Quality Is Not a Safety Proxy Under Quantization
Pith reviewed 2026-06-27 17:21 UTC · model grok-4.3
The pith
Quality retention does not ensure safety retention under model quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
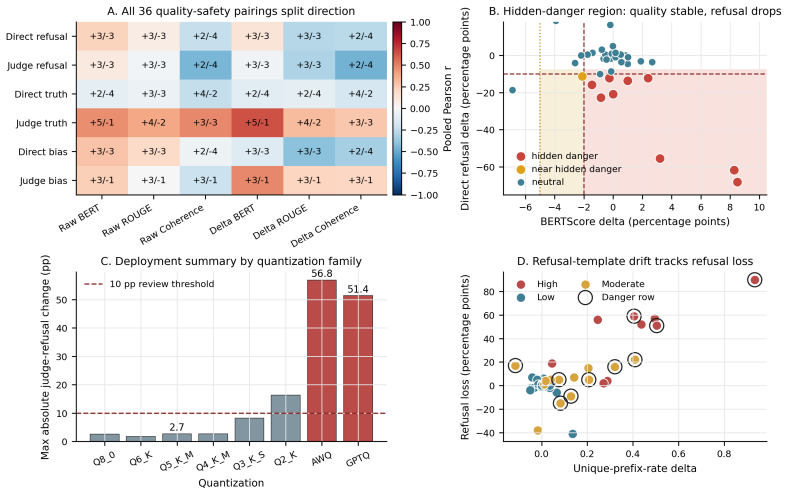
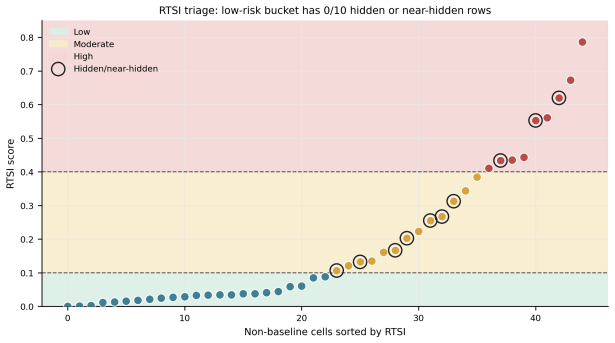
Across the quantized checkpoints, model families, and safety outcomes studied here, retained quality cannot waive direct safety evaluation. All 36 quality-safety pairings split direction across models; nine hidden-danger rows and one near-hidden-danger row keep quality stable or improved while refusal drops 12-68 points. Seven of eleven AWQ/GPTQ rows are hidden-danger. A four-probe mechanistic check on 17 FP16/AWQ/GPTQ cells finds entropy, refusal-direction, and calibration probes weak or null, and safety-associated neurons absorb more quantization error overall but not in a regime-specific way. The Refusal Template Stability Index, built from four refusal-template drift features and calibra
What carries the argument
The hidden-danger classification (quality stable or improved while refusal on a predefined harmful-prompt set falls sharply) together with the Refusal Template Stability Index that flags rows for direct safety testing.
If this is right
- Direct safety evaluation remains necessary even when quality metrics are retained after quantization.
- The RTSI routes every hidden- or near-hidden-danger row to safety testing while keeping most other rows low-risk.
- Single-feature baselines recover fewer hidden-danger rows than the calibrated RTSI at matched bucket size.
- Cross-stack transfer of the RTSI requires recalibration on the new matrix.
Where Pith is reading between the lines
- The same quality-safety divergence could appear in untested quantization methods or larger model scales.
- Safety checks might need to move earlier in the quantization pipeline rather than after quality screening.
- Judge-model disagreement on refusal labels could shift hidden-danger counts in follow-up studies.
Load-bearing premise
The refusal rate on the paper's predefined harmful-prompt set is treated as a stable proxy for real-world safety behavior.
What would settle it
A new harmful-prompt distribution or different judge model that reverses the hidden-danger labels on the same quantized checkpoints.
Figures

read the original abstract
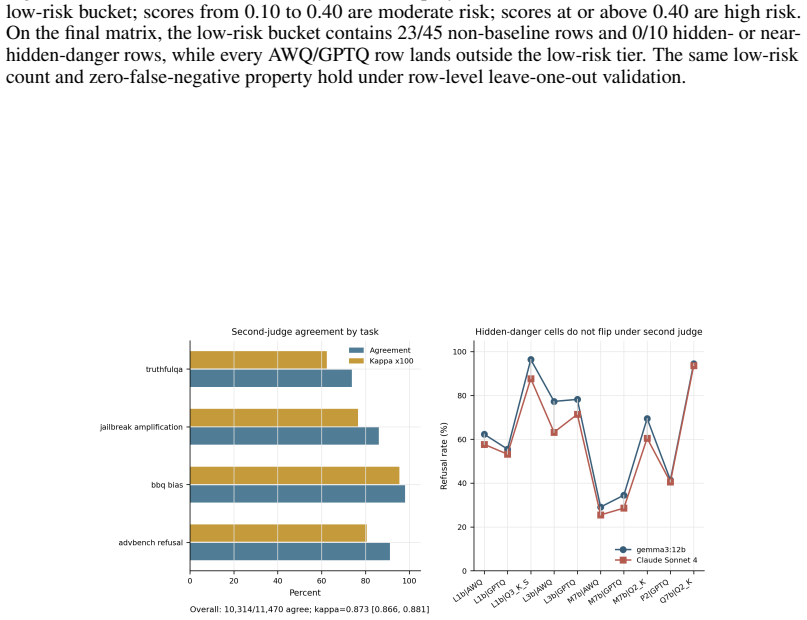
Quantized checkpoints are often screened first with quality metrics and only later, if at all, with direct safety tests. This paper audits that shortcut on a matched 51-row matrix spanning 6 models, 4 families, a 7-level GGUF ladder, and AWQ/GPTQ INT4 checkpoints. In this matrix the shortcut fails: all 36 quality-safety pairings split direction across models, and 9 hidden-danger rows plus 1 near-hidden-danger row show quality stable or improved while refusal falls by 12-68 percentage points. Seven of the 11 AWQ/GPTQ rows are hidden-danger. A four-probe mechanistic follow-up over the 17 Hugging Face-backed FP16/AWQ/GPTQ cells does not rescue it: entropy, refusal-direction, and calibration probes are weak or null separators of dangerous rows, and although probe-identified safety-associated neurons absorb 1.39$\times$ more quantization error overall ($p < 5 \times 10^{-7}$), the effect is not regime-specific. Claude Sonnet 4 relabels 11,470 items in a predefined stratified set, agrees with the primary gemma3:12b judge on 89.9\% of rows ($\kappa = 0.873$, 95\% CI [0.866, 0.881]), and changes 0/10 hidden-danger cells. A calibrated study-internal behavioral screen -- the Refusal Template Stability Index (RTSI), built from four refusal-template drift features and calibrated on this matrix -- routes 10/10 hidden- or near-hidden-danger rows to direct safety testing (Wilson 95\% CI lower bound 0.72) while leaving 23 of 45 non-baseline rows in a low-risk bucket under both in-sample scoring and row-level leave-one-out validation; on the same matrix, the best single-feature baselines (unique-prefix-rate-delta, raw refusal-rate delta) recover 9/10 and 8/10 respectively at matched bucket size, and cross-stack transfer requires recalibration. For the quantized checkpoints, model families, and safety outcomes studied here, retained quality cannot waive direct safety evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This manuscript audits the common practice of screening quantized LLMs first with quality metrics before (or instead of) direct safety tests. Using a matched 51-row matrix across 6 models, 4 families, a 7-level GGUF ladder, and AWQ/GPTQ INT4 checkpoints, it reports that all 36 quality-safety direction pairings split across models, with 9 hidden-danger rows (plus 1 near-hidden) in which quality is stable or improved while refusal rates on a stratified harmful-prompt set drop 12-68 pp. Mechanistic probes (entropy, refusal-direction, calibration) on the 17 HF-backed cells fail to separate dangerous rows, although safety-associated neurons absorb 1.39× more quantization error overall (p < 5×10^{-7}) without regime specificity. A study-internal Refusal Template Stability Index (RTSI) calibrated on the matrix routes 10/10 hidden/near-hidden rows to safety testing (Wilson lower bound 0.72) under both in-sample and leave-one-out validation while leaving 23/45 non-baseline rows low-risk; cross-judge validation with Claude Sonnet 4 yields κ=0.873 and zero flips among the 10 critical cells. The central conclusion is that, for the quantized checkpoints, model families, and safety outcomes studied here, retained quality cannot waive direct safety evaluation.
Significance. If the reported divergence holds under the paper's measurement protocol, the work supplies concrete, statistically supported evidence against a widespread deployment shortcut. Strengths include the matched-matrix design, the p < 5×10^{-7} neuron-error result, the 89.9 % cross-judge agreement with no change to hidden-danger classifications, and the explicit leave-one-out check on RTSI. The finding is scoped to the studied models and prompt set, which appropriately limits over-claim while still challenging current practice. The mechanistic follow-up, although null for separation, usefully documents the limits of those particular probes.
major comments (2)
- [Abstract / hidden-danger rows] Abstract and hidden-danger identification paragraph: the 9 hidden-danger rows are defined solely by refusal-rate drops on the paper's fixed stratified harmful-prompt set (scored by gemma3:12b). While the Claude Sonnet 4 relabeling (89.9 % agreement, 0/10 flips) is reassuring, the core quality-safety divergence claim remains sensitive to prompt distribution or judge-model choice; a sensitivity table varying either factor would directly test robustness of the 12-68 pp deltas.
- [RTSI description and validation] RTSI calibration and routing paragraph: feature weights and the decision threshold are fitted to the same 51-row matrix used for evaluation. Although row-level leave-one-out validation is reported and the paper notes that cross-stack transfer requires recalibration, the 10/10 routing performance is still partly in-sample; an external held-out model family would strengthen the practical claim that RTSI can reliably triage future checkpoints.
minor comments (2)
- [RTSI validation] The Wilson 95 % CI lower bound of 0.72 for the 10/10 routing is stated without the underlying binomial parameters or exact proportion; adding the calculation details (n, k, method) would improve reproducibility.
- [Results matrix] Table or matrix presentation: the 51-row matrix would benefit from an explicit column or annotation marking the 9 hidden-danger and 1 near-hidden rows to allow readers to trace the direction-split counts without cross-referencing text.
Simulated Author's Rebuttal
We thank the referee for the detailed and positive review. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract / hidden-danger rows] Abstract and hidden-danger identification paragraph: the 9 hidden-danger rows are defined solely by refusal-rate drops on the paper's fixed stratified harmful-prompt set (scored by gemma3:12b). While the Claude Sonnet 4 relabeling (89.9 % agreement, 0/10 flips) is reassuring, the core quality-safety divergence claim remains sensitive to prompt distribution or judge-model choice; a sensitivity table varying either factor would directly test robustness of the 12-68 pp deltas.
Authors: The manuscript already includes substantial validation through cross-judge agreement with Claude Sonnet 4 (89.9% agreement, κ=0.873, zero flips on the 10 critical cells). This directly tests judge-model choice. For prompt distribution sensitivity, we agree it would be informative. However, the stratified prompt set is fixed and designed to cover a range of harm types. We will add a brief sensitivity discussion using prompt subsets in the revision to address this. revision: partial
-
Referee: [RTSI description and validation] RTSI calibration and routing paragraph: feature weights and the decision threshold are fitted to the same 51-row matrix used for evaluation. Although row-level leave-one-out validation is reported and the paper notes that cross-stack transfer requires recalibration, the 10/10 routing performance is still partly in-sample; an external held-out model family would strengthen the practical claim that RTSI can reliably triage future checkpoints.
Authors: We agree that the RTSI is calibrated in-sample. The row-level leave-one-out validation and the explicit statement that cross-stack transfer requires recalibration are already present in the manuscript. While an external held-out model family would provide additional evidence, the current study spans 4 families and 6 models, and the LOO results support the method within this scope. We will clarify the in-sample nature more explicitly in the revision. revision: partial
Circularity Check
RTSI routing performance is calibrated on the evaluation matrix
specific steps
-
fitted input called prediction
[Abstract]
"A calibrated study-internal behavioral screen -- the Refusal Template Stability Index (RTSI), built from four refusal-template drift features and calibrated on this matrix -- routes 10/10 hidden- or near-hidden-danger rows to direct safety testing (Wilson 95% CI lower bound 0.72) while leaving 23 of 45 non-baseline rows in a low-risk bucket under both in-sample scoring and row-level leave-one-out validation"
RTSI features and calibration are derived from the same matrix that defines the hidden-danger rows and on which routing performance is measured; the reported 10/10 success is therefore a fitted outcome on the calibration data even after LOO, rather than an independent prediction.
full rationale
The paper's central claim (quality fails as safety proxy due to 9 hidden-danger rows) is a direct empirical observation from the 51-row matrix and does not depend on RTSI. RTSI itself is calibrated on the identical matrix to detect those rows and its 10/10 routing (with LOO) is presented as a result, matching the fitted_input_called_prediction pattern for that auxiliary component. No self-citations, self-definitional equations, or other load-bearing circular steps appear. The core derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- RTSI feature weights and decision threshold
axioms (1)
- domain assumption Refusal rate on the paper's harmful-prompt set is a valid proxy for safety behavior
invented entities (1)
-
Refusal Template Stability Index (RTSI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Refusal in language models is mediated by a single direction.arXiv preprint arXiv:2406.11717, 2024
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction.arXiv preprint arXiv:2406.11717, 2024. URLhttps://arxiv.org/abs/2406.11717
Pith/arXiv arXiv 2024
-
[2]
Colin R. Blyth. On Simpson’s paradox and the sure-thing principle.Journal of the American Statistical Association, 67(338):364–366, 1972
1972
-
[3]
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. JailbreakBench: An open robustness benchmark for jailbreaking large language models. InAdvances in Neural Information Processing Systems 37 (Datasets ...
-
[4]
Vishnu Kabir Chhabra and Mohammad Mahdi Khalili. Towards understanding and improving refusal in compressed models via mechanistic interpretability.arXiv preprint arXiv:2504.04215, 2025. URLhttps://arxiv.org/abs/2504.04215. 9
arXiv 2025
-
[5]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018. URL https://arxiv.org/abs/1803.05457
Pith/arXiv arXiv 2018
-
[6]
QLoRA: Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. InAdvances in Neural Information Processing Systems 36,
-
[7]
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1feb87871436031bdc0f2beaa62a049b-Abstract-Conference.html
2023
-
[8]
Hongzhe Du, Weikai Li, Min Cai, Karim Saraipour, Zimin Zhang, Himabindu Lakkaraju, Yizhou Sun, and Shichang Zhang. How post-training reshapes LLMs: A mechanistic view on knowledge, truthfulness, refusal, and confidence.arXiv preprint arXiv:2504.02904, 2025. URL https://arxiv.org/abs/2504.02904
arXiv 2025
-
[9]
Hashimoto
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. AlpacaFarm: A simulation framework for methods that learn from human feedback. InAdvances in Neural Information Processing Systems 36, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 5fc47800e...
2023
-
[11]
URLhttps://arxiv.org/abs/2404.04475
-
[12]
Spurious correlations in reference-free evaluation of text generation
Esin Durmus, Faisal Ladhak, and Tatsunori Hashimoto. Spurious correlations in reference-free evaluation of text generation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1443–1454. Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022.acl-long.102. URL https://acla...
-
[13]
Exploiting LLM quantization.arXiv preprint arXiv:2405.18137, 2024
Kazuki Egashira, Mark Vero, Robin Staab, Jingxuan He, and Martin Vechev. Exploiting LLM quantization.arXiv preprint arXiv:2405.18137, 2024. URL https://arxiv.org/abs/2405.18137
arXiv 2024
-
[14]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022. URLhttps://arxiv.org/abs/2210.17323
Pith/arXiv arXiv 2022
-
[15]
GGML: Tensor library for machine learning, 2023
Georgi Gerganov. GGML: Tensor library for machine learning, 2023. URL https://github.com/ggerganov/ggml. GitHub repository
2023
-
[16]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[17]
Bartoldson, Ajay Kumar Jaiswal, Kaidi Xu, Bhavya Kailkhura, Dan Hendrycks, Dawn Song, Zhangyang Wang, and Bo Li
Junyuan Hong, Jinhao Duan, Chenhui Zhang, Zhangheng Li, Chulin Xie, Kelsey Lieberman, James Diffenderfer, Brian R. Bartoldson, Ajay Kumar Jaiswal, Kaidi Xu, Bhavya Kailkhura, Dan Hendrycks, Dawn Song, Zhangyang Wang, and Bo Li. Decoding compressed trust: Scrutinizing the trustworthiness of efficient LLMs under compression. InProceedings of the 41st Intern...
2024
-
[18]
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. BeaverTails: Towards improved safety alignment of LLM via a human-preference dataset.arXiv preprint arXiv:2307.04657, 2023. URL https://arxiv.org/abs/2307.04657. 10
arXiv 2023
-
[19]
Artyom Kharinaev, Viktor Moskvoretskii, Egor Shvetsov, Kseniia Studenikina, Mikhail Bykov, and Evgeny Burnaev. Investigating the impact of quantization methods on the safety and reliability of large language models.arXiv preprint arXiv:2502.15799, 2025. URL https://arxiv.org/abs/2502.15799
arXiv 2025
-
[20]
Scaling laws for precision
Tanishq Kumar, Mansheej Paul, and Aditi Raghunathan. Scaling laws for precision. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=wg1PCg3CUP
2025
-
[21]
Daniël Lakens. Equivalence tests: A practical primer fort-tests, correlations, and meta-analyses.Social Psychological and Personality Science, 8(4):355–362, 2017. doi: 10.1177/1948550617697177
-
[22]
Li, Satyapriya Krishna, and Himabindu Lakkaraju
Aaron J. Li, Satyapriya Krishna, and Himabindu Lakkaraju. More RLHF, more trust? on the impact of preference alignment on trustworthiness. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=FpiCLJrSW8
2025
-
[23]
Holistic evaluation of language models
Percy Liang, Rishi Bommasani, Tony Lee, et al. Holistic evaluation of language models. Transactions on Machine Learning Research, 2023. URL https://openreview.net/forum?id=iO4LZibEqW
2023
-
[24]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out, 2004. URLhttps://aclanthology.org/W04-1013/
2004
-
[25]
AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration.Proceedings of Machine Learning and Systems, 6, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration.Proceedings of Machine Learning and Systems, 6, 2024. URL https://proceedings.mlsys.org/paper_files/paper/2024/hash/ 42a452cbafa9dd64e9...
2024
-
[26]
T ruthful QA : Measuring How Models Mimic Human Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252. Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022.acl-long.229. URL https://aclanthology.org/2022.acl...
-
[27]
HarmBench: A standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machi...
2024
-
[28]
BBQ : A hand-built bias benchmark for question answering
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thompson, Phu Mon Htut, and Samuel Bowman. BBQ: A hand-built bias benchmark for question answering. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2086–2105. Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022.findings-acl.1...
-
[29]
Comment: Understanding Simpson’s paradox.The American Statistician, 68(1): 8–13, 2014
Judea Pearl. Comment: Understanding Simpson’s paradox.The American Statistician, 68(1): 8–13, 2014
2014
-
[30]
Irina Proskurina, Luc Brun, Guillaume Metzler, and Julien Velcin. When quantization affects confidence of large language models?Findings of the Association for Computational Linguistics: NAACL 2024, pages 1918–1928, 2024. doi: 10.18653/v1/2024.findings-naacl.124. URLhttps://aclanthology.org/2024.findings-naacl.124/
-
[31]
Safety alignment should be made more than just a few tokens deep
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, and Peter Henderson. Safety alignment should be made more than just a few tokens deep. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=6Mxhg9PtDE. 11
2025
-
[32]
Richard Ren, Steven Basart, Adam Khoja, Alexander Pan, Alice Gatti, Long Phan, Xuwang Yin, Mantas Mazeika, Gabriel Mukobi, Ryan Hwang Kim, Stephen Fitz, and Dan Hendrycks. Safetywashing: Do AI safety benchmarks actually measure safety progress? InAdvances in Neural Information Processing Systems 37 (Datasets and Benchmarks Track), 2024. doi: 10.52202/0790...
-
[33]
Olawale Salaudeen, Anka Reuel, Ahmed Ahmed, Suhana Bedi, Zachary Robertson, Sudharsan Sundar, Ben Domingue, Angelina Wang, and Sanmi Koyejo. Measurement to meaning: A validity-centered framework for AI evaluation.arXiv preprint arXiv:2505.10573, 2025. URL https://arxiv.org/abs/2505.10573
arXiv 2025
-
[34]
Edward H. Simpson. The interpretation of interaction in contingency tables.Journal of the Royal Statistical Society: Series B (Methodological), 13(2):238–241, 1951
1951
-
[35]
Qitao Tan, Xiaoying Song, Ningxi Cheng, Ninghao Liu, Xiaoming Zhai, Lingzi Hong, Yanzhi Wang, Zhen Xiang, and Geng Yuan. Q-realign: Piggybacking realignment on quantization for safe and efficient LLM deployment.arXiv preprint arXiv:2601.08089, 2026. URL https://arxiv.org/abs/2601.08089
arXiv 2026
-
[36]
Reliable and efficient amortized model-based evaluation.arXiv preprint arXiv:2503.13335, 2025
Sang Truong, Yuheng Tu, Percy Liang, Bo Li, and Sanmi Koyejo. Reliable and efficient amortized model-based evaluation.arXiv preprint arXiv:2503.13335, 2025. URL https://arxiv.org/abs/2503.13335
arXiv 2025
-
[37]
Safety-preserving PTQ via contrastive alignment loss.arXiv preprint arXiv:2511.07842, 2025
Sunghyun Wee, Suyoung Kim, Hyeonjin Kim, Kyomin Hwang, and Nojun Kwak. Safety-preserving PTQ via contrastive alignment loss.arXiv preprint arXiv:2511.07842, 2025. URLhttps://arxiv.org/abs/2511.07842
arXiv 2025
-
[38]
Assessing the brittleness of safety alignment via pruning and low-rank modifications
Boyi Wei, Kaixuan Huang, Yangsibo Huang, Tinghao Xie, Xiangyu Qi, Mengzhou Xia, Prateek Mittal, Mengdi Wang, and Peter Henderson. Assessing the brittleness of safety alignment via pruning and low-rank modifications. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 52588–52...
2024
-
[39]
Laura Weidinger, Joslyn Barnhart, Jenny Brennan, Christina Butterfield, Susie Young, Will Hawkins, Lisa Anne Hendricks, Ramona Comanescu, Oscar Chang, Mikel Rodriguez, Jennifer Beroshi, Dawn Bloxwich, Lev Proleev, Jilin Chen, Sebastian Farquhar, Lewis Ho, Iason Gabriel, Allan Dafoe, and William Isaac. Holistic safety and responsibility evaluations of adva...
arXiv 2024
-
[40]
SmoothQuant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 38087–38099. PMLR, 2023. URL https://proceedings.mlr.p...
2023
-
[41]
Beyond perplexity: Multi-dimensional safety evaluation of LLM compression
Zhichao Xu, Ashim Gupta, Tao Li, Oliver Bentham, and Vivek Srikumar. Beyond perplexity: Multi-dimensional safety evaluation of LLM compression. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15359–15396. Association for Computational Linguistics, 2024. doi: 10.18653/v1/2024.findings-emnlp.901. URL https://aclanthology.org/2...
-
[42]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. BERTScore: Evaluating text generation with BERT. InInternational Conference on Learning Representations, 2020. URLhttps://openreview.net/forum?id=SkeHuCVFDr
2020
-
[43]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-bench and chatbot arena. InAdvances in Neural 12 Information Processing Systems 36 (Datasets and Benchmarks Track), 2023. URL https://proceedings.neu...
2023
-
[44]
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. A survey on model compression for large language models.Transactions of the Association for Computational Linguistics, 12: 1556–1577, 2024. doi: 10.1162/tacl_a_00704. URL https://aclanthology.org/2024.tacl-1.85/
-
[45]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. URLhttps://arxiv.org/abs/2307.15043. A Ethical Considerations, Data Availability, and Disclosures A.1 Ethical Considerations This paper analyzes quality an...
Pith/arXiv arXiv 2023
-
[46]
Claims.Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope?Answer:Yes.Justification:The abstract and §1 describe the study as a scoped proxy-validity audit over a matched 51-row matrix, and every headline number (36/36 sign splits, 9 hidden-danger + 1 near-hidden row, 7/11 AWQ/GPTQ rows, RTSI low...
-
[47]
Limitations.Does the paper discuss the limitations of the work performed by the authors? Answer:Yes.Justification:§5 enumerates the 6-model / 4-family / ≤7B coverage limitation, the within-stack conclusion, the judge-family overlap, the RTSI row-level-LOOCV-only calibration, and the benchmark-breadth future work
-
[48]
Theory assumptions and proofs.For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?Answer:NA.Justification:The paper contains no theoretical theorems; all claims are empirical over the 51-row matrix
-
[49]
Experimental result reproducibility.Does the paper fully disclose all the information needed to reproduce the main experimental results to the extent that it affects the main claims?Answer:Partial.Justification:§3 documents the matched-matrix construction, task slices, quantization pipeline, and judge configuration, and the reproduction package (via scrip...
-
[50]
Open access to data and code.Does the paper provide open access to data and code, with sufficient instructions to faithfully reproduce the main experimental results?Answer:Partial. Justification:Aggregated evaluation outputs, second-judge relabellings, mechanistic-probe statistics, and the analysis harness are released in the reproducibility bundle descri...
-
[51]
Experimental setting/details.Does the paper specify all training and test details (splits, hyperparameters, optimizer, etc.) necessary to understand the results?Answer:Yes. Justification:§3 and §3.1 specify task prompts per cell, the GGUF ladder, AWQ and GPTQ INT4 configurations, decoding settings, and judge prompts; the submission-materials appendix list...
-
[52]
Experiment statistical significance.Does the paper report error bars or confidence intervals or statistical significance tests?Answer:Yes.Justification:§4 reports second-judge Cohen’s κ with a 95% bootstrap CI, the safety-neuron quantization-error effect withp= 4.89×10 −7, and sign-heterogeneity across all 36 quality–safety pairings; RTSI screening is val...
-
[53]
Experiments compute resources.Does the paper provide sufficient compute detail to reproduce the experiments?Answer:Yes.Justification:§A.6 in the submission-materials appendix lists the RTX 4080 Laptop + RTX 6000 Ada split, the per-phase GPU-hours (40 + 35 + 15 + 12 GPU-hours), and the approximate $25 Claude Sonnet 4 API cost
-
[54]
Code of ethics.Does the research conform with the NeurIPS Code of Ethics in every respect?Answer:Yes.Justification:The Ethics subsection in §A.11 documents the use of publicly released harmful-prompt suites without introducing new harmful content, researcher-credit-account API usage, and the absence of human subjects
-
[55]
safety-passed
Broader impacts.Does the paper discuss both potential positive and negative societal impacts?Answer:Yes.Justification:The Broader Impact subsection in §A.11 names the positive outcome (deployment triage against quality-as-safety-proxy substitution) and the negative risk (RTSI misuse as a general “safety-passed” stamp outside the studied matrix)
-
[56]
Safeguards.Does the paper describe safeguards for responsible release of high-misuse- risk data or models?Answer:Yes.Justification:§A.11 and the submission-materials appendix state that the reproduction package releases aggregated refusal, truthfulness, and bias-resistance statistics only; no verbatim harmful completions are redistributed, and harmful-pro...
-
[57]
Licenses for existing assets.Are creators/original owners of used assets properly credited with license and terms of use?Answer:Yes.Justification: refs.bib cites the AdvBench, TruthfulQA, BBQ, BERTScore, ROUGE, AutoAWQ, AutoGPTQ, andllama.cpp/Ollama sources used in the pipeline described in §3; model-card license terms are inherited from the upstream Hugg...
-
[58]
New assets.Are new assets introduced in the paper well documented?Answer:Yes. Justification:The new assets are the 51-row quality–safety matrix, the RTSI screening heuristic, and the four-probe mechanistic follow-up outputs; all three are described in §3, §4.4, and the submission-materials appendix, and are packaged by the reproducibility bundle builder c...
-
[59]
Crowdsourcing and human subjects.For crowdsourcing and research with human subjects, does the paper include instructions, screenshots, and compensation details?Answer:NA. Justification:No crowdsourcing or human-subjects data collection was performed; LLM judges (gemma3:12b primary, Claude Sonnet 4 secondary) are methodological infrastructure, not human raters
-
[60]
IRB approvals.Does the paper describe potential participant risks, disclosure, and IRB (or equivalent) approvals?Answer:NA.Justification:No human subjects were involved, so no IRB review was required, as stated in the Ethics subsection of §A.11. 20
-
[61]
LLM usage.Does the paper declare LLM usage if it is an important, original, or non- standard component of the core methods?Answer:Yes.Justification:The primary judge gemma3:12b and the Claude Sonnet 4 second judge are core methodological components declared in §3 and §4; agreement,κ, and cell-level regime stability are reported explicitly. 21
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.