Fisher-Guided Progressive Parameter Selection for Adaptive Fine-Tuning
Pith reviewed 2026-06-27 16:32 UTC · model grok-4.3
The pith
Fisher structural drift allows progressive freezing of parameter groups during fine-tuning to reduce generalization error bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
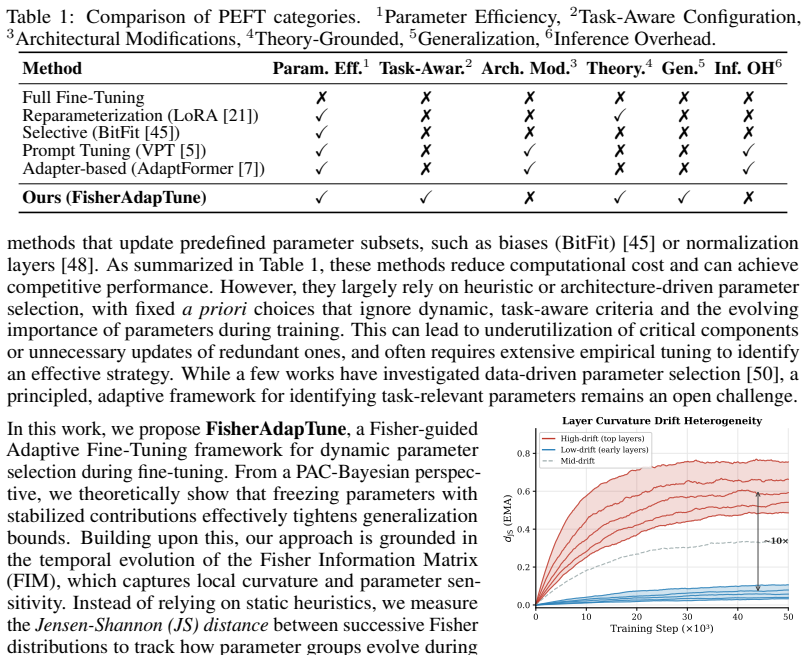
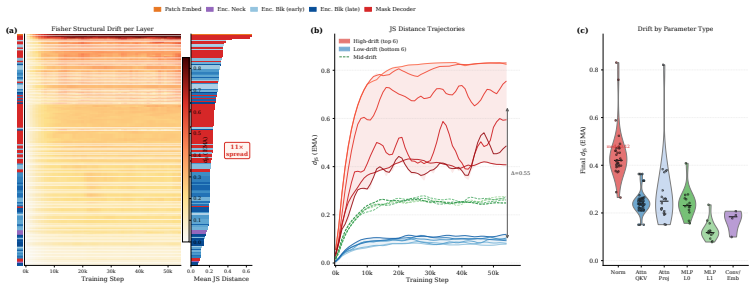
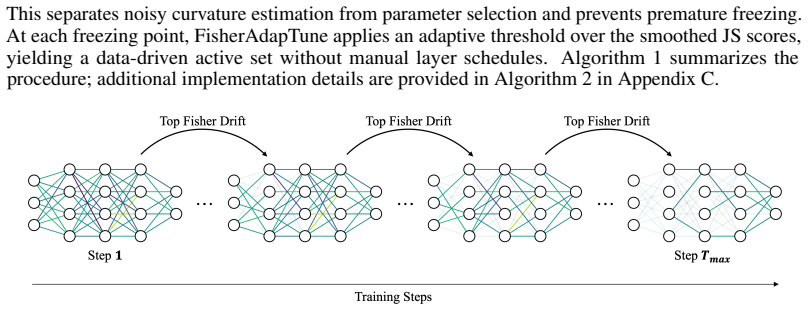
FisherAdapTune formulates parameter selection by tracking the temporal drift of Fisher geometry; starting from a PAC-Bayesian view, the generalization error bound is decomposed into Fisher-weighted update costs so that groups whose curvature contribution has stabilized can be frozen without interrupting remaining adaptation dynamics, with the criterion expressed via scale-invariant Jensen-Shannon distance between consecutive Fisher distributions.
What carries the argument
Scale-invariant Jensen-Shannon distance between consecutive Fisher distributions, used to detect structural drift and decide which parameter groups to freeze.
If this is right
- The active parameter set becomes task-dependent rather than fixed by architecture.
- Fewer parameters need updating once drift stabilizes, lowering compute per step.
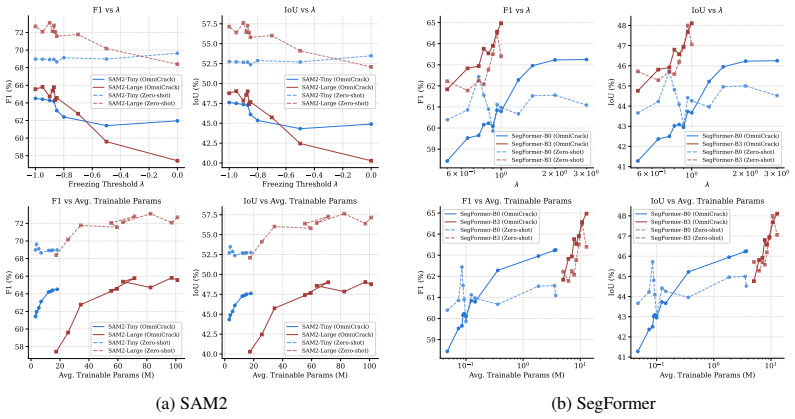
- The same drift signal improves both in-distribution performance and zero-shot transfer on segmentation tasks.
- The PAC-Bayesian decomposition supplies an explicit link between curvature stability and error-bound reduction.
Where Pith is reading between the lines
- The same drift-tracking rule could be applied to other vision or language adaptation settings where Fisher matrices remain tractable.
- If the decomposition holds, similar progressive freezing might combine with existing PEFT modules such as adapters or LoRA.
- Measuring drift only on a small validation subset might preserve the method's efficiency while still capturing task-specific curvature changes.
Load-bearing premise
The generalization error bound from a PAC-Bayesian view of fine-tuning can be decomposed into Fisher-weighted update costs such that stabilized curvature groups can be frozen without harming remaining adaptation.
What would settle it
A controlled run in which parameters are frozen according to the Fisher drift criterion yet the final generalization error or downstream accuracy is higher than when the same groups remain trainable throughout training.
Figures
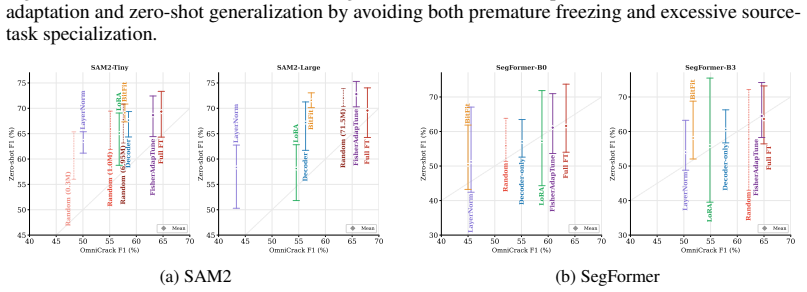
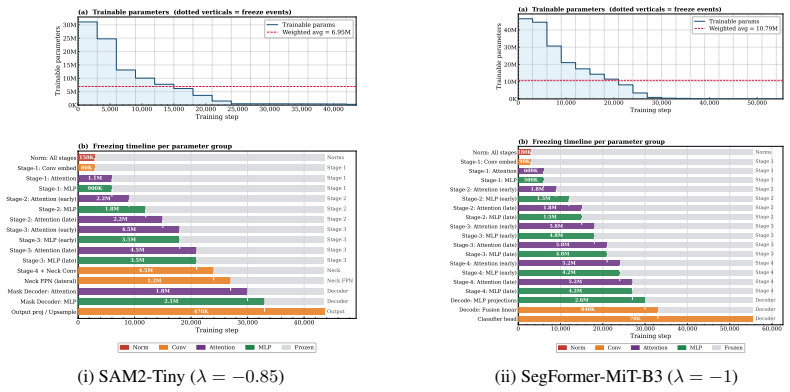
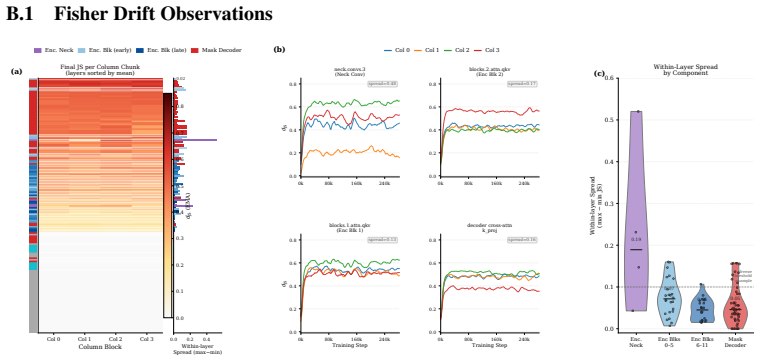
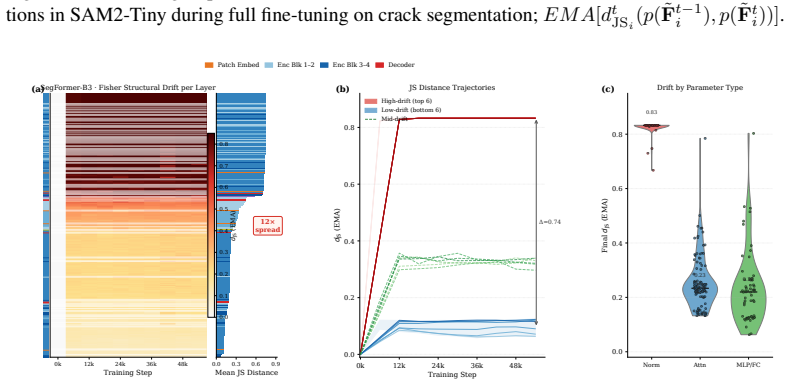
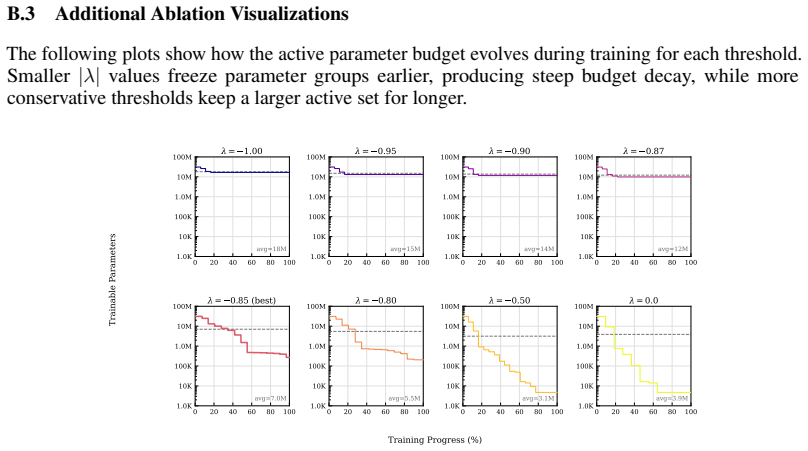
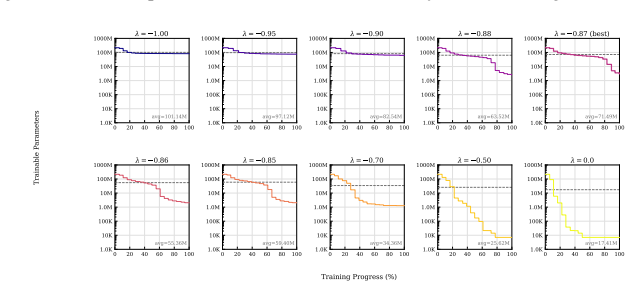
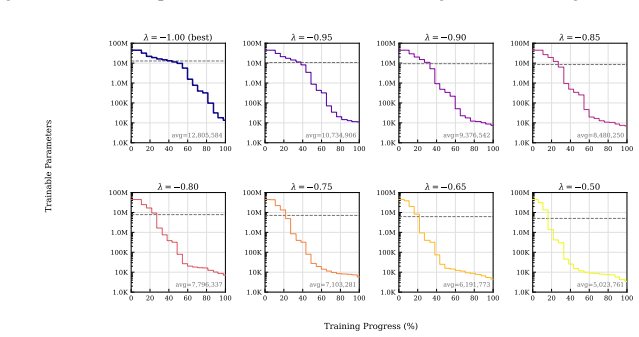
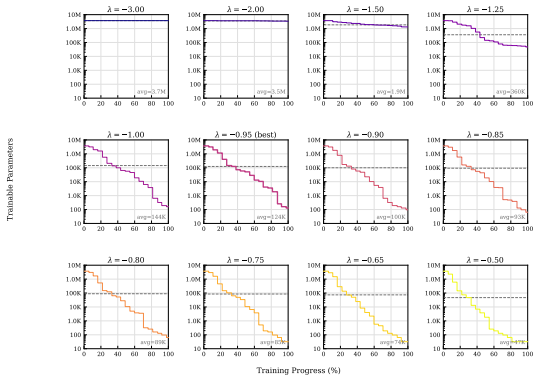
read the original abstract
Parameter-efficient fine-tuning (PEFT) aims to adapt pretrained models with a small trainable parameter subset, however, most existing methods choose this subset from fixed architectural heuristics rather than using dynamic, task-aware criteria. We introduce \textbf{FisherAdapTune}, a Fisher-guided Adaptive Fine-Tuning framework that progressively selects parameter groups by tracking the temporal drift of their Fisher geometry. Starting from a PAC-Bayesian view of fine-tuning, we decompose the generalization error bound into Fisher-weighted update costs and show that parameter groups whose curvature contribution has stabilized can be frozen to reduce the error bound without interrupting the remaining adaptation dynamics. FisherAdapTune formulates this criterion with a scale-invariant Jensen-Shannon distance between consecutive Fisher distributions, yielding an adaptive active parameter set. We evaluate our approach on a downstream segmentation task, and results show FisherAdapTune improves the in-distribution performance and zero-shot transfer in multiple settings, validating that Fisher structural drift is a useful signal for efficient, task-aware adaptation. We release our \href{https://github.com/AtlasAnalyticsLab/FisherAdapTune}{code} publicly to enable further application of our proposed approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FisherAdapTune, a Fisher-guided adaptive fine-tuning method that progressively selects parameter groups by tracking temporal drift in their Fisher geometry via scale-invariant Jensen-Shannon distance between consecutive Fisher distributions. Starting from a PAC-Bayesian perspective on fine-tuning, it claims to decompose the generalization error bound into Fisher-weighted update costs so that groups whose curvature contribution has stabilized can be frozen, reducing the bound without interrupting remaining adaptation dynamics. The approach is positioned as a task-aware alternative to fixed architectural heuristics in PEFT, with evaluation on a downstream segmentation task reportedly showing gains in in-distribution performance and zero-shot transfer; code is released publicly.
Significance. If the claimed decomposition holds and the empirical results prove robust with proper controls, the work could provide a principled, dynamic criterion for parameter selection in fine-tuning that improves efficiency over static PEFT methods. The public code release is a positive contribution that supports reproducibility.
major comments (2)
- [Abstract] Abstract: the PAC-Bayesian decomposition of the generalization error bound into Fisher-weighted update costs is asserted without any derivation, explicit equations, or stated assumptions on parameter-group independence or higher-order terms; this leaves the justification for the JS-distance freeze criterion unverified and makes it impossible to confirm that freezing reduces the bound while preserving adaptation dynamics.
- [Abstract] Abstract: performance improvements on segmentation and zero-shot transfer are claimed, yet no quantitative results, baselines, error bars, dataset details, or experimental protocol are supplied, so the data-to-claim link cannot be assessed and the central empirical support for Fisher structural drift as a useful signal remains unevaluated.
minor comments (1)
- [Abstract] The abstract refers to 'multiple settings' without enumerating them or indicating whether they include standard benchmarks or ablation studies on the JS threshold.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major point below and propose targeted revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the PAC-Bayesian decomposition of the generalization error bound into Fisher-weighted update costs is asserted without any derivation, explicit equations, or stated assumptions on parameter-group independence or higher-order terms; this leaves the justification for the JS-distance freeze criterion unverified and makes it impossible to confirm that freezing reduces the bound while preserving adaptation dynamics.
Authors: The full derivation of the PAC-Bayesian decomposition, including explicit equations, the handling of higher-order terms, and assumptions on parameter-group independence, appears in Section 3 of the manuscript. The abstract summarizes the high-level contribution. To address the concern that the abstract alone leaves the justification unverified, we will revise the abstract to include a concise reference to the key decomposition equation and the relevant section. revision: yes
-
Referee: [Abstract] Abstract: performance improvements on segmentation and zero-shot transfer are claimed, yet no quantitative results, baselines, error bars, dataset details, or experimental protocol are supplied, so the data-to-claim link cannot be assessed and the central empirical support for Fisher structural drift as a useful signal remains unevaluated.
Authors: We agree that the abstract provides only a high-level claim without numbers or protocol details. The complete quantitative results (including specific gains, baselines, error bars, datasets, and experimental protocol) are reported in Section 4 and the supplementary material. We will revise the abstract to incorporate representative quantitative metrics and a brief mention of the evaluation settings to strengthen the link between claims and evidence. revision: yes
Circularity Check
No significant circularity; derivation presented as independent decomposition from PAC-Bayesian starting point
full rationale
The abstract states that the authors start from a PAC-Bayesian view and decompose the generalization error bound into Fisher-weighted update costs, then formulate the freeze criterion via scale-invariant JS distance on Fisher distributions. No equations are supplied that reduce the JS threshold or active parameter set back to quantities defined inside the bound itself. No self-citations, fitted-input renamings, or ansatzes smuggled via prior work appear in the provided text. The central claim therefore retains independent content from the stated decomposition and the empirical JS criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PAC-Bayesian view of fine-tuning decomposes the generalization error bound into Fisher-weighted update costs
Reference graph
Works this paper leans on
-
[1]
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, December 2020
Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, December 2020
2020
-
[2]
Natural Gradient Works Efficiently in Learning.Neural Computation, 10(2): 251–276, February 1998
Shun-ichi Amari. Natural Gradient Works Efficiently in Learning.Neural Computation, 10(2): 251–276, February 1998. ISSN 0899-7667. doi: 10.1162/089976698300017746
-
[3]
Springer, February 2016
Shun-ichi Amari.Information Geometry and Its Applications. Springer, February 2016. ISBN 978-4-431-55978-8
2016
-
[4]
Composable Sparse Fine-Tuning for Cross-Lingual Transfer, February 2023
Alan Ansell, Edoardo Maria Ponti, Anna Korhonen, and Ivan Vuli ´c. Composable Sparse Fine-Tuning for Cross-Lingual Transfer, February 2023
2023
-
[5]
Exploring Visual Prompts for Adapting Large-Scale Models, June 2022
Hyojin Bahng, Ali Jahanian, Swami Sankaranarayanan, and Phillip Isola. Exploring Visual Prompts for Adapting Large-Scale Models, June 2022
2022
-
[6]
Affor- dancellm: Grounding affordance from vision language models
Christian Benz and V olker Rodehorst. Omni-Crack30k: A Benchmark for Crack Segmentation and the Reasonable Effectiveness of Transfer Learning. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 3876–3886, June 2024. doi: 10.1109/CVPRW63382.2024.00392
-
[7]
AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition.Advances in Neural Information Processing Systems, 35:16664–16678, December 2022
Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition.Advances in Neural Information Processing Systems, 35:16664–16678, December 2022
2022
-
[8]
Vision Transformer Adapter for Dense Predictions
Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong Lu, Jifeng Dai, and Yu Qiao. Vision Transformer Adapter for Dense Predictions. InThe Eleventh International Conference on Learning Representations, September 2022
2022
-
[9]
The Devil is in the Crack Orientation: A New Perspective for Crack Detection
Zhuangzhuang Chen, Jin Zhang, Zhuonan Lai, Guanming Zhu, Zun Liu, Jie Chen, and Jianqiang Li. The Devil is in the Crack Orientation: A New Perspective for Crack Detection. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 6630–6640, October
-
[10]
doi: 10.1109/ICCV51070.2023.00612
-
[11]
Mind marginal non-crack regions: Clustering-inspired representation learning for crack segmentation
Zhuangzhuang Chen, Zhuonan Lai, Jie Chen, and Jianqiang Li. Mind marginal non-crack regions: Clustering-inspired representation learning for crack segmentation. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12698–12708, June
-
[12]
doi: 10.1109/CVPR52733.2024.01207. 10
-
[13]
Kronecker-factored Approximate Curvature (KFAC) From Scratch, July 2025
Felix Dangel, Bálint Mucsányi, Tobias Weber, and Runa Eschenhagen. Kronecker-factored Approximate Curvature (KFAC) From Scratch, July 2025
2025
-
[14]
Gintare Karolina Dziugaite and Daniel M Roy. Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data.arXiv preprint arXiv:1703.11008, 2017
Pith/arXiv arXiv 2017
-
[15]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, March 2019
Jonathan Frankle and Michael Carbin. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, March 2019
2019
-
[16]
K. Ge, C. Wang, Y . T. Guo, Y . S. Tang, Z. Z. Hu, and H. B. Chen. Fine-tuning vision foundation model for crack segmentation in civil infrastructures.Construction and Building Materials, 431:136573, June 2024. ISSN 0950-0618. doi: 10.1016/j.conbuildmat.2024.136573
-
[17]
Hosseini
Damien MARTINS Gomes, Yanlei Zhang, Eugene Belilovsky, Guy Wolf, and Mahdi S. Hosseini. AdaFisher: Adaptive Second Order Optimization via Fisher Information. InThe Thirteenth International Conference on Learning Representations, October 2024
2024
-
[18]
Rush, and Yoon Kim
Demi Guo, Alexander M. Rush, and Yoon Kim. Parameter-Efficient Transfer Learning with Diff Pruning, June 2021
2021
-
[19]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey, April 2024
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey, April 2024
2024
-
[20]
Xuehai He, Chunyuan Li, Pengchuan Zhang, Jianwei Yang, and Xin Eric Wang. Parameter- Efficient Model Adaptation for Vision Transformers.Proceedings of the AAAI Conference on Artificial Intelligence, 37(1):817–825, June 2023. ISSN 2374-3468. doi: 10.1609/aaai.v37i1. 25160
-
[21]
On the slow death of scaling.Available at SSRN 5877662, 2025
Sara Hooker. On the slow death of scaling.Available at SSRN 5877662, 2025
2025
-
[22]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
2019
-
[23]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models, October 2021
2021
-
[24]
UniSim: A Neural Closed-Loop Sensor Simulator
Qidong Huang, Xiaoyi Dong, Dongdong Chen, Weiming Zhang, Feifei Wang, Gang Hua, and Nenghai Yu. Diversity-Aware Meta Visual Prompting. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10878–10887, Vancouver, BC, Canada, June 2023. IEEE. ISBN 979-8-3503-0129-8. doi: 10.1109/CVPR52729.2023.01047
-
[25]
Visual Prompt Tuning, July 2022
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual Prompt Tuning, July 2022
2022
-
[26]
Convolutional Bypasses Are Better Vision Transformer Adapters
Shibo Jie, Zhi-Hong Deng, Shixuan Chen, and Zhijuan Jin. Convolutional Bypasses Are Better Vision Transformer Adapters. InECAI 2024, pages 202–209. IOS Press, 2024. doi: 10.3233/FAIA240489
-
[27]
BayesTune: Bayesian Sparse Deep Model Fine- tuning.Advances in Neural Information Processing Systems, 36:65317–65365, December 2023
Minyoung Kim and Timothy Hospedales. BayesTune: Bayesian Sparse Deep Model Fine- tuning.Advances in Neural Information Processing Systems, 36:65317–65365, December 2023
2023
-
[28]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[29]
Fine- Tuning can Distort Pretrained Features and Underperform Out-of-Distribution
Ananya Kumar, Aditi Raghunathan, Robbie Matthew Jones, Tengyu Ma, and Percy Liang. Fine- Tuning can Distort Pretrained Features and Underperform Out-of-Distribution. InInternational Conference on Learning Representations, October 2021. 11
2021
-
[30]
Yongshang Li, Ronggui Ma, Han Liu, and Gaoli Cheng. Real-time high-resolution neural network with semantic guidance for crack segmentation.Automation in Construction, 156: 105112, December 2023. ISSN 0926-5805. doi: 10.1016/j.autcon.2023.105112
-
[31]
Selecting Large Language Model to Fine-tune via Rectified Scaling Law
Haowei Lin, Baizhou Huang, Haotian Ye, Qinyu Chen, Zihao Wang, Sujian Li, Jianzhu Ma, Xiaojun Wan, James Zou, and Yitao Liang. Selecting Large Language Model to Fine-tune via Rectified Scaling Law. InProceedings of the 41st International Conference on Machine Learning, pages 30080–30107. PMLR, July 2024
2024
-
[32]
AutoFreeze: Automatically Freez- ing Model Blocks to Accelerate Fine-tuning, April 2021
Yuhan Liu, Saurabh Agarwal, and Shivaram Venkataraman. AutoFreeze: Automatically Freez- ing Model Blocks to Accelerate Fine-tuning, April 2021
2021
-
[33]
PAC-Bayes compression bounds so tight that they can explain generalization
Sanae Lotfi, Marc Anton Finzi, Sanyam Kapoor, Andres Potapczynski, Micah Goldblum, and Andrew Gordon Wilson. PAC-Bayes compression bounds so tight that they can explain generalization. InAdvances in Neural Information Processing Systems, 2022. URL https: //openreview.net/forum?id=o8nYuR8ekFm
2022
-
[34]
Optimizing Neural Networks with Kronecker-factored Approximate Curvature
James Martens and Roger Grosse. Optimizing Neural Networks with Kronecker-factored Approximate Curvature. InProceedings of the 32nd International Conference on Machine Learning, pages 2408–2417. PMLR, June 2015
2015
-
[35]
David A. McAllester. PAC-Bayesian model averaging. InProceedings of the Twelfth Annual Conference on Computational Learning Theory, pages 164–170, Santa Cruz California USA, July 1999. ACM. ISBN 978-1-58113-167-3. doi: 10.1145/307400.307435
-
[36]
David A. McAllester. Some PAC-Bayesian Theorems.Machine Learning, 37(3):355–363, December 1999. ISSN 1573-0565. doi: 10.1023/A:1007618624809
-
[37]
Make Sharpness-Aware Minimization Stronger: A Sparsified Perturbation Approach.Advances in Neural Information Processing Systems, 35:30950–30962, December 2022
Peng Mi, Li Shen, Tianhe Ren, Yiyi Zhou, Xiaoshuai Sun, Rongrong Ji, and Dacheng Tao. Make Sharpness-Aware Minimization Stronger: A Sparsified Perturbation Approach.Advances in Neural Information Processing Systems, 35:30950–30962, December 2022
2022
-
[38]
How Do Vision Transformers Work? InInternational Conference on Learning Representations, October 2021
Namuk Park and Songkuk Kim. How Do Vision Transformers Work? InInternational Conference on Learning Representations, October 2021
2021
-
[39]
SAM 2: Segment Anything in Images and Videos, October 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. SAM 2: Segment Anything in Images and Videos, October 2024
2024
-
[40]
Trade-Offs of Diagonal Fisher Information Matrix Estimators
Alexander Soen and Ke Sun. Trade-Offs of Diagonal Fisher Information Matrix Estimators. Advances in Neural Information Processing Systems, 37:5870–5912, December 2024
2024
-
[41]
Training Neural Networks with Fixed Sparse Masks - Preprint, November 2021
Yi-Lin Sung, Varun Nair, and Colin Raffel. Training Neural Networks with Fixed Sparse Masks - Preprint, November 2021
2021
-
[42]
Scale Efficiently: Insights from Pretraining and Finetuning Transformers
Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, and Donald Metzler. Scale Efficiently: Insights from Pretraining and Finetuning Transformers. InInternational Conference on Learning Representations, October 2021
2021
-
[43]
Automatic concrete crack segmentation model based on transformer
Wenjun Wang and Chao Su. Automatic concrete crack segmentation model based on transformer. Automation in Construction, 139:104275, July 2022. ISSN 09265805. doi: 10.1016/j.autcon. 2022.104275
-
[44]
LoRA-Pro: Are Low- Rank Adapters Properly Optimized? InThe Thirteenth International Conference on Learning Representations, October 2024
Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, and Tieniu Tan. LoRA-Pro: Are Low- Rank Adapters Properly Optimized? InThe Thirteenth International Conference on Learning Representations, October 2024
2024
-
[45]
Alvarez, and Ping Luo
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Advances in Neural Information Processing Systems, volume 34, pages 12077–12090. Curran Associates, Inc., 2021. 12
2021
-
[46]
Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning, September 2021
Runxin Xu, Fuli Luo, Zhiyuan Zhang, Chuanqi Tan, Baobao Chang, Songfang Huang, and Fei Huang. Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning, September 2021
2021
-
[47]
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models, September 2022
Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models, September 2022
2022
-
[48]
Parameter- Efficient Fine-Tuning for Foundation Models, January 2025
Dan Zhang, Tao Feng, Lilong Xue, Yuandong Wang, Yuxiao Dong, and Jie Tang. Parameter- Efficient Fine-Tuning for Foundation Models, January 2025
2025
-
[49]
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter- efficient fine-tuning.arXiv preprint arXiv:2303.10512, 2023
Pith/arXiv arXiv 2023
-
[50]
Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning
Bingchen Zhao, Haoqin Tu, Chen Wei, Jieru Mei, and Cihang Xie. Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning. InThe Twelfth International Conference on Learning Representations, October 2023
2023
-
[51]
FisherTune: Fisher-Guided Robust Tuning of Vision Foundation Models for Domain Gener- alized Segmentation
Dong Zhao, Jinlong Li, Shuang Wang, Mengyao Wu, Qi Zang, Nicu Sebe, and Zhun Zhong. FisherTune: Fisher-Guided Robust Tuning of Vision Foundation Models for Domain Gener- alized Segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15043–15054, 2025
2025
-
[52]
Masking as an Efficient Alternative to Finetuning for Pretrained Language Models, October 2020
Mengjie Zhao, Tao Lin, Fei Mi, Martin Jaggi, and Hinrich Schütze. Masking as an Efficient Alternative to Finetuning for Pretrained Language Models, October 2020
2020
-
[53]
Wenda Zhou, Victor Veitch, Morgane Austern, Ryan P Adams, and Peter Orbanz. Non-vacuous generalization bounds at the imagenet scale: a pac-bayesian compression approach.arXiv preprint arXiv:1804.05862, 2018
Pith/arXiv arXiv 2018
-
[54]
A Comprehensive Survey on Transfer Learning.Proceedings of the IEEE, 109 (1):43–76, January 2021
Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, and Qing He. A Comprehensive Survey on Transfer Learning.Proceedings of the IEEE, 109 (1):43–76, January 2021. ISSN 1558-2256. doi: 10.1109/JPROC.2020.3004555. 13 Appendix Overview The appendix provides theoretical derivations, implementation details for Fisher drift, s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.