Two to Tango: Coupled Task-Reference Selection for Safe LLM Fine-tuning
Pith reviewed 2026-06-28 15:56 UTC · model grok-4.3
The pith
DualSelect jointly selects task samples and safety references to preserve LLM safety during fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
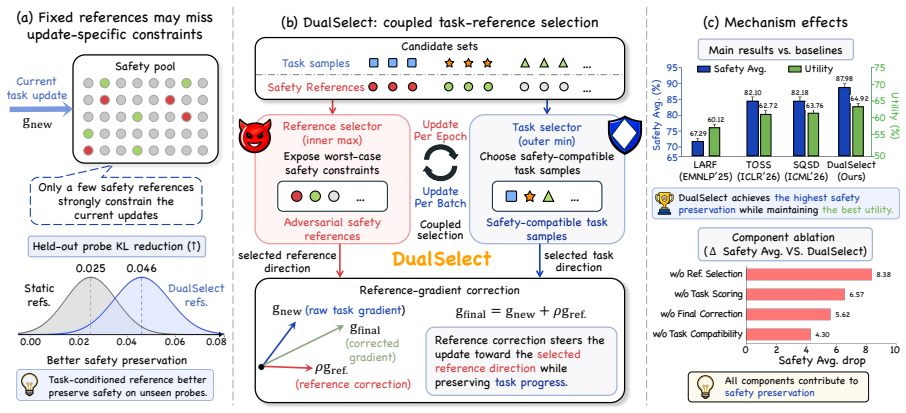
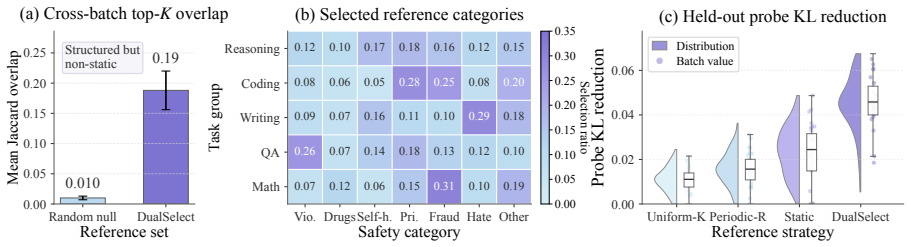
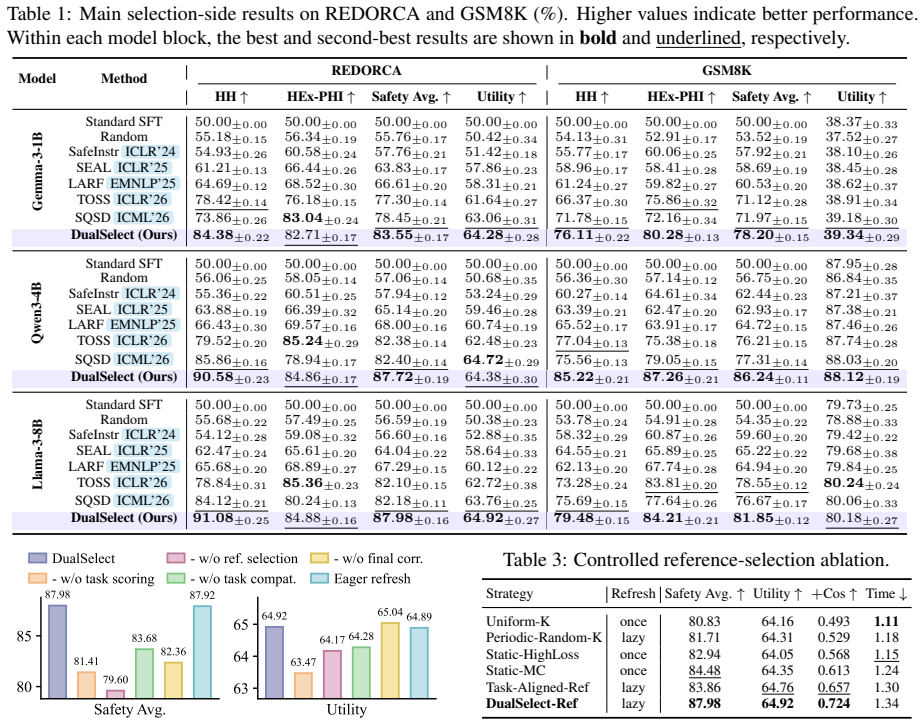
DualSelect selects safety references that have high preservation loss and task conflict, together with compatible task samples, through entropy-regularized scoring surrogates, lazy reference refresh, and gradient correction. On 1B-8B LLMs it preserves safety without losing task utility; using the REDORCA judge it improves Safety Avg. over the strongest baseline by at least 5.10 points and remains highest in Safety Avg. across judges with moderate overhead. This view extends to retention focused continual learning.
What carries the argument
DualSelect, the coupled framework that refreshes task-conditioned safety references before filtering whole task samples compatible with the induced reference direction.
If this is right
- Safety Avg. rises by at least 5.10 points over the strongest baseline on the REDORCA judge.
- Safety Avg. stays highest across multiple judges while task utility is retained.
- The method incurs only moderate overhead.
- The same coupled selection logic applies to retention-focused continual learning.
Where Pith is reading between the lines
- The minimax formulation might link to other game-theoretic selection problems in machine learning.
- The refresh-and-filter pattern could be tested on alignment dimensions beyond safety, such as factual consistency.
- Scaling the approach to models larger than 8B would show whether the safety gains persist.
Load-bearing premise
Task updates expose different safety constraints that require joint selection of references and task samples rather than handling them separately.
What would settle it
On the same 1B-8B model benchmarks and judges, DualSelect produces safety averages no higher than the strongest baseline while still matching task utility.
Figures

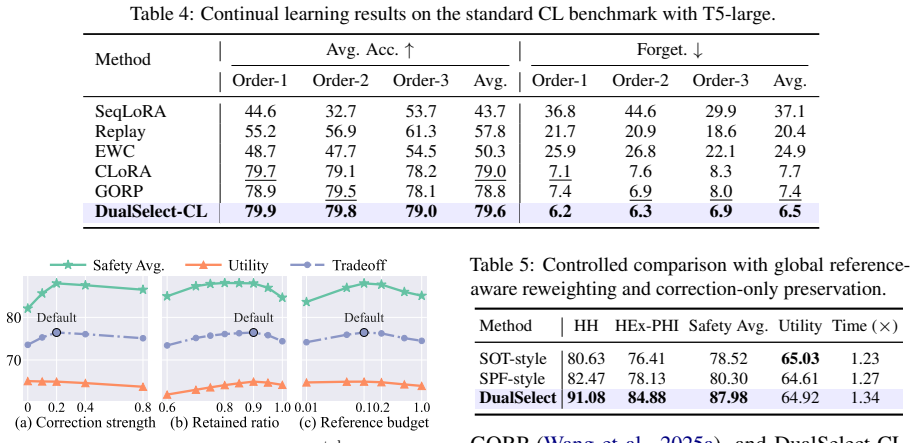
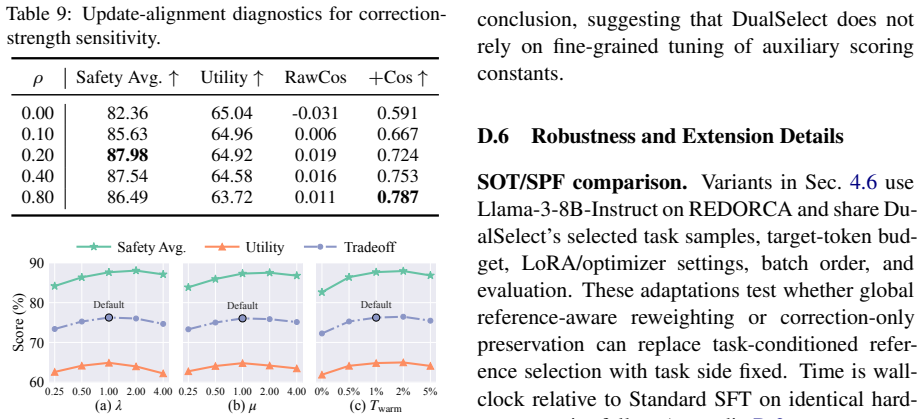
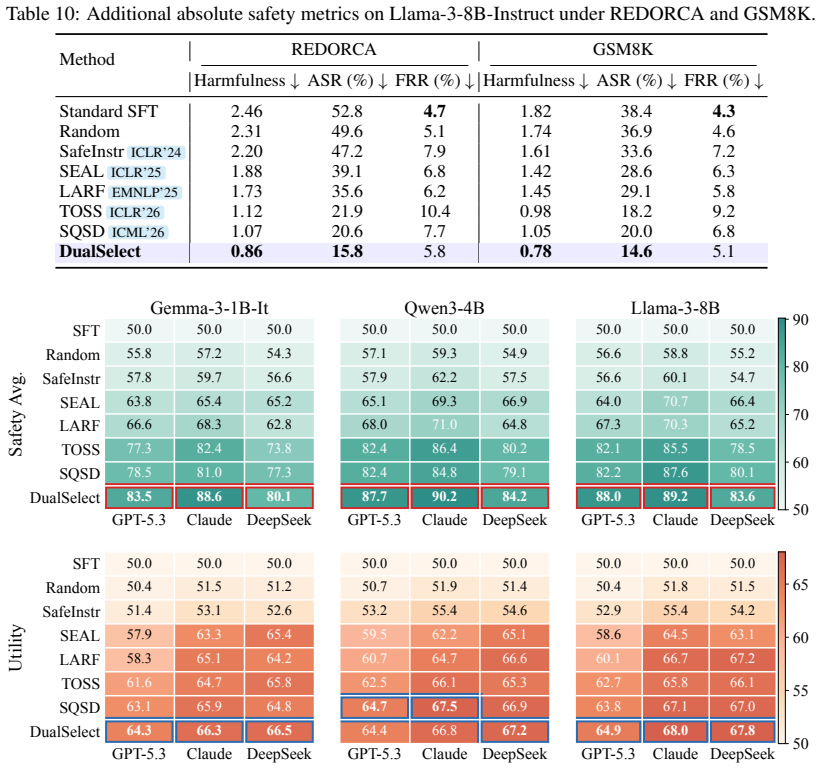
read the original abstract
Fine-tuning safety aligned large language models (LLMs) on downstream data improves adaptation but may erode learned safety behavior. Existing methods use fixed safety examples, global constraints, or one-sided task filtering. Our diagnostics show task updates expose different safety constraints, motivating joint selection of relevant references and compatible task samples. We propose DualSelect, a coupled framework for task and reference selection that refreshes task conditioned safety references before filtering whole task samples compatible with the induced reference direction. Under a minimax view, DualSelect selects safety references with high preservation loss and task conflict, together with compatible task samples, through entropy-regularized scoring surrogates, lazy reference refresh, and gradient correction. On 1B-8B LLMs, DualSelect preserves safety without losing task utility; using the REDORCA judge, it improves Safety Avg. over the strongest baseline by at least 5.10 points and remains highest in Safety Avg. across judges with moderate overhead. This view extends to retention focused continual learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DualSelect, a coupled task-reference selection framework for safe LLM fine-tuning. It motivates the approach by noting that task updates expose varying safety constraints, then frames selection as a minimax problem solved via entropy-regularized scoring surrogates, lazy reference refresh, and gradient correction. The method refreshes task-conditioned safety references before filtering compatible task samples. On 1B-8B LLMs it reports preserving safety while retaining task utility, with a Safety Avg. improvement of at least 5.10 points over the strongest baseline under the REDORCA judge and top-ranked safety across multiple judges, at moderate overhead; the approach is also positioned as applicable to retention-focused continual learning.
Significance. If the empirical claims hold under full experimental scrutiny, the work offers a practical, adaptive alternative to fixed safety examples or one-sided filtering by explicitly coupling reference and task selection. The quantified margin on multiple model scales and judges, together with the extension to continual learning, would make the contribution relevant to the safe-adaptation literature.
major comments (2)
- [Experiments] Experimental section: the abstract states a ≥5.10 point Safety Avg. gain on REDORCA but supplies no information on baseline implementations, number of random seeds, variance, or statistical tests; without these the reported margin cannot be assessed for robustness and is load-bearing for the central empirical claim.
- [Methods] Methods: the minimax framing and entropy-regularized surrogates are presented at a high level; explicit equations showing how the surrogates are computed from the preservation-loss and conflict terms, and how lazy refresh plus gradient correction are applied, are required to verify that the procedure is not circular or task-specific by construction.
minor comments (2)
- Define the REDORCA judge and all other acronyms on first use in the abstract and main text.
- The abstract would benefit from a one-sentence statement of the number of tasks, model sizes, and evaluation judges used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Experiments] Experimental section: the abstract states a ≥5.10 point Safety Avg. gain on REDORCA but supplies no information on baseline implementations, number of random seeds, variance, or statistical tests; without these the reported margin cannot be assessed for robustness and is load-bearing for the central empirical claim.
Authors: We agree that the current experimental section does not provide sufficient detail on these aspects to allow independent assessment of robustness. In the revised manuscript we will expand the experimental section to explicitly describe baseline implementations, the number of random seeds, variance across runs, and any statistical tests performed. revision: yes
-
Referee: [Methods] Methods: the minimax framing and entropy-regularized surrogates are presented at a high level; explicit equations showing how the surrogates are computed from the preservation-loss and conflict terms, and how lazy refresh plus gradient correction are applied, are required to verify that the procedure is not circular or task-specific by construction.
Authors: We acknowledge that the methods presentation remains at a high level. In the revision we will insert the explicit equations for the entropy-regularized scoring surrogates (derived from the preservation-loss and conflict terms), the lazy reference refresh schedule, and the gradient correction step, together with a short argument showing that the procedure is not circular or task-specific by construction. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces DualSelect as a new coupled selection procedure motivated by diagnostics on task-induced safety constraints, framed under a minimax view with entropy-regularized surrogates, lazy refresh, and gradient correction. The load-bearing claims are empirical (Safety Avg. gains of ≥5.10 points on 1B-8B models versus baselines, using named judges), with no equations, fitted parameters renamed as predictions, self-definitional reductions, or load-bearing self-citations that collapse the central result to its own inputs. The derivation remains self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[2]
Journal of machine learning research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of machine learning research , volume=
-
[3]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[4]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo
-
[5]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Realtoxicityprompts: Evaluating neural toxic degeneration in language models , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[6]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Red teaming language models with language models , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[7]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[9]
arXiv preprint arXiv:2508.07172 , year=
Gradient surgery for safe llm fine-tuning , author=. arXiv preprint arXiv:2508.07172 , year=
-
[10]
2004 , publisher=
Convex optimization , author=. 2004 , publisher=
2004
-
[11]
Mathematical programming , volume=
An analysis of approximations for maximizing submodular set functions-I , author=. Mathematical programming , volume=. 1978 , publisher=
1978
-
[12]
50 Years of Integer Programming 1958-2008: from the Early Years to the State-of-the-Art , pages=
Reducibility among combinatorial problems , author=. 50 Years of Integer Programming 1958-2008: from the Early Years to the State-of-the-Art , pages=. 2009 , publisher=
1958
-
[13]
International Conference on Learning Representations , year=
Fast is better than free: Revisiting adversarial training , author=. International Conference on Learning Representations , year=
-
[14]
International Conference on Machine Learning , pages=
Towards Stable and Efficient Adversarial Training against l\_1 Bounded Adversarial Attacks , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[15]
Efficient Lifelong Learning with A-
Arslan Chaudhry and Marc'Aurelio Ranzato and Marcus Rohrbach and Mohamed Elhoseiny , booktitle=. Efficient Lifelong Learning with A-
-
[16]
IEEE transactions on pattern analysis and machine intelligence , volume=
A comprehensive survey of continual learning: Theory, method and application , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2024 , publisher=
2024
-
[17]
Annals of operations research , volume=
An overview of bilevel optimization , author=. Annals of operations research , volume=. 2007 , publisher=
2007
-
[18]
International conference on machine learning , pages=
Hyperparameter optimization with approximate gradient , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[19]
International conference on artificial intelligence and statistics , pages=
Optimizing millions of hyperparameters by implicit differentiation , author=. International conference on artificial intelligence and statistics , pages=. 2020 , organization=
2020
-
[20]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[21]
Progressive neural networks , author=. arXiv preprint arXiv:1606.04671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Advances in neural information processing systems , volume=
Gradient episodic memory for continual learning , author=. Advances in neural information processing systems , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
Keeping llms aligned after fine-tuning: The crucial role of prompt templates , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Advances in Neural Information Processing Systems , volume=
Navigating the safety landscape: Measuring risks in finetuning large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
Advances in Neural Information Processing Systems , volume=
Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Advances in Neural Information Processing Systems , volume=
Lisa: Lazy safety alignment for large language models against harmful fine-tuning attack , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
The Thirteenth International Conference on Learning Representations , year =
Booster: Tackling Harmful Fine-tuning for Large Language Models via Attenuating Harmful Perturbation , author=. The Thirteenth International Conference on Learning Representations , year =
-
[28]
The Thirteenth International Conference on Learning Representations , year =
SEAL: Safety-enhanced Aligned LLM Fine-tuning via Bilevel Data Selection , author=. The Thirteenth International Conference on Learning Representations , year =
-
[29]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Layer-aware representation filtering: Purifying finetuning data to preserve llm safety alignment , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[30]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
How to Fine-Tune Safely on a Budget: Model Adaptation Using Minimal Resources , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[31]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
Adaptive Defense against Harmful Fine-Tuning for Large Language Models via Bayesian Data Scheduler , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[32]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
Shape it Up! Restoring LLM Safety during Finetuning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[33]
Forty-second International Conference on Machine Learning , year =
Antidote: Post-fine-tuning Safety Alignment for Large Language Models against Harmful Fine-tuning Attack , author=. Forty-second International Conference on Machine Learning , year =
-
[34]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
Panacea: Mitigating Harmful Fine-tuning for Large Language Models via Post-fine-tuning Perturbation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[35]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Data advisor: Dynamic data curation for safety alignment of large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[36]
arXiv preprint arXiv:2510.10085 , year=
Pharmacist: Safety alignment data curation for large language models against harmful fine-tuning , author=. arXiv preprint arXiv:2510.10085 , year=
-
[37]
Token-level Data Selection for Safe
Yanping Li and Zhening Liu and Zijian Li and Zehong Lin and Jun Zhang , booktitle=. Token-level Data Selection for Safe
-
[38]
The Fourteenth International Conference on Learning Representations , year=
Antibody: Strengthening Defense Against Harmful Fine-Tuning for Large Language Models via Attenuating Harmful Gradient Influence , author=. The Fourteenth International Conference on Learning Representations , year=
-
[39]
Shuhao Chen and Weisen Jiang and Yeqi Gong and Shengda Luo and Chengxiang Zhuo and Zang Li and James Kwok and Yu Zhang , year=
-
[40]
GradShield: Alignment Preserving Finetuning
GradShield: Alignment Preserving Finetuning , author=. arXiv preprint arXiv:2605.14194 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Separate the wheat from the chaff: A post-hoc approach to safety re-alignment for fine-tuned language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Lssf: Safety alignment for large language models through low-rank safety subspace fusion , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[43]
Advances in Neural Information Processing Systems , volume=
Smalltolarge (s2l): Scalable data selection for fine-tuning large language models by summarizing training trajectories of small models , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Davir: Data selection via implicit reward for large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[45]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Data whisperer: Efficient data selection for task-specific llm fine-tuning via few-shot in-context learning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hft: Half fine-tuning for large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[47]
Forty-second International Conference on Machine Learning , year=
Boosting Multi-Domain Fine-Tuning of Large Language Models through Evolving Interactions between Samples , author=. Forty-second International Conference on Machine Learning , year=
-
[48]
Token Cleaning: Fine-Grained Data Selection for
Jinlong Pang and Na Di and Zhaowei Zhu and Jiaheng Wei and Hao Cheng and Chen Qian and Yang Liu , booktitle=. Token Cleaning: Fine-Grained Data Selection for
-
[49]
Mengzhou Xia and Sadhika Malladi and Suchin Gururangan and Sanjeev Arora and Danqi Chen , booktitle=
-
[50]
GIST: Targeted Data Selection for Instruction Tuning via Coupled Optimization Geometry , author=
-
[51]
Zichun Yu and Spandan Das and Chenyan Xiong , booktitle=
-
[52]
Learn More, Forget Less: A Gradient-Aware Data Selection Approach for LLM , author=
-
[53]
Yichen Yan and Ming Zhong and Qi Zhu and Xiaoling Gu and Jinpeng Chen and Huan Li , booktitle=. Co
-
[54]
Diversity as a Reward: Fine-Tuning
Zhenqing Ling and Daoyuan Chen and Liuyi Yao and Qianli Shen and Yaliang Li and Ying Shen , booktitle=. Diversity as a Reward: Fine-Tuning
-
[55]
ProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection
ProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection , author=. arXiv preprint arXiv:2601.09195 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
The Thirteenth International Conference on Learning Representations , year=
Data Shapley in One Training Run , author=. The Thirteenth International Conference on Learning Representations , year=
-
[57]
Reza Shirkavand and Peiran Yu and Qi He and Heng Huang , booktitle=. Bilevel
-
[58]
International conference on machine learning , pages=
A generic first-order algorithmic framework for bi-level programming beyond lower-level singleton , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[59]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
A general descent aggregation framework for gradient-based bi-level optimization , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2022 , publisher=
2022
-
[60]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[61]
International conference on machine learning , pages=
Bilevel programming for hyperparameter optimization and meta-learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[62]
Hanxiao Liu and Karen Simonyan and Yiming Yang , booktitle=
-
[63]
Yang Yu and Kai Han and Hang Zhou and Yehui Tang and Kaiqi Huang and Yunhe Wang and Dacheng Tao , booktitle=
-
[64]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Beyond Value Functions: Single-Loop Bilevel Optimization under Flatness Conditions , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[65]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Compress Large Language Models via Collaboration Between Learning and Matrix Approximation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[66]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Recurrent knowledge identification and fusion for language model continual learning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[67]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Continual Learning Using Only Large Language Model Prompting , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[68]
International Conference on Machine Learning , pages=
Learning Dynamics in Continual Pre-Training for Large Language Models , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[69]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Gated Integration of Low-Rank Adaptation for Continual Learning of Large Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[70]
arXiv preprint arXiv:2509.23893 , year=
Dynamic Orthogonal Continual Fine-tuning for Mitigating Catastrophic Forgettings , author=. arXiv preprint arXiv:2509.23893 , year=
-
[71]
Continual learning via sparse memory finetuning, 2025
Continual learning via sparse memory finetuning , author=. arXiv preprint arXiv:2510.15103 , year=
-
[72]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[73]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[74]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , author =
-
[75]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Recursive deep models for semantic compositionality over a sentiment treebank , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
2013
-
[76]
Advances in neural information processing systems , volume=
Character-level convolutional networks for text classification , author=. Advances in neural information processing systems , volume=
-
[77]
Hugging Face dataset repository , year=
Openorca: An open dataset of gpt augmented flan reasoning traces , author=. Hugging Face dataset repository , year=
-
[78]
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Orca: Progressive learning from complex explanation traces of gpt-4 , author=. arXiv preprint arXiv:2306.02707 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned , author=. arXiv preprint arXiv:2209.07858 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Hex-phi: Human-extended policy-oriented harmful instruction benchmark , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.