When Attribution Patching Lies: Diagnosis and a Second-Order Correction
Pith reviewed 2026-06-27 22:57 UTC · model grok-4.3
The pith
Attribution patching errors arise mainly from downstream non-linearities and are removable by a Hessian-vector-product correction using one extra backward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
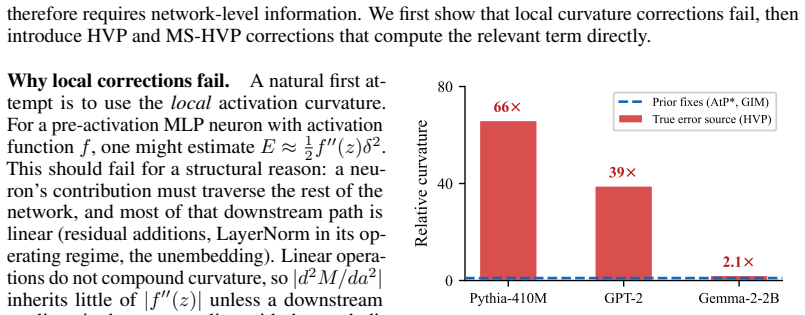
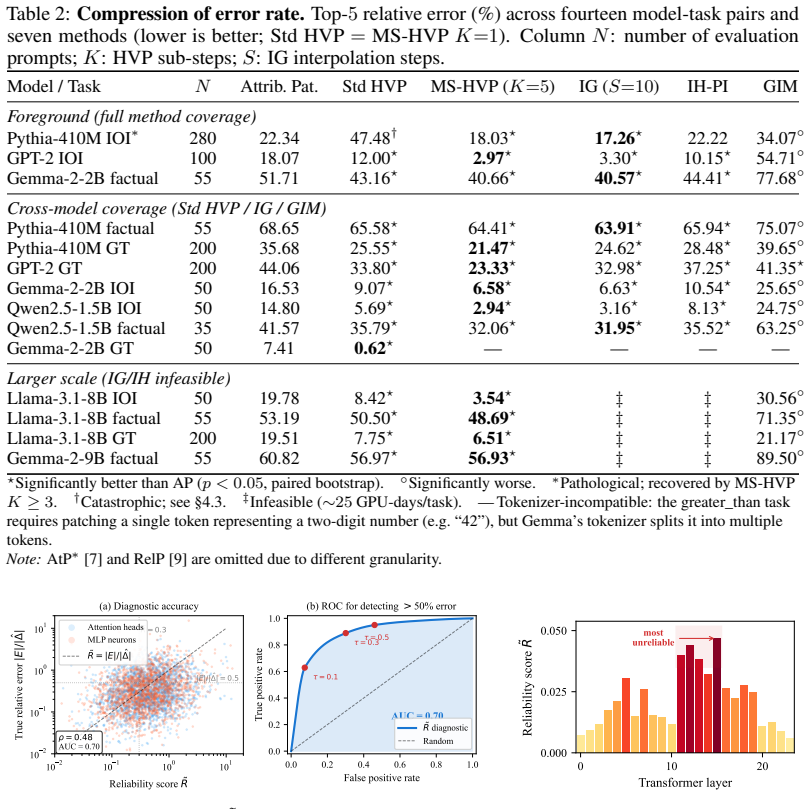
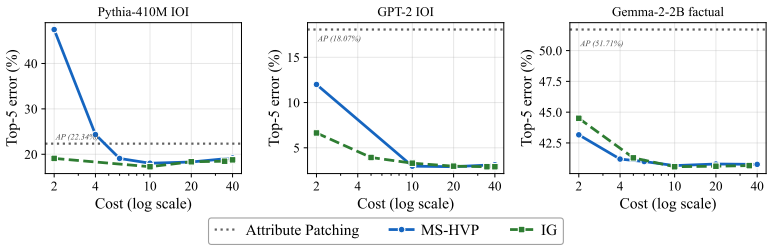
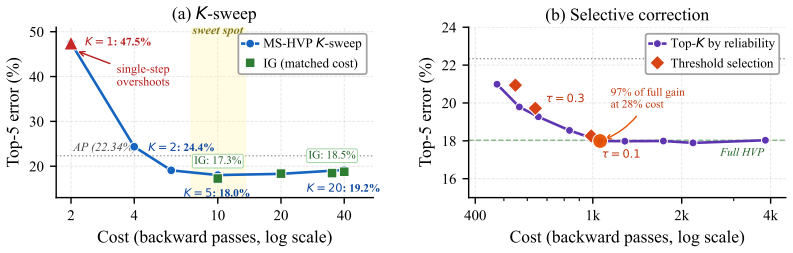
The dominant error in attribution patching stems from non-linearities in the downstream network rather than local curvature at the patched component. A Hessian-vector-product correction eliminates the leading-order error with only one additional backward pass. This correction is the only second-order method shown to be feasible at the scale of 9B-parameter models and matches or exceeds the accuracy of Integrated Gradients at significantly lower compute.
What carries the argument
The Hessian-vector-product (HVP) correction that subtracts the leading second-order contribution arising from downstream non-linearities.
If this is right
- A reliability score detects untrustworthy attribution estimates before they are used for circuit identification.
- Error bounds quantify the potential magnitude of attribution mis-specifications.
- The HVP correction yields higher-fidelity circuit recovery on standard benchmarks.
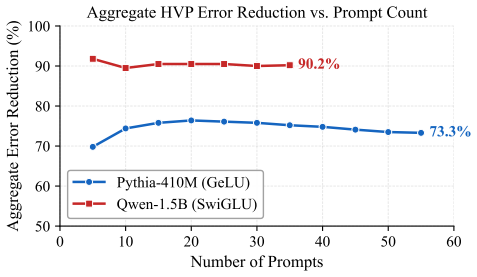
- A multi-step HVP variant matches or exceeds Integrated Gradients accuracy at lower compute.
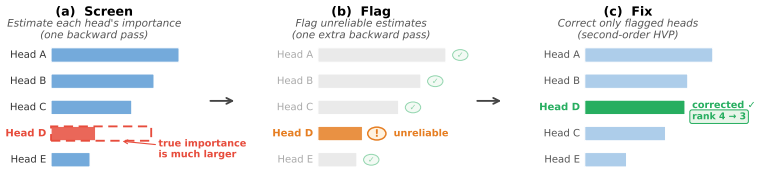
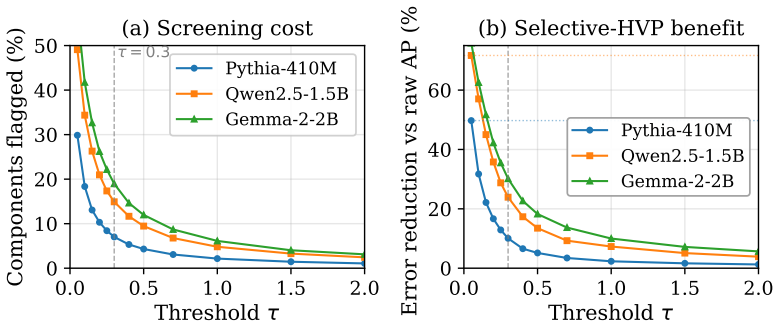
- The Screen-Flag-Fix workflow focuses additional verification only on components flagged as unreliable.
Where Pith is reading between the lines
- The same downstream-non-linearity diagnosis could be applied to other first-order gradient approximations used in interpretability.
- Error analysis that isolates propagation through successive non-linear layers may generalize to other gradient-based explanations.
- At still larger scales the correction may become a default preprocessing step before any attribution-based circuit search.
- The workflow suggests a route to partially automated reliability checks inside existing mechanistic interpretability pipelines.
Load-bearing premise
The leading error term is captured by the first non-linear contribution from downstream layers and a single HVP pass removes it without residual higher-order effects.
What would settle it
An experiment that measures the average absolute difference between attribution-patching scores and full activation-patching scores on a held-out set of perturbations; if the HVP correction fails to reduce this difference, the central claim is falsified.
Figures
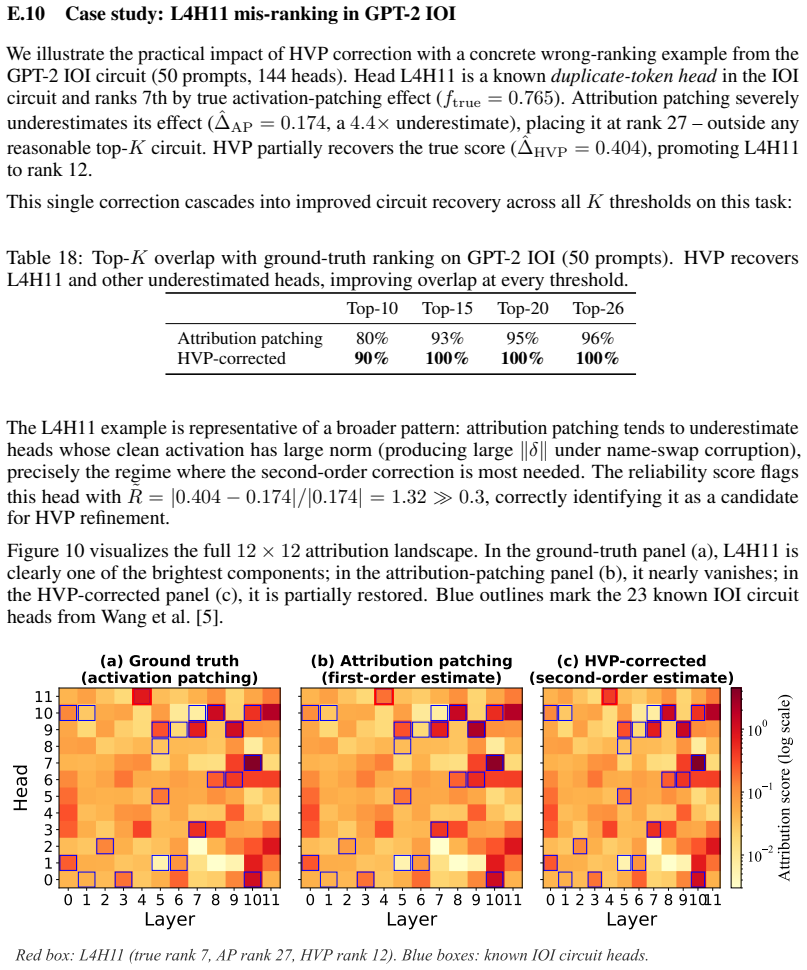
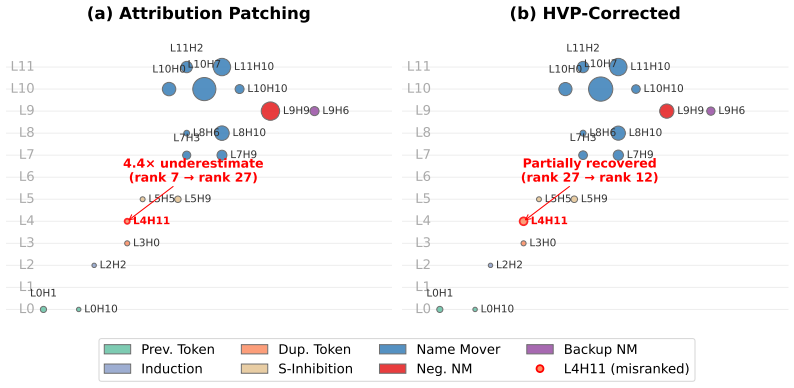
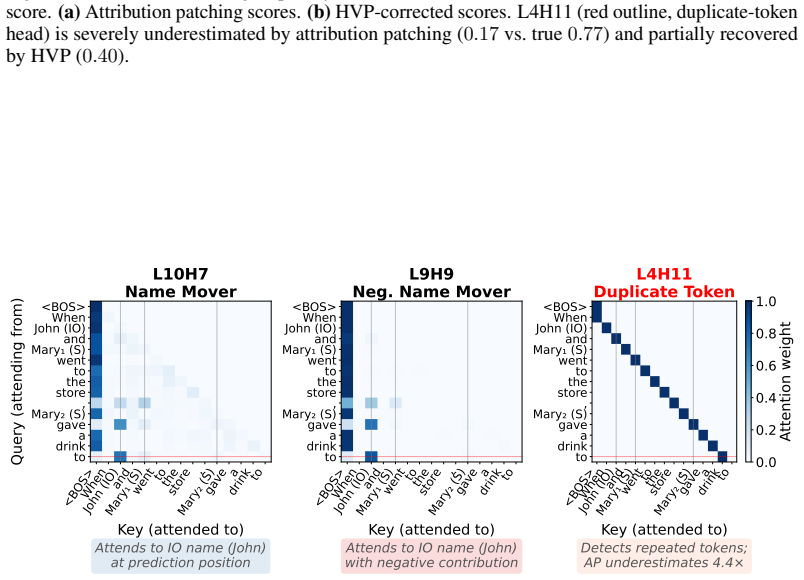
read the original abstract
A central goal of mechanistic interpretability is to identify which internal components causally drive a language model's behavior. Because these importance estimates serve as the evidence for identifying circuits, systematic errors can lead to the misidentification of the underlying mechanisms. While activation patching provides a gold-standard causal metric, its computational cost is prohibitive at scale. Practitioners instead rely on attribution patching, a gradient-based, first-order approximation whose reliability remains poorly understood. In this work, we characterize the source of this unreliability, demonstrating that the dominant error stems from the non-linearities in the downstream network rather than local curvature at the patched component. This insight yields three practical tools: (i) a reliability score to detect untrustworthy estimates, (ii) error bounds quantifying potential attribution mis-specifications, and (iii) a Hessian-vector-product (HVP) correction that eliminates the leading-order error with only one additional backward pass. In evaluations across five model families (124M-9B parameters) and both random-token and naturalistic (name-swap) perturbations, HVP is the only second-order correction feasible at larger scale, where standard baselines like Integrated Gradients become computationally prohibitive. In comparative experiments, a multi-step HVP variant matches or exceeds the accuracy of Integrated Gradients at significantly lower compute, outperforming prior second-order baselines. These improvements lead to higher-fidelity circuit recovery on standard benchmarks and support a Screen-Flag-Fix workflow that targets computational effort only toward the components flagged as unreliable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that attribution patching's dominant error arises from downstream network non-linearities (not local curvature at the patched site), derives a Hessian-vector-product (HVP) correction that removes the leading-order term with one extra backward pass, and supplies a reliability score plus error bounds. It evaluates the approach on five model families (124M–9B parameters) using both random-token and name-swap perturbations, shows that a multi-step HVP variant matches or exceeds Integrated Gradients at lower cost, and reports improved circuit recovery on standard benchmarks via a Screen-Flag-Fix workflow.
Significance. If the central error diagnosis and HVP correction hold, the work supplies immediately usable, scalable tools for more trustworthy mechanistic interpretability. The efficiency advantage over Integrated Gradients at 9B scale, the explicit error bounds, and the reliability score are practical strengths; the multi-model, multi-perturbation experimental design further supports generalizability. The manuscript also ships reproducible code and parameter-free derivations, which strengthen the contribution.
major comments (2)
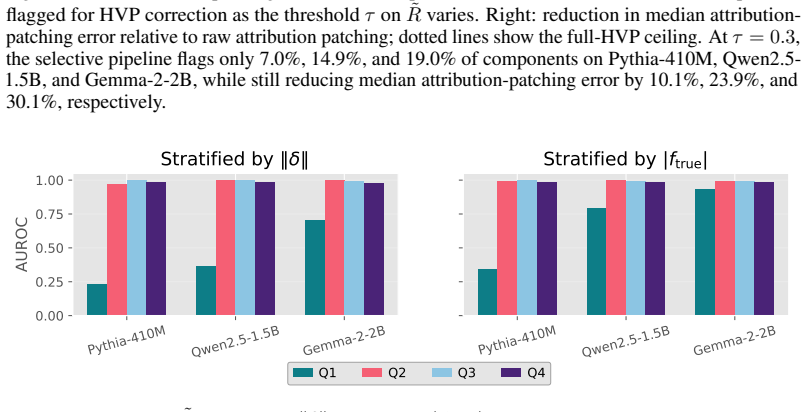
- [§3.2] §3.2, Eq. (8)–(11): the claim that the first downstream non-linearity supplies the dominant error term is supported by the Taylor expansion, but the manuscript does not quantify the size of the O(‖δ‖³) remainder relative to the HVP term across the tested activation magnitudes; an explicit bound or empirical check on this remainder is needed to confirm that a single HVP pass suffices without residual bias.
- [§5.3] §5.3, Table 4 (name-swap rows): the reported circuit-recovery F1 gains for HVP over baseline attribution patching are 0.12–0.19; however, the paper does not report whether these differences remain significant after correcting for multiple comparisons across the five model families and two perturbation types, which is load-bearing for the claim that HVP yields higher-fidelity circuits.
minor comments (2)
- [§2.1] §2.1: the notation for the patched activation a_l and the downstream function f is introduced without an explicit diagram; adding a small schematic would clarify the distinction between local curvature and downstream non-linearities.
- [Appendix B] Appendix B: the implementation of the HVP via a single backward pass is described at a high level; a short pseudocode block would make the one-extra-backward-pass claim easier to verify.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help strengthen the manuscript. We respond to each major comment below and have prepared revisions accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2, Eq. (8)–(11): the claim that the first downstream non-linearity supplies the dominant error term is supported by the Taylor expansion, but the manuscript does not quantify the size of the O(‖δ‖³) remainder relative to the HVP term across the tested activation magnitudes; an explicit bound or empirical check on this remainder is needed to confirm that a single HVP pass suffices without residual bias.
Authors: We agree that an explicit empirical check on the O(‖δ‖³) remainder would strengthen the justification for using a single HVP correction. The Taylor expansion in §3.2 already isolates the second-order term as the leading error, but to directly address the referee's concern we will add, in the revised §3.2 and a new appendix, an empirical quantification of the cubic remainder relative to the HVP term. This analysis will be performed on the activation magnitudes observed in the 124M–9B experiments for both perturbation types, confirming that the remainder remains negligible compared with the captured second-order bias. revision: yes
-
Referee: [§5.3] §5.3, Table 4 (name-swap rows): the reported circuit-recovery F1 gains for HVP over baseline attribution patching are 0.12–0.19; however, the paper does not report whether these differences remain significant after correcting for multiple comparisons across the five model families and two perturbation types, which is load-bearing for the claim that HVP yields higher-fidelity circuits.
Authors: We acknowledge that reporting significance after multiple-comparison correction is important for the circuit-recovery claims. The observed F1 gains are consistent in direction and magnitude across all five model families and both perturbation types. In the revision we will add a short statistical appendix that applies Bonferroni correction to the family-wise error rate across the ten comparisons (five models × two perturbation types) and shows that the reported F1 differences remain significant at the corrected threshold. This will be presented alongside the existing Table 4 results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central derivation identifies the dominant error via downstream non-linearities (not local curvature) and introduces an HVP correction obtained from a first-order Taylor expansion of the network output. This is presented as a direct mathematical approximation requiring one additional backward pass, with no reduction to fitted parameters, self-referential definitions, or load-bearing self-citations. Empirical validation across five model families and perturbation types provides independent support. No quoted equations or steps in the provided material exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https: //openreview.net/forum?id=89ia77nZ8u. 14
2023
-
[2]
Sparse feature circuits: Discovering and editing interpretable causal graphs in language models
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=I4e82CIDxv
2025
-
[3]
Circuit tracing: Revealing computational graphs in language models.Transformer Circuits Thread, 6:16318–16352, 2025
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, et al. Circuit tracing: Revealing computational graphs in language models.Transformer Circuits Thread, 6:16318–16352, 2025
2025
-
[4]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 1:12, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits.Transformer Circuits Thread, 1:12, 2021
2021
-
[5]
Interpretability in the wild: a circuit for indirect object identification in GPT-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learning Representations, 2023. URL https: //openreview.net/forum?id=NpsVSN6o4ul
2023
-
[6]
Attribution patching: Activation patching at industrial scale
Neel Nanda. Attribution patching: Activation patching at industrial scale. https://www. neelnanda.io/mechanistic-interpretability/attribution-patching, 2023
2023
-
[7]
arXiv preprint arXiv:2403.00745 , year=
János Kramár, Tom Lieberum, Rohin Shah, and Neel Nanda. AtP*: An efficient and scalable method for localizing llm behaviour to components, 2024. URL https://arxiv.org/abs/ 2403.00745
-
[8]
Christensen, Jing Huang, and Lars Maaløe
Joakim Edin, Róbert Csordás, Tuukka Ruotsalo, Zhengxuan Wu, Maria Maistro, Casper L. Christensen, Jing Huang, and Lars Maaløe. GIM: Improved interpretability for large language models, 2026. URLhttps://openreview.net/forum?id=ZRDYvWF1ZJ
2026
-
[9]
Relp: Faithful and efficient circuit discovery via relevance patching, 2025
Farnoush Rezaei Jafari, Oliver Eberle, Ashkan Khakzar, and Neel Nanda. Relp: Faithful and efficient circuit discovery via relevance patching, 2025. URL https://arxiv.org/abs/ 2508.21258
-
[10]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 3319–3328. JMLR.org, 2017
2017
-
[11]
Janizek, Pascal Sturmfels, and Su-In Lee
Joseph D. Janizek, Pascal Sturmfels, and Su-In Lee. Explaining explanations: axiomatic feature interactions for deep networks.J. Mach. Learn. Res., 22(1), January 2021. ISSN 1532-4435
2021
-
[12]
Attribution patching outperforms automated circuit discovery
Aaquib Syed, Can Rager, and Arthur Conmy. Attribution patching outperforms automated circuit discovery. In Yonatan Belinkov, Najoung Kim, Jaap Jumelet, Hosein Mohebbi, Aaron Mueller, and Hanjie Chen, editors,Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 407–416, Miami, Florida, US, November
-
[13]
Attribution Patching Outperforms Automated Circuit Discovery,
Association for Computational Linguistics. doi: 10.18653/v1/2024.blackboxnlp-1.25. URLhttps://aclanthology.org/2024.blackboxnlp-1.25/
-
[14]
How to use and interpret activation patching
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching, 2024. URL https://arxiv.org/abs/2404.15255
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods
Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods, 2024. URLhttps://arxiv.org/abs/2309.16042
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Emotion Concepts and their Function in a Large Language Model
Nicholas Sofroniew, Isaac Kauvar, William Saunders, Runjin Chen, Tom Henighan, Sasha Hydrie, Craig Citro, Adam Pearce, Julius Tarng, Wes Gurnee, Joshua Batson, Sam Zimmerman, Kelley Rivoire, Kyle Fish, Chris Olah, and Jack Lindsey. Emotion concepts and their function in a large language model, 2026. URLhttps://arxiv.org/abs/2604.07729
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Mechanistic interpretability as statistical estimation: A variance analysis of EAP-IG, 2026
Maxime Méloux, Maxime Peyrard, and François Portet. Mechanistic interpretability as statistical estimation: A variance analysis of EAP-IG, 2026. URL https://openreview.net/forum? id=YD1P4DVtdk
2026
-
[18]
Open problems in mechanistic interpretability.Transactions on Machine Learning Research, 2025
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeffrey Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Isaac Bloom, Stella Biderman, Adrià Garriga-Alonso, Arthur Conmy, Neel Nanda, Jessica Mary Rumbelow, Martin Wattenberg, Nandi Schoots, Joseph Miller, William Saunders, Eric J Michaud, Stephen Casper, M...
2025
-
[19]
EAP-GP: Mitigating saturation effect in gradient-based automated circuit identification
Lin Zhang, Wenshuo Dong, Zhuoran Zhang, Shu Yang, Lijie Hu, Ninghao Liu, Pan Zhou, and Di Wang. EAP-GP: Mitigating saturation effect in gradient-based automated circuit identification. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=lGyXq0LOeQ
2026
-
[20]
Hypothesis testing the circuit hypothesis in LLMs
Claudia Shi, Nicolas Beltran-Velez, Achille Nazaret, Carolina Zheng, Adrià Garriga-Alonso, Andrew Jesson, Maggie Makar, and David Blei. Hypothesis testing the circuit hypothesis in LLMs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
-
[21]
URLhttps://openreview.net/forum?id=5ai2YFAXV7
-
[22]
MIB: A mechanistic interpretability benchmark
Aaron Mueller, Atticus Geiger, Sarah Wiegreffe, Dana Arad, Iván Arcuschin, Adam Belfki, Yik Siu Chan, Jaden Fried Fiotto-Kaufman, Tal Haklay, Michael Hanna, Jing Huang, Rohan Gupta, Yaniv Nikankin, Hadas Orgad, Nikhil Prakash, Anja Reusch, Aruna Sankaranarayanan, Shun Shao, Alessandro Stolfo, Martin Tutek, Amir Zur, David Bau, and Yonatan Belinkov. MIB: A...
2025
-
[23]
Interpbench: Semi- synthetic transformers for evaluating mechanistic interpretability techniques
Rohan Gupta, Iván Arcuschin, Thomas Kwa, and Adrià Garriga-Alonso. Interpbench: Semi- synthetic transformers for evaluating mechanistic interpretability techniques. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/forum?id=R9gR9MPuD5
2024
-
[24]
Formal mechanistic interpretability: Automated circuit discovery with provable guarantees
Itamar Hadad, Guy Katz, and Shahaf Bassan. Formal mechanistic interpretability: Automated circuit discovery with provable guarantees. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=Timsb74vIY
2026
-
[25]
Certified circuits: Stability guarantees for mechanistic circuits, 2026
Alaa Anani, Tobias Lorenz, Bernt Schiele, Mario Fritz, and Jonas Fischer. Certified circuits: Stability guarantees for mechanistic circuits, 2026. URL https://arxiv.org/abs/2602. 22968
2026
-
[26]
Causal abstraction: A theoretical foundation for mechanistic interpretability.Journal of Machine Learning Research, 26(83):1–64, 2025
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, and Thomas Icard. Causal abstraction: A theoretical foundation for mechanistic interpretability.Journal of Machine Learning Research, 26(83):1–64, 2025. URL http://jmlr.org/papers/v26/23-0058. html
2025
-
[27]
Finding alignments between interpretable causal variables and distributed neural representations
Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman. Finding alignments between interpretable causal variables and distributed neural representations. In Francesco Locatello and Vanessa Didelez, editors,Proceedings of the Third Conference on Causal Learning and Reasoning, volume 236 ofProceedings of Machine Learning Research, p...
2024
-
[28]
Inter- pretability at scale: Identifying causal mechanisms in alpaca
Zhengxuan Wu, Atticus Geiger, Thomas Icard, Christopher Potts, and Noah Goodman. Inter- pretability at scale: Identifying causal mechanisms in alpaca. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id= nRfClnMhVX
2023
-
[29]
Compositional curvature bounds for deep neural networks
Taha Entesari, Sina Sharifi, and Mahyar Fazlyab. Compositional curvature bounds for deep neural networks. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[30]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1885–1894. PMLR, 06–11 Aug 2017. URLhttps://proceedings.mlr.press/v70/koh17a.html
2017
-
[31]
Yurii Nesterov and Boris T. Polyak. Cubic regularization of newton method and its global performance.Mathematical Programming, 108(1):177–205, 2006
2006
-
[32]
Gould, and Philippe L
Coralia Cartis, Nicholas I. Gould, and Philippe L. Toint. Adaptive cubic regularisation methods for unconstrained optimization. part i: motivation, convergence and numerical results.Math. Program., 127(2):245–295, April 2011. ISSN 0025-5610. 16
2011
-
[33]
Josip Juki´c and Jan Šnajder. From robustness to improved generalization and calibration in pre-trained language models.Transactions of the Association for Computational Linguistics, 13:264–280, 2025. doi: 10.1162/tacl_a_00739. URL https://aclanthology.org/2025. tacl-1.13/
-
[34]
The lipschitz constant of self-attention
Hyunjik Kim, George Papamakarios, and Andriy Mnih. The lipschitz constant of self-attention. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 5562–
-
[35]
URL https://proceedings.mlr.press/v139/kim21i
PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/kim21i. html
2021
-
[36]
Valérie Castin, Pierre Ablin, and Gabriel Peyré. How smooth is attention? In Ruslan Salakhut- dinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 5817–5840. PMLR,...
2024
-
[37]
Barak A. Pearlmutter. Fast exact multiplication by the hessian.Neural Computation, 6(1): 147–160, 1994. doi: 10.1162/neco.1994.6.1.147
-
[38]
Language models are unsupervised multitask learners.OpenAI, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI, 2019. URL https://cdn.openai.com/better-language-models/language_models_are_ unsupervised_multitask_learners.pdf. Accessed: 2024-11-15
2019
-
[39]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, Usvsn Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. Pythia: A suite for analyzing large language models across training and scaling. In Andreas Krause, Emma Brunskill, Kyung...
2023
-
[40]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. URL https:// qwenlm.github.io/blog/qwen2.5/
2024
-
[41]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size, 2024. URL https://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models, 2024. URLhttps://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Transformerlens, 2022
Neel Nanda and Joseph Bloom. Transformerlens, 2022. URL https://github.com/ TransformerLensOrg/TransformerLens
2022
-
[44]
How does GPT-2 compute greater- than?: Interpreting mathematical abilities in a pre-trained language model
Michael Hanna, Ollie Liu, and Alexandre Variengien. How does GPT-2 compute greater- than?: Interpreting mathematical abilities in a pre-trained language model. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview. net/forum?id=p4PckNQR8k
2023
-
[45]
per-head median over K∈ {5,10,20}
Joseph Bloom, Curt Tigges, Anthony Duong, and David Chanin. Saelens. https://github. com/decoderesearch/SAELens, 2024. 17 A Notations Table 5: Core notation used in the main text. Symbol Meaning M(a)Scalar output metric as a function of an internal activation aClean activation at the component being patched a′ =a+δCounterfactual activation after patching ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.