When RL Fails after SFT: Rejuvenating Model Plasticity for Robust SFT-to-RL Handoff
Pith reviewed 2026-06-27 18:48 UTC · model grok-4.3
The pith
Excessive SFT creates over-confident token distributions and sharp parameter landscapes that hinder RL optimization, but Rejuvenation restores plasticity through base-anchored fusion and neuron reset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
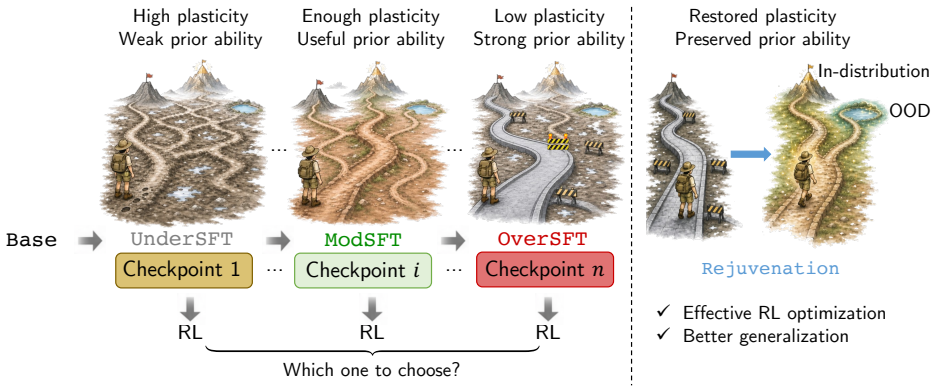
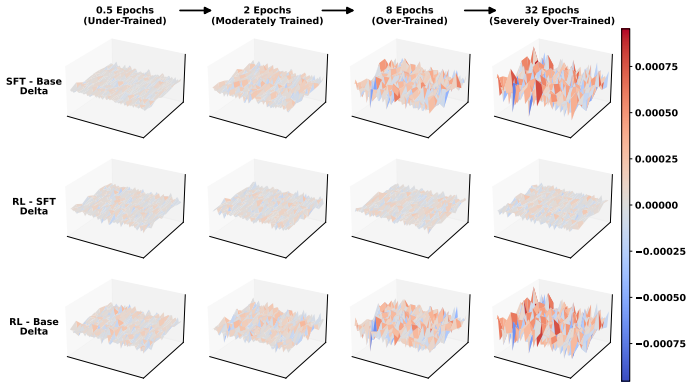
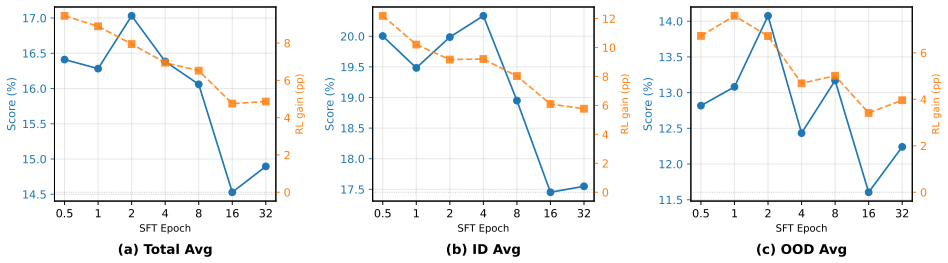
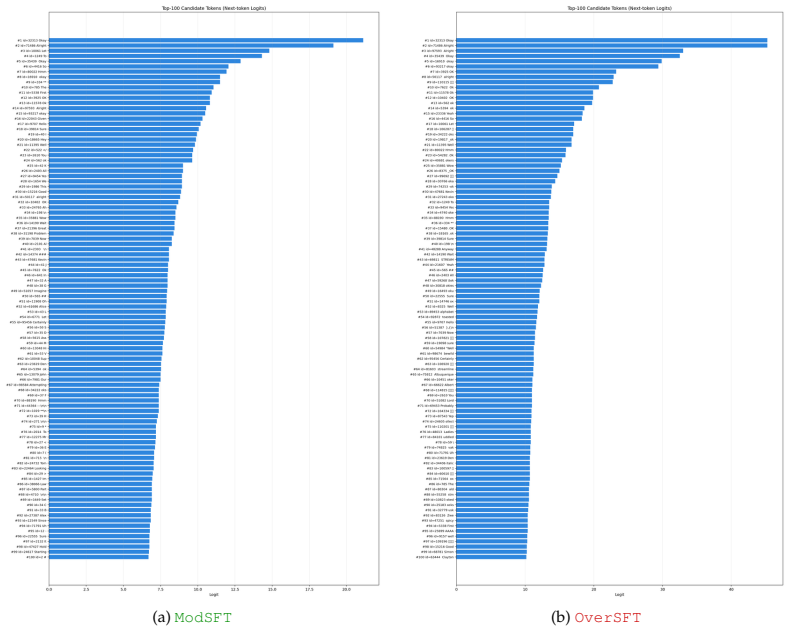
Models from excessive SFT lose plasticity, shown by over-confident token distributions and sharp parameter landscapes that resist effective reshaping during RL. Rejuvenation counters this with base-anchored model fusion to limit SFT-induced drift together with targeted neuron reset to reduce rigidity, thereby restoring adaptability without discarding SFT-acquired priors.
What carries the argument
Rejuvenation, which applies base-anchored model fusion to curb SFT drift and targeted neuron reset to ease model rigidity.
If this is right
- Rejuvenation raises final RL performance on math reasoning tasks.
- Rejuvenation raises final RL performance on agentic tasks.
- Rejuvenation improves generalization to out-of-distribution tasks.
- The method preserves SFT priors while reducing optimization difficulty in the RL stage.
Where Pith is reading between the lines
- Training pipelines may need explicit controls on SFT duration or strength to leave sufficient plasticity for later RL.
- The same fusion-and-reset pattern could be tested on other sequential training regimes such as continued pretraining followed by fine-tuning.
- Measuring landscape sharpness or distribution entropy before RL could serve as a practical diagnostic for deciding when to apply rejuvenation.
Load-bearing premise
The limited RL improvement after excessive SFT is caused mainly by loss of plasticity rather than reward model quality, optimization choices, or data mismatch.
What would settle it
Apply Rejuvenation to an over-SFT model and observe no reduction in parameter landscape sharpness or no increase in RL reward improvement.
Figures


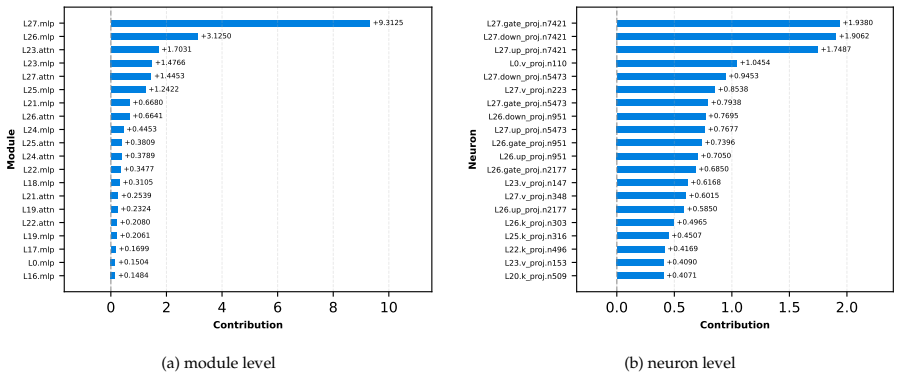

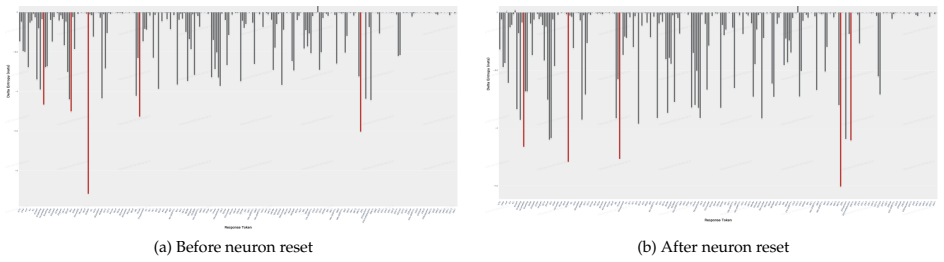
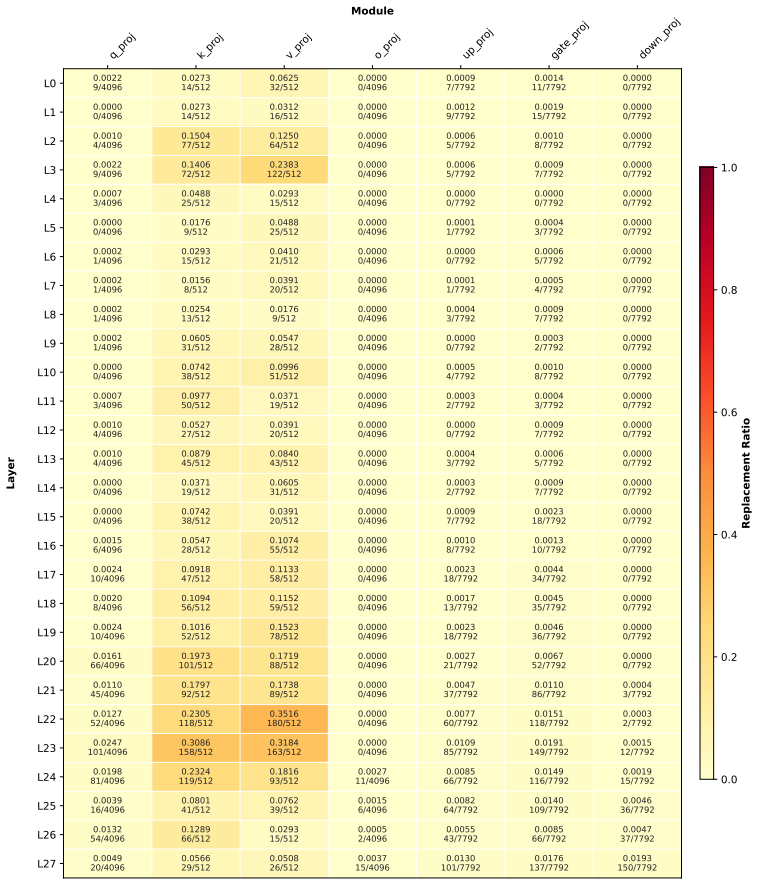
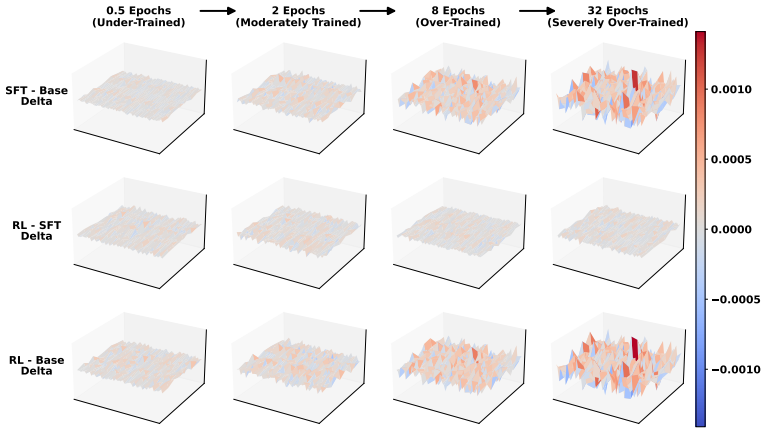
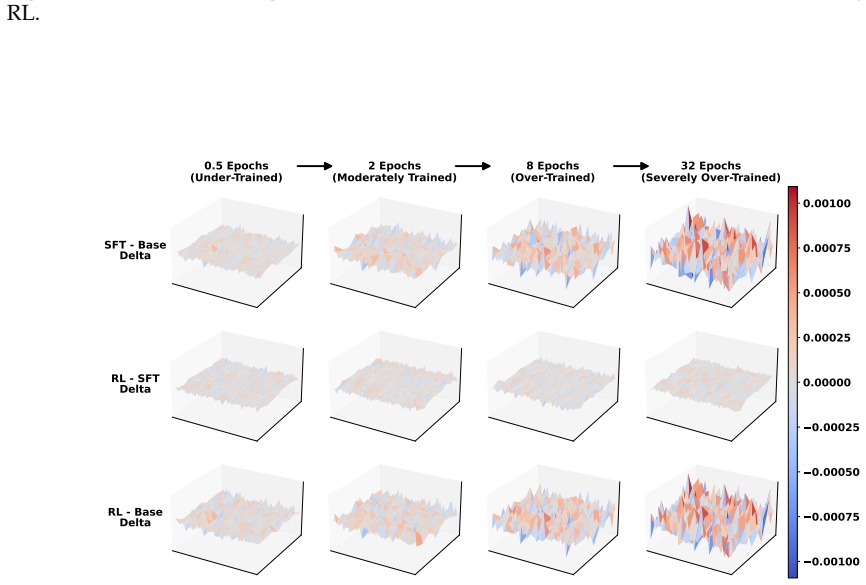
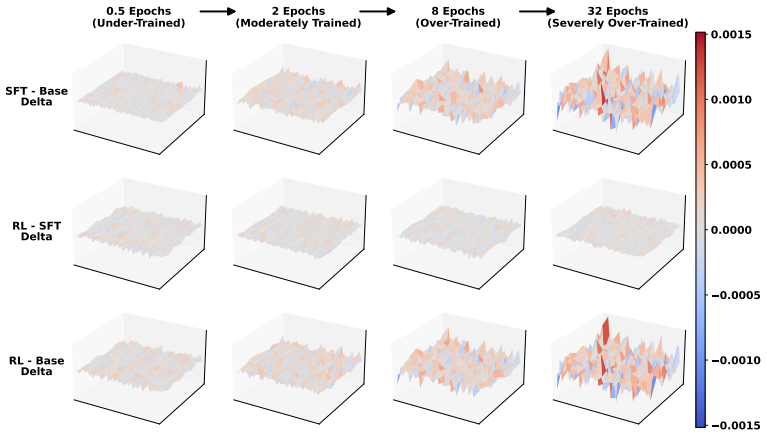
read the original abstract
Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has become a standard pipeline for Large Language Model (LLM) post-training. SFT is expected to provide a useful behavioral prior for RL to further enhance model capabilities. However, checkpoints with excessive SFT often show limited improvement during RL. We attribute this failure to the loss of model plasticity: the reduced ability of an SFT-initialized policy to be effectively reshaped by subsequent RL. To better understand this phenomenon, we conduct detailed analysis from multiple perspectives, including parameter changes, output spaces, and RL optimization dynamics. Our results show that models from excessive SFT tend to produce over-confident token distributions and exhibit sharp parameter landscapes, which make them harder to optimize in the RL stage. To enable a more robust SFT-to-RL handoff, we propose \texttt{Rejuvenation}, a simple yet effective method that restores plasticity while preserving useful SFT-acquired priors. Rejuvenation leverages base-anchored model fusion to reduce excessive SFT-induced drift with targeted neuron reset to mitigate model rigidity. Experimental results on both math reasoning tasks and agentic tasks demonstrate that our approach consistently improves RL performance on over-trained SFT models, while also enhancing generalization to out-of-distribution tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that excessive SFT produces over-confident token distributions and sharp parameter landscapes that reduce model plasticity and limit gains during subsequent RL. The authors support this via analysis of parameter changes, output spaces, and RL optimization dynamics, then introduce Rejuvenation (base-anchored model fusion plus targeted neuron reset) to restore plasticity while retaining SFT priors. Experiments on math reasoning and agentic tasks report consistent RL improvements and better OOD generalization for over-trained SFT checkpoints.
Significance. If the plasticity-loss attribution is isolated from confounds and the empirical gains hold under controlled conditions, the work would be significant for LLM post-training pipelines by providing a practical intervention for SFT-to-RL transitions. The multi-perspective analysis and task diversity are positive features; reproducible code or parameter-free derivations are not mentioned.
major comments (2)
- [Abstract] Abstract: the central claim attributes limited RL improvement after excessive SFT specifically to loss of plasticity (over-confident distributions and sharp landscapes) rather than confounds such as reward-model quality, KL coefficient, or data mismatch. No explicit controls are described that hold the reward model, optimization hyperparameters, and data fixed while varying only SFT duration or plasticity metrics; without such isolation the observed Rejuvenation gains could arise from incidental regularization rather than restored plasticity.
- [Abstract] Abstract (experimental results paragraph): the claim of 'consistent' RL performance improvements and enhanced OOD generalization is stated without reference to error bars, ablation details, dataset sizes, or statistical significance tests. These omissions are load-bearing because they prevent verification that the gains are robustly attributable to the proposed plasticity restoration rather than other factors.
minor comments (1)
- The method description ('base-anchored model fusion' and 'targeted neuron reset') is high-level; adding precise definitions, hyperparameters, or pseudocode would improve clarity without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on isolating the plasticity effect and strengthening experimental reporting. We address each major comment below and will revise the manuscript to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim attributes limited RL improvement after excessive SFT specifically to loss of plasticity (over-confident distributions and sharp landscapes) rather than confounds such as reward-model quality, KL coefficient, or data mismatch. No explicit controls are described that hold the reward model, optimization hyperparameters, and data fixed while varying only SFT duration or plasticity metrics; without such isolation the observed Rejuvenation gains could arise from incidental regularization rather than restored plasticity.
Authors: We agree that explicit isolation of SFT duration is necessary to support the plasticity attribution. In the full experimental setup, the reward model, KL coefficient, optimization hyperparameters, and training data were held fixed while varying only the number of SFT steps across checkpoints; the same base model and RL procedure were used for all comparisons. However, this controlled design was not stated explicitly in the abstract. We will revise the abstract and add a dedicated paragraph in Section 3 (or an appendix) describing the fixed components and the SFT-duration sweep to make the isolation clear. revision: yes
-
Referee: [Abstract] Abstract (experimental results paragraph): the claim of 'consistent' RL performance improvements and enhanced OOD generalization is stated without reference to error bars, ablation details, dataset sizes, or statistical significance tests. These omissions are load-bearing because they prevent verification that the gains are robustly attributable to the proposed plasticity restoration rather than other factors.
Authors: We acknowledge that the abstract lacks these details. The full manuscript reports results over multiple random seeds with standard deviations, includes ablation studies on the fusion and reset components, specifies dataset sizes, and uses statistical tests for key comparisons. We will expand the abstract's results paragraph to reference error bars, note the ablation scope, and mention significance testing. We will also ensure these elements are highlighted in the main results section for easier verification. revision: yes
Circularity Check
No significant circularity: empirical attribution and intervention with no derivations or self-referential predictions
full rationale
The paper conducts empirical analysis of SFT-to-RL handoff, attributes limited RL gains after excessive SFT to loss of plasticity (over-confident distributions and sharp landscapes), and proposes the Rejuvenation method (base-anchored fusion plus neuron reset) with experimental validation on math and agentic tasks. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The central claim is an observational attribution supported by analysis of parameter changes, output spaces, and optimization dynamics rather than any quantity that reduces to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing elements. The method is presented as an empirical intervention, not a closed-form result equivalent to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature , volume =
Loss of plasticity in deep continual learning , author =. Nature , volume =. 2024 , publisher =
2024
-
[2]
arXiv preprint arXiv:2602.11137 , year=
Weight Decay Improves Language Model Plasticity , author=. arXiv preprint arXiv:2602.11137 , year=
-
[3]
arXiv preprint arXiv:2604.14164 , year=
How to Fine-Tune a Reasoning Model? A Teacher-Student Cooperation Framework to Synthesize Student-Consistent SFT Data , author=. arXiv preprint arXiv:2604.14164 , year=
-
[4]
Proceedings of the 39th International Conference on Machine Learning , pages =
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[5]
The Eleventh International Conference on Learning Representations , year=
Editing models with task arithmetic , author=. The Eleventh International Conference on Learning Representations , year=
-
[6]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[7]
International Conference on Learning Representations , year=
Pruning Convolutional Neural Networks for Resource Efficient Inference , author=. International Conference on Learning Representations , year=
-
[8]
Are Sixteen Heads Really Better than One? , url =
Michel, Paul and Levy, Omer and Neubig, Graham , booktitle =. Are Sixteen Heads Really Better than One? , url =
-
[9]
Knowledge Neurons in Pretrained Transformers
Dai, Damai and Dong, Li and Hao, Yaru and Sui, Zhifang and Chang, Baobao and Wei, Furu. Knowledge Neurons in Pretrained Transformers. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.581
-
[10]
An Adversarial Example for Direct Logit Attribution: Memory Management in GELU -4 L
Janiak, Jett and Rager, Can and Dao, James and Lau, Yeu-Tong. An Adversarial Example for Direct Logit Attribution: Memory Management in GELU -4 L. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2024. doi:10.18653/v1/2024.blackboxnlp-1.15
-
[11]
2025 , editor =
Chu, Tianzhe and Zhai, Yuexiang and Yang, Jihan and Tong, Shengbang and Xie, Saining and Schuurmans, Dale and Le, Quoc V and Levine, Sergey and Ma, Yi , booktitle =. 2025 , editor =
2025
-
[12]
reinforcement learning fine-tuning for llms , author =
Rl is neither a panacea nor a mirage: Understanding supervised vs. reinforcement learning fine-tuning for llms , author =. arXiv preprint arXiv:2508.16546 , year =
-
[13]
arXiv preprint arXiv:2509.12235 , year =
Rl fine-tuning heals ood forgetting in sft , author =. arXiv preprint arXiv:2509.12235 , year =
-
[14]
Quagmires in
Feiyang Kang and Michael Kuchnik and Karthik Padthe and Marin Vlastelica and Ruoxi Jia and Carole-Jean Wu and Newsha Ardalani , booktitle =. Quagmires in. 2026 , url =
2026
-
[15]
arXiv preprint arXiv:2602.01058 , year =
Good SFT Optimizes for SFT, Better SFT Prepares for Reinforcement Learning , author =. arXiv preprint arXiv:2602.01058 , year =
-
[16]
arXiv preprint arXiv:2602.14012 , year =
From SFT to RL: Demystifying the Post-Training Pipeline for LLM-based Vulnerability Detection , author =. arXiv preprint arXiv:2602.14012 , year =
-
[17]
The Thirteenth International Conference on Learning Representations , year =
Preserving Diversity in Supervised Fine-Tuning of Large Language Models , author =. The Thirteenth International Conference on Learning Representations , year =
-
[18]
arXiv preprint arXiv:2507.12856 , year =
Supervised fine tuning on curated data is reinforcement learning (and can be improved) , author =. arXiv preprint arXiv:2507.12856 , year =
-
[19]
On the Generalization of
Yongliang Wu and Yizhou Zhou and Zhou Ziheng and Yingzhe Peng and Xinyu Ye and Xinting Hu and Wenbo Zhu and Lu Qi and Ming-Hsuan Yang and Xu Yang , booktitle =. On the Generalization of. 2026 , url =
2026
-
[20]
The Fourteenth International Conference on Learning Representations , year =
Anchored Supervised Fine-Tuning , author =. The Fourteenth International Conference on Learning Representations , year =
-
[21]
Getting Your
Xinran Li and Guangda Huzhang and Siqi Shen and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Jun Zhang , booktitle =. Getting Your. 2026 , url =
2026
-
[22]
arXiv preprint arXiv:2602.02244 , year =
Learning While Staying Curious: Entropy-Preserving Supervised Fine-Tuning via Adaptive Self-Distillation for Large Reasoning Models , author =. arXiv preprint arXiv:2602.02244 , year =
-
[23]
arXiv preprint arXiv:2601.09195 , year =
ProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection , author =. arXiv preprint arXiv:2601.09195 , year =
-
[24]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
Learning to Reason under Off-Policy Guidance , author =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[25]
arXiv preprint arXiv:2505.13026 , year =
Step-wise adaptive integration of supervised fine-tuning and reinforcement learning for task-specific llms , author =. arXiv preprint arXiv:2505.13026 , year =
-
[26]
Ozdaglar , booktitle =
Mingyang Liu and Gabriele Farina and Asuman E. Ozdaglar , booktitle =. 2025 , url =
2025
-
[27]
arXiv preprint arXiv:2506.01096 , year =
SuperRL: Reinforcement Learning with Supervision to Boost Language Model Reasoning , author =. arXiv preprint arXiv:2506.01096 , year =
-
[28]
The Fourteenth International Conference on Learning Representations , year =
Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions , author =. The Fourteenth International Conference on Learning Representations , year =
-
[29]
2026 , url =
Yuqian Fu and Tinghong Chen and Jiajun Chai and Xihuai Wang and Songjun Tu and Guojun Yin and Wei Lin and Qichao Zhang and Yuanheng Zhu and Dongbin Zhao , booktitle =. 2026 , url =
2026
-
[30]
arXiv preprint arXiv:2507.01679 , year =
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling , author =. arXiv preprint arXiv:2507.01679 , year =
-
[31]
arXiv preprint arXiv:2508.00222 , year =
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization , author =. arXiv preprint arXiv:2508.00222 , year =
-
[32]
On-Policy
Wenhao Zhang and Yuexiang Xie and Yuchang Sun and Yanxi Chen and Guoyin Wang and Yaliang Li and Bolin Ding and Jingren Zhou , booktitle =. On-Policy. 2026 , url =
2026
-
[33]
The Fourteenth International Conference on Learning Representations , year =
Proximal Supervised Fine-Tuning , author =. The Fourteenth International Conference on Learning Representations , year =
-
[34]
arXiv preprint arXiv:2509.04419 , year =
Towards a unified view of large language model post-training , author =. arXiv preprint arXiv:2509.04419 , year =
-
[35]
arXiv preprint arXiv:2604.14258 , year=
GFT: From Imitation to Reward Fine-Tuning with Unbiased Group Advantages and Dynamic Coefficient Rectification , author=. arXiv preprint arXiv:2604.14258 , year=
-
[36]
arXiv preprint arXiv:2604.23747 , year =
SFT-then-RL Outperforms Mixed-Policy Methods for LLM Reasoning , author =. arXiv preprint arXiv:2604.23747 , year =
-
[37]
Xing and Sham M
Zhenting Qi and Fan Nie and Alexandre Alahi and James Zou and Himabindu Lakkaraju and Yilun Du and Eric P. Xing and Sham M. Kakade and Hanlin Zhang , booktitle =. Evo. 2025 , url =
2025
-
[38]
arXiv preprint arXiv:2512.07783 , year =
On the interplay of pre-training, mid-training, and rl on reasoning language models , author =. arXiv preprint arXiv:2512.07783 , year =
-
[39]
arXiv preprint arXiv:1707.06347 , year =
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
-
[40]
AAAI Conference on Artificial Intelligence (AAAI) , author =
Mastering Complex Control in MOBA Games with Deep Reinforcement Learning , volume =. AAAI Conference on Artificial Intelligence (AAAI) , author =. 2020 , month =. doi:10.1609/aaai.v34i04.6144 , number =
-
[41]
Reinforcement learning: An introduction , author =
-
[42]
The Bitter Lesson , author =
-
[43]
Advances in neural information processing systems (NeurIPS) , volume =
Direct preference optimization: Your language model is secretly a reward model , author =. Advances in neural information processing systems (NeurIPS) , volume =
-
[44]
Conference on Language Modeling (COLM) , year =
From r to Q star: Your Language Model is Secretly a Q-Function , author =. Conference on Language Modeling (COLM) , year =
-
[45]
arXiv preprint arXiv:2211.14275 , year =
Solving math word problems with process-and outcome-based feedback , author =. arXiv preprint arXiv:2211.14275 , year =
-
[46]
The Twelfth International Conference on Learning Representations , year =
Let's Verify Step by Step , author =. The Twelfth International Conference on Learning Representations , year =
-
[47]
Math-Shepherd: Verify and Reinforce LLM s Step-by-step without Human Annotations
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang , editor =. Math-Shepherd: Verify and Reinforce. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =. doi:10.18653/v1/2024.acl-long.510 , pages =
-
[48]
The Lessons of Developing Process Reward Models in Mathematical Reasoning
Zhang, Zhenru and Zheng, Chujie and Wu, Yangzhen and Zhang, Beichen and Lin, Runji and Yu, Bowen and Liu, Dayiheng and Zhou, Jingren and Lin, Junyang. The Lessons of Developing Process Reward Models in Mathematical Reasoning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.547
-
[49]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning , volume =. Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2026 , month =. doi:10.1609/aaai.v40i41.40797 , number =
-
[50]
arXiv preprint arXiv:2502.01456 , year =
Process Reinforcement through Implicit Rewards , author =. arXiv preprint arXiv:2502.01456 , year =
-
[51]
The Fourteenth International Conference on Learning Representations , year =
Agentic Reinforced Policy Optimization , author =. The Fourteenth International Conference on Learning Representations , year =
-
[52]
International Conference on Machine Learning (ICML) , pages =
AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training , author =. International Conference on Machine Learning (ICML) , pages =. 2024 , editor =
2024
-
[53]
2023 , note =
Introducing Claude , author =. 2023 , note =
2023
-
[54]
arXiv preprint arXiv:2303.08774 , year =
GPT-4 Technical Report , author =. arXiv preprint arXiv:2303.08774 , year =
-
[55]
arXiv preprint arXiv:2410.21276 , year =
GPT-4o System Card , author =. arXiv preprint arXiv:2410.21276 , year =
-
[56]
2024 , note =
Learning to reason with LLMs , author =. 2024 , note =
2024
-
[57]
2024 , note =
OpenAI o3-mini , author =. 2024 , note =
2024
-
[58]
arXiv preprint arXiv:2501.12599 , year =
Kimi k1.5: Scaling Reinforcement Learning with LLMs , author =. arXiv preprint arXiv:2501.12599 , year =
-
[59]
arXiv preprint arXiv:2402.03300 , year =
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. arXiv preprint arXiv:2402.03300 , year =
-
[60]
Nature , volume =
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author =. Nature , volume =
-
[61]
arXiv preprint arXiv:2412.15115 , year =
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
-
[62]
arXiv preprint arXiv:2409.12122 , year =
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement , author =. arXiv preprint arXiv:2409.12122 , year =
-
[63]
arXiv preprint arXiv:2409.12186 , year =
Qwen2.5-Coder Technical Report , author =. arXiv preprint arXiv:2409.12186 , year =
-
[64]
arXiv preprint arXiv:2505.09388 , year =
Qwen3 Technical Report , author =. arXiv preprint arXiv:2505.09388 , year =
-
[65]
QwQ-32B: Embracing the Power of Reinforcement Learning , url =
-
[66]
arXiv preprint arXiv:2407.21783 , year =
The Llama 3 Herd of Models , author =. arXiv preprint arXiv:2407.21783 , year =
-
[67]
Introducing Gemma 3: The most capable model you can run on a single GPU or TPU , url =
-
[68]
Measuring Mathematical Problem Solving With the MATH Dataset , url =
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving With the MATH Dataset , url =
-
[69]
arXiv preprint arXiv:2110.14168 , year =
Training verifiers to solve math word problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[70]
2023 , note =
American Mathematics Contest 12 (AMC 12) , author =. 2023 , note =
2023
-
[71]
2024 , note =
American Invitational Mathematics Examination (AIME) , author =. 2024 , note =
2024
-
[72]
2025 , note =
American Invitational Mathematics Examination (AIME) , author =. 2025 , note =
2025
-
[73]
Solving Quantitative Reasoning Problems with Language Models , url =
Lewkowycz, Aitor and Andreassen, Anders and Dohan, David and Dyer, Ethan and Michalewski, Henryk and Ramasesh, Vinay and Slone, Ambrose and Anil, Cem and Schlag, Imanol and Gutman-Solo, Theo and Wu, Yuhuai and Neyshabur, Behnam and Gur-Ari, Guy and Misra, Vedant , booktitle =. Solving Quantitative Reasoning Problems with Language Models , url =
-
[74]
He, Chaoqun and Luo, Renjie and Bai, Yuzhuo and Hu, Shengding and Thai, Zhen and Shen, Junhao and Hu, Jinyi and Han, Xu and Huang, Yujie and Zhang, Yuxiang and Liu, Jie and Qi, Lei and Liu, Zhiyuan and Sun, Maosong , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, yea...
-
[75]
Bowman , booktitle =
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle =. 2024 , url =
2024
-
[76]
arXiv preprint arXiv:1803.05457 , year =
Think you have solved question answering? try arc, the ai2 reasoning challenge , author =. arXiv preprint arXiv:1803.05457 , year =
-
[77]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark , url =
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and Li, Tianle and Ku, Max and Wang, Kai and Zhuang, Alex and Fan, Rongqi and Yue, Xiang and Chen, Wenhu , booktitle =. MMLU-Pro: A More Robust and Challenging Multi-Task Language Understandi...
-
[78]
The Thirteenth International Conference on Learning Representations , year =
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author =. The Thirteenth International Conference on Learning Representations , year =
-
[79]
GitHub repository , howpublished =
Jia LI and Edward Beeching and Lewis Tunstall and Ben Lipkin and Roman Soletskyi and Shengyi Costa Huang and Kashif Rasul and Longhui Yu and Albert Jiang and Ziju Shen and Zihan Qin and Bin Dong and Li Zhou and Yann Fleureau and Guillaume Lample and Stanislas Polu , title =. GitHub repository , howpublished =. 2024 , publisher =
2024
-
[80]
The Fourteenth International Conference on Learning Representations , year =
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning , author =. The Fourteenth International Conference on Learning Representations , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.