SHAPO: Sharpness-Aware Policy Optimization for Safe Exploration
Pith reviewed 2026-06-27 16:56 UTC · model grok-4.3
The pith
Evaluating gradients at perturbed parameters makes RL policy updates pessimistic to epistemic uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
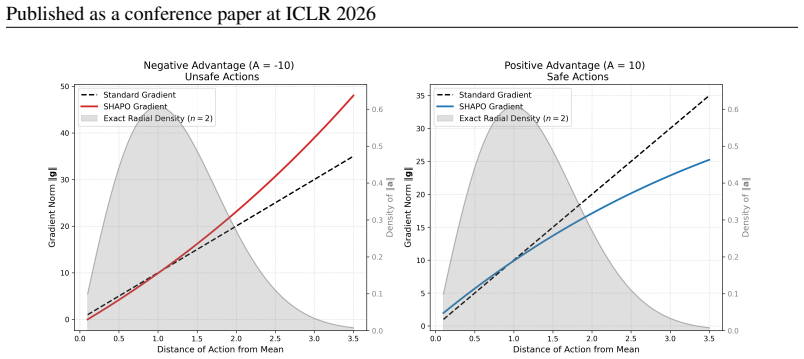
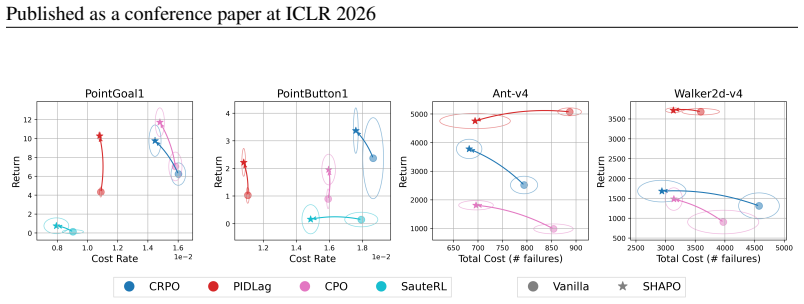
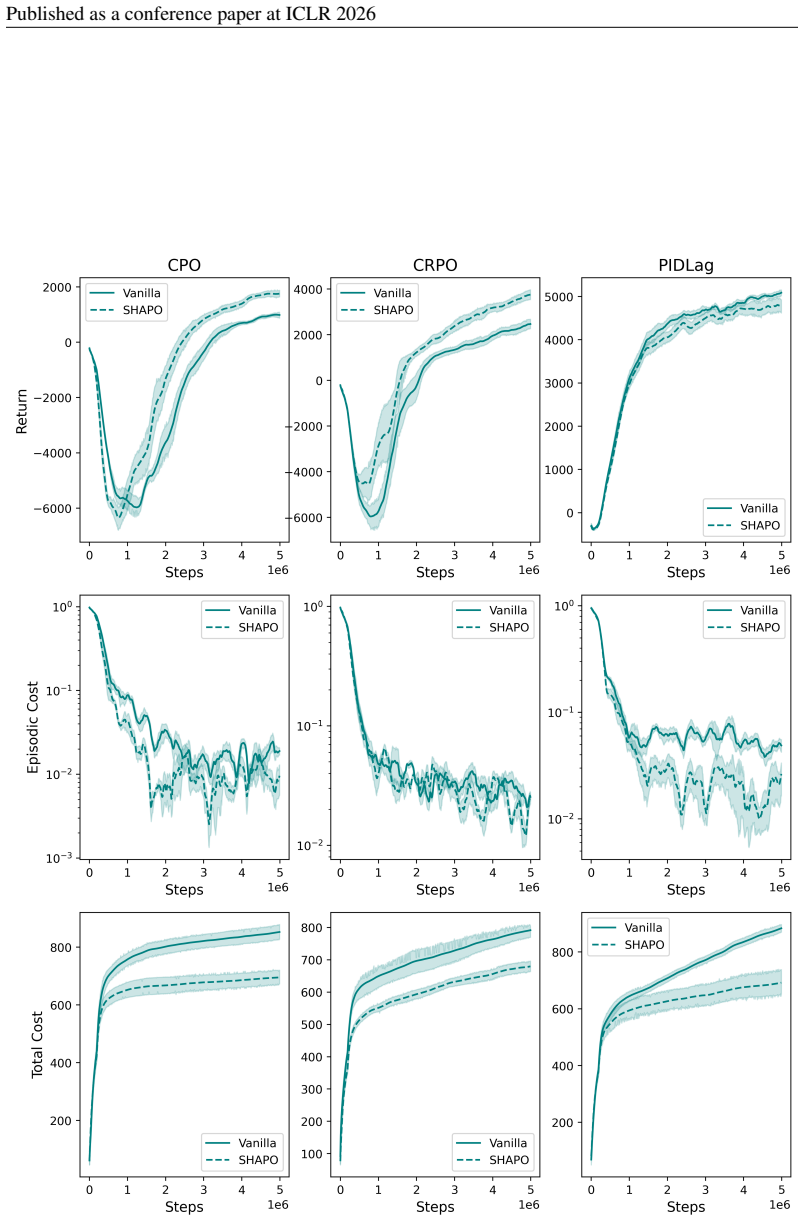
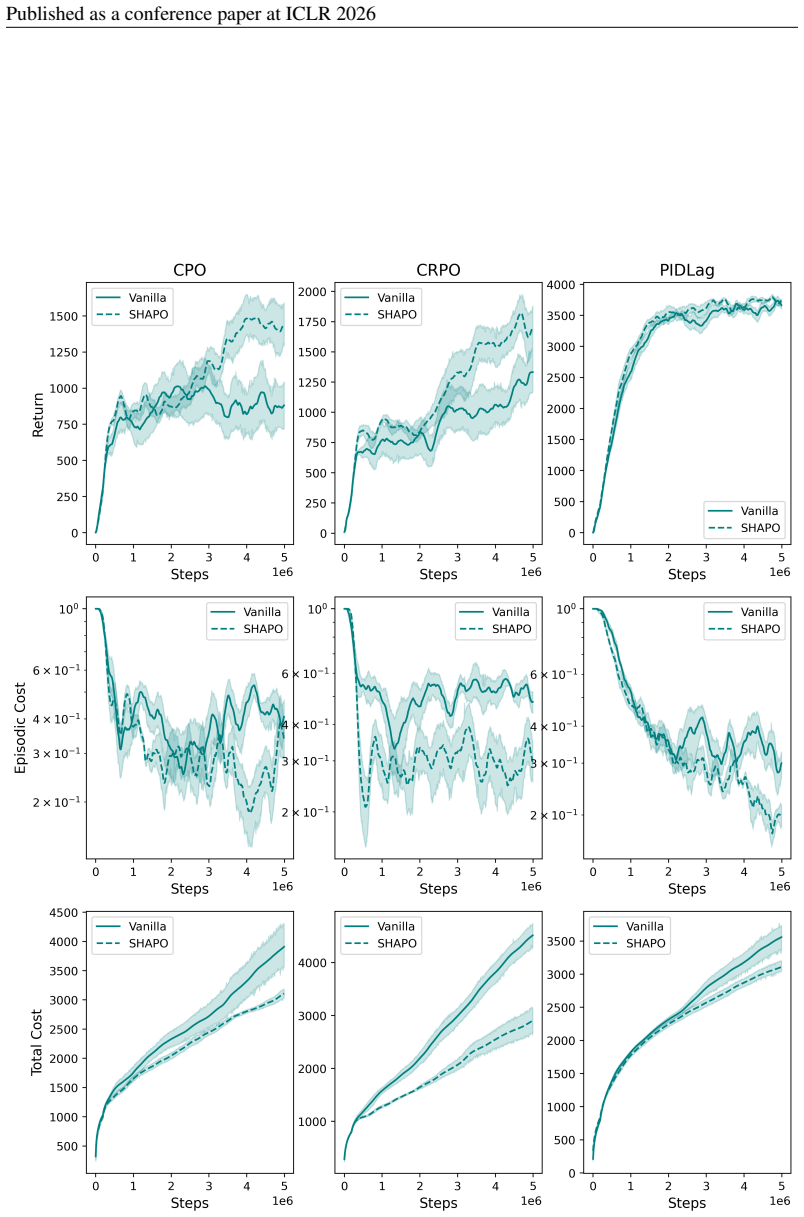
SHAPO is a sharpness-aware policy update rule that evaluates gradients at perturbed parameters, making policy updates pessimistic with respect to the actor's epistemic uncertainty. Analytically this adjustment implicitly reweighs policy gradients, amplifying the influence of rare unsafe actions while tempering contributions from already safe ones, thereby biasing learning toward conservative behavior in under-explored regions. Across several continuous-control tasks the method consistently improves both safety and task performance over existing baselines, significantly expanding their Pareto frontiers.
What carries the argument
The sharpness-aware policy update rule that evaluates gradients at perturbed parameters to produce pessimistic updates with respect to epistemic uncertainty.
If this is right
- Policy updates become pessimistic with respect to the actor's epistemic uncertainty.
- Rare unsafe actions receive amplified weight in the gradient while safe actions are tempered.
- Learning is biased toward conservative behavior specifically in under-explored regions.
- Both safety and task performance improve simultaneously over existing baselines.
- The safety-performance Pareto frontier expands on the tested continuous-control tasks.
Where Pith is reading between the lines
- The same perturbation-based reweighting might transfer to discrete-action settings where uncertainty estimation differs.
- Combining SHAPO with explicit constraint-based safe RL methods could yield further gains in highly constrained environments.
- The approach suggests that other first-order sensitivity measures besides sharpness could serve as uncertainty proxies.
- Scalability to high-dimensional or image-based observations remains an open test that would follow directly from the mechanism.
Load-bearing premise
The actor's sensitivity to parameter perturbations serves as a practical proxy for regions of high uncertainty.
What would settle it
On the continuous-control tasks, if the method produces no measurable improvement in safety metrics or task return relative to the baselines, the central claim would be falsified.
Figures
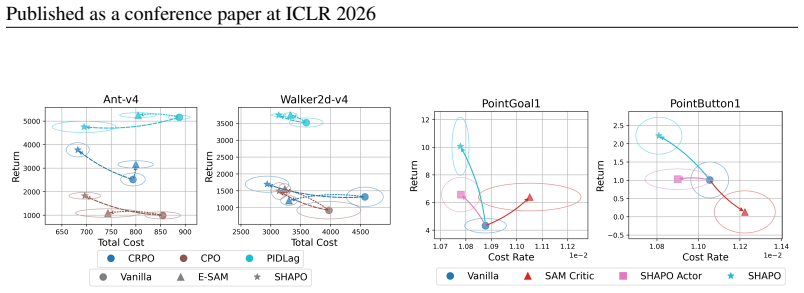
read the original abstract
Safe exploration is a prerequisite for deploying reinforcement learning (RL) agents in safety-critical domains. In this paper, we approach safe exploration through the lens of epistemic uncertainty, where the actor's sensitivity to parameter perturbations serves as a practical proxy for regions of high uncertainty. We propose Sharpness-Aware Policy Optimization (SHAPO), a sharpness-aware policy update rule that evaluates gradients at perturbed parameters, making policy updates pessimistic with respect to the actor's epistemic uncertainty. Analytically we show that this adjustment implicitly reweighs policy gradients, amplifying the influence of rare unsafe actions while tempering contributions from already safe ones, thereby biasing learning toward conservative behavior in under-explored regions. Across several continuous-control tasks, our method consistently improves both safety and task performance over existing baselines, significantly expanding their Pareto frontiers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Sharpness-Aware Policy Optimization (SHAPO) for safe exploration in reinforcement learning. It treats the actor's sensitivity to parameter perturbations as a proxy for epistemic uncertainty and introduces a sharpness-aware policy update that evaluates gradients at perturbed parameters. The abstract states that this produces pessimistic updates and analytically reweights policy gradients to amplify the influence of rare unsafe actions while tempering safe ones, thereby encouraging conservative behavior in under-explored regions. Empirical results on continuous-control tasks are reported to improve both safety and task performance over baselines and to expand their Pareto frontiers.
Significance. If the reweighting analysis is correct and the perturbation sensitivity reliably proxies epistemic uncertainty rather than parameterization curvature, the method would offer a lightweight way to bias policy gradients toward safety without separate uncertainty estimators or explicit constraints. The reported Pareto-frontier expansion on continuous-control benchmarks would then represent a practical advance over existing safe-RL baselines.
major comments (2)
- [Abstract] Abstract: the central analytical claim—that evaluating gradients at perturbed parameters 'implicitly reweighs policy gradients, amplifying the influence of rare unsafe actions'—is asserted without any equation, derivation, or proof sketch. Because this reweighting is the stated mechanism linking sharpness to conservative behavior, its absence prevents verification that the claimed effect follows from the update rule rather than from an auxiliary modeling choice.
- [Abstract] Abstract (and method description): the load-bearing assumption that 'the actor's sensitivity to parameter perturbations serves as a practical proxy for regions of high uncertainty' is presented without justification, counter-example, or diagnostic experiment. If the sharpness measure primarily reflects policy curvature or optimization landscape geometry instead of environment epistemic uncertainty, the reweighting would not systematically favor unsafe-action amplification, undermining both the analytic justification and the reported safety gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for clearer presentation of the analytical claims. We address each point below and indicate revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central analytical claim—that evaluating gradients at perturbed parameters 'implicitly reweighs policy gradients, amplifying the influence of rare unsafe actions'—is asserted without any equation, derivation, or proof sketch. Because this reweighting is the stated mechanism linking sharpness to conservative behavior, its absence prevents verification that the claimed effect follows from the update rule rather than from an auxiliary modeling choice.
Authors: The full derivation appears in Section 3.2, where the perturbed gradient is expanded via first-order Taylor approximation to obtain the reweighting term that amplifies low-probability unsafe actions. We agree the abstract would be stronger with an explicit pointer. In revision we will append a parenthetical reference to Section 3.2 and note the Taylor step, while respecting abstract length constraints. revision: yes
-
Referee: [Abstract] Abstract (and method description): the load-bearing assumption that 'the actor's sensitivity to parameter perturbations serves as a practical proxy for regions of high uncertainty' is presented without justification, counter-example, or diagnostic experiment. If the sharpness measure primarily reflects policy curvature or optimization landscape geometry instead of environment epistemic uncertainty, the reweighting would not systematically favor unsafe-action amplification, undermining both the analytic justification and the reported safety gains.
Authors: Section 2 motivates the proxy by relating parameter sensitivity to posterior variance over actor weights under a Bayesian view of the policy. The experiments then show that this choice yields measurable safety gains precisely where visitation is sparse. We acknowledge the absence of an isolated diagnostic separating curvature from epistemic effects; we will add such a plot (sharpness vs. ensemble disagreement on held-out states) to the appendix in revision. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents the sharpness-aware update as an independently motivated rule whose reweighting effect on policy gradients is derived analytically from the perturbation mechanism. The epistemic-uncertainty proxy is introduced as an explicit modeling assumption rather than a quantity fitted or defined by the target result. No equations reduce the claimed safety or Pareto improvements to a self-referential fit, and no load-bearing self-citation or uniqueness theorem is invoked. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Why is SAM robust to label noise?arXiv preprint arXiv:2405.03676,
Christina Baek, Zico Kolter, and Aditi Raghunathan. Why is SAM robust to label noise?arXiv preprint arXiv:2405.03676,
-
[3]
A distributional perspective on reinforcement learning
4https://deel.quebec 11 Published as a conference paper at ICLR 2026 Marc G Bellemare, Will Dabney, and R ´emi Munos. A distributional perspective on reinforcement learning. InInternational Conference on Machine Learning, pp. 449–458. PMLR,
2026
-
[4]
Conservative safety critics for exploration.arXiv preprint arXiv:2010.14497, 2020
Homanga Bharadhwaj, Aviral Kumar, Nicholas Rhinehart, Sergey Levine, Florian Shkurti, and Ani- mesh Garg. Conservative safety critics for exploration.arXiv preprint arXiv:2010.14497,
-
[5]
Eugene Bykovets, Yannick Metz, Mennatallah El-Assady, Daniel A. Keim, and Joachim M. Buh- mann. How to enable uncertainty estimation in proximal policy optimization.arXiv preprint arXiv:2210.03649,
-
[6]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware minimiza- tion for efficiently improving generalization.arXiv preprint arXiv:2010.01412,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
arXiv preprint arXiv:2307.07176 , year=
Weidong Huang, Jiaming Ji, Borong Zhang, Chunhe Xia, and Yaodong Yang. Safe dreamerv3: Safe reinforcement learning with world models.arXiv preprint arXiv:2307.07176,
-
[8]
Hao Jiang, Tien Mai, Pradeep Varakantham, and Minh Huy Hoang. Solving richly con- strained reinforcement learning through state augmentation and reward penalties.arXiv preprint arXiv:2301.11592,
-
[9]
Fisher sam: Information geometry and sharpness aware minimisation
Minyoung Kim, Da Li, Shell X Hu, and Timothy Hospedales. Fisher sam: Information geometry and sharpness aware minimisation. InInternational Conference on Machine Learning, pp. 11148– 11161. PMLR, 2022a. Minyoung Kim, Da Li, Shell X Hu, and Timothy Hospedales. Fisher sam: Information geometry and sharpness aware minimisation. InInternational Conference on ...
2026
-
[10]
Vincent Mai, Kaustubh Mani, and Liam Paull. Sample efficient deep reinforcement learning via uncertainty estimation.arXiv preprint arXiv:2201.01666,
-
[11]
Safety representations for safer policy learning.arXiv preprint arXiv:2502.20341,
Kaustubh Mani, Vincent Mai, Charlie Gauthier, Annie Chen, Samer Nashed, and Liam Paull. Safety representations for safer policy learning.arXiv preprint arXiv:2502.20341,
-
[12]
Sam as an optimal relaxation of bayes.arXiv preprint arXiv:2210.01620,
Thomas M¨ollenhoff and Mohammad Emtiyaz Khan. Sam as an optimal relaxation of bayes.arXiv preprint arXiv:2210.01620,
-
[13]
Proximal Policy Optimization Algorithms
PMLR. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Learning to be safe: Deep rl with a safety critic.arXiv preprint arXiv:2010.14603, 2020
Krishnan Srinivasan, Benjamin Eysenbach, Sehoon Ha, Jie Tan, and Chelsea Finn. Learning to be safe: Deep RL with a safety critic.arXiv preprint arXiv:2010.14603,
-
[15]
Responsive safety in reinforcement learning by PID Lagrangian methods
13 Published as a conference paper at ICLR 2026 Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in reinforcement learning by PID Lagrangian methods. InInternational Conference on Machine Learning, pp. 9133–9143. PMLR,
2026
-
[16]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goul˜ao, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. Gymnasium: A standard interface for reinforcement learning environments.arXiv preprint arXiv:2407.17032,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
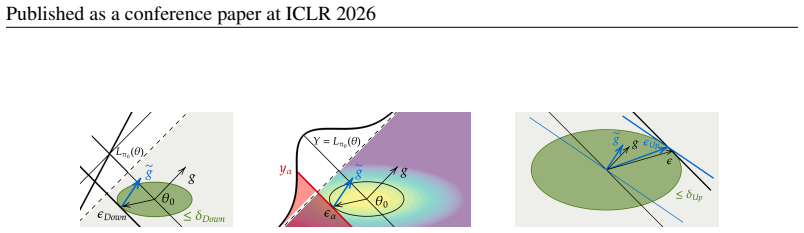
14 Published as a conference paper at ICLR 2026 Algorithm 2Sharpness-aware optimization 1:Initializeθ 2:whilenot convergeddo 3:Computeϵsuch thatπ θ+ϵ ≈arg min ˜π∈N(π)L(˜π) 4:Calculate the gradient at perturbed parameter:g← ∇L(θ+ϵ) 5:Update parameters:θ←θ+αg{αis the learning rate} 6:end while Algorithm 3SHAPO-TRPOLag (Trust Region Policy Optimization) 1:In...
2026
-
[18]
It returns a parameter direction˜gfor updating the current policyπ θ based on the objective function, the Fisher matrix of the policy parametrization and con- straint boundδ Down
Formulated this way, our method can be ap- plied to most on-policy RL algorithms. It returns a parameter direction˜gfor updating the current policyπ θ based on the objective function, the Fisher matrix of the policy parametrization and con- straint boundδ Down. This function effectively abstracts lines4−7of Algorithm 3 and allows us to present how our met...
2026
-
[19]
In Algorithm 4, we propose a simple approach to applySHAPO on the popular PPO algorithm that uses the following clipped objective (for someϵ >0): LPPO π0 (θ) =E s∼d0 Ea∼π0(a|s) h min r(θ, a, s)A0(s, a),clip(r(θ, a, s),1−ϵ,1 +ϵ)A 0(s, a) i , wherer(θ, a, s) = πθ(a|s) π0(a|s) . 16 Published as a conference paper at ICLR 2026 B REINTERPRETINGFISHERSAMASPESSI...
2026
-
[20]
Finallyz α, denotes theα-quantile forN(0,1)
Recall thatY=g t(θ−θ 0)withθ∼Qwithα-quantiles denoted byy α. Finallyz α, denotes theα-quantile forN(0,1). We now provide the proof of Propo- sition 2 which is illustrated in Figure 1: Proposition 5.LetQ(θ) =N(θ 0, 1 n F −1). For everyα∈(0, 1 2)the solutionϵ α to the optimization problem maximize ϵ logQ(θ 0 +ϵ) subject tog T ϵ≤y α (14) coincides with the a...
2026
-
[21]
Here we study how these two gradientsgand ˜gdiffer in a simplified setting. We observe that the contribution of a single state-action pair(s,a)towardsL λ π0 is given by: Lλ π0(θ|s,a) = A0(s,a) π0(a|s) πθ(a|s), whose gradient with respect toθis given by ∇θLλ π0(θ|s,a) = A0(s,a) π0(a|s) ∇θπθ(a|s) Each observed state-action pair therefore contributes towards...
2026
-
[22]
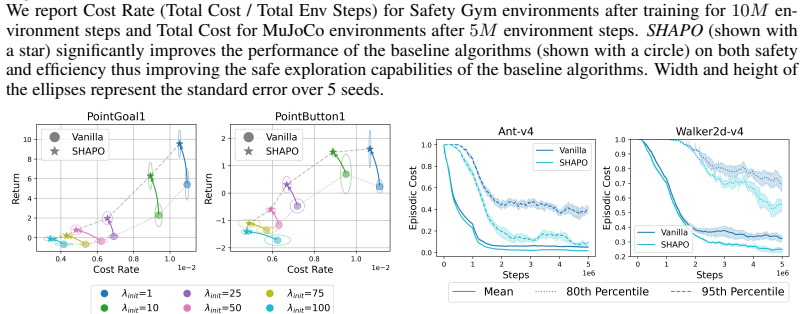
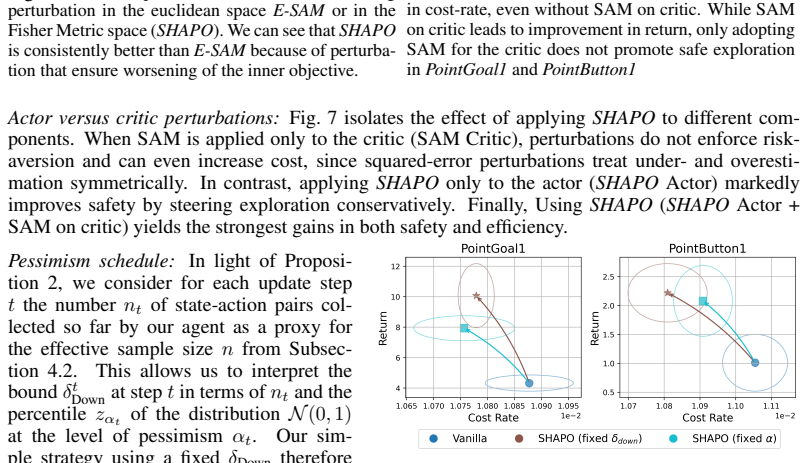
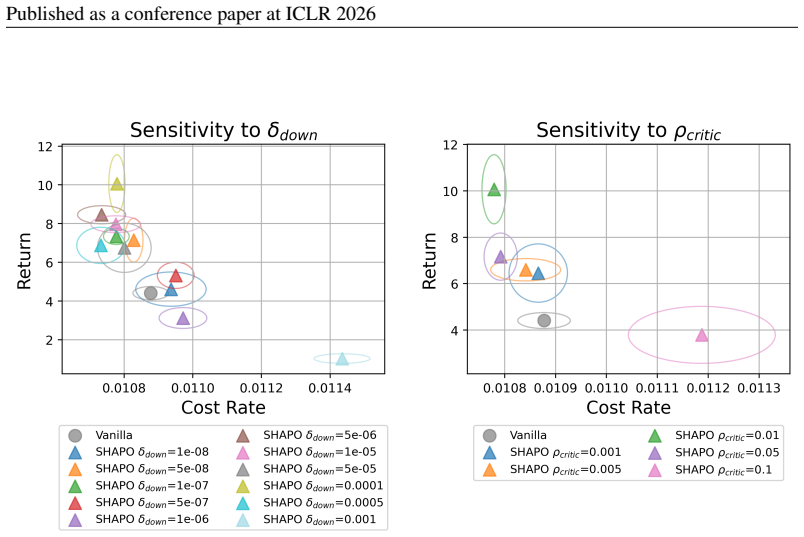
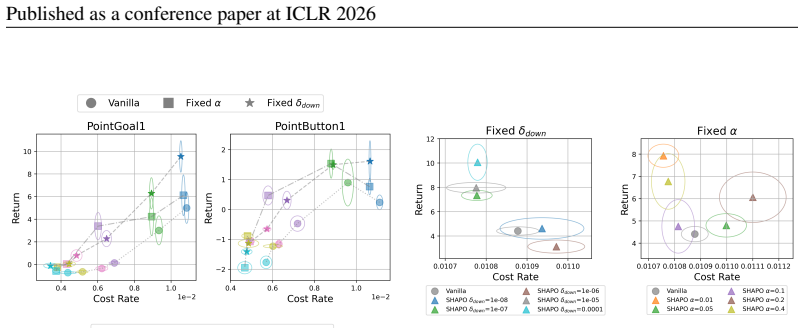
Very smallδ Down effectively disablesSHAPOand yields performance similar to the vanilla baseline, while overly large values destabilize training
19 Published as a conference paper at ICLR 2026 Figure 9:Hyperparameter Sensitivity:We evaluate the sensitivity ofSHAPOtoδ Down (left) and ρcritic (right). Very smallδ Down effectively disablesSHAPOand yields performance similar to the vanilla baseline, while overly large values destabilize training. Moderate values provide the most consistent improvement...
2026
-
[23]
This setup allows us to isolate the effect of each hyperparameter on safety and efficiency of the resulting policy
varying the two key hyperparameters,δ down andρ critic, while keeping all other settings fixed. This setup allows us to isolate the effect of each hyperparameter on safety and efficiency of the resulting policy. The results show that very smallδ down values effectively disable the perturbation step in SHAPO, causing the algorithm to behave like the vanill...
2026
-
[24]
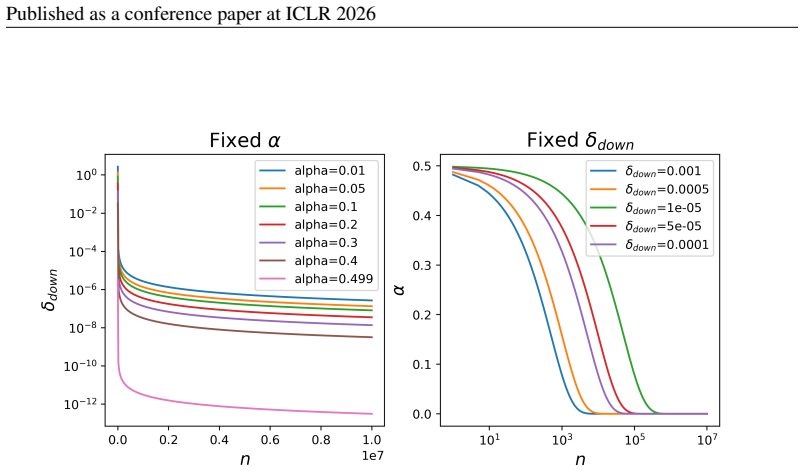
and safety-gymnasium(Ray et al., 2019), with5environments running in parallel. F PESSIMISM SCHEDULE In order to compare different ways of controlling the level of pessimism used inSHAPO, we use at each update steptthe number of collected state–action samplesn t as a proxy for the ideal sample sizenintroduced in Subsection 4.2. It is important to note that...
2019
-
[25]
From this perspective,SHAPO’s role becomes clear: it 23 Published as a conference paper at ICLR 2026 Figure 14:PointGoal1 modulates the actor’s sensitivity to tail events in the loss landscape, whether these arise from explicit constraints or from inherent structural properties of the environment. Fig. 13 illustrates how the impact ofSHAPOdepends on the p...
2026
-
[26]
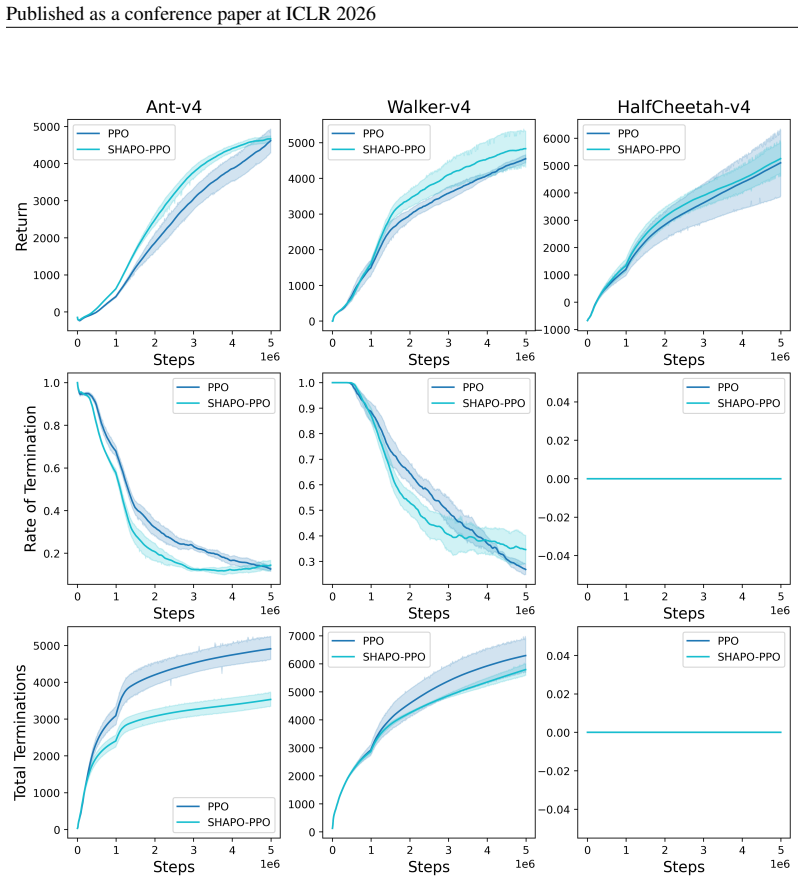
was used to polish writing and also as a tool to correct grammar and spelling mistakes. 24 Published as a conference paper at ICLR 2026 Figure 15:PointButton1 25 Published as a conference paper at ICLR 2026 Figure 16:Ant-v4 26 Published as a conference paper at ICLR 2026 Figure 17:Walker2d-v4 27
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.