LongMoE: Longitudinal Multimodal Learning via Trajectory-Aware Mixture-of-Experts
Pith reviewed 2026-06-27 20:07 UTC · model grok-4.3
The pith
LongMoE routes multimodal clinical visits through context-conditioned experts to handle both missing data and disease progression over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
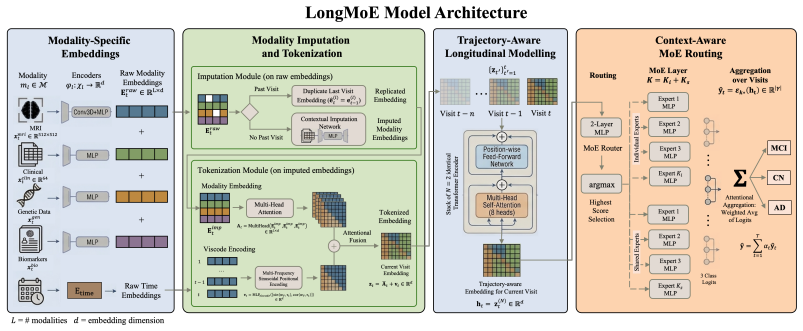
LongMoE jointly addresses modality missingness and longitudinal dynamics via context-aware imputation, attentional tokenization, trajectory-aware encoding, and context-conditioned Sparse MoE routing, improving robustness under missing or weak contemporaneous modalities while remaining competitive in full-modality settings.
What carries the argument
Context-conditioned Sparse MoE routing inside a trajectory-aware encoder that selects patient-specific experts based on the observed multimodal context at each visit.
If this is right
- Predictions remain stable even when imaging, text, or lab values are absent at some visits.
- Temporal frequency patterns captured by attentional tokenization improve modeling of irregular visit schedules.
- Patient-specific expert selection via context-conditioned routing adapts to individual disease trajectories.
- The same architecture works without retraining when all modalities become available.
- The approach supplies a unified starting point for other longitudinal multimodal clinical tasks.
Where Pith is reading between the lines
- The same routing logic could be tested on non-clinical longitudinal sequences such as wearable sensor streams with dropouts.
- If the frequency-domain tokenization proves decisive, simpler periodic imputation baselines might be revisited.
- Deployment would require checking whether the context-conditioned router generalizes to new hospitals with different missingness patterns.
- Extending the trajectory encoder to output uncertainty estimates could turn the model into a decision-support tool that flags when missing data reduces reliability.
Load-bearing premise
The four modules can be stacked without creating new biases or needing complete modality records during training.
What would settle it
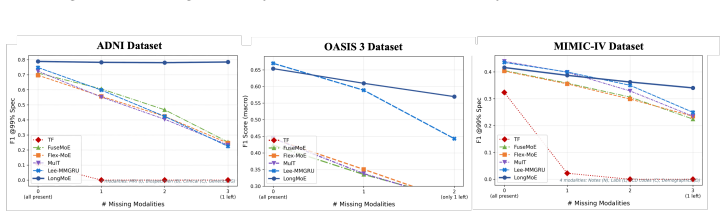
A controlled ablation on ADNI or MIMIC-IV in which modality dropout rates are increased visit-by-visit while measuring whether the combined model loses its reported robustness advantage over separate missing-modality and longitudinal baselines.
Figures
read the original abstract
Multimodal clinical learning is increasingly important for integrating diverse patient data, including imaging, text, and personalised health records. However, it faces two fundamental challenges: i) modality missingness, where arbitrary subsets of modalities are unavailable at a given patient visit, ii) longitudinal dynamics, where the diagnostic significance of an observation depends on the patient's evolving disease trajectory over time. Existing methods address these challenges in isolation: missing-modality frameworks treat each visit as an independent static snapshot and discard temporal context, while longitudinal models often assume complete modality availability and degrade under systematic modality incompleteness. We propose LongMoE (Longitudinal Mixture-of-Experts), the unified framework to jointly address both challenges. LongMoE combines a context-aware imputation module with an attentional tokenization module that captures frequency-domain temporal patterns across irregular visit sequences, a trajectory-aware encoder for modeling disease progression, and context-conditioned Sparse MoE routing for patient-specific expert selection. Experiments on ADNI, OASIS-3, and MIMIC-IV show that LongMoE improves robustness under missing or weak contemporaneous modalities and remains competitive in full-modality settings, establishing a strong foundation for longitudinally-aware multimodal clinical learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LongMoE, a unified framework for longitudinal multimodal clinical learning that jointly addresses modality missingness and longitudinal dynamics. It integrates a context-aware imputation module, an attentional tokenization module capturing frequency-domain temporal patterns across irregular visits, a trajectory-aware encoder for disease progression, and context-conditioned Sparse MoE routing for patient-specific expert selection. Experiments on ADNI, OASIS-3, and MIMIC-IV are claimed to show improved robustness under missing or weak modalities while remaining competitive in full-modality settings.
Significance. If the results hold and the modules can be trained without hidden reliance on complete-modality trajectories, the work would offer a meaningful unification of two previously isolated challenges in clinical multimodal learning, enabling more practical use of incomplete longitudinal patient data.
major comments (2)
- [Abstract / §3] Abstract and §3 (Method): The claim that context-aware imputation, attentional tokenization, trajectory-aware encoding, and context-conditioned Sparse MoE routing can be jointly trained and deployed without requiring complete-modality examples is unsupported by any mechanism details. It remains unclear how imputation outputs are fed into MoE routing or whether the routing loss or expert selection implicitly depends on at least one fully-observed visit per trajectory; this directly undermines the robustness claim under arbitrary missingness.
- [§4] §4 (Experiments): No description is given of how missingness patterns are simulated during training or testing, nor are ablation results or error bars reported for the individual modules or overall gains; without these, the quantitative improvements cannot be verified as load-bearing evidence for the central claim.
minor comments (1)
- [Abstract] Abstract: The phrase 'personalised health records' is used without specifying the exact set of modalities (imaging, text, EHR fields) employed in the three datasets.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Method): The claim that context-aware imputation, attentional tokenization, trajectory-aware encoding, and context-conditioned Sparse MoE routing can be jointly trained and deployed without requiring complete-modality examples is unsupported by any mechanism details. It remains unclear how imputation outputs are fed into MoE routing or whether the routing loss or expert selection implicitly depends on at least one fully-observed visit per trajectory; this directly undermines the robustness claim under arbitrary missingness.
Authors: We acknowledge that the integration flow between modules could be described more explicitly. The method section outlines context-aware imputation operating on longitudinal context from available modalities, with outputs tokenized and routed via context-conditioned MoE that depends only on observed/imputed features. To strengthen this, we will revise §3 with a detailed forward-pass description, pseudocode, and diagram confirming no requirement for complete-modality visits during training or inference. revision: yes
-
Referee: [§4] §4 (Experiments): No description is given of how missingness patterns are simulated during training or testing, nor are ablation results or error bars reported for the individual modules or overall gains; without these, the quantitative improvements cannot be verified as load-bearing evidence for the central claim.
Authors: We agree that these experimental details are insufficient in the current version. The revised manuscript will expand §4 to specify the missingness simulation procedure (random modality dropout per visit), include ablations for each proposed module, and report error bars (mean ± std over multiple seeds) for all metrics. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
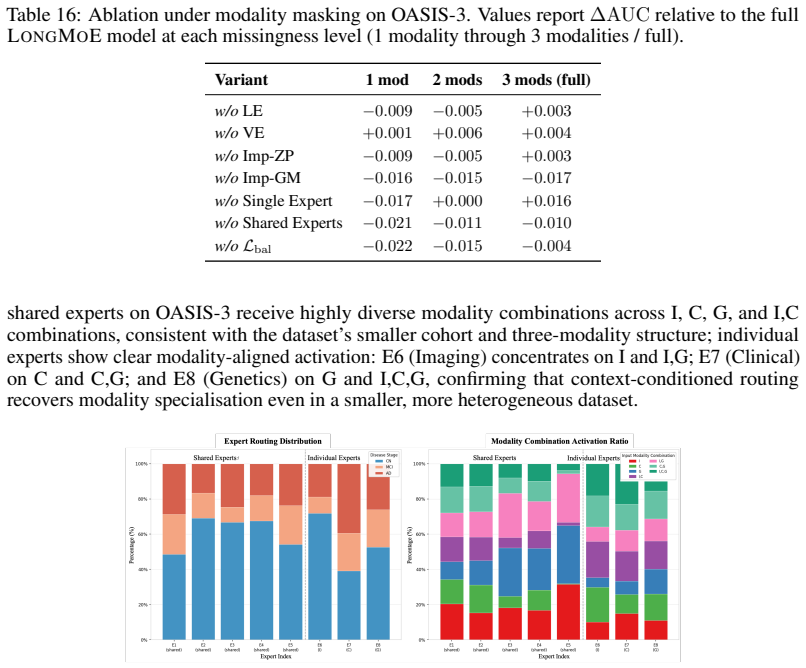
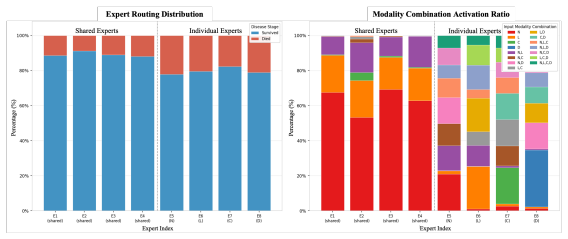
The provided abstract and description present LongMoE as a proposed architecture combining four modules (context-aware imputation, attentional tokenization, trajectory-aware encoder, context-conditioned Sparse MoE routing) evaluated empirically on ADNI, OASIS-3, and MIMIC-IV. No equations, parameter-fitting procedures, self-citations, or uniqueness theorems are referenced that would reduce any claimed prediction or result to its inputs by construction. The central claims rest on empirical robustness rather than a closed mathematical derivation, so the work is self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal machine learning: A survey and taxonomy,
T. Baltrušaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 2, pp. 423–443, 2018
2018
-
[2]
MultiBench: Multiscale benchmarks for multimodal representation learning,
P. P. Liang, Y . Lyu, X. Fan, Z. Wu, Y . Cheng, J. Wu, L. Chen, P. Wu, M. A. Lee, Y . Zhu, R. Salakhutdinov, and L. Morency, “MultiBench: Multiscale benchmarks for multimodal representation learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 5813–5826, 2021
2021
-
[3]
Multi-task learning in heterogeneous feature spaces,
Y . Zhang and D.-Y . Yeung, “Multi-task learning in heterogeneous feature spaces,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 25, pp. 574–579, 2011
2011
-
[4]
Biomarker modeling of Alzheimer’s disease,
C. R. Jack and D. M. Holtzman, “Biomarker modeling of Alzheimer’s disease,”Neuron, vol. 80, no. 6, pp. 1347–1358, 2013
2013
-
[5]
Neuroimaging biomarkers for Alzheimer’s disease,
F. Márquez and M. A. Yassa, “Neuroimaging biomarkers for Alzheimer’s disease,”Molecular Neurodegeneration, vol. 14, no. 1, p. 21, 2019
2019
-
[6]
Genet- ics, transcriptomics, and proteomics of Alzheimer’s disease,
A. Papassotiropoulos, M. Fountoulakis, T. Dunckley, D. A. Stephan, and E. M. Reiman, “Genet- ics, transcriptomics, and proteomics of Alzheimer’s disease,”Journal of Clinical Psychiatry, vol. 67, no. 4, p. 652, 2006
2006
-
[7]
Flex-MoE: Modeling arbitrary modality combination via the flexible mixture-of-experts,
S. Yun, I. Choi, J. Peng, Y . Wu, J. Bao, Q. Zhang, J. Xin, Q. Long, and T. Chen, “Flex-MoE: Modeling arbitrary modality combination via the flexible mixture-of-experts,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[8]
FuseMoE: Mixture-of-experts transformers for fleximodal fusion,
X. Han, H. Nguyen, C. Harris, N. Ho, and S. Saria, “FuseMoE: Mixture-of-experts transformers for fleximodal fusion,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[9]
Y . Zhang, N. He, J. Yang, Y . Li, D. Wei, Y . Huang, Y . Zhang, Z. He, and Y . Zheng, “mm- Former: Multimodal medical transformer for incomplete multimodal learning of brain tumor segmentation,”arXiv preprint arXiv:2206.02425, 2022
-
[10]
Multi-modal learning with missing modality via shared-specific feature modelling,
H. Wang, Y . Chen, C. Ma, J. Avery, L. Hull, and G. Carneiro, “Multi-modal learning with missing modality via shared-specific feature modelling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 10
2024
-
[11]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inInternational Conference on Learning Representations (ICLR), 2017
2017
-
[12]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[13]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chap- lot, D. de las Casas, E. B. Hanna, F. Bressand, et al., “Mixtral of experts,”arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Multimodal contrastive learning with LiMoE: The language-image mixture of experts,
B. Mustafa, C. Riquelme, J. Puigcerver, R. Jenatton, and N. Houlsby, “Multimodal contrastive learning with LiMoE: The language-image mixture of experts,” inAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2022
2022
-
[15]
Sparse MoE as a new treatment: Addressing forgetting, fitting, and learning issues in multi-modal multi-task learning,
J. Peng, K. Zhou, R. Zhou, T. Hartvigsen, Y . Zhang, Z. Wang, and T. Chen, “Sparse MoE as a new treatment: Addressing forgetting, fitting, and learning issues in multi-modal multi-task learning,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[16]
Tensor fusion network for multimodal sentiment analysis,
A. Zadeh, M. Chen, S. Poria, E. Cambria, and L.-P. Morency, “Tensor fusion network for multimodal sentiment analysis,” inProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1103–1114, 2017
2017
-
[17]
Multimodal transformer for unaligned multimodal language sequences,
Y .-H. H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L.-P. Morency, and R. Salakhutdinov, “Multimodal transformer for unaligned multimodal language sequences,” inProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pp. 6558–6569, 2019
2019
-
[18]
Integrating multimodal information in large pretrained transformers,
W. Rahman, M. K. Hasan, S. Lee, A. B. Zadeh, C. Mao, L.-P. Morency, and E. Hoque, “Integrating multimodal information in large pretrained transformers,” inProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pp. 2359–2369, 2020
2020
-
[19]
Predicting Alzheimer’s disease progression using multi-modal deep learning approach,
G. Lee, K. Nho, B. Kang, K.-A. Sohn, and D. Kim, “Predicting Alzheimer’s disease progression using multi-modal deep learning approach,”Scientific Reports, vol. 9, no. 1, p. 1952, 2019
1952
-
[20]
Multimodal deep learning models for early detection of Alzheimer’s disease stage,
J. Venugopalan, L. Tong, H. R. Hassanzadeh, and M. D. Wang, “Multimodal deep learning models for early detection of Alzheimer’s disease stage,”Scientific Reports, vol. 11, no. 1, p. 3254, 2021
2021
-
[21]
Machine learning with multi- modal neuroimaging data to classify stages of Alzheimer’s disease: A systematic review and meta-analysis,
M. Odusami, R. Maskeliunas, R. Damasevicius, and S. Misra, “Machine learning with multi- modal neuroimaging data to classify stages of Alzheimer’s disease: A systematic review and meta-analysis,”Cognitive Neurodynamics, pp. 1–20, 2023
2023
-
[22]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, pp. 5998–6008, 2017
2017
-
[23]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 4171–4186, 2019
2019
-
[24]
The Alzheimer’s Disease Neuroimaging Initiative: Progress report and future plans,
M. W. Weiner, P. S. Aisen, C. R. Jack, W. J. Jagust, J. Q. Trojanowski, L. Shaw, A. J. Saykin, J. C. Morris, N. Cairns, L. A. Beckett, et al., “The Alzheimer’s Disease Neuroimaging Initiative: Progress report and future plans,”Alzheimer’s & Dementia, vol. 6, no. 3, pp. 202–211, 2010
2010
-
[25]
OASIS-3: Longitudinal neuroimaging, clinical, and cognitive dataset for normal aging and Alzheimer’s disease,
P. J. LaMontagne, T. L. Benzinger, J. C. Morris, S. Keefe, R. Hornbeck, C. Yao, A. Hintaus, and D. Marcus, “OASIS-3: Longitudinal neuroimaging, clinical, and cognitive dataset for normal aging and Alzheimer’s disease,”medRxiv, 2019
2019
-
[26]
A., and Mark, R
Johnson, A., Bulgarelli, L., Pollard, T., Horng, S., Celi, L. A., and Mark, R. (2023). MIMIC-IV , a freely accessible electronic health record dataset.Scientific Data,10(1), 1–9. Nature Publishing Group. 11
2023
-
[27]
MUSE: Multi-atlas region segmentation utilizing ensem- bles of registration algorithms and parameters, and locally optimal atlas selection,
J. Doshi, G. Erus, Y . Ou, S. M. Resnick, R. C. Gur, R. E. Gur, T. D. Satterthwaite, S. Furth, C. Davatzikos, and A. D. N. Initiative, “MUSE: Multi-atlas region segmentation utilizing ensem- bles of registration algorithms and parameters, and locally optimal atlas selection,”NeuroImage, vol. 127, pp. 186–195, 2016
2016
-
[28]
DRAMMS: Deformable registration via attribute matching and mutual-saliency weighting,
Y . Ou, A. Sotiras, N. Paragios, and C. Davatzikos, “DRAMMS: Deformable registration via attribute matching and mutual-saliency weighting,”Medical Image Analysis, vol. 15, no. 4, pp. 622–639, 2011
2011
-
[29]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Confer- ence on Learning Representations (ICLR), 2019
2019
-
[30]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al., “PyTorch: An imperative style, high-performance deep learning library,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 32, pp. 8024–8035, 2019
2019
-
[31]
R. J. A. Little and D. B. Rubin,Statistical Analysis with Missing Data, 3rd ed. John Wiley & Sons, 2019
2019
-
[32]
Scaling vision with sparse mixture of experts,
C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. S. Pinto, D. Keysers, and N. Houlsby, “Scaling vision with sparse mixture of experts,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 8583–8595, 2021
2021
-
[33]
Modeling task relationships in multi-task learning with multi-gate mixture-of-experts,
J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi, “Modeling task relationships in multi-task learning with multi-gate mixture-of-experts,” inProceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pp. 1930–1939, 2018
1930
-
[34]
Mod-Squad: Designing mixtures of experts as modular multi-task learners,
Z. Chen, Y . Shen, M. Ding, Z. Chen, H. Zhao, E. G. Learned-Miller, and C. Gan, “Mod-Squad: Designing mixtures of experts as modular multi-task learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11828–11837, 2023
2023
-
[35]
Mixture-of-experts with expert choice routing,
Y . Zhou, T. Lei, H. Liu, N. Du, Y . Huang, V . Zhao, A. Dai, Z. Chen, Q. Le, and J. Laudon, “Mixture-of-experts with expert choice routing,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[36]
DSelect-k: Differentiable selection in the mixture of experts with applications to multi-task learning,
H. Hazimeh, Z. Zhao, A. Chowdhery, M. Sathiamoorthy, Y . Chen, R. Mazumder, L. Hong, and E. H. Chi, “DSelect-k: Differentiable selection in the mixture of experts with applications to multi-task learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 29335–29347, 2021
2021
-
[37]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[38]
Learning phrase representations using RNN encoder–decoder for statistical machine translation,
K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using RNN encoder–decoder for statistical machine translation,” inProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1724–1734, 2014
2014
-
[39]
RETAIN: An inter- pretable predictive model for healthcare using reverse time attention mechanism,
E. Choi, M. T. Bahadori, J. Sun, J. Kulas, A. Schuetz, and W. Stewart, “RETAIN: An inter- pretable predictive model for healthcare using reverse time attention mechanism,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 29, pp. 3504–3512, 2016
2016
-
[40]
Set functions for time series,
M. Horn, M. Moor, C. Bock, B. Rieck, and K. Borgwardt, “Set functions for time series,” in Proceedings of the International Conference on Machine Learning (ICML), vol. 119, pp. 4353– 4363, 2020
2020
-
[41]
Multi-time attention networks for irregularly sampled time series,
N. Shukla and B. Marlin, “Multi-time attention networks for irregularly sampled time series,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[42]
Hierarchical mixtures of experts and the EM algorithm,
M. I. Jordan and R. A. Jacobs, “Hierarchical mixtures of experts and the EM algorithm,”Neural Computation, vol. 6, no. 2, pp. 181–214, 1994. 12
1994
-
[43]
A., Jordan, M
Jacobs, R. A., Jordan, M. I., Nowlan, S. J., and Hinton, G. E. Adaptive mixtures of local experts. Neural Computation, 3(1):79–87, 1991
1991
-
[44]
TimesNet: Temporal 2D-variation modeling for general time series analysis
Wu, H., Hu, T., Liu, Y ., Zhou, H., Wang, J., and Long, M. TimesNet: Temporal 2D-variation modeling for general time series analysis. InProceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[45]
FEDformer: Frequency enhanced de- composed transformer for long-term series forecasting
Zhou, T., Ma, Z., Wen, Q., Wang, X., Sun, L., and Jin, R. FEDformer: Frequency enhanced de- composed transformer for long-term series forecasting. InProceedings of the 39th International Conference on Machine Learning (ICML), pp. 27268–27286, 2022
2022
-
[46]
Supervised multimodal bitransformers for classifying images and text,
D. Kiela, C. Bhooshan, H. Firooz, E. Perez, and D. Testuggine, “Supervised multimodal bitransformers for classifying images and text,”arXiv preprint arXiv:1909.02950, 2019
-
[47]
Reformer: The efficient transformer,
N. Kitaev, L. Kaiser, and A. Levskaya, “Reformer: The efficient transformer,” inInternational Conference on Learning Representations (ICLR), 2020
2020
-
[48]
T. M. Cover and J. A. Thomas,Elements of Information Theory, 2nd ed. John Wiley & Sons, 2006
2006
-
[49]
Multilayer feedforward networks are universal approximators,
K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward networks are universal approximators,”Neural Networks, vol. 2, no. 5, pp. 359–366, 1989
1989
-
[50]
Optimization methods for large-scale machine learning,
L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large-scale machine learning,” SIAM Review, vol. 60, no. 2, pp. 223–311, 2018
2018
-
[51]
Are transformers universal approximators of sequence-to-sequence functions?
C. Yun, S. Bhojanapalli, A. S. Rawat, S. J. Reddi, and S. Kumar, “Are transformers universal approximators of sequence-to-sequence functions?” inInternational Conference on Learning Representations (ICLR), 2020. 13 A Technical appendices and supplementary material We provide theoretical grounding for the four core architectural components of LONGMOE: the ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.