SoK: Colluding Adversaries in Machine Learning Pipelines
Pith reviewed 2026-06-27 16:09 UTC · model grok-4.3
The pith
A framework maps how adversaries at training and inference stages in ML pipelines can collude by sharing enabling factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
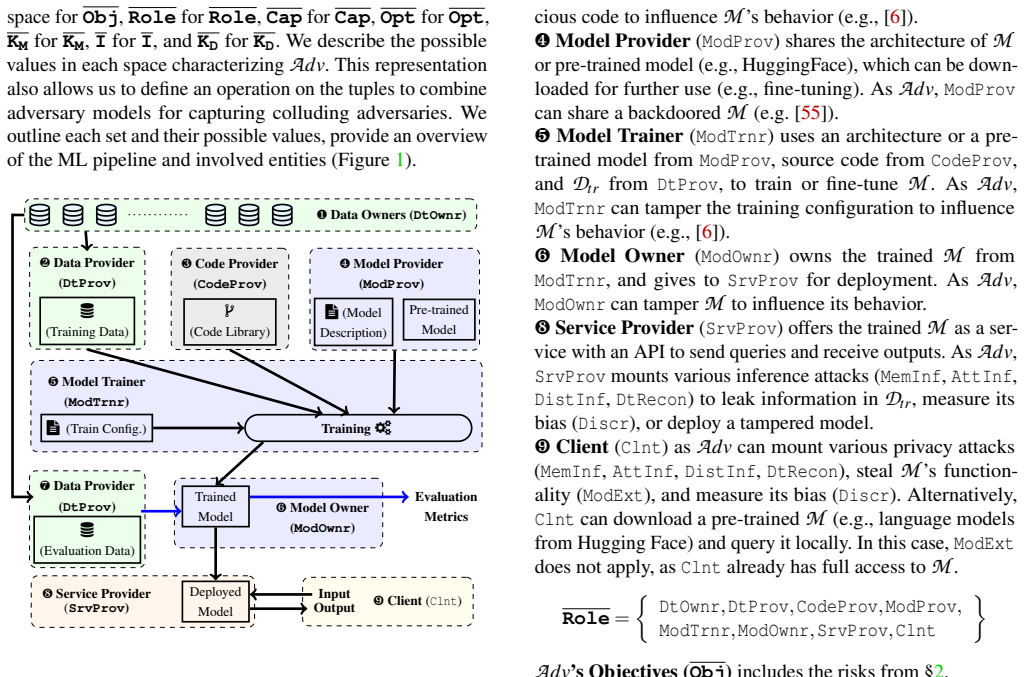
The central claim is that a dedicated framework can systematically cover collusion between train- and inference-time adversaries and among inference-time adversaries by incorporating enabling factors, while a guideline based on those factors allows conjectures about collusion potential. Application of the framework explains prior work, supports conjectures on new collusions, and leads to empirical validation of five cases. Adversary characteristics are shown to influence collusion potential.
What carries the argument
The collusion framework that covers train- versus inference-time adversaries and among inference-time adversaries while tracking enabling factors and supplying a conjecture guideline.
If this is right
- Prior attacks become explainable as outcomes of collusion when enabling factors align.
- Unexplored collusions can be systematically conjectured and tested for amplification effects.
- Adversary characteristics such as objectives and knowledge directly raise or lower collusion likelihood.
- Security analyses must move beyond isolated adversary models to account for multi-stage interactions.
- The five validated cases demonstrate concrete attack amplification through collusion.
Where Pith is reading between the lines
- Defenses could target disruption of specific enabling factors to reduce collusion risk across pipeline stages.
- The guideline might be applied to emerging settings such as federated learning to surface additional collusion vectors.
- Threat models that omit collusion likely underestimate total risk to deployed ML systems.
- Extension of the framework to new attack combinations could be tested by checking whether predicted collusions materialize in controlled experiments.
Load-bearing premise
The enabling factors identified by the framework are sufficient to accurately conjecture about collusion potential and the five validated cases generalize.
What would settle it
A documented collusion case in which the enabling factors predict low potential but high amplification is observed, or high potential but no amplification occurs, outside the five tested scenarios.
Figures
read the original abstract
Machine learning (ML) models are susceptible to various security, privacy, and fairness risks. Adversaries with different characteristics (i.e., objectives, knowledge, and capabilities) can collude by executing one attack to amplify others. Existing work lacks a systematic framework to explore collusion among adversaries, and to study the implications of the adversaries' characteristics. We present a framework covering collusion (a) between train- and inference-time adversaries, and (b) among inference-time adversaries. Our framework accounts for factors enabling collusion between adversaries. We propose a guideline to conjecture about the potential for collusion using enabling factors. We use it to explain prior work, conjecture about unexplored collusions, and empirically validate five such cases. Finally, we discuss how adversaries' characteristics influence the potential for collusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a systematization of knowledge (SoK) on colluding adversaries in ML pipelines. It introduces a framework covering collusion (a) between train-time and inference-time adversaries and (b) among inference-time adversaries, identifies enabling factors for collusion, and proposes a guideline for conjecturing collusion potential from those factors. The framework is applied to explain prior work, conjecture about unexplored collusions, and the guideline is empirically validated on five cases; the paper closes by discussing how adversary characteristics affect collusion potential.
Significance. If the framework and guideline prove reliable, the work would organize a fragmented area of ML security research by supplying a structured lens for multi-adversary interactions, which are increasingly plausible in deployed pipelines. The explicit conjecture-plus-validation step is a positive feature of the SoK approach and could guide both future attacks and defenses.
major comments (2)
- [Empirical validation] Empirical validation section: the claim that the guideline enables reliable conjecture about collusion potential rests on five cases, yet the manuscript supplies no information on case selection criteria, attack diversity, experimental controls, datasets, or negative results. Without these, it is impossible to evaluate whether the enabling factors are sufficient or whether the guideline would have predicted outcomes prospectively.
- [Framework] Framework section: the enabling factors are presented as the basis for the conjecture guideline, but the manuscript does not demonstrate that the listed factors are exhaustive or derived systematically (e.g., via a complete literature mapping or formal taxonomy). This leaves open the possibility that unaccounted factors could alter collusion potential in unexamined scenarios.
minor comments (2)
- Notation for adversary characteristics (objectives, knowledge, capabilities) is introduced but used inconsistently across figures and text; a single summary table would improve readability.
- Several citations to prior collusion or multi-adversary work appear only in passing; a dedicated related-work subsection would clarify the novelty of the proposed structure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our SoK. We respond to each major comment below and note the revisions we will make to address them.
read point-by-point responses
-
Referee: [Empirical validation] Empirical validation section: the claim that the guideline enables reliable conjecture about collusion potential rests on five cases, yet the manuscript supplies no information on case selection criteria, attack diversity, experimental controls, datasets, or negative results. Without these, it is impossible to evaluate whether the enabling factors are sufficient or whether the guideline would have predicted outcomes prospectively.
Authors: We agree that more transparency on the validation cases is needed. The five cases were chosen to illustrate distinct collusion patterns (train-inference and inference-inference) across different attack objectives and knowledge assumptions drawn from the surveyed literature. In the revised version we will insert a dedicated subsection that states the selection criteria, documents attack diversity, lists the datasets and controls employed, and clarifies that the validation demonstrates the guideline's utility on positive examples rather than claiming exhaustiveness or prospective prediction power. We will also add a limitations paragraph noting the absence of systematic negative-result testing. revision: yes
-
Referee: [Framework] Framework section: the enabling factors are presented as the basis for the conjecture guideline, but the manuscript does not demonstrate that the listed factors are exhaustive or derived systematically (e.g., via a complete literature mapping or formal taxonomy). This leaves open the possibility that unaccounted factors could alter collusion potential in unexamined scenarios.
Authors: The factors were compiled via a literature survey of known ML adversary models; the SoK does not assert that the list is exhaustive or that a formal taxonomy was constructed. In the revision we will add an explicit paragraph describing the survey process used to identify the factors and will state the scope limitation that future attacks may surface additional enabling conditions. This will be paired with a forward-looking remark on how the guideline could be updated. revision: yes
Circularity Check
No circularity: SoK framework and guideline are new organizational structure drawn from external literature
full rationale
This is a systematization-of-knowledge paper whose central contribution is a new framework that organizes existing attacks into categories of train/inference collusion and identifies enabling factors from the cited body of work. The guideline for conjecturing collusion potential is presented as an application of those factors rather than a quantity fitted to or defined by the five validation cases. No equations, parameter estimation, or self-referential definitions appear in the abstract or described structure. The five empirical cases are described as post-hoc validation and conjecture exercises, not as the source from which the factors or guideline are derived. Self-citations, if any, are not required to carry the load-bearing argument; the derivation remains externally grounded in the prior literature it systematizes. This is the normal, non-circular outcome for an SoK paper that introduces taxonomy without reducing its claims to fitted inputs or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adversaries with different objectives, knowledge, and capabilities can collude by executing one attack to amplify others.
invented entities (1)
-
Framework for collusion analysis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On the alignment of group fairness with attribute privacy
Jan Aalmoes, Vasisht Duddu, and Antoine Boutet. On the alignment of group fairness with attribute privacy. InWISE, pages 333–348, 2025
2025
-
[2]
Sok: A systematic evaluation of backdoor trigger characteristics in image classification
Gorka Abad et al. Sok: A systematic evaluation of backdoor trigger characteristics in image classification. InarXiv:2302.01740, 2023
-
[3]
Measuring non-adversarial repro- duction of training data in large language models
Michael Aerni et al. Measuring non-adversarial repro- duction of training data in large language models. In arXiv:2411.10242, 2024
-
[4]
Square attack: a query-efficient black-box adversarial attack via ran- dom search
Maksym Andriushchenko et al. Square attack: a query-efficient black-box adversarial attack via ran- dom search. InECCV, pages 484–501, 2020
2020
-
[5]
Static vs
Gilad Asharov et al. Static vs. adaptive security in perfect MPC: A separation and the adaptive security of BGW. InCryptology ePrint Archive, Paper 2022/758, 2022
2022
-
[6]
Blind backdoors in deep learning models
Eugene Bagdasaryan and Vitaly Shmatikov. Blind backdoors in deep learning models. InUSENIX Secu- rity, pages 1505–1521, 2021
2021
-
[7]
CSI NN: Reverse engineering of neu- ral network architectures through electromagnetic side channel
Lejla Batina, Shivam Bhasin, Dirmanto Jap, and Stjepan Picek. CSI NN: Reverse engineering of neu- ral network architectures through electromagnetic side channel. InUSENIX Security, pages 515–532, August 2019
2019
-
[8]
Chosen ciphertext attacks against protocols based on the rsa encryption standard pkcs #1
Daniel Bleichenbacher. Chosen ciphertext attacks against protocols based on the rsa encryption standard pkcs #1. InCRYPTO, pages 1–12, 1998
1998
-
[9]
Sok: Gradient inversion attacks in federated learning
Vincenzo Carletti et al. Sok: Gradient inversion attacks in federated learning. InUSENIX Security Symposium (USENIX SEC), 2025
2025
-
[10]
Extracting training data from large language models
Nicholas Carlini et al. Extracting training data from large language models. InUSENIX Security, pages 2633–2650, 2021
2021
-
[11]
Membership inference attacks from first principles
Nicholas Carlini et al. Membership inference attacks from first principles. InSP, pages 1897–1914, 2022
1914
-
[12]
The privacy onion effect: Mem- orization is relative
Nicholas Carlini et al. The privacy onion effect: Mem- orization is relative. InNeurIPS, 2022
2022
-
[13]
Extracting training data from diffusion models
Nicholas Carlini et al. Extracting training data from diffusion models. InUSENIX Security, 2023. 14
2023
-
[14]
Stealing part of a production language model
Nicholas Carlini et al. Stealing part of a production language model. InarXiv:2403.06634, 2024
-
[15]
Property inference from poisoning
Melissa Chase et al. Property inference from poisoning. InSP, 2022
2022
-
[16]
Snap: Efficient extraction of private properties with poisoning
Harsh Chaudhari et al. Snap: Efficient extraction of private properties with poisoning. InSP, pages 400– 417, 2023
2023
-
[17]
Chen Chen et al. Killing one bird with two stones: model extraction and attribute inference attacks against bert-based apis. InarXiv:2105.10909, 2021
-
[18]
Privacy and fairness in federated learning: On the perspective of tradeoff.ACM Comput
Huiqiang Chen et al. Privacy and fairness in federated learning: On the perspective of tradeoff.ACM Comput. Surv., 56, sep 2023
2023
-
[19]
Amplifying membership exposure via data poisoning
Yufei Chen et al. Amplifying membership exposure via data poisoning. InNeurIPS, pages 29830–29844, 2022
2022
-
[20]
A method to fa- cilitate membership inference attacks in deep learning models
Zitao Chen and Karthik Pattabiraman. A method to fa- cilitate membership inference attacks in deep learning models. InNDSS, 2025
2025
-
[21]
Long-tailed adversarial training with self-distillation
Seungju Cho et al. Long-tailed adversarial training with self-distillation. InICLR, 2025
2025
-
[22]
Choquette-Choo et al
Christopher A. Choquette-Choo et al. Label-only mem- bership inference attacks. InICML, pages 1964–1974, 2021
1964
-
[23]
Wild patterns reloaded: A survey of machine learning security against training data poisoning.ACM Comput
Antonio Emanuele Cinà et al. Wild patterns reloaded: A survey of machine learning security against training data poisoning.ACM Comput. Surv., 55, 2023
2023
-
[24]
Energy-latency at- tacks via sponge poisoning.Information Sciences, 702:121905, 2025
Antonio Emanuele Cinà et al. Energy-latency at- tacks via sponge poisoning.Information Sciences, 702:121905, 2025
2025
-
[25]
Why do adversarial attacks transfer? explaining transferability of evasion and poi- soning attacks
Ambra Demontis et al. Why do adversarial attacks transfer? explaining transferability of evasion and poi- soning attacks. InUSENIX Security, pages 321–338, 2019
2019
-
[26]
Vertexserum: Poisoning graph neural networks for link inference
Ruyi Ding et al. Vertexserum: Poisoning graph neural networks for link inference. InICCV, pages 4532– 4541, 2023
2023
-
[27]
Are diffusion models vulnerable to membership inference attacks? InICML, 2023
Jinhao Duan et al. Are diffusion models vulnerable to membership inference attacks? InICML, 2023
2023
-
[28]
Do membership inference attacks work on large language models? InarXiv:2402.07841, 2024
Michael Duan et al. Do membership inference attacks work on large language models? InarXiv:2402.07841, 2024
-
[29]
Sok: Unintended interactions among machine learning defenses and risks
Vasisht Duddu et al. Sok: Unintended interactions among machine learning defenses and risks. InSP, pages 2996–3014, 2024
2024
-
[30]
Combining machine learning defenses without conflicts
Vasisht Duddu et al. Combining machine learning defenses without conflicts. InTMLR, 2025
2025
-
[31]
Gifd: A generative gradient inversion method with feature domain optimization
Hao Fang et al. Gifd: A generative gradient inversion method with feature domain optimization. InICCV, pages 4967–4976, 2023
2023
-
[32]
SoK: Ana- lyzing adversarial examples: A framework to study adversary knowledge
Lucas Fenaux and Florian Kerschbaum. SoK: Ana- lyzing adversarial examples: A framework to study adversary knowledge. InarXiv 2402.14937, 2024
-
[33]
Stateful defenses for machine learning models are not yet secure against black-box attacks
Ryan Feng et al. Stateful defenses for machine learning models are not yet secure against black-box attacks. In CCS, pages 786–800, 2023
2023
-
[34]
Privacy backdoors: Stealing data with corrupted pretrained models
Shanglun Feng and Florian Tramèr. Privacy backdoors: Stealing data with corrupted pretrained models. In ICML, 2024
2024
-
[35]
Julien Ferry et al. Sok: Taming the triangle–on the interplays between fairness, interpretability and privacy in machine learning.arXiv:2312.16191, 2023
-
[36]
Differential privacy and fairness in decisions and learning tasks: A survey
Ferdinando Fioretto et al. Differential privacy and fairness in decisions and learning tasks: A survey. In IJCAI, pages 5470–5477, 2022
2022
-
[37]
Adversarial examples make strong poisons
Liam Fowl et al. Adversarial examples make strong poisons. InNeurIPS, pages 30339–30351, 2021
2021
-
[38]
Honglin Fu et al. Perseus: Tracing the masterminds be- hind cryptocurrency pump-and-dump schemes.arXiv preprint arXiv:2503.01686, 2025
-
[39]
Un-fair trojan: Targeted backdoor attacks against model fairness
Nicholas Furth et al. Un-fair trojan: Targeted backdoor attacks against model fairness. InSDS, pages 1–9, 2022
2022
-
[40]
Bias and fairness in large language models: A survey.Computational Linguistics, pages 1–79, 2024
Isabel O Gallegos et al. Bias and fairness in large language models: A survey.Computational Linguistics, pages 1–79, 2024
2024
-
[41]
Inverting gradients - how easy is it to break privacy in federated learning? InAdvances in Neural Information Processing Systems, pages 16937– 16947, 2020
Jonas Geiping et al. Inverting gradients - how easy is it to break privacy in federated learning? InAdvances in Neural Information Processing Systems, pages 16937– 16947, 2020
2020
-
[42]
An adversarial perspective on ac- curacy, robustness, fairness, and privacy: Multilateral- tradeoffs in trustworthy ml.IEEE Access, 10:120850– 120865, 2022
Alex Gittens et al. An adversarial perspective on ac- curacy, robustness, fairness, and privacy: Multilateral- tradeoffs in trustworthy ml.IEEE Access, 10:120850– 120865, 2022
2022
-
[43]
Inversenet: Augmenting model ex- traction attacks with training data inversion
Xueluan Gong et al. Inversenet: Augmenting model ex- traction attacks with training data inversion. InIJCAI, pages 2439–2447, 2021
2021
-
[44]
Adversarial initialization - when your network performs the way i want -.ArXiv e-prints, February 2019
Kathrin Grosse et al. Adversarial initialization - when your network performs the way i want -.ArXiv e-prints, February 2019. 15
2019
-
[45]
On the security relevance of initial weights in deep neural networks
Kathrin Grosse et al. On the security relevance of initial weights in deep neural networks. InICANN, pages 3– 14, Cham, 2020. Springer International Publishing
2020
-
[46]
A survey on transferability of adver- sarial examples across deep neural networks.Transac- tions on Machine Learning Research (TMLR), 2024
Jindong Gu et al. A survey on transferability of adver- sarial examples across deep neural networks.Transac- tions on Machine Learning Research (TMLR), 2024
2024
-
[47]
What is an initial access broker (iab)? Ac- cessed 2026-05-18
Halcyon. What is an initial access broker (iab)? Ac- cessed 2026-05-18
2026
-
[48]
Reverse engineering convolu- tional neural networks through side-channel informa- tion leaks
Weizhe Hua et al. Reverse engineering convolu- tional neural networks through side-channel informa- tion leaks. InDAC, 2018
2018
-
[49]
Are attribute inference attacks just imputation? InCCS, pages 1569– 1582, 2022
Bargav Jayaraman and David Evans. Are attribute inference attacks just imputation? InCCS, pages 1569– 1582, 2022
2022
-
[50]
Adversarial robustness poisoning: Increasing adversarial vulnerability of the model via data poisoning
Wenbo Jiang et al. Adversarial robustness poisoning: Increasing adversarial vulnerability of the model via data poisoning. InGLOBECOM, pages 4286–4291, 2024
2024
-
[51]
TOGA: Trigger optimization for clean data ordering backdoor attack, 2026
Qixuan Jin et al. TOGA: Trigger optimization for clean data ordering backdoor attack, 2026
2026
-
[52]
Prada: protecting against dnn model stealing attacks
Mika Juuti et al. Prada: protecting against dnn model stealing attacks. InEuroS&P, pages 512–527, 2019
2019
-
[53]
Thieves of sesame street: Model extraction on bert-based apis
Kalpesh Krishna et al. Thieves of sesame street: Model extraction on bert-based apis. InICLR, 2020
2020
-
[54]
Architectural backdoors for within-batch data stealing and model inference manip- ulation
Nicolas Küchler et al. Architectural backdoors for within-batch data stealing and model inference manip- ulation. InarXiv 2505.18323, 2025
-
[55]
Architectural Neural Backdoors from First Principles
Harry Langford et al. Architectural Neural Backdoors from First Principles . InSP, pages 60–60, 2025
2025
-
[56]
Enhanced label-only membership infer- ence attacks with fewer queries
Hao Li et al. Enhanced label-only membership infer- ence attacks with fewer queries. InUSENIX Security, 2025
2025
-
[57]
Backdoor learning: A survey.IEEE Transactions on Neural Networks and Learning Sys- tems, 35:5–22, 2022
Yiming Li et al. Backdoor learning: A survey.IEEE Transactions on Neural Networks and Learning Sys- tems, 35:5–22, 2022
2022
-
[58]
From head to tail: Efficient black-box model inversion attack via long-tailed learning
Ziang Li et al. From head to tail: Efficient black-box model inversion attack via long-tailed learning. In CVPR, pages 29288–29298, 2025
2025
-
[59]
{ML-Doctor}: Holistic risk assess- ment of inference attacks against machine learning models
Yugeng Liu et al. {ML-Doctor}: Holistic risk assess- ment of inference attacks against machine learning models. InUSENIX Security, pages 4525–4542, 2022
2022
-
[60]
Amplifying machine learning attacks through strategic compositions
Yugeng Liu et al. Amplifying machine learning attacks through strategic compositions. InarXiv 2506.18870, 2025
-
[61]
Stable bias: Evaluating societal representations in diffusion models
Sasha Luccioni et al. Stable bias: Evaluating societal representations in diffusion models. InNeurIPS, 2024
2024
-
[62]
Analyzing leakage of personally identifiable information in language models
Nils Lukas et al. Analyzing leakage of personally identifiable information in language models. InSP, pages 346–363, 2023
2023
-
[63]
Leveraging optimization for adaptive attacks on image watermarks
Nils Lukas et al. Leveraging optimization for adaptive attacks on image watermarks. InICLR, 2024
2024
-
[64]
Exploring privacy and fairness risks in sharing diffusion models: An adversarial perspective
Xinjian Luo et al. Exploring privacy and fairness risks in sharing diffusion models: An adversarial perspective. IEEE TIFS, 2024
2024
-
[65]
Deepstrike: Remotely-guided fault injection attacks on dnn accelerator in cloud-fpga
Yukui Luo et al. Deepstrike: Remotely-guided fault injection attacks on dnn accelerator in cloud-fpga. In DAC, page 295–300, 2022
2022
-
[66]
Honest-but-curious nets: Sensitive attributes of private inputs can be secretly coded into the classifiers’ outputs
Mohammad Malekzadeh et al. Honest-but-curious nets: Sensitive attributes of private inputs can be secretly coded into the classifiers’ outputs. InCCS, pages 825– 844, 2021
2021
-
[67]
Eab-fl: Exacerbat- ing algorithmic bias through model poisoning attacks in federated learning
Syed Irfan Ali Meerza and Jian Liu. Eab-fl: Exacerbat- ing algorithmic bias through model poisoning attacks in federated learning. InIJCAI, pages 458–466, 2024
2024
-
[68]
Exacerbating algorithmic bias through fairness attacks
Ninareh Mehrabi et al. Exacerbating algorithmic bias through fairness attacks. InAAAI, pages 8930–8938, 2021
2021
-
[69]
A survey on bias and fairness in machine learning.ACM Comput
Ninareh Mehrabi et al. A survey on bias and fairness in machine learning.ACM Comput. Surv., 54:1–35, 2021
2021
-
[70]
Exploiting unintended feature leakage in collaborative learning
Luca Melis et al. Exploiting unintended feature leakage in collaborative learning. InSP, pages 691–706, 2019
2019
-
[71]
From defender to devil? un- intended risk interactions induced by llm defenses
Xiangtao Meng et al. From defender to devil? un- intended risk interactions induced by llm defenses. arXiv:2510.07968, 2025
-
[72]
Backdooring bias into text-to-image models
Ali Naseh et al. Backdooring bias into text-to-image models. InarXiv:2406.15213, 2024
-
[73]
Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning
Milad Nasr et al. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In SP, pages 739–753, 2019
2019
-
[74]
Towards reverse-engineering black-box neural networks
Seong Joon Oh et al. Towards reverse-engineering black-box neural networks. InICLR, 2018
2018
-
[75]
I know what you trained last summer: A survey on stealing machine learning mod- els and defences.ACM Comput
Daryna Oliynyk et al. I know what you trained last summer: A survey on stealing machine learning mod- els and defences.ACM Comput. Surv., 55, July 2023
2023
-
[76]
Knockoff nets: Stealing functionality of black-box models
Tribhuvanesh Orekondy et al. Knockoff nets: Stealing functionality of black-box models. InCVPR, pages 4954–4963, 2019. 16
2019
-
[77]
Teach llms to phish: Stealing private information from language models
Ashwinee Panda et al. Teach llms to phish: Stealing private information from language models. InICLR, 2024
2024
-
[78]
A tale of evil twins: Adversarial inputs versus poisoned models
Ren Pang et al. A tale of evil twins: Adversarial inputs versus poisoned models. InCCS, pages 85–99, 2020
2020
-
[79]
Practical black-box attacks against machine learning
Nicolas Papernot et al. Practical black-box attacks against machine learning. InAsiaCCS, pages 506–519, 2017
2017
-
[80]
SoK: Security and privacy in machine learning
Nicolas Papernot et al. SoK: Security and privacy in machine learning. InEuroS&P, pages 399–414, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.