Inside the Latent Flow: Causal Deciphering of Attention Dynamics in Audio Separation Foundation Models
Pith reviewed 2026-06-27 14:57 UTC · model grok-4.3
The pith
Orthogonal probing reveals dual text-conditioning pathways and asynchronous layer convergence in audio separation transformers, supporting selective caching that cuts attention computation by 25%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
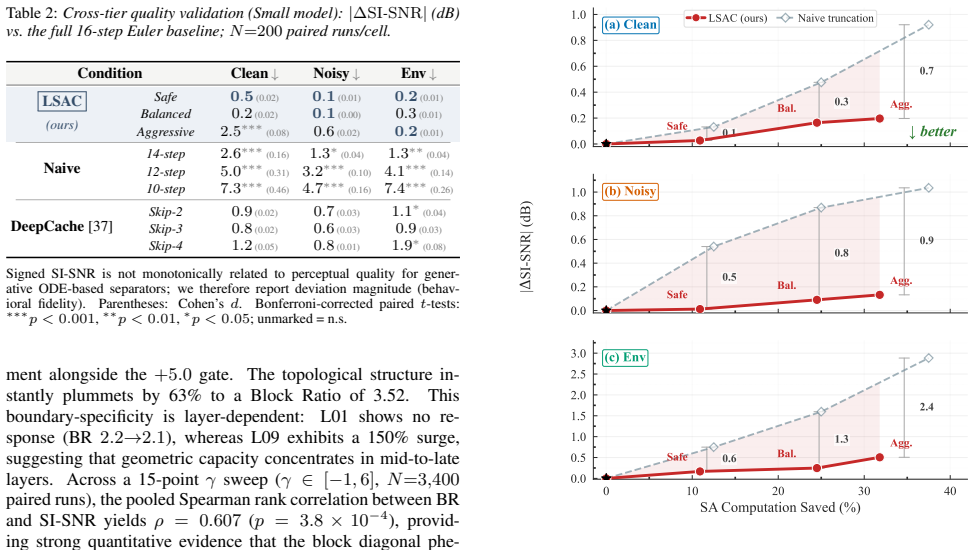
Orthogonal probing uncovers a dual-pathway text-conditioning mechanism: additive injections control semantic identity, while cross-attention refines acoustic structure. Asynchronous layerwise convergence occurs such that stable layers build temporal scaffolds early whereas fast layers continue resolving artifacts during sampling. The model attenuates temporal segmentation cues to maintain continuous-flow stability. These dynamics support Layer-Selective Attention Caching (LSAC), a training-free method that caches attention in stable layers and reduces self-attention computation by about 25% with negligible quality loss while retaining up to 6.7 times more quality than naive step reduction.
What carries the argument
Orthogonal probing protocol, a deterministic inference-time intervention that isolates causal roles of attention components to map text-conditioning pathways and layer convergence speeds.
If this is right
- Additive text injections set semantic identity while cross-attention separately refines acoustic structure.
- Stable layers establish temporal scaffolds early while fast layers resolve remaining artifacts later in sampling.
- Attenuation of temporal segmentation cues supports continuous-flow stability.
- Caching attention only in stable layers reduces self-attention computation by about 25% with negligible quality loss.
- LSAC retains up to 6.7 times more quality than reducing the number of sampling steps.
Where Pith is reading between the lines
- The identified dual pathways suggest that conditioning strategies in other flow-based audio models could be decomposed similarly for targeted interventions.
- Layer-selective caching may generalize to flow-matching transformers in related domains such as speech synthesis or music generation.
- The asynchronous convergence pattern implies that hybrid inference schedules could allocate compute unevenly across layers in broader generative audio systems.
Load-bearing premise
The deterministic inference-time probing protocol accurately reveals the model's natural attention dynamics without introducing artifacts or altering behavior.
What would settle it
Running standard inference and probed inference on the same inputs and checking whether the resulting separation outputs or attention maps differ substantially would show whether the protocol alters natural dynamics.
Figures

read the original abstract
Flow-matching transformers achieve strong audio separation, yet their attention dynamics are opaque. We adapt established causal-intervention principles into a deterministic, inference-time probing protocol for SAM Audio. Orthogonal probing uncovers a dual-pathway text-conditioning mechanism: additive injections control semantic identity, while cross-attention refines acoustic structure. We observe an asynchronous layerwise convergence: stable layers build temporal scaffolds early, whereas fast layers continue resolving artifacts during sampling. The model also attenuates temporal segmentation cues to maintain continuous-flow stability. Using these insights, we propose Layer-Selective Attention Caching (LSAC), a training-free acceleration method that caches attention in stable layers. Across acoustic complexities, LSAC cuts self-attention computation by about ~25% with negligible quality loss and yields up to 6.7x higher quality retention than naive step reduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript adapts causal-intervention principles into a deterministic inference-time orthogonal probing protocol for flow-matching transformers in audio separation (SAM Audio). It claims this reveals a dual-pathway text-conditioning mechanism (additive injections for semantic identity, cross-attention for acoustic structure), asynchronous layerwise convergence (stable layers building temporal scaffolds early, fast layers resolving artifacts later), and attenuation of temporal segmentation cues. From these insights it derives Layer-Selective Attention Caching (LSAC), a training-free method that caches attention in stable layers, reporting ~25% self-attention computation reduction with negligible quality loss and up to 6.7x higher quality retention than naive step reduction across acoustic complexities.
Significance. If the probing protocol is shown to expose rather than induce the reported dynamics, the work would supply useful mechanistic insight into attention behavior in these models and a practical acceleration technique. The quantitative performance claims, if backed by full experimental data, baselines, and statistical controls, would be relevant for efficient audio separation deployment. The adaptation of established causal ideas is a strength, but the absence of direct validation for the probing protocol limits the current evidential weight.
major comments (1)
- [Probing Protocol (Abstract and Methods)] The central claims (dual-pathway mechanism, asynchronous convergence, and LSAC efficacy) rest on the orthogonal probing protocol accurately revealing intrinsic attention dynamics. No direct check is described showing that the deterministic interventions leave output distributions, attention statistics, or separation metrics unchanged relative to unprobed baseline runs. Without such a comparison, the observed additive vs. cross-attention split and stable/fast layer distinction risk being artifacts of the probing itself, rendering both the interpretation and the derived caching strategy circular.
minor comments (1)
- [Abstract] Abstract states quantitative results (25% computation reduction, 6.7x quality retention) without data, error bars, baselines, or methodological details; these must be supplied with full experimental reporting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the single major comment below.
read point-by-point responses
-
Referee: The central claims (dual-pathway mechanism, asynchronous convergence, and LSAC efficacy) rest on the orthogonal probing protocol accurately revealing intrinsic attention dynamics. No direct check is described showing that the deterministic interventions leave output distributions, attention statistics, or separation metrics unchanged relative to unprobed baseline runs. Without such a comparison, the observed additive vs. cross-attention split and stable/fast layer distinction risk being artifacts of the probing itself, rendering both the interpretation and the derived caching strategy circular.
Authors: We agree that the manuscript would be strengthened by an explicit empirical check that the deterministic, inference-time interventions do not materially alter output distributions or metrics relative to unprobed runs. The protocol is constructed to be orthogonal (interventions are applied only to selected attention components without changing model architecture or sampling trajectory), but we acknowledge that this design argument alone is insufficient without quantitative verification. In the revised manuscript we will add a new subsection (and associated figure/table) that reports SI-SDR, PESQ, and attention-statistic differences between probed and baseline runs on the same seeds and inputs, confirming that any changes remain within the variance observed across independent unprobed runs. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper adapts external causal-intervention principles into a deterministic probing protocol, then reports empirical observations (dual-pathway conditioning, asynchronous convergence) to motivate the LSAC caching strategy. No quoted step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or definitional tautology. The protocol is presented as an adaptation rather than a self-derived construct, and LSAC is a downstream engineering application of observed layer behavior. The central claims rest on falsifiable measurements rather than constructional equivalence to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Modern au- dio foundation models integrate continuous flow matching [3] with diffusion transformers [4] to process diverse multimodal conditions [5, 6]
Introduction The promptable segmentation paradigm [1] has successfully transitioned from computer vision to audition, establishing a robust baseline for universal sound separation [2]. Modern au- dio foundation models integrate continuous flow matching [3] with diffusion transformers [4] to process diverse multimodal conditions [5, 6]. These architectures...
-
[2]
Method We define a framework of deterministic inference time inter- ventions [23] to probe the underlying mechanisms of the audio diffusion transformer. These operations manipulate the contin- uous probability flow trajectory [24] during inference without altering the pretrained network weights. 2.1. Orthogonal Probing Orthogonal probing isolates the two ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
This model features 12 transformer layers and utilizes a 16 step Euler solver
Experimental Setup We conduct causal probing on the open source SAM Audio Small model. This model features 12 transformer layers and utilizes a 16 step Euler solver. It processes audio inside a 25 Hz discrete autoencoder latent space [28]. To eliminate capacity induced behavioral discrepancies, we execute parallel random sampling on the 3 billion paramete...
-
[4]
Dual Pathway Conditioning We observe an asymmetric division of labor within the text con- ditioning mechanisms
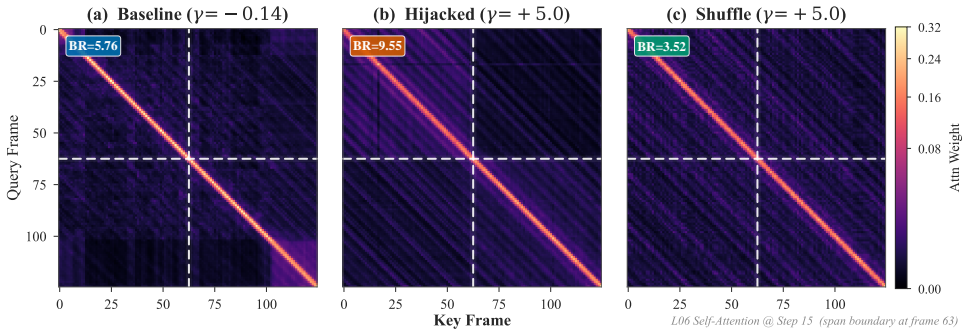
Results 4.1. Dual Pathway Conditioning We observe an asymmetric division of labor within the text con- ditioning mechanisms. Table 1 details the orthogonal physical 1For SAM-Audio-Small with a 16-step Euler solver, the baseline requires 211.4 GFLOPs, of which 61.4 GFLOPs are self-attention. /uni00000013/uni00000015/uni00000018/uni00000018/uni00000013/uni0...
-
[5]
We quantitatively establish a dual pathway text conditioning mechanism where additive injections govern se- mantic identity while cross attention resolves acoustic textures
Conclusion This work applies strict inference time causal interventions to decipher the latent flow dynamics of audio diffusion founda- tion models. We quantitatively establish a dual pathway text conditioning mechanism where additive injections govern se- mantic identity while cross attention resolves acoustic textures. We map abstract integration steps ...
-
[6]
The tool was not used to generate scien- tific content, experimental results, or conclusions
Generative AI Use Disclosure We used a generative AI tool to assist with language editing and polishing of the manuscript, including improving grammar, clarity, and readability. The tool was not used to generate scien- tific content, experimental results, or conclusions. All coauthors reviewed the final manuscript and take full responsibility for it
-
[7]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W. Lo, P. Doll´ar, and R. Girshick, “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV),
-
[8]
[Online]. Available: https://arxiv.org/abs/2304.02643
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Sun, Y ., Si, Y ., Zhu, C., Zhang, K., Shui, Z., Ding, B., Lin, T., and Yang, L
B. Shi, A. Tjandra, J. Hoffman, H. Wang, Y . Wu, L. Gao, J. Richter, M. Le, A. Vyas, S. Chen, C. Feichtenhofer, P. Doll ´ar, W. Hsu, and A. Lee, “SAM Audio: Segment anything in audio,” arXiv preprint arXiv:2512.18099, 2025. [Online]. Available: https://arxiv.org/abs/2512.18099
-
[10]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2023. [Online]. Available: https: //arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Scalable diffusion models with transform- ers,
W. Peebles and S. Xie, “Scalable diffusion models with transform- ers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4172–4182
2023
-
[13]
Available: https://arxiv.org/abs/2407.14358
[Online]. Available: https://arxiv.org/abs/2407.14358
-
[14]
AudioLDM 2: Learning holistic audio generation with self-supervised pretraining,
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wang, W. Wang, Y . Wang, and M. D. Plumbley, “AudioLDM 2: Learning holistic audio generation with self-supervised pretraining,”arXiv preprint arXiv:2308.05734, 2024. [Online]. Available: https://arxiv.org/abs/2308.05734
-
[15]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020. [Online]. Available: https://arxiv.org/abs/2006. 11239
2020
-
[16]
FlowSep: Language-queried sound separation with rectified flow matching,
Y . Yuan, X. Liu, H. Liu, M. D. Plumbley, and W. Wang, “FlowSep: Language-queried sound separation with rectified flow matching,” in2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Hyderabad, India: IEEE, 2025. [Online]. Available: https://doi.org/10.1109/ ICASSP49660.2025.10890129
-
[17]
MGE-LDM: Joint latent diffusion for simultaneous music generation and source extraction,
Y . Chae and K. Lee, “MGE-LDM: Joint latent diffusion for simultaneous music generation and source extraction,” in Advances in Neural Information Processing Systems (NeurIPS), 2025, neurIPS 2025 poster; OpenReview version. [Online]. Available: https://openreview.net/forum?id=17O8DqToyr
2025
-
[18]
LiteFocus: Accelerated diffusion inference for long audio synthesis,
Z. Tan, X. Ma, G. Fang, and X. Wang, “LiteFocus: Accelerated diffusion inference for long audio synthesis,” inProc. Interspeech 2024, 2024, pp. 4878–4882. [Online]. Available: https://www. isca-archive.org/interspeech 2024/tan24c interspeech.html
2024
-
[19]
Time-frequency- based attention cache memory model for real-time speech separation,
G. Chen, K. Li, R. Yang, and X. Hu, “Time-frequency- based attention cache memory model for real-time speech separation,”arXiv preprint arXiv:2505.13094, 2025, replaces an unverified/mismatched ICASSP metadata pair in the previous draft. [Online]. Available: https://arxiv.org/abs/2505.13094
-
[20]
Explicit-memory multiresolution adaptive framework for speech and music separation,
A. Bellur, K. Thakkar, and M. Elhilali, “Explicit-memory multiresolution adaptive framework for speech and music separation,”EURASIP Journal on Audio, Speech, and Music Processing, vol. 2023, no. 1, p. 20, 2023, verified peer- reviewed substitute for the previously unverified ICASSP 2024 Bellur/Elhilali entry. [Online]. Available: https://doi.org/10.1186/...
2023
-
[21]
What the DAAM: Interpreting stable diffusion using cross attention,
R. Tang, L. Liu, A. Pandey, Z. Jiang, G. Yang, K. Kumar, P. Stenetorp, J. Lin, and F. Ture, “What the DAAM: Interpreting stable diffusion using cross attention,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Toronto, Canada: Association for Computational Linguistics, 2023. [Online]. Avai...
2023
-
[22]
Masked-attention diffusion guidance for spatially con- trolling text-to-image generation,
Y . Endo, “Masked-attention diffusion guidance for spatially con- trolling text-to-image generation,”The Visual Computer, vol. 40, pp. 6033–6045, 2024
2024
-
[23]
Attend- and-excite: Attention-based semantic guidance for text-to-image diffusion models,
Y . Alaluf, O. Bar-Tal, D. Cohen-Or, and A. Shamir, “Attend- and-excite: Attention-based semantic guidance for text-to-image diffusion models,”arXiv preprint arXiv:2301.13826, 2023. [Online]. Available: https://arxiv.org/abs/2301.13826
-
[24]
High-Resolution Image Synthesis with Latent Diffusion Models
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 10 684–10 695. [Online]. Available: https://arxiv.org/abs/2112.10752
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Prompt-to-Prompt Image Editing with Cross Attention Control
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or, “Prompt-to-prompt image editing with cross- attention control,” inInternational Conference on Learning Representations (ICLR), 2023. [Online]. Available: https: //arxiv.org/abs/2208.01626
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Complex image-generative diffusion transformer for audio denoising,
J. Li, P. Wang, J. Li, and Y . Zhang, “Complex image-generative diffusion transformer for audio denoising,” inProc. Interspeech 2024, 2024, pp. 2220–2224, verified Interspeech paper used in place of the previously mismatched arXiv entry. [Online]. Available: https://www.isca-archive.org/interspeech 2024/li24m interspeech.html
2024
-
[27]
Causal deciphering and inpainting in spatio-temporal dynamics via diffusion model,
Y . Duan, J. Zhao, pengcheng, J. Mao, H. Wu, J. Xu, S. Wang, C. Ma, K. Wang, K. Wang, and X. Li, “Causal deciphering and inpainting in spatio-temporal dynamics via diffusion model,” inAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), 2024, main Conference Track. [Online]. Avail- able: https://proceedings.neurips.cc/paper files/paper/202...
2024
-
[28]
Attention is not explanation,
S. Jain and B. C. Wallace, “Attention is not explanation,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Volume 1 (Long and Short Papers). Association for Computational Linguistics, 2019, pp. 3543–3556. [Online]. Available: https://aclanthology...
2019
-
[29]
Towards understanding cross and self-attention in stable diffusion for text-guided image editing,
B. Liu, C. Wang, T. Cao, K. Jia, and J. Huang, “Towards understanding cross and self-attention in stable diffusion for text-guided image editing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 11 848–11 858. [Online]. Available: https: //arxiv.org/abs/2403.03431
-
[30]
Transformer interpretability be- yond attention visualization,
H. Chefer, S. Gur, and L. Wolf, “Transformer interpretability be- yond attention visualization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 782–791
2021
-
[31]
Pearl,Causality: Models, Reasoning, and Inference, 2nd ed
J. Pearl,Causality: Models, Reasoning, and Inference, 2nd ed. Cambridge University Press, 2009
2009
-
[32]
Score-Based Generative Modeling through Stochastic Differential Equations
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations (ICLR), 2021. [Online]. Available: https://arxiv.org/abs/2011.13456
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
FiLM: Visual Reasoning with a General Conditioning Layer
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville, “FiLM: Visual reasoning with a general conditioning layer,” inAAAI Conference on Artificial Intelligence, 2018. [Online]. Available: https://arxiv.org/abs/1709.07871
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017, pp. 5998–6008. [Online]. Available: https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Quantifying attention flow in transformers,
S. Abnar and W. Zuidema, “Quantifying attention flow in transformers,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, 2020, pp. 4190–4197. [Online]. Available: https://aclanthology.org/2020.acl-main.385/
2020
-
[36]
High-fidelity audio compression with improved RVQGAN,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved RVQGAN,” arXiv preprint arXiv:2306.06546, 2023. [Online]. Available: https://arxiv.org/abs/2306.06546
-
[37]
Lib- riSpeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- riSpeech: An ASR corpus based on public domain audio books,” inProceedings of the IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2015, pp. 5206– 5210
2015
-
[38]
ESC-50: A dataset for environmental sound classifi- cation,
K. J. Piczak, “ESC-50: A dataset for environmental sound classifi- cation,” inProceedings of the 23rd ACM International Conference on Multimedia (ACM MM), 2015, pp. 1015–1018
2015
-
[39]
FSD50K: An open dataset of human-labeled sound events,
E. Fonseca, M. Plakal, D. P. W. Ellis, F. Font, and X. Serra, “FSD50K: An open dataset of human-labeled sound events,” arXiv preprint arXiv:2010.00475, 2020. [Online]. Available: https://arxiv.org/abs/2010.00475
-
[40]
Conv-TasNet: Surpassing ideal time– frequency magnitude masking for speech separation,
Y . Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal time– frequency magnitude masking for speech separation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, 2019
2019
-
[41]
Performance measure- ment in blind audio source separation,
E. Vincent, R. Gribonval, and C. F ´evotte, “Performance measure- ment in blind audio source separation,”IEEE Transactions on Au- dio, Speech, and Language Processing, vol. 14, no. 4, pp. 1462– 1469, 2006
2006
-
[42]
An al- gorithm for intelligibility prediction of time–frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “An al- gorithm for intelligibility prediction of time–frequency weighted noisy speech,”IEEE Transactions on Audio, Speech, and Lan- guage Processing, vol. 19, no. 7, pp. 2125–2136, 2011
2011
-
[43]
ITU-T, “ITU-T Recommendation P.862: Perceptual evaluation of speech quality (pesq): An objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs,” International Telecommunication Union, 2001
2001
-
[44]
Cohen,Statistical Power Analysis for the Behavioral Sciences, 2nd ed
J. Cohen,Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Lawrence Erlbaum Associates, 1988
1988
-
[46]
Available: https://arxiv.org/abs/2312.00858
[Online]. Available: https://arxiv.org/abs/2312.00858
-
[47]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,” arXiv preprint arXiv:2209.03003, 2022. [Online]. Available: https://arxiv.org/abs/2209.03003
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learning Representations (ICLR), 2021. [Online]. Available: https: //arxiv.org/abs/2010.02502
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[49]
DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps,
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu, “DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022. [Online]. Available: https://arxiv.org/abs/2206.00927
-
[50]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” inInternational Conference on Learning Representations (ICLR),
-
[51]
Auto-Encoding Variational Bayes
[Online]. Available: https://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Fast timing-conditioned latent audio diffusion,
Z. Evans, C. Carr, J. Taylor, S. H. Hawley, and J. Pons, “Fast timing-conditioned latent audio diffusion,”arXiv preprint arXiv:2402.04825, 2024, accepted to ICML 2024. [Online]. Available: https://arxiv.org/abs/2402.04825
-
[53]
EzAudio: Enhancing text-to-audio generation with efficient diffusion transformer,
J. Hai, Y . Xu, H. Zhang, C. Li, H. Wang, M. Elhilali, and D. Yu, “EzAudio: Enhancing text-to-audio generation with efficient diffusion transformer,” inProc. Interspeech, 2025. [Online]. Available: https://www.isca-archive.org/interspeech 2025/hai25 interspeech.html
2025
-
[54]
W A-Transformer: Window attention-based transformer with two-stage strategy for multi-task audio source separation,
Y . Wang, C. Li, F. Deng, S. Lu, P. Yao, J. Tan, C. Song, and X. Wang, “W A-Transformer: Window attention-based transformer with two-stage strategy for multi-task audio source separation,” inProc. Interspeech 2022, 2022, pp. 5373–5377. [Online]. Available: https://www.isca-archive.org/interspeech 2022/wang22p interspeech.html
2022
-
[55]
TriBERT: Human- centric audio-visual representation learning,
T. Rahman, M. Yang, and L. Sigal, “TriBERT: Human- centric audio-visual representation learning,” inAdvances in Neural Information Processing Systems 34 (NeurIPS 2021), 2021, pp. 9774–9787, the arXiv preprint uses the longer title “TriBERT: Full-body Human-centric Audio-visual Rep- resentation Learning for Visual Sound Separation”. [On- line]. Available: ...
2021
-
[56]
SepTr: Separable transformer for audio spectrogram processing,
N.-C. Ristea, R. T. Ionescu, and F. S. Khan, “SepTr: Separable transformer for audio spectrogram processing,” inProc. Interspeech 2022, 2022, pp. 4103–4107. [On- line]. Available: https://www.isca-archive.org/interspeech 2022/ ristea22 interspeech.html
2022
-
[57]
HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection,
K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dubnov, “HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection,” in2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 646–650. [Online]. Available: https://ieeexplore.ieee.org/document/9746312
-
[58]
Interpretability analysis in transformers based on attention visualization,
Y . Guo, “Interpretability analysis in transformers based on attention visualization,”Applied and Computational Engineering, vol. 76, pp. 92–102, 2024. [Online]. Available: https: //ace.ewapub.com/article/view/13745
2024
-
[59]
Dynamic knowledge condensation with audio-selective transformer for audio deepfake detection,
T. M. Wani and I. Amerini, “Dynamic knowledge condensation with audio-selective transformer for audio deepfake detection,” Discover Computing, vol. 28, p. 231, 2025, article number
2025
-
[60]
Available: https://link.springer.com/article/10
[Online]. Available: https://link.springer.com/article/10. 1007/s10791-025-09746-4
-
[61]
Ripple sparse self-attention for monaural speech enhancement,
Q. Zhang, H. Zhu, Q. Song, X. Qian, Z. Ni, and H. Li, “Ripple sparse self-attention for monaural speech enhancement,” in2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Rhodes Island, Greece: IEEE, 2023, pp. 4426–4430, iCASSP 2023 formal conference version (5 pages); arXiv preprint: 2305.08541. DOI not independently ...
-
[62]
P. Wang and H. Van hamme, “Disentangled-transformer: An explainable end-to-end automatic speech recognition model with speech content-context separation,” in2025 6th IEEE International Conference on Image Processing, Applications and Systems (IPAS), Lyon, France, 2025, pp. 1–7. [Online]. Available: https://ieeexplore.ieee.org/document/10924511
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.