SHAPE: Coalition-Aware Expert Pruning for Sparse Mixture-of-Experts LLMs
Pith reviewed 2026-06-28 07:28 UTC · model grok-4.3
The pith
SHAPE uses Shapley attribution on expert coalitions from routing traces to prune MoE models while preserving competitive accuracy at 20-40% sparsity without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
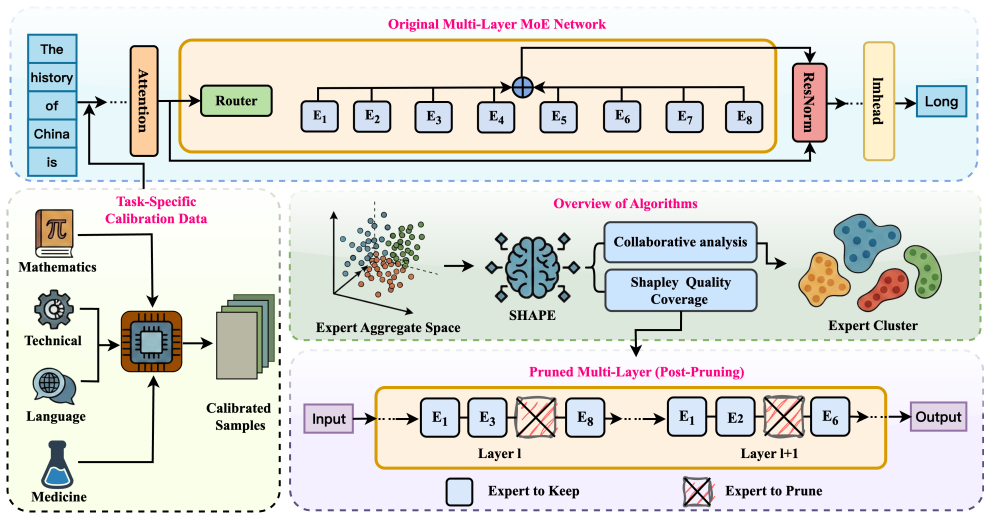
SHAPE formulates routing traces on a small calibration set as an empirical cooperative game and assigns interaction-aware expert values via a Shapley-style attribution over observed top-k coalitions, enabling the identification of experts that are essential for high-utility collaborations rather than merely frequent. To preserve MoE topology under a global pruning budget, SHAPE further introduces a quality-coverage selection rule that retains, in each layer, the minimal expert subset covering an alpha fraction of non-negative Shapley mass, while using bisection to match a target keep rate.
What carries the argument
Shapley-style attribution computed over empirical top-k coalitions from calibration routing traces, followed by per-layer quality-coverage selection under a global budget.
If this is right
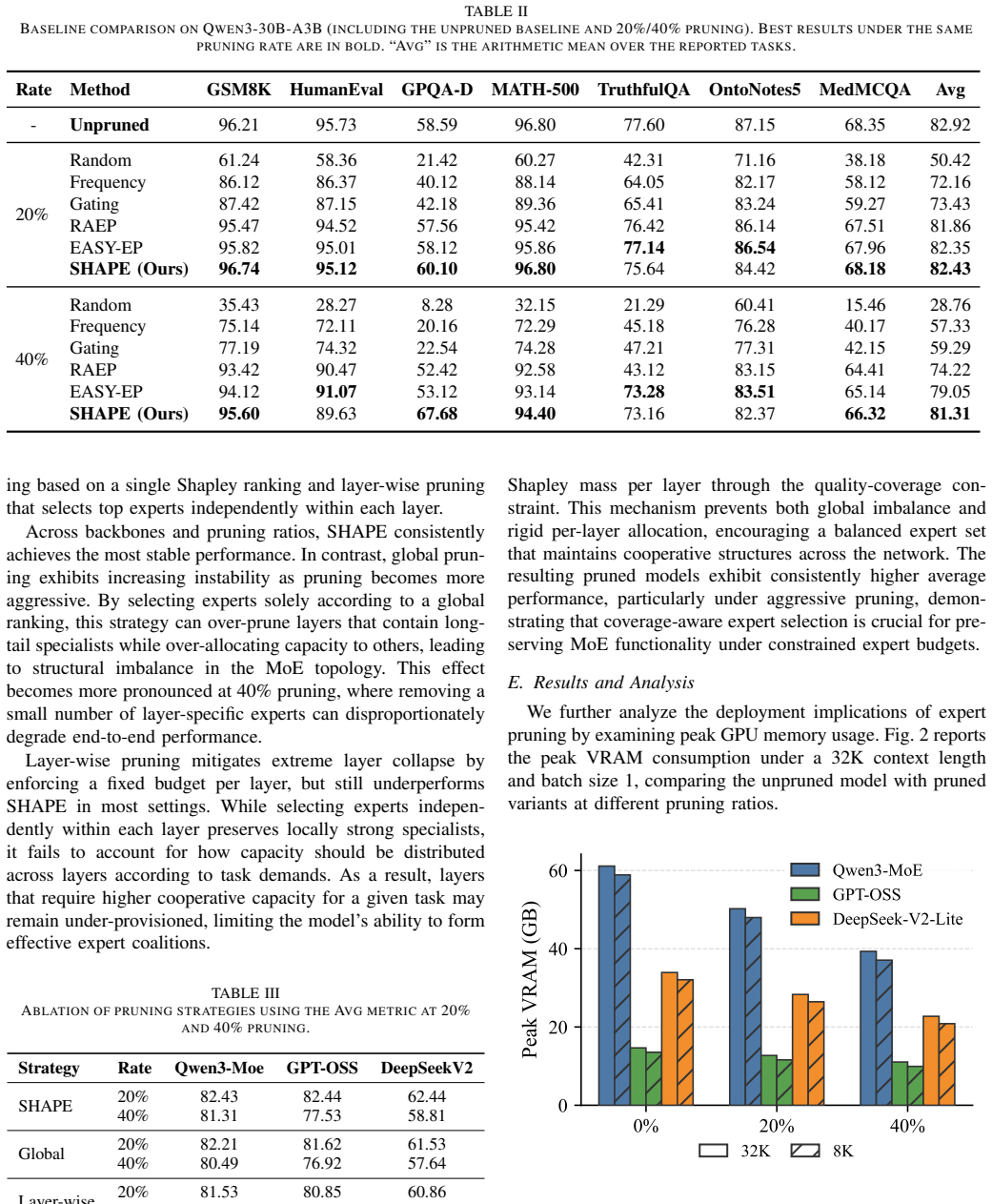
- SHAPE maintains competitive accuracy under 20% and 40% expert pruning on three modern MoE backbones.
- It improves robustness relative to both global and layer-wise pruning baselines.
- It produces measurable reductions in peak GPU memory footprint.
- All results are obtained without any additional training after the pruning step.
Where Pith is reading between the lines
- If routing statistics on small calibration sets prove stable, the same attribution pipeline could support periodic re-pruning as usage patterns evolve.
- The coalition view may generalize to other routed architectures where outputs depend on small active subsets rather than independent components.
- Memory savings could enable larger expert pools on the same hardware by pruning after initial training rather than limiting pool size upfront.
Load-bearing premise
Shapley values derived from routing traces on a small calibration set identify experts that remain essential for high-utility collaborations when the pruned model is deployed on the full data distribution.
What would settle it
A large accuracy drop on held-out benchmarks when the SHAPE-pruned model is compared with the unpruned baseline, or when the same pruning mask is applied after swapping the calibration set for data drawn from a shifted distribution.
Figures
read the original abstract
Sparse Mixture-of-Experts (MoE) large language models achieve strong quality with low per-token compute, yet their deployment is often limited by the memory wall: the full expert pool must remain resident to support token-dependent routing. Expert pruning is a direct remedy, but prior criteria typically score experts independently and overlook that MoE inference is inherently \emph{coalitional}, where outputs arise from routed top-$k$ expert combinations. We propose \textbf{SHAPE}, a task-driven pruning framework that explicitly models \emph{intra-layer} expert cooperation. SHAPE formulates routing traces on a small calibration set as an empirical cooperative game and assigns interaction-aware expert values via a Shapley-style attribution over observed top-$k$ coalitions, enabling the identification of experts that are essential for high-utility collaborations rather than merely frequent. To preserve MoE topology under a global pruning budget, SHAPE further introduces a \emph{quality-coverage} selection rule that retains, in each layer, the minimal expert subset covering an $\alpha$ fraction of non-negative Shapley mass, while using bisection to match a target keep rate. Experiments on three modern MoE backbones (Qwen3-30B-A3B, GPT-OSS-20B, and DeepSeek-V2-Lite) across diverse benchmarks show that SHAPE consistently improves robustness over global and layer-wise pruning variants, maintaining competitive accuracy under 20\% and 40\% expert pruning without additional training and delivering clear reductions in peak GPU memory footprint. The open-source code is available at https://github.com/Alizen-1009/Shapley-Moe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SHAPE, a pruning method for sparse MoE LLMs that treats routing traces on a small calibration set as an empirical cooperative game, computes Shapley-style attributions over observed top-k coalitions to value experts based on intra-layer interactions, and applies a quality-coverage rule (retaining the minimal subset covering an α fraction of non-negative Shapley mass per layer, with bisection to meet a target keep rate) to prune under global budgets. Experiments on Qwen3-30B-A3B, GPT-OSS-20B, and DeepSeek-V2-Lite across benchmarks claim consistent robustness gains over global and layer-wise baselines at 20% and 40% expert pruning, with no additional training and reduced peak GPU memory.
Significance. If the calibration-set Shapley values reliably identify coalition-essential experts on the deployment distribution, SHAPE would provide a practical, training-free way to reduce the memory wall for MoE inference while preserving the coalitional structure of routing; the open-source code strengthens reproducibility.
major comments (1)
- [Experiments (implied by abstract and §4)] The central robustness claim (competitive accuracy at 20-40% pruning) rests on the untested assumption that Shapley values from a small calibration set generalize to the full data distribution. No domain-diversity statistics, sensitivity analysis across calibration sources, or comparison of coalition frequencies between calibration and test data are reported, leaving open the possibility that rare high-impact patterns are under-sampled and the quality-coverage rule retains low-value experts.
minor comments (2)
- [Abstract] The abstract states 'without additional training' but does not clarify whether the calibration set itself requires any forward passes beyond standard inference; a brief note on this would aid clarity.
- [Method] Notation for the quality-coverage rule (α fraction of non-negative Shapley mass) is introduced without an explicit equation; adding one would make the bisection procedure easier to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the generalization of calibration-set Shapley values. We address the concern directly below.
read point-by-point responses
-
Referee: [Experiments (implied by abstract and §4)] The central robustness claim (competitive accuracy at 20-40% pruning) rests on the untested assumption that Shapley values from a small calibration set generalize to the full data distribution. No domain-diversity statistics, sensitivity analysis across calibration sources, or comparison of coalition frequencies between calibration and test data are reported, leaving open the possibility that rare high-impact patterns are under-sampled and the quality-coverage rule retains low-value experts.
Authors: We agree that the manuscript does not report domain-diversity statistics for the calibration set, sensitivity analysis across calibration sources, or explicit comparisons of coalition frequencies between calibration and test data. This is a valid observation and constitutes a gap in the current experimental section. In the revised version we will add: (1) domain-diversity statistics (token and task coverage) of the calibration set relative to the evaluation benchmarks, (2) sensitivity results obtained by varying calibration sources (different subsets and domains), and (3) a direct comparison of observed top-k coalition frequencies between calibration traces and evaluation traces. These additions will test the generalization assumption and address the concern about under-sampling of rare high-impact patterns. We therefore plan to incorporate the requested analyses. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper computes empirical Shapley values directly from observed routing traces on a held-out calibration set and applies a quality-coverage selection rule to prune experts. This process is defined independently of the downstream benchmark accuracies used for evaluation. No equations reduce the pruning outcome to fitted performance metrics by construction, no self-citations form load-bearing premises, and no ansatz or uniqueness claims are imported from prior author work. The central claim rests on external empirical validation rather than definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (2)
- alpha
- target keep rate
axioms (1)
- domain assumption Routing traces on a small calibration set form a representative sample of the coalitions that matter for model utility.
Reference graph
Works this paper leans on
-
[1]
Gshard: Scaling giant models with condi- tional computation and automatic sharding,
D. Lepikhin, Lee, and et.al, “Gshard: Scaling giant models with condi- tional computation and automatic sharding,” inInternational Conference on Learning Representations, 2021
2021
-
[2]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[3]
gpt-oss-120b and gpt-oss-20b model card,
OpenAIet al., “gpt-oss-120b and gpt-oss-20b model card,” 2025
2025
-
[4]
Deepseek-v3.2: Pushing the frontier of open large language models,
DeepSeek-AIet al., “Deepseek-v3.2: Pushing the frontier of open large language models,” 2025
2025
-
[5]
Qwen3 technical report,
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, and e. a. Chengen Huang, “Qwen3 technical report,” 2025
2025
-
[6]
Qmoe: Practical sub-1-bit compression of trillion-parameter models,
E. Frantar and D. Alistarh, “Qmoe: Practical sub-1-bit compression of trillion-parameter models,” inConference on Neural Information Processing Systems, 2023
2023
-
[7]
Moequant: Enhancing quantization for mixture- of-experts large language models via expert-balanced sampling and affinity guidance,
X. Hu, Chen, and et.al, “Moequant: Enhancing quantization for mixture- of-experts large language models via expert-balanced sampling and affinity guidance,” inProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[8]
Moe-svd: Structured mixture-of-experts llms compression via singular value decomposition,
W. Liet al., “Moe-svd: Structured mixture-of-experts llms compression via singular value decomposition,” inProceedings of the 42nd Interna- tional Conference on Machine Learning (ICML), 2025
2025
-
[9]
Dropping experts, recombining neurons: Retraining-free pruning for sparse mixture-of-experts llms,
Y . Zhou, Z. Zhao, Cheng, and et.al, “Dropping experts, recombining neurons: Retraining-free pruning for sparse mixture-of-experts llms,” inFindings of the Association for Computational Linguistics: EMNLP 2025
2025
-
[10]
Diep: Adaptive mixture-of-experts compression through differentiable expert pruning,
S. Bai, H. Li, J. Zhang, Z. Hong, and S. Guo, “Diep: Adaptive mixture-of-experts compression through differentiable expert pruning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[11]
arXiv preprint arXiv:2206.00277 , year=
T. Chen, S. Huang, Y . Xie, B. Jiao, D. Jiang, H. Zhou, J. Li, and F. Wei, “Task-specific expert pruning for sparse mixture-of-experts,”CoRR, vol. abs/2206.00277, 2022
-
[12]
Seer-moe: Sparse expert efficiency through regularization for mixture-of-experts,
A. Muzio, A. Sun, and C. He, “Seer-moe: Sparse expert efficiency through regularization for mixture-of-experts,” 2024
2024
-
[13]
A provably effective method for pruning experts in fine-tuned sparse mixture-of-experts,
M. N. R. Chowdhury and et.al, “A provably effective method for pruning experts in fine-tuned sparse mixture-of-experts,” inProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[14]
Seap: Training-free sparse expert activation pruning unlock the brainpower of large language models,
Lianget al., “Seap: Training-free sparse expert activation pruning unlock the brainpower of large language models,”arXiv preprint arXiv:2503.07605, 2025
-
[15]
REAP the Experts: Why Pruning Prevails for One-Shot MoE compression
M. Lasby, I. Lazarevich, N. Sinnadurai, S. Lie, Y . Ioannou, and V . Thangarasa, “Reap the experts: Why pruning prevails for one-shot moe compression,”arXiv preprint arXiv:2510.13999, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Camera: Multi-matrix joint compression for moe models via micro- expert redundancy analysis,
Y . Xu, X. Han, Y . Zhang, Y . Wang, Y . Liu, S. Ji, Q. Zhu, and W. Che, “Camera: Multi-matrix joint compression for moe models via micro- expert redundancy analysis,” 2025
2025
-
[17]
Condense, don’t just prune: Enhancing efficiency and performance in moe layer pruning,
M. Cao, G. Li, J. Ji, J. Zhang, X. Ma, S. Liu, and L. Yin, “Condense, don’t just prune: Enhancing efficiency and performance in moe layer pruning,”Transactions on Machine Learning Research (TMLR), 2025
2025
-
[18]
Diversifying the expert knowledge for task-agnostic pruning in sparse mixture-of-experts,
Z. Zhang, X. Liu, H. Cheng, C. Xu, and J. Gao, “Diversifying the expert knowledge for task-agnostic pruning in sparse mixture-of-experts,” in Findings of the Association for Computational Linguistics: ACL 2025
2025
-
[19]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer, Mirhoseini, and et.al, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inInternational Confer- ence on Learning Representations (ICLR), 2017
2017
-
[20]
Unveiling super experts in mixture-of-experts large language models,
Z. Su, Q. Li, H. Zhang, W. Ye, Q. Xue, Y . Qian, Y . Xie, N. Wong, and K. Yuan, “Unveiling super experts in mixture-of-experts large language models,” 2025
2025
-
[21]
Training verifiers to solve math word problems,
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman, “Training verifiers to solve math word problems,” 2021
2021
-
[22]
Humaneval-xl: A multilingual code generation benchmark for cross-lingual natural language generalization,
Q. Peng, Y . Chai, and X. Li, “Humaneval-xl: A multilingual code generation benchmark for cross-lingual natural language generalization,” inProceedings of the 2024 Joint International Conference on Compu- tational Linguistics
2024
-
[23]
A value for n-person games,
L. S. Shapley, “A value for n-person games,” inContributions to the Theory of Games, H. W. Kuhn and A. W. Tucker, Eds. Princeton University Press, 1953
1953
-
[24]
St-moe: Designing stable and transferable sparse expert models,
B. Zoph, I. Bello, S. Kumar, N. Du, Y . Huang, J. Dean, N. Shazeer, and W. Fedus, “St-moe: Designing stable and transferable sparse expert models,”Transactions on Machine Learning Research (TMLR), 2022
2022
-
[25]
Mixtral of experts,
Mistral AI, “Mixtral of experts,” 2023, model release / technical report
2023
-
[26]
A provably effective method for pruning experts in fine-tuned sparse mixture-of-experts,
M. N. R. Chowdhury, M. Wang, K. E. Maghraoui, N. Wang, P.-Y . Chen, and C. Carothers, “A provably effective method for pruning experts in fine-tuned sparse mixture-of-experts,” 2024
2024
-
[27]
Domain-specific pruning of large mixture-of-experts models with few- shot demonstrations,
Z. Dong, H. Peng, P. Liu, X. Zhao, D. Wu, F. Xiao, and Z. Wang, “Domain-specific pruning of large mixture-of-experts models with few- shot demonstrations,” inAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[28]
One student knows all experts know: From sparse to dense,
F. Xue, X. He, X. Ren, Y . Lou, and Y . You, “One student knows all experts know: From sparse to dense,” inTiny Papers @ ICLR 2023
2023
-
[29]
Rethinking the knowledge distillation from the perspective of model calibration,
L. Yang and J. Song, “Rethinking the knowledge distillation from the perspective of model calibration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[30]
Moe pathfinder: Trajectory-driven expert pruning,
X. Yang, Y . Tian, and Y . Song, “Moe pathfinder: Trajectory-driven expert pruning,” 2025
2025
-
[31]
Unveiling hidden collaboration within mixture-of-experts in large language models,
Y . Tang, Y . Tang, N. Zhang, M. Chen, and Y . Li, “Unveiling hidden collaboration within mixture-of-experts in large language models,” 2025
2025
-
[32]
Neuron shapley: Discovering the responsi- ble neurons,
A. Ghorbani and J. Zou, “Neuron shapley: Discovering the responsi- ble neurons,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[33]
Explaining deep neural networks with a polynomial time algorithm for shapley value approximation,
M. Ancona, C. Oztireli, and M. Gross, “Explaining deep neural networks with a polynomial time algorithm for shapley value approximation,” in Proceedings of the 36th International Conference on Machine Learning (ICML), 2019
2019
-
[34]
Data shapley valuation for efficient batch active learning,
A. Ghorbani, J. Zou, and A. Esteva, “Data shapley valuation for efficient batch active learning,” in2022 56th Asilomar Conference on Signals, Systems, and Computers. IEEE, 2022
2022
-
[35]
Enhancing interpretability for vision models via shapley value optimization,
K. Fan, Y . Yang, and C. Ma, “Enhancing interpretability for vision models via shapley value optimization,” inProceedings of the 40th Annual AAAI Conference on Artificial Intelligence (AAAI), 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.