Effective Training Principles of Physical Reservoirs
Pith reviewed 2026-06-27 15:09 UTC · model grok-4.3
The pith
Selecting readouts across the full output spectrum plus L1 or L2 regularization reduces overfitting and raises accuracy in physical reservoir computers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
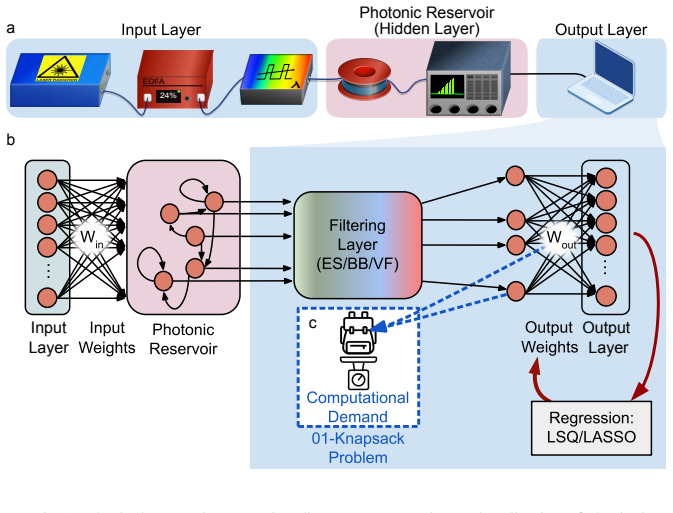
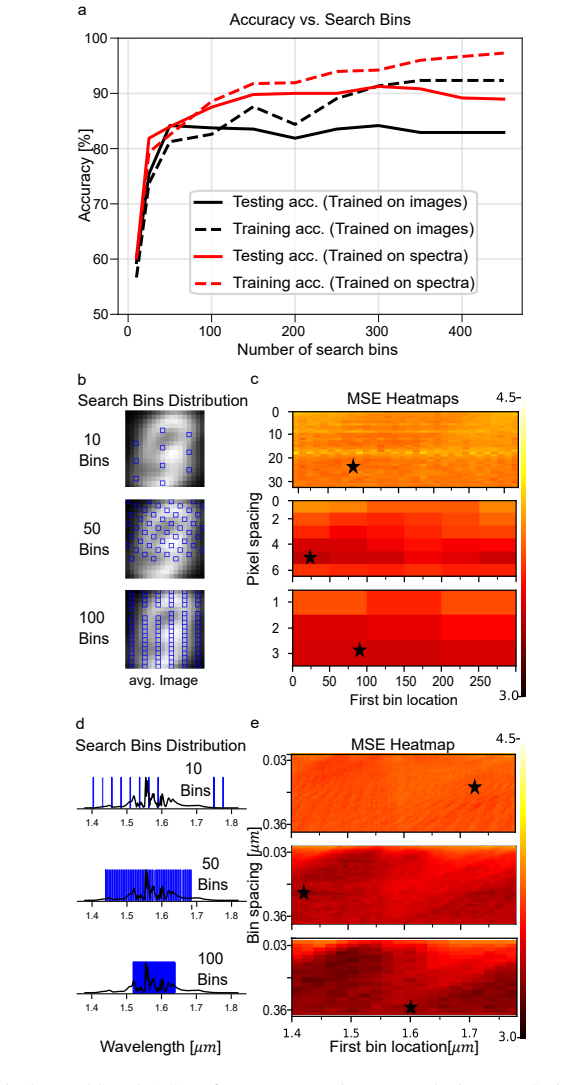
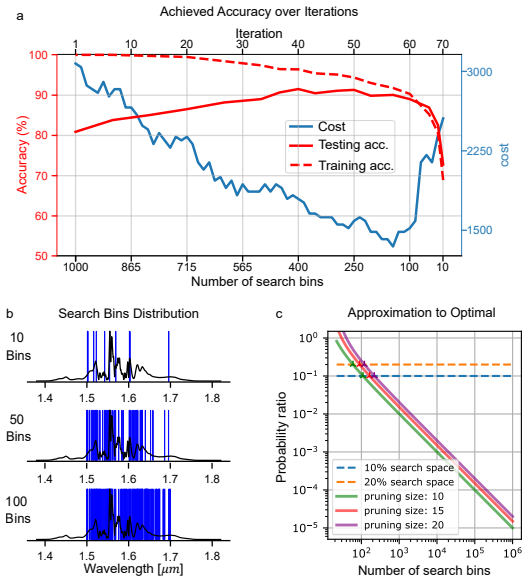
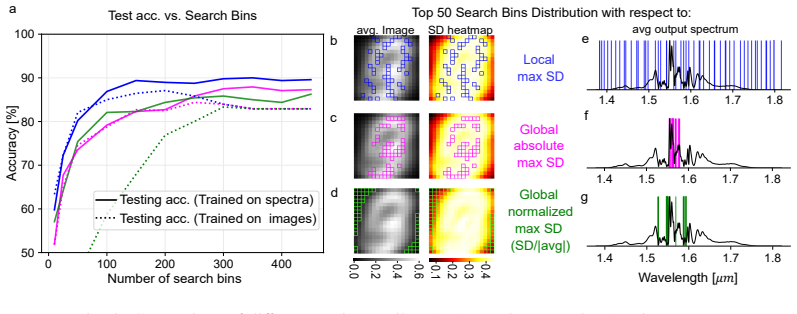
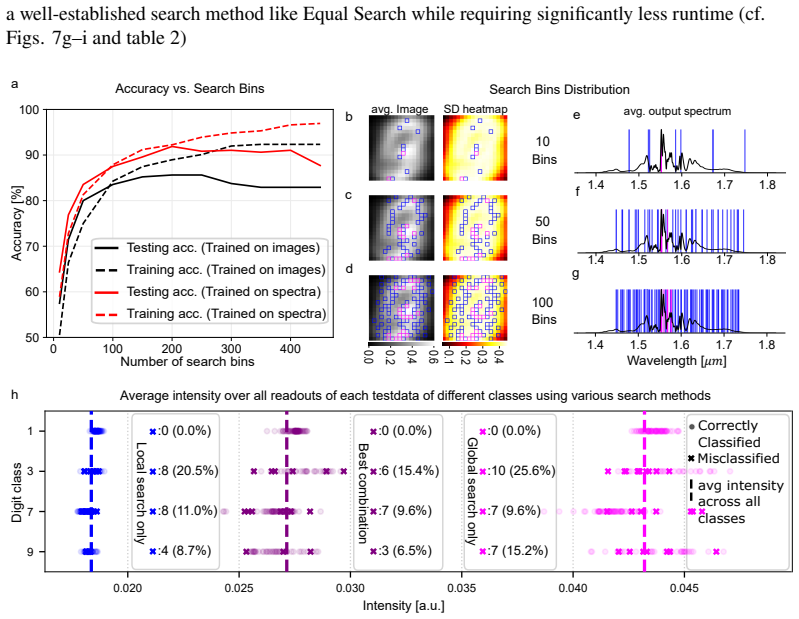
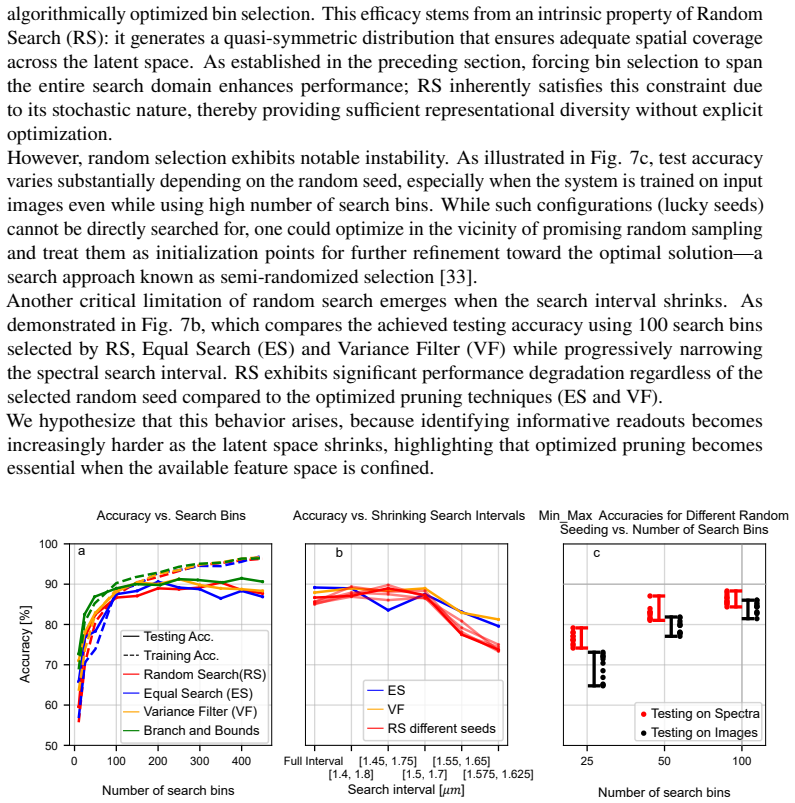
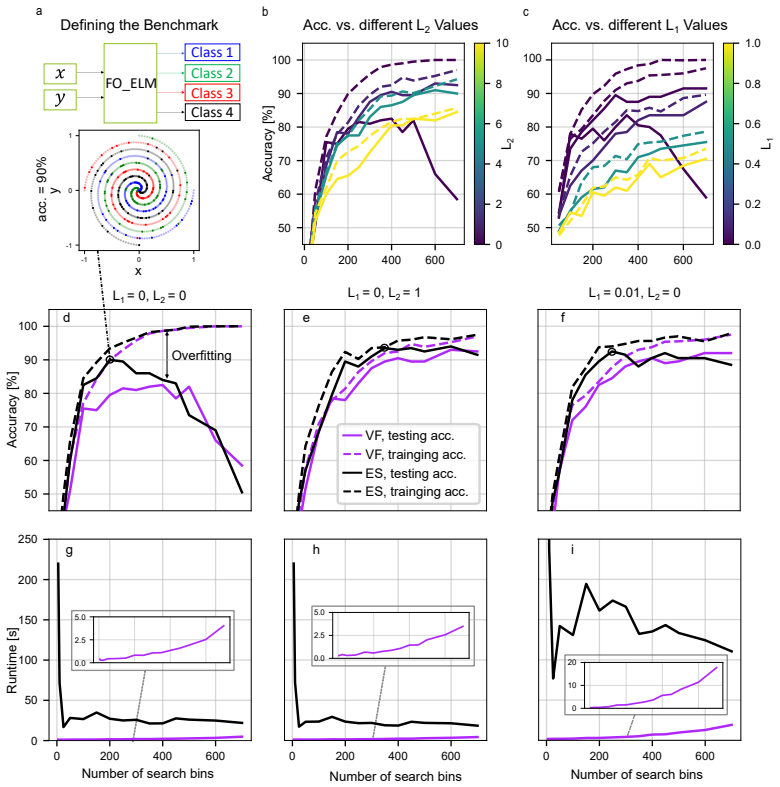
Enforcing readout selection across the full output spectrum improves performance, especially for non-iterative methods; L1 and L2 regularization significantly enhance performance on highly nonlinear tasks such as the Spiral Benchmark. These gains are obtained by comparing loss-minimizing search methods (Equal Search, Branch and Bound) against statistical filtering (Variance Filter) and random pruning, all applied to the output layer of a nonlinear fiber-optical extreme learning machine.
What carries the argument
Output pruning (Equal Search, Branch and Bound, Variance Filter) combined with L1 (LASSO) and L2 (ridge) regularization applied to the readout weights of the physical reservoir.
If this is right
- Informed output sampling becomes essential once the latent space of the reservoir shrinks.
- Regularization yields the largest lift precisely on tasks whose target function is highly nonlinear.
- Non-iterative training methods gain more from full-spectrum readout selection than iterative ones.
- Both pruning and regularization lower the computational cost of the training phase.
Where Pith is reading between the lines
- If the same pruning statistics hold across different physical media, a single set of selection rules could be ported between optical, electronic, and mechanical reservoirs.
- The variance-filter approach may interact with the specific spectrum of the physical nonlinearity, suggesting a platform-dependent tuning step that the paper leaves open.
- Extending the full-spectrum constraint to multi-layer or deep physical reservoirs could further reduce the need for iterative retraining.
Load-bearing premise
That the fiber-optical extreme learning machine used for experiments is representative of physical reservoirs in general and that the observed gains from pruning and regularization will transfer to other physical substrates without platform-specific retuning.
What would settle it
A controlled test on a second physical reservoir (for example a photonic or spin-wave device) in which the same pruning rules and regularization strengths produce no accuracy gain or a clear drop on the Spiral Benchmark.
Figures
read the original abstract
Reservoir computers benefit from the inherent complexity of optical phenomena, which provide rich, often nonlinear dynamics. However, training directly on the reservoir's output renders the system prone to overfitting and computationally inefficient during the training phase. In this work, we investigate strategies to mitigate overfitting and reduce computational overhead through output pruning and regularization. We compare loss-minimizing search methods (Equal Search and Branch and Bound) against an output-oriented statistical filtering approach (Variance Filter) and random pruning, highlighting advantages and disadvantages of each approach and the overall importance of informed reservoir output sampling, particularly for a shrinking latent space. We further demonstrate that enforcing readout selection across the full output spectrum improves performance, especially for non-iterative methods. Additionally, we examine L1 and L2 regularization techniques (LASSO and ridge regression), both of which significantly enhance performance on highly nonlinear tasks such as the Spiral Benchmark. While our methods are of general use, results are obtained from and discussed exemplarily for a nonlinear fiber-optical extreme learning machine. Overall, this study provides a deep analysis of the reservoirs' hidden-layer filtering mechanisms and the output-layer training, enabling optimized performance in physical reservoir computing systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines output pruning strategies (Equal Search, Branch and Bound, Variance Filter, and random pruning) and L1/L2 regularization (LASSO and ridge regression) to reduce overfitting and computational cost when training physical reservoir computers. Using a nonlinear fiber-optical extreme learning machine as the experimental platform, it reports that informed readout selection across the full output spectrum benefits non-iterative methods and that regularization improves performance on nonlinear benchmarks such as the Spiral task; the authors state that the methods are of general use while noting the results are obtained exemplarily on this substrate.
Significance. If the reported performance gains are reproducible and the pruning/regularization benefits prove transferable, the work would supply concrete, practical guidelines for training physical reservoirs that could reduce overfitting and training overhead in optical and other hardware implementations.
major comments (2)
- [Abstract] Abstract: the central claim that the described methods 'significantly enhance performance' and are 'of general use' is presented without any quantitative metrics, error bars, dataset sizes, or baseline comparisons, rendering the empirical contribution impossible to evaluate from the provided text.
- [Abstract] Abstract and closing paragraph: the assertion that the pruning and regularization principles are 'of general use' for physical reservoirs rests on results from a single fiber-optical ELM substrate; no cross-platform experiments, no ablation of substrate-specific dynamics (e.g., fiber nonlinearity versus other photonic or electronic reservoirs), and no theoretical derivation establishing platform independence are supplied, leaving transferability as an untested assumption that directly supports the broad applicability claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the abstract accordingly to improve clarity and precision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the described methods 'significantly enhance performance' and are 'of general use' is presented without any quantitative metrics, error bars, dataset sizes, or baseline comparisons, rendering the empirical contribution impossible to evaluate from the provided text.
Authors: We agree that the abstract would benefit from quantitative support. In the revised manuscript we will add specific metrics (e.g., accuracy improvements on the Spiral benchmark with LASSO/ridge regularization versus unregularized baselines, including standard deviations across repeated trials) together with dataset sizes and brief baseline comparisons. This will allow readers to evaluate the empirical contribution directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract and closing paragraph: the assertion that the pruning and regularization principles are 'of general use' for physical reservoirs rests on results from a single fiber-optical ELM substrate; no cross-platform experiments, no ablation of substrate-specific dynamics (e.g., fiber nonlinearity versus other photonic or electronic reservoirs), and no theoretical derivation establishing platform independence are supplied, leaving transferability as an untested assumption that directly supports the broad applicability claim.
Authors: The manuscript already qualifies the claim by stating that 'results are obtained from and discussed exemplarily for a nonlinear fiber-optical extreme learning machine.' We acknowledge that no cross-platform experiments or theoretical derivation of platform independence are provided, as the work focuses on training principles rather than exhaustive validation across substrates. In revision we will further tone down the phrasing in the abstract and closing paragraph to 'principles expected to be of general use for physical reservoir computers, demonstrated here on a fiber-optical ELM' to avoid implying untested universality while retaining the practical motivation. revision: yes
Circularity Check
No circularity: empirical methods with no derivations or self-referential reductions
full rationale
The manuscript applies standard statistical techniques (pruning via Equal Search, Branch and Bound, Variance Filter; L1/L2 regularization) to experimental data from a single fiber-optical ELM. No equations, derivations, or parameter-fitting steps are described that would reduce any claim to its own inputs by construction. The statement that methods are 'of general use' is an interpretive claim, not a load-bearing derivation that collapses into fitted values or self-citations. The paper is self-contained as an empirical study without the circular patterns enumerated in the analysis criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The unified Reservoir Computing concept and its digital hardware implementations,
Verstraeten, David and Schrauwen, Benjamin and D’Haene, Michiel and Stroobandt, Dirk, “The unified Reservoir Computing concept and its digital hardware implementations,” inProceedings of the 2006 EPFL LATSIS Symposium, (2006), pp. 139–140
2006
-
[2]
Reservoir computing approaches to recurrent neural network training,
M. Lukoševičius and H. Jaeger, “Reservoir computing approaches to recurrent neural network training,” Comput. Sci. Rev.3, 127–149
-
[3]
Real-time computing without stable states: A new framework for neural computation based on perturbations,
W. Maass, T. Natschläger, and H. Markram, “Real-time computing without stable states: A new framework for neural computation based on perturbations,” Neural Comput.14, 2531–2560 (2002)
2002
-
[4]
Recent advances in physical reservoir computing: A review,
G. Tanaka, T. Yamane, J. B. Héroux,et al., “Recent advances in physical reservoir computing: A review,” Neural Networks115, 100–123
-
[5]
Extreme learning machine: Theory and applications,
G.-B. Huang, Q.-Y. Zhu, and C.-K. Siew, “Extreme learning machine: Theory and applications,” Neurocomputing 70, 489–501 (2006). Neural Networks
2006
-
[6]
Robust forecasting using predictive generalized synchronization in reservoir computing,
J. A. Platt, A. Wong, R. Clark,et al., “Robust forecasting using predictive generalized synchronization in reservoir computing,” Chaos: An Interdiscip. J. Nonlinear Sci.31, 123118 (2021)
2021
-
[7]
Optimizing memory in reservoir computers,
T. L. Carroll, “Optimizing memory in reservoir computers,” Chaos: An Interdiscip. J. Nonlinear Sci.32, 023123 (2022)
2022
-
[9]
Embedding theory of reservoir computing and reducing reservoir network using time delays,
X.-Y. Duan, X. Ying, S.-Y. Leng,et al., “Embedding theory of reservoir computing and reducing reservoir network using time delays,” Phys. Rev. Res.5, L022041 (2023)
2023
-
[10]
Stable output feedback in reservoir computing using ridge regression,
F. Wyffels, B. Schrauwen, and D. Stroobandt, “Stable output feedback in reservoir computing using ridge regression,” inArtificialNeuralNetworks-ICANN2008,V.Kůrková,R.Neruda,andJ.Koutník,eds.(SpringerBerlinHeidelberg, Berlin, Heidelberg, 2008), pp. 808–817
2008
-
[11]
Photonic extreme learning machine by free-space optical propagation,
D. Pierangeli, G. Marcucci, and C. Conti, “Photonic extreme learning machine by free-space optical propagation,” Photon. Res.9, 1446
-
[12]
All-optical reservoir computing,
F. Duport, B. Schneider, A. Smerieri,et al., “All-optical reservoir computing,” Opt. Express20, 22783–22795 (2012)
2012
-
[13]
Multiplexed networks: reservoir computing with virtual and real nodes,
A. Röhm and K. Lüdge, “Multiplexed networks: reservoir computing with virtual and real nodes,” J. Phys. Commun. 2, 085007
-
[14]
Reconfigurable semiconductor laser networks based on diffractive coupling,
D. Brunner and I. Fischer, “Reconfigurable semiconductor laser networks based on diffractive coupling,” Opt. Lett. 40, 3854
-
[15]
Neuromorphiccomputingviafission-basedbroadbandfrequencygeneration,
B.Fischer,M.Chemnitz,Y.Zhu,etal.,“Neuromorphiccomputingviafission-basedbroadbandfrequencygeneration,” Adv. Sci.10, 2303835 (2023)
2023
-
[16]
Principlesandmetricsofextremelearningmachinesusingahighlynonlinear fiber,
M.Hary,D.Brunner,L.Leybov,etal.,“Principlesandmetricsofextremelearningmachinesusingahighlynonlinear fiber,” Nanophotonics14, 2733–2748 (2025)
2025
-
[17]
Principlesandmetricsofextremelearningmachinesusingahighlynonlinear fiber,
M.Hary,D.Brunner,L.Leybov,etal.,“Principlesandmetricsofextremelearningmachinesusingahighlynonlinear fiber,” Nanophotonics14, 2733–2748
-
[18]
Robust regularized extreme learning machine for regression using iteratively reweighted least squares,
K. Chen, Q. Lv, Y. Lu, and Y. Dou, “Robust regularized extreme learning machine for regression using iteratively reweighted least squares,” Neurocomputing230, 345–358 (2017)
2017
-
[19]
Pruning and regularization in reservoir computing,
X. Dutoit, B. Schrauwen, J. Van Campenhout,et al., “Pruning and regularization in reservoir computing,” Neurocom- puting72, 1534–1546
-
[20]
Adding filters to improve reservoir computer performance,
T. Carroll, “Adding filters to improve reservoir computer performance,” Phys. D: Nonlinear Phenom.416, 132798 (2021)
2021
-
[21]
Nonlinear inference capacity of fiber-optical extreme learning machines,
S. Saeed, M. Müftüoğlu, G. R. Cheeran,et al., “Nonlinear inference capacity of fiber-optical extreme learning machines,” Nanophotonics14, 2749–2760 (2025)
2025
-
[22]
On the partition of numbers,
G. B. Mathews, “On the partition of numbers,” Proc. Lond. Math. Soc.s1-28, 486–490 (1896)
-
[23]
An automatic method of solving discrete programming problems,
A. H. Land and A. G. Doig, “An automatic method of solving discrete programming problems,” Econometrica28, 497–520 (1960)
1960
-
[24]
Machine-aided near-transform-limited pulse compression in fully fiber-interconnected systems for efficient spectral broadening,
B. Fischer, M. Müftüoglu, and M. Chemnitz, “Machine-aided near-transform-limited pulse compression in fully fiber-interconnected systems for efficient spectral broadening,” inNonlinear Optics and its Applications 2024,vol. 13004 J. M. Dudley, A. C. Peacock, B. Stiller, and G. Tissoni, eds., International Society for Optics and Photonics (SPIE, 2024), p. 1300402
2024
-
[25]
Adaptive control of pulse phase in a chirped-pulse amplifier,
A. Efimov, M. D. Moores, N. M. Beach,et al., “Adaptive control of pulse phase in a chirped-pulse amplifier,” Opt. Lett.23, 1915–1917 (1998)
1915
-
[26]
Real-time reservoir computing network-based systems for detection tasks on visual contents,
A. Jalalvand, G. Van Wallendael, and R. Van De Walle, “Real-time reservoir computing network-based systems for detection tasks on visual contents,” in2015 7th International Conference on Computational Intelligence, Communication Systems and Networks,(IEEE), pp. 146–151
-
[27]
A multicriteria approach to find predictive and sparse models with stable feature selection for high-dimensional data,
A. Bommert, J. Rahnenführer, and M. Lang, “A multicriteria approach to find predictive and sparse models with stable feature selection for high-dimensional data,” Comput. Math. Methods Med.2017, 1–18
2017
-
[28]
Sensitivity-guided framework for pruned and quantized reservoir computing accelerators,
A. Jafari, M. Taheri, H. G. Mohammadi,et al., “Sensitivity-guided framework for pruned and quantized reservoir computing accelerators,”
-
[29]
A comprehensive study of random forest for short-term load forecasting,
G. Dudek, “A comprehensive study of random forest for short-term load forecasting,” Energies15, 7547
-
[30]
Random forest-driven photonic reservoir computing model for signal modulation recognition,
L. Zheng, S. Wen, P. Zhang,et al., “Random forest-driven photonic reservoir computing model for signal modulation recognition,” in2025 Photonics Global Conference (PGC),(IEEE), pp. 1–3
-
[31]
SVM–ELM: Pruning of extreme learning machine with support vector machines for regression,
S. F. Mahmood, M. H. Marhaban, F. Z. Rokhani,et al., “SVM–ELM: Pruning of extreme learning machine with support vector machines for regression,” J. Intell. Syst.25, 555–566
-
[32]
OP-ELM: Optimally pruned extreme learning machine,
Yoan Miche, A. Sorjamaa, P. Bas,et al., “OP-ELM: Optimally pruned extreme learning machine,” IEEE Trans. Neural Netw.21, 158–162
-
[33]
Novel and efficient randomized algorithms for feature selection,
Z. Wang, X. Xiao, and S. Rajasekaran, “Novel and efficient randomized algorithms for feature selection,” Big Data Min. Anal.3, 208–224
-
[34]
A. E. Hoerl and R. W. Kennard, “Ridge regression: Biased estimation for nonorthogonal problems,” Technometrics 12, 55–67. _eprint: https://doi.org/10.1080/00401706.1970.10488634
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.