τ-Rec: A Verifiable Benchmark for Agentic Recommender Systems
Pith reviewed 2026-06-27 14:24 UTC · model grok-4.3
The pith
A verifiable benchmark for agentic recommender systems shows even top models reach only 57% success on first attempt and 38% by the fourth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
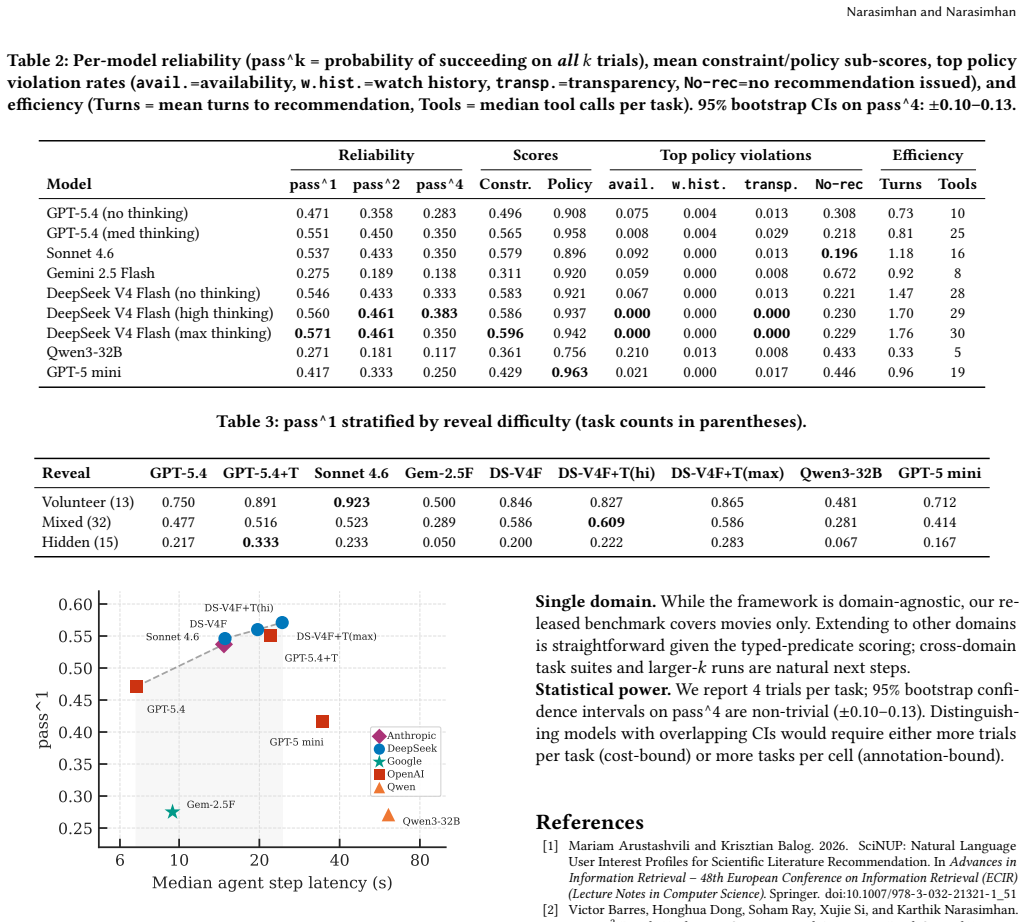
By testing agents against structured catalog predicates and employing a pass^k reliability metric, τ-Rec provides a systematic test for consistent reasoning that replaces subjective evaluation with verifiable rewards and a reveal-tagged elicitation mechanism, revealing a steep reliability cliff where even the best model achieves only ~57% at pass^1 and ~38% at pass^4.
What carries the argument
The τ-Rec benchmark with its verifiable rewards, reveal-tagged elicitation (RTE) mechanism for controlling constraint surfacing, structured catalog predicates, and pass^k metric for measuring multi-attempt reliability.
If this is right
- Agent evaluations should shift toward verifiable, predicate-based rewards to reduce inconsistency from subjective judgments.
- Model development must target improved consistency in multi-turn reasoning over recommendation constraints.
- Reliability metrics like pass^k can guide deployment decisions by quantifying how often agents reach correct outcomes across attempts.
- The benchmark's public code and data enable standardized comparisons across future model families.
Where Pith is reading between the lines
- If the benchmark's tasks prove representative, progress on agentic recommenders may require new training objectives focused on predicate satisfaction rather than open dialogue generation.
- The observed reliability cliff could extend to other structured agent tasks such as multi-step planning where partial information is revealed incrementally.
- Adoption of similar RTE-style controls might improve evaluation in adjacent areas like conversational search or personalized assistants.
Load-bearing premise
The structured catalog predicates and reveal-tagged elicitation mechanism produce tasks whose difficulty and coverage match the real constraints that arise in deployed agentic recommender systems.
What would settle it
A direct comparison where models that score low on τ-Rec still succeed reliably in production conversational recommendation deployments, or where high-scoring models fail in those same deployments, would test whether the benchmark captures actual performance gaps.
Figures
read the original abstract
As recommender systems transition toward agentic, multi-turn conversational interfaces, evaluation paradigms have struggled to keep pace. Current benchmarks often rely on "LLM-as-a-judge" evaluations, which introduce subjectivity, high costs and inconsistency. We present $\tau$-Rec, a benchmark for agentic recommender systems that replaces subjective evaluation with verifiable rewards and a reveal-tagged elicitation (RTE) mechanism that controls how task constraints surface during dialogue. By testing agents against structured catalog predicates and employing a pass^k reliability metric, $\tau$-Rec provides a systematic test for consistent reasoning. Our evaluation of nine configurations across five model families -- GPT-5.4, Claude Sonnet 4.6, Gemini 2.5 Flash, DeepSeek V4 Flash, Qwen3-32B and GPT-5 mini -- reveals a steep reliability cliff, where even the best model achieves only ~57% at pass^1 and ~38% at pass^4, highlighting a critical gap in current conversational agent deployment. All code and data are publicly available at https://github.com/nbharaths/tau-rec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces τ-Rec, a benchmark for agentic recommender systems that uses verifiable rewards derived from structured catalog predicates together with a reveal-tagged elicitation (RTE) mechanism to control how constraints are revealed across dialogue turns. It defines a pass^k reliability metric and reports empirical results on nine configurations spanning five model families, finding that the strongest model reaches only ~57% at pass^1 and ~38% at pass^4.
Significance. If the benchmark tasks are representative, the work supplies an objective, reproducible alternative to LLM-as-a-judge evaluation and publicly releases code and data, which are concrete strengths. The pass^k metric is a useful addition for quantifying consistency in multi-turn agent behavior.
major comments (1)
- [Benchmark construction and evaluation sections] The headline claim of a 'critical gap in current conversational agent deployment' (abstract) is load-bearing on the assumption that tasks generated from the structured catalog predicates and RTE mechanism match the difficulty, constraint distribution, and multi-turn dynamics of real deployed systems. The manuscript supplies no external validation (e.g., comparison against logged production dialogues, human solvability rates, or coverage statistics against actual catalogs) that would establish this representativeness; without it the reported pass^k figures cannot be unambiguously attributed to model shortcomings versus benchmark construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the representativeness of the τ-Rec benchmark. We address the major comment below and outline targeted revisions.
read point-by-point responses
-
Referee: [Benchmark construction and evaluation sections] The headline claim of a 'critical gap in current conversational agent deployment' (abstract) is load-bearing on the assumption that tasks generated from the structured catalog predicates and RTE mechanism match the difficulty, constraint distribution, and multi-turn dynamics of real deployed systems. The manuscript supplies no external validation (e.g., comparison against logged production dialogues, human solvability rates, or coverage statistics against actual catalogs) that would establish this representativeness; without it the reported pass^k figures cannot be unambiguously attributed to model shortcomings versus benchmark construction.
Authors: We agree that external validation against production logs or human solvability rates would strengthen claims of real-world relevance. The benchmark is intentionally synthetic to enable fully verifiable rewards from catalog predicates, which directly addresses the subjectivity of LLM-as-a-judge methods. Tasks are constructed from common e-commerce constraints (price, category, attribute filters) that appear in public datasets and deployed systems, with RTE controlling revelation to simulate multi-turn dynamics. However, we do not claim the distribution exactly matches any specific production catalog. We will revise the abstract to replace the 'critical gap in current conversational agent deployment' phrasing with a more precise statement focused on consistent reasoning reliability under verifiable conditions, add an explicit Limitations subsection discussing the synthetic nature and absence of production-log comparisons, and include coverage statistics relative to public catalog benchmarks. These changes will make the scope and attribution of the pass^k results clearer without requiring new external data. revision: partial
Circularity Check
No circularity: empirical benchmark results with explicitly defined metrics
full rationale
The paper introduces a new benchmark (τ-Rec) with RTE mechanism, structured catalog predicates, and pass^k metric, then reports direct empirical measurements of model performance on public LLMs. No derivation, equation, or prediction reduces to a fitted parameter, self-defined quantity, or self-citation chain. The central claims are measurements (~57% pass^1, ~38% pass^4), not derivations that collapse to inputs by construction. Self-citations, if present, are not load-bearing for the reported results. This matches the default expectation of a non-circular empirical evaluation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structured catalog predicates can be used as objective, machine-checkable task constraints for recommender dialogues.
Reference graph
Works this paper leans on
-
[1]
Mariam Arustashvili and Krisztian Balog. 2026. SciNUP: Natural Language User Interest Profiles for Scientific Literature Recommendation. InAdvances in Information Retrieval – 48th European Conference on Information Retrieval (ECIR) (Lecture Notes in Computer Science). Springer. doi:10.1007/978-3-032-21321-1_51
-
[2]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan
-
[3]
arXiv:2506.07982 [cs.AI] https://arxiv.org/abs/2506.07982
𝜏 2-Bench: Evaluating Conversational Agents in a Dual-Control Environ- ment. arXiv:2506.07982 [cs.AI] https://arxiv.org/abs/2506.07982
-
[4]
Nolwenn Bernard and Krisztian Balog. 2025. Limitations of Current Evaluation Practices for Conversational Recommender Systems and the Potential of User Simulation. InProceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region (SIGIR-AP ’25). 261–271. doi:10.1145/3767695.3769478
-
[5]
Nolwenn Bernard and Krisztian Balog. 2026. UserSimCRS v2: Simulation-Based Evaluation for Conversational Recommender Systems. InAdvances in Information Retrieval – 48th European Conference on Information Retrieval (ECIR) (Lecture Notes in Computer Science). Springer
2026
-
[6]
Nolwenn Bernard, Hideaki Joko, Faegheh Hasibi, and Krisztian Balog. 2025. CRS Arena: Crowdsourced Benchmarking of Conversational Recommender Systems. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining (WSDM ’25). 1028–1031. doi:10.1145/3701551.3704120
-
[7]
Luyu Chen, Quanyu Dai, Zeyu Zhang, Xueyang Feng, Mingyu Zhang, Pengcheng Tang, Xu Chen, Yue Zhu, and Zhenhua Dong. 2025. RecUserSim: A Realistic and Diverse User Simulator for Evaluating Conversational Recommender Systems. InCompanion Proceedings of the ACM Web Conference 2025 (WWW Companion ’25). 133–142. doi:10.1145/3701716.3715258
-
[8]
Shirley Anugrah Hayati, Dongyeop Kang, Qingxiaoyang Zhu, Weiyan Shi, and Zhou Yu. 2020. INSPIRED: Toward Sociable Recommendation Dialog Systems. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 8142–8152. 𝜏-Rec: A Verifiable Benchmark for Agentic Recommender Systems
2020
-
[9]
Xu Huang, Jianxun Lian, Yuxuan Lei, Jing Yao, Defu Lian, and Xing Xie. 2025. Recommender AI Agent: Integrating Large Language Models for Interactive Recommendations.ACM Transactions on Information Systems43, 4, Article 96 (2025), 33 pages. doi:10.1145/3731446
-
[10]
Zheng Hui, Xiaokai Wei, Yexi Jiang, Kevin Gao, Chen Wang, Frank Ong, Se eun Yoon, Rachit Pareek, and Michelle Gong. 2025. Toward Safe and Human-Aligned Game Conversational Recommendation via Multi-Agent Decomposition.arXiv preprint arXiv:2504.20094(2025)
arXiv 2025
-
[11]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. Live- CodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. InThe Thirteenth International Conference on Learning Repre- sentations (ICLR). https://openreview.net/forum?id=chfJJYC3iL
2025
-
[12]
Zeming Liu, Haifeng Wang, Zheng-Yu Niu, Hua Wu, Wanxiang Che, and Ting Liu. 2020. Towards Conversational Recommendation over Multi-Type Dialogs. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL). 1036–1049
2020
-
[13]
Ofer Meshi, Krisztian Balog, Sally Goldman, Avi Caciularu, Guy Tennenholtz, Jihwan Jeong, Amir Globerson, and Craig Boutilier. 2026. ConvApparel: A Bench- mark Dataset and Validation Framework for User Simulators in Conversational Recommenders. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (V...
-
[14]
Seungwhan Moon, Pararth Shah, Anuj Kumar, and Rajen Subba. 2019. OpenDi- alKG: Explainable Conversational Reasoning with Attention-based Walks over Knowledge Graphs. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL). 845–854
2019
-
[15]
Dario Di Palma, Felice Antonio Merra, Maurizio Sfilio, Vito Walter Anelli, Fedelu- cio Narducci, and Tommaso Di Noia. 2025. Do LLMs Memorize Recommendation Datasets? A Preliminary Study on MovieLens-1M. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25). 2582–2586. doi:10.1145/3726...
-
[16]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun
-
[17]
InInternational Conference on Learning Representations (ICLR)
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. InInternational Conference on Learning Representations (ICLR)
-
[18]
Yu Shang, Peijie Liu, Yuwei Yan, Zijing Wu, Leheng Sheng, Yuanqing Yu, Chu- meng Jiang, An Zhang, Fengli Xu, Yu Wang, Min Zhang, and Yong Li. 2025. AgentRecBench: Benchmarking LLM Agent-based Personalized Recommender Systems. InAdvances in Neural Information Processing Systems 38 (NeurIPS)
2025
-
[19]
Jiakai Tang, Yujie Luo, Xunke Xi, Fei Sun, Xueyang Feng, Sunhao Dai, Chao Yi, Dian Chen, Zhujin Gao, Yang Li, Xu Chen, Wen Chen, Jian Wu, Yuning Jiang, and Bo Zheng. 2025. Interactive Recommendation Agent with Active User Commands.arXiv preprint arXiv:2509.21317(2025)
arXiv 2025
-
[20]
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian
-
[21]
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 16022–16076. doi:10.18653/v1/2024.acl-long.850
-
[22]
Xiaolei Wang, Xinyu Tang, Xin Zhao, Jingyuan Wang, and Ji-Rong Wen. 2023. Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 10052–10065. doi:10.18653/v1/2023. emnlp-main.621
-
[23]
Yancheng Wang, Ziyan Jiang, Zheng Chen, Fan Yang, Yingxue Zhou, Eunah Cho, Xing Fan, Yanbin Lu, Xiaojiang Huang, and Yingzhen Yang. 2024. RecMind: Large Language Model Powered Agent For Recommendation. InFindings of the Association for Computational Linguistics: NAACL
2024
-
[24]
Zhefan Wang, Yuanqing Yu, Wendi Zheng, Weizhi Ma, and Min Zhang. 2024. MACRec: A Multi-Agent Collaboration Framework for Recommendation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24). 2760–2764. doi:10.1145/3626772. 3657669
-
[25]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2025. 𝜏- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. In Proceedings of the Thirteenth International Conference on Learning Representations (ICLR)
2025
-
[26]
Mingqiao Zhang, Qiyao Peng, Yumeng Wang, Chunyuan Liu, and Hongtao Liu
-
[27]
Benchmark Leakage Trap: Can We Trust LLM-based Recommendation? arXiv preprint arXiv:2602.13626(2026)
Pith/arXiv arXiv 2026
-
[28]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems 36 (NeurIPS)
2023
-
[29]
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. Instruction-Following Evaluation for Large Language Models. arXiv:2311.07911 [cs.CL] https://arxiv.org/abs/2311.07911
Pith/arXiv arXiv 2023
-
[30]
Kun Zhou, Xiaolei Wang, Yuanhang Zhou, Chenzhan Shang, Yuan Cheng, Wayne Xin Zhao, Yaliang Li, and Ji-Rong Wen. 2021. CRSLab: An Open-Source Toolkit for Building Conversational Recommender System. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL): System Demonstrations. 185–193
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.