What Spatial Memory Must Store: Occlusion as the Test for Language-Agent Memory
Pith reviewed 2026-06-27 13:45 UTC · model grok-4.3
The pith
Spatial memory in language agents requires geometry to lead recall and a separate occlusion visibility check rather than blending proximity with recency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
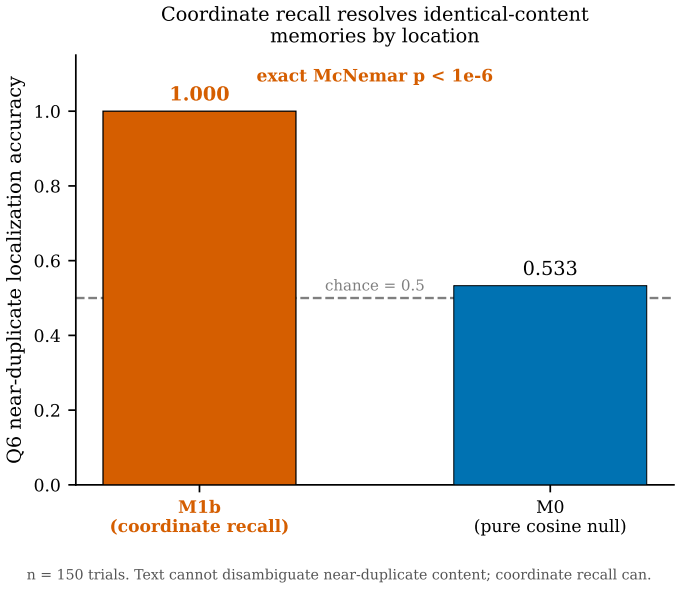
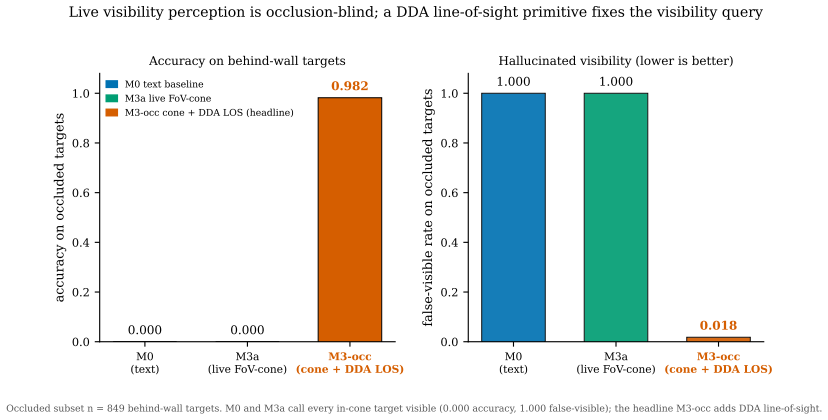
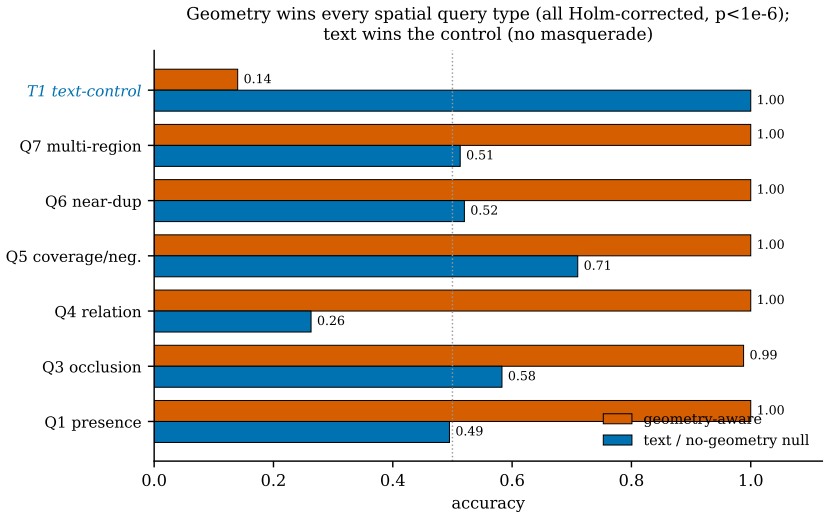
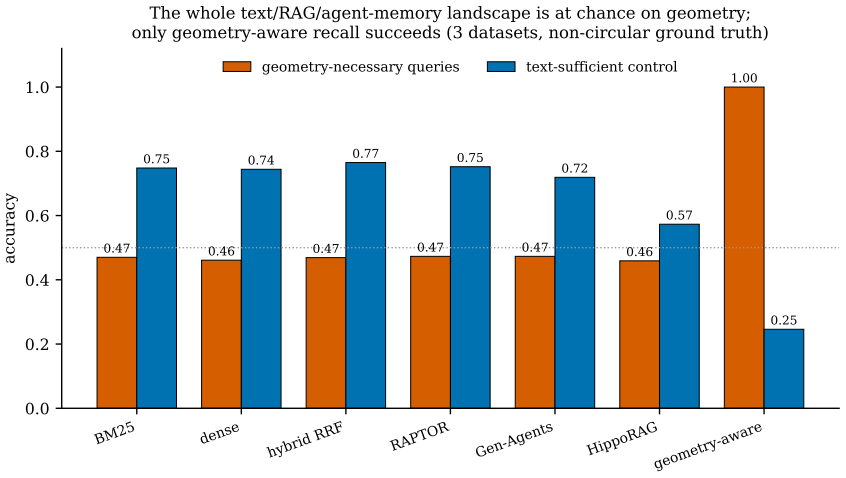
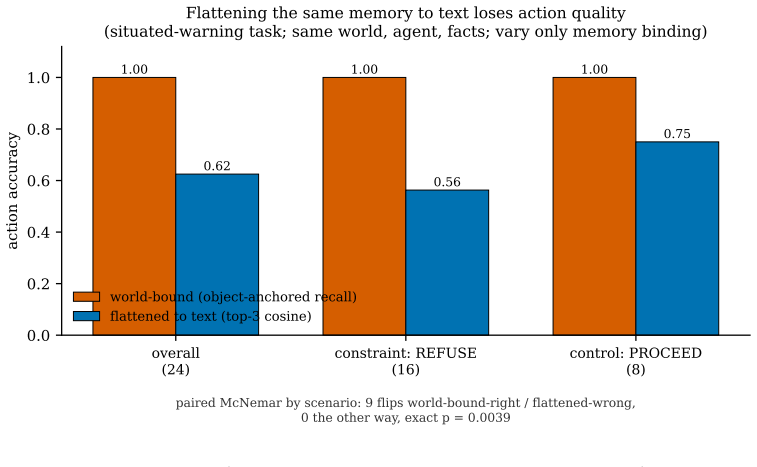
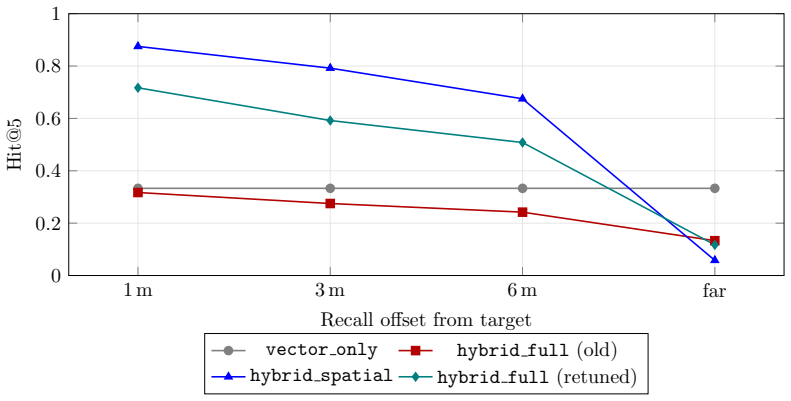
When the query regime is spatial, geometry must lead the weighting of memory recall, and recall must remain occlusion-blind while visibility is supplied on the fly by a ray-versus-voxel digital differential analyzer pointed from the agent's gaze. In pre-registered tests the standard blend failed to beat a position-blind baseline, but geometry-led weighting succeeded, and the DDA visibility predicate correctly identified 98 percent of behind-wall targets where text and field-of-view alone scored zero.
What carries the argument
A one-line ray-versus-voxel digital differential analyzer (DDA) that computes visibility from stored geometry without prior computation, paired with geometry-led recall weighting that overrides recency-importance blends.
If this is right
- The default proximity blend can be dropped in favor of a position-blind baseline when queries are not spatial.
- Coordinate recall resolves near-duplicate locations where cosine similarity on text fails.
- The visibility predicate can be inserted into live systems to cut false positives on hidden memories.
- Pre-registered live runs can surface and correct real defects in memory anchor placement.
Where Pith is reading between the lines
- The separation of recall from visibility could apply to agents operating in changing environments where geometry updates occur.
- Storing only the minimal geometry needed for occlusion checks might suffice instead of full maps.
- Similar predicate checks could be tested in vision-language memory systems for other hidden-object scenarios.
Load-bearing premise
The scripted worlds, automated oracle, and chosen metrics on selected targets are representative of broader language-agent use cases.
What would settle it
A new spatial recall task in which geometry-led weighting shows no gain over the blend or baseline, or in which the DDA visibility check fails to separate occluded from visible targets.
Figures
read the original abstract
Language-agent "memory palace" systems anchor each memory to a world coordinate, on the intuition that geometry adds something text cannot. We make that intuition testable and report three results. First, the memory-palace default of folding spatial proximity into a linear blend beside recency and importance does not help and can hurt: in a pre-registered recall experiment the shipped blend fails its own frozen test (mean Delta-Hit@5 -0.0375, Wilcoxon p=0.306), sitting at a position-blind baseline, while a geometry-led weighting wins decisively (+0.3208, p<10^-15): geometry must lead recall when the query regime is spatial. Second, memory recall and visibility must be separated: recall is occlusion-blind by design (you correctly remember the next room behind a wall), while visibility is a perception predicate over stored geometry that the live system never computed. A one-line ray-versus-voxel digital differential analyzer (DDA), re-pointed from the gaze ray the agent already casts, supplies it: text and the live FoV cone both score 0.000 on 849 behind-wall targets while cone-plus-DDA reaches 0.982 (exact McNemar p<10^-6); coordinate recall separately resolves near-duplicate locations a cosine null cannot (1.000 vs 0.533, n=150). Third, the visibility predicate is confirmed live under a git-committed pre-registration (SPMEM-OCC-LIVE-v1: eight scripted worlds, automated oracle scoring, 96 behind-wall targets, false-visible 1.000->0.000, pooled exact McNemar p=2.5x10^-29), a run that surfaced and fixed a real relay anchor defect. We concede that occlusion-needs-geometry is near-tautological; the contribution is the measurement and isolation, separating what spatial memory must store from how it is read. These pilots power a frozen confirmatory study (SPMEM-ZERO-REAL-PREREG-v1); the full human-authored multi-world study with blind raters remains future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that spatial memory systems for language agents require geometry to lead recall under spatial query regimes, and that recall must be separated from a visibility predicate (implemented via a one-line ray-versus-voxel DDA) to correctly handle occlusion. It reports three results from pre-registered experiments: a geometry-led weighting outperforms position-blind and blended baselines on Hit@5 in scripted worlds (Delta +0.3208, p<10^-15); text and FoV cone score 0 on 849 behind-wall targets while cone-plus-DDA reaches 0.982 (McNemar p<10^-6); and a live confirmation run (SPMEM-OCC-LIVE-v1) on 96 targets confirms the separation with pooled McNemar p=2.5x10^-29, fixing a relay defect. The work positions these as pilots for a future confirmatory study.
Significance. If the experimental isolation holds, the paper supplies a concrete, measurable distinction between what spatial memory must store (geometry for recall) and how it is read (occlusion-aware visibility), with credit for pre-registered design, external statistical tests, and a live run that surfaced a real implementation defect. This strengthens the empirical basis for memory-palace architectures in AI agents beyond intuition.
major comments (1)
- [Abstract and Experiments] Abstract and Experiments: The claim that 'geometry must lead recall when the query regime is spatial' and the separation result rest on scripted worlds with an automated oracle supplying perfect target locations and exact coordinate-match scoring. The manuscript should address whether these hold when queries are natural-language (with noisy spatial intent) and hits are judged by downstream LLM generation rather than coordinate match, as this directly bears on whether the reported isolation transfers beyond the controlled setting.
minor comments (2)
- The one-line DDA implementation is described at a high level; including the exact pseudocode or voxel traversal logic in the main text (rather than assuming reader familiarity) would improve reproducibility.
- Table or figure references for the 849-target and 96-target McNemar results would help readers locate the exact per-world breakdowns.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and for recognizing the pre-registered design, external statistical tests, and the live run that surfaced a real defect. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The claim that 'geometry must lead recall when the query regime is spatial' and the separation result rest on scripted worlds with an automated oracle supplying perfect target locations and exact coordinate-match scoring. The manuscript should address whether these hold when queries are natural-language (with noisy spatial intent) and hits are judged by downstream LLM generation rather than coordinate match, as this directly bears on whether the reported isolation transfers beyond the controlled setting.
Authors: We agree that the reported experiments operate in scripted worlds with perfect oracle locations and exact coordinate-match scoring. The manuscript already states that these are pilots powering a frozen confirmatory study (SPMEM-ZERO-REAL-PREREG-v1) and that the full human-authored multi-world study with blind raters remains future work. In the revision we will add an explicit limitations paragraph in the Discussion that (a) acknowledges the controlled nature of the current query regime and scoring, (b) notes that noisy natural-language spatial intent and downstream LLM generation metrics are outside the scope of the present pilots, and (c) outlines how the planned confirmatory study will test transfer under those conditions. We do not claim the isolation has already been shown to generalize; the contribution is the measurable separation demonstrated under the pre-registered, controlled conditions. revision: yes
Circularity Check
No significant circularity; empirical results stand on pre-registered measurements
full rationale
The paper reports three results from pre-registered experiments (Hit@5 deltas, McNemar tests on 849 and 96 targets across eight scripted worlds) that directly compare weighting schemes and visibility predicates against baselines. No equations, parameters, or uniqueness theorems are defined in terms of the target claims; the geometry-led weighting and cone-plus-DDA outcomes are measured outcomes rather than reductions to fitted inputs or self-citations. The authors explicitly note that occlusion-needs-geometry is near-tautological and position their contribution as the isolation via measurement, which is externally falsifiable via the reported statistics and oracle. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein. Generative Agents: Interactive Simulacra of Human Behavior.arXiv:2304.03442, 2023
Pith/arXiv arXiv 2023
-
[2]
C. Packer, S. Wooders, K. Lin, V. Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez. MemGPT: Towards LLMs as Operating Systems.arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[3]
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y. Zhang. A-MEM: Agentic Memory for LLM Agents.arXiv:2502.12110, 2025
Pith/arXiv arXiv 2025
-
[4]
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.arXiv:2504.19413, 2025
Pith/arXiv arXiv 2025
-
[5]
P. Rasmussen, P. Paliychuk, T. Beauvais, J. Ryan, and D. Chalef. Zep: A Temporal Knowledge Graph Architecture for Agent Memory.arXiv:2501.13956, 2025
Pith/arXiv arXiv 2025
-
[6]
Y. Yang et al. 3D-Mem: 3D Scene Memory for Embodied Exploration and Reasoning. arXiv:2411.17735, 2024. CVPR 2025
arXiv 2024
-
[7]
Z. Cai, Y. Du, C. Wang, and Y. Kong. Vision to Geometry: 3D Spatial Memory for Sequential Embodied MLLM Reasoning and Exploration.arXiv:2512.02458, 2025
arXiv 2025
-
[8]
Y. Lu, Y. Du, D. Liu, Y. Zhou, C. Wang, and Y. Yin. GSMem: 3D Gaussian Splatting as Per- sistent Spatial Memory for Zero-Shot Embodied Exploration and Reasoning.arXiv:2603.19137, 2026
arXiv 2026
-
[9]
J. Park and H. Kang. RenderMem: Rendering as Spatial Memory Retrieval.arXiv:2603.14669, 2026
arXiv 2026
-
[10]
Project Sid: Many-agent Simulations Toward AI Civilization.arXiv:2411.00114, 2024
Altera.AL et al. Project Sid: Many-agent Simulations Toward AI Civilization.arXiv:2411.00114, 2024
arXiv 2024
-
[11]
P. Sarthi, S. Abdullah, A. Tuli, S. Khanna, A. Goldie, and C. D. Manning. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval.ICLR, 2024. arXiv:2401.18059
Pith/arXiv arXiv 2024
-
[12]
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson. From Local to Global: A Graph RAG Approach to Query-Focused Summarization.arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
-
[13]
B. J. Guti´ errez, Y. Shu, Y. Gu, M. Yasunaga, and Y. Su. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models.NeurIPS, 2024. arXiv:2405.14831
arXiv 2024
-
[14]
Robertson and H
S. Robertson and H. Zaragoza. The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
2009
-
[15]
G. V. Cormack, C. L. A. Clarke, and S. Buettcher. Reciprocal Rank Fusion Outperforms Condorcet and Individual Rank Learning Methods.SIGIR, 2009
2009
-
[16]
Cosmos 3: Omnimodal World Models for Physical AI.arXiv:2606.02800, 2026
NVIDIA. Cosmos 3: Omnimodal World Models for Physical AI.arXiv:2606.02800, 2026
Pith/arXiv arXiv 2026
-
[17]
Li and the World Labs Team
F.-F. Li and the World Labs Team. A Functional Taxonomy of World Models. World Labs essay, 2026. 23
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.