Neural Information Processing Systems , volume=
Removing bias in multi-modal classifiers: Regularization by maximizing functional entropies , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
A value for n-person games , author=. , year=
-
[56]
Advances in neural information processing systems , volume=
A unified approach to interpreting model predictions , author=. Advances in neural information processing systems , volume=
-
[57]
SGDR: Stochastic Gradient Descent with Warm Restarts
Sgdr: Stochastic gradient descent with warm restarts , author=. arXiv preprint arXiv:1608.03983 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Presentation at Google, Mountain View, 2nd April , volume=
Statistical language models based on neural networks , author=. Presentation at Google, Mountain View, 2nd April , volume=
-
[59]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Increasing Visual Awareness in Multimodal Neural Machine Translation from an Information Theoretic Perspective , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[60]
1999 , publisher=
Elements of information theory , author=. 1999 , publisher=
1999
-
[61]
Advances in neural information processing systems , volume=
Supervised contrastive learning , author=. Advances in neural information processing systems , volume=
-
[62]
International Conference on Machine Learning , pages=
Dissecting supervised contrastive learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[63]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
International Conference on Machine Learning , pages=
Sorting out Lipschitz function approximation , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[65]
Intriguing properties of neural networks
Intriguing properties of neural networks , author=. arXiv preprint arXiv:1312.6199 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
Advances in Neural Information Processing Systems , volume=
Perceptual score: What data modalities does your model perceive? , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
Proceedings of the 25th ACM international conference on Multimedia , pages=
Adversarial cross-modal retrieval , author=. Proceedings of the 25th ACM international conference on Multimedia , pages=
-
[68]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[69]
Proceedings of the conference
Multimodal transformer for unaligned multimodal language sequences , author=. Proceedings of the conference. Association for computational linguistics. Meeting , volume=. 2019 , organization=
2019
-
[70]
Tensor Fusion Network for Multimodal Sentiment Analysis
Tensor fusion network for multimodal sentiment analysis , author=. arXiv preprint arXiv:1707.07250 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Advances in neural information processing systems , volume=
Attention bottlenecks for multimodal fusion , author=. Advances in neural information processing systems , volume=
-
[72]
Demystifying clip data , author=. arXiv preprint arXiv:2309.16671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
arXiv preprint arXiv:2402.16318 , year=
Gradient-Guided Modality Decoupling for Missing-Modality Robustness , author=. arXiv preprint arXiv:2402.16318 , year=
-
[74]
arXiv preprint arXiv:2405.07930 , year=
Improving Multimodal Learning with Multi-Loss Gradient Modulation , author=. arXiv preprint arXiv:2405.07930 , year=
-
[75]
Journal of Machine Learning Research , volume=
All models are wrong, but many are useful: Learning a variable's importance by studying an entire class of prediction models simultaneously , author=. Journal of Machine Learning Research , volume=
-
[76]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , pages=
Fooling lime and shap: Adversarial attacks on post hoc explanation methods , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , pages=
-
[77]
2018 , publisher=
Density estimation for statistics and data analysis , author=. 2018 , publisher=
2018
-
[78]
2015 , publisher=
Multivariate density estimation: theory, practice, and visualization , author=. 2015 , publisher=
2015
-
[79]
something something
The" something something" video database for learning and evaluating visual common sense , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[80]
The information bottleneck method
The information bottleneck method , author=. arXiv preprint physics/0004057 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[81]
2015 ieee information theory workshop (itw) , pages=
Deep learning and the information bottleneck principle , author=. 2015 ieee information theory workshop (itw) , pages=. 2015 , organization=
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.