Selection, Not Salience: The Shape and Limits of Personalization in Social Highlighting
Pith reviewed 2026-06-27 11:49 UTC · model grok-4.3
The pith
Personal history selects which documents and spans to highlight with a modest 0.13 gain but adds nothing at the sentence salience layer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
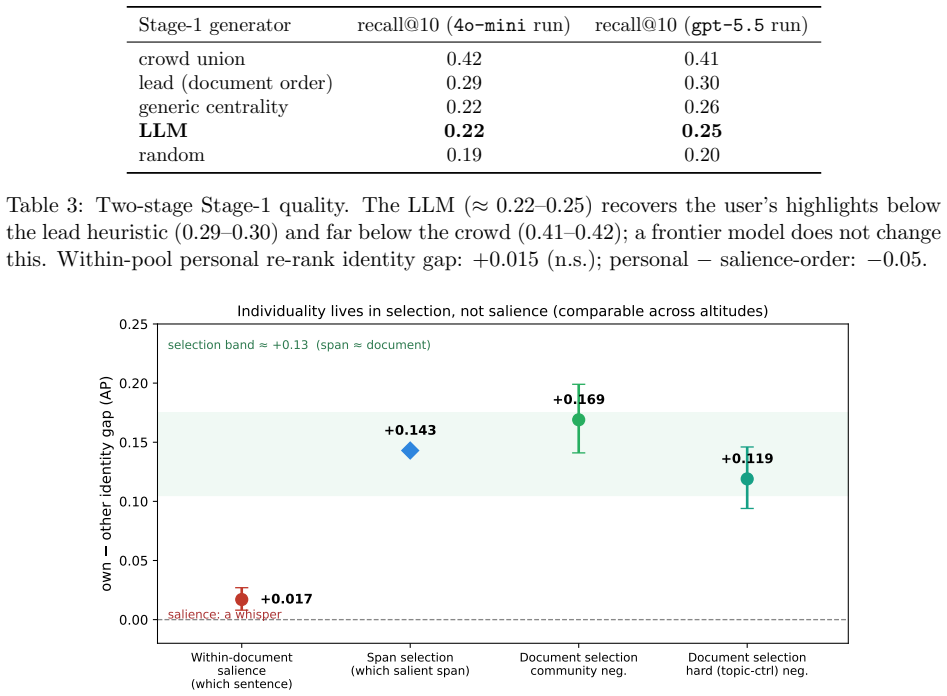
Using a co-readership identity control that holds document content and topic fixed, a person's history identifies their documents in a co-reading neighborhood with an own-versus-other gap of +0.169 against community negatives and +0.119 against topic-matched hard negatives; the selection-layer signal is comparable in magnitude at span altitude (+0.14) and is mostly stable topic preference, while a two-stage personalized auto-highlight model at sentence altitude yields no gain over its impersonal baseline and is beaten by salience order even on the highest-recall candidate pool.
What carries the argument
The co-readership identity control, which uses the same document highlighted by many users to hold content and topic fixed while measuring the own-versus-other gap in personal history.
If this is right
- The selection signal remains stable in size (+0.12 to +0.17) whether measured at document or span altitude.
- A content-based arm shows the document-level signal is largely thematic rather than driven solely by titles.
- Zero-shot LLMs, including frontier models, predict sentence highlight locations worse than a lead baseline.
- Personal re-ranking is outperformed by the impersonal salience order even when the candidate pool has high recall.
- Beyond the shared salience layer, aggregating individuals may outperform further individual personalization.
Where Pith is reading between the lines
- Social highlighting platforms could rely on community topic models for most of the measurable lift instead of building per-user salience predictors.
- The corrected control-in-negatives bias suggests that future studies using shared documents must audit negative sampling to avoid inflating personalization estimates.
- The same identity-control design could be applied to other annotation or recommendation tasks where multiple users interact with identical items.
Load-bearing premise
That the same document highlighted by many users holds content and topic fixed enough to isolate the effect of personal history without leakage from document differences.
What would settle it
A personal re-ranking model that produces a statistically significant lift over the lead baseline on sentence-level highlight prediction within the same co-readership dataset would falsify the claim of no reliable salience-layer gain.
Figures
read the original abstract
Does personalizing what a reader sees pay off, and where does it stop? Using a social web highlighter and a co-readership identity control (the same document highlighted by many users, which holds document and topic fixed and asks whether a person's own history predicts their marks better than another reader's does), we map the shape and limits of personalization across reading altitudes. At the document altitude we give the clean, leakage-free, identity-controlled measurement that prior next-document evaluations could only upper-bound: a person's history identifies which documents in a co-reading neighborhood are theirs, with an own-versus-other gap of +0.169 against community negatives and +0.119 against topic-matched hard negatives (both highly significant); a content-based arm suggests the signal is not purely title-driven but is largely thematic. This is comparable to the span-level selection signal (+0.14) from our prior work: the selection signal is of comparable magnitude across altitudes (+0.12 to +0.17), most of it stable topic preference. At the sentence altitude, a two-stage personalized auto-highlight (an impersonal model proposes candidates, a personal model re-ranks them) does not improve on its impersonal baseline: two off-the-shelf zero-shot LLMs, including a frontier model, predict highlight locations worse than a lead baseline, and personal re-ranking is beaten by the salience order even on the highest-recall candidate pool, so the null is not merely a Stage-1 ceiling artifact. Measurable personalization appears primarily at the selection layer: modest (~+0.13), topic-dominated, with no reliable gain at the salience layer. We also surface a control-in-negatives bias that inflated our document gap to a spurious +0.227 until audited. Going beyond the shared salience layer may be better approached by aggregating individuals than by personalizing them harder.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper uses a social web highlighter and a co-readership identity control (same document highlighted by multiple users, fixing document and topic) to measure personalization at document and sentence altitudes. It reports own-versus-other gaps of +0.169 (community negatives) and +0.119 (topic-matched hard negatives) at the document level, comparable to prior span-level selection signals (~+0.14), with the signal largely thematic rather than purely personal; at the sentence level, a two-stage personalized auto-highlight (impersonal candidates + personal re-rank) yields no improvement over impersonal baselines, with zero-shot LLMs underperforming a lead baseline and personal re-ranking beaten by salience order. The work also corrects a control-in-negatives bias that had inflated the document gap to +0.227. The central claim is that measurable personalization is modest (~+0.13), topic-dominated, and confined to the selection layer with no reliable salience-layer gains.
Significance. If the controlled gaps hold after further scrutiny of the identity control, the result supplies a clean, leakage-audited measurement of personalization limits that prior next-document evaluations could only upper-bound, with credit for the explicit bias audit, use of hard negatives, and content-based arm. This would support the practical implication that aggregation across users may outperform further individual personalization for salience tasks.
major comments (2)
- [Document-altitude results and control construction] The co-readership control (described in the methods and results sections on document altitude) is load-bearing for the claim that the +0.169/+0.119 own-versus-other gaps isolate personal history rather than shared topic or community preferences. The paper's own audit shows the gap is sensitive to negative construction (dropping from a spurious +0.227), yet no additional checks for residual user-overlap or community signals are reported; if such leakage exists, the attribution of the gap to 'largely thematic' personal selection would be weakened.
- [Sentence-altitude experiments] § on sentence-level experiments: the null result for personal re-ranking (beaten by salience order even on high-recall pools) and the LLM underperformance versus lead baseline are central to the 'no reliable gain at salience' conclusion, but the manuscript summarizes LLM prompts, exact negative sampling, and candidate-pool construction only at a high level. Full details are required to rule out post-hoc choices that could affect whether the null is robust.
minor comments (2)
- The abstract and results refer to 'two off-the-shelf zero-shot LLMs, including a frontier model' without naming the models or providing the exact prompts used; adding these would improve reproducibility.
- Table or figure presenting the bias-corrected gaps (+0.169, +0.119) versus the uncorrected +0.227 should explicitly label the negative-sampling variants for clarity.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive report. We respond to each major comment below and have revised the manuscript to incorporate additional controls and full experimental specifications.
read point-by-point responses
-
Referee: [Document-altitude results and control construction] The co-readership control (described in the methods and results sections on document altitude) is load-bearing for the claim that the +0.169/+0.119 own-versus-other gaps isolate personal history rather than shared topic or community preferences. The paper's own audit shows the gap is sensitive to negative construction (dropping from a spurious +0.227), yet no additional checks for residual user-overlap or community signals are reported; if such leakage exists, the attribution of the gap to 'largely thematic' personal selection would be weakened.
Authors: The co-readership identity control fixes both document and topic by design, as the same document is highlighted by multiple users; the hard-negative arm further matches on topic. The content-based arm already indicates the signal is largely thematic rather than title-driven. We agree that explicit checks for residual user overlap within co-reading sets would strengthen the isolation claim, and we have added these analyses (including overlap statistics and a community-preference ablation) to the revised methods and results sections. revision: yes
-
Referee: [Sentence-altitude experiments] § on sentence-level experiments: the null result for personal re-ranking (beaten by salience order even on high-recall pools) and the LLM underperformance versus lead baseline are central to the 'no reliable gain at salience' conclusion, but the manuscript summarizes LLM prompts, exact negative sampling, and candidate-pool construction only at a high level. Full details are required to rule out post-hoc choices that could affect whether the null is robust.
Authors: We agree that full reproducibility details are required. The revised manuscript now includes the complete LLM prompts (both zero-shot templates), the exact negative-sampling procedure (including how topic-matched and community negatives were drawn), and the full candidate-pool construction protocol (recall thresholds, pool sizes at each stage, and how the two-stage pipeline was implemented). These additions confirm that the null result holds across the reported conditions. revision: yes
Circularity Check
Minor self-citation for baseline comparison; central empirical measurements independent
specific steps
-
self citation load bearing
[Abstract]
"This is comparable to the span-level selection signal (+0.14) from our prior work: the selection signal is of comparable magnitude across altitudes (+0.12 to +0.17), most of it stable topic preference."
The paper invokes its own prior work solely to benchmark the new document-level gaps against the earlier +0.14 span-level figure. While this citation is not load-bearing for the primary claims (which rest on independent measurements), it constitutes the single minor self-citation noted in the evaluation.
full rationale
The paper's core results consist of direct empirical measurements of own-versus-other gaps at document altitude (+0.169/+0.119) and null results for personalized re-ranking at sentence altitude using LLMs, all derived from fresh analysis of the social highlighter dataset with the co-readership control. The sole self-citation is used only to contextualize effect-size magnitude against prior sentence-level work and does not derive, fit, or justify any of the new claims. No self-definitional relations, fitted inputs renamed as predictions, ansatz smuggling, or uniqueness theorems appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The co-readership identity control holds document content and topic fixed while varying only reader identity.
Forward citations
Cited by 3 Pith papers
-
Trait, Not State: The Durability of Reading Identity in Social Highlighting
Readers' highlighting patterns on a social web platform remain stable over 24 months as a durable trait, with personal profiles from early documents predicting future selections at roughly 3x the average precision of ...
-
Factions Within, Uncertain Across: Within-Document Reader Sub-Groups in Social Highlighting
Within-document highlighting shows strong reader sub-groups beyond null expectations from salience and popularity, but cross-document reproducibility of pair agreement is near zero and unresolved due to insufficient overlap.
-
The Long Tail, Not the Front Page: Cold-Start Prediction of Crowd Highlight Salience
A supervised logistic ranker on embeddings and features beats the lead baseline by 0.044 average precision in retrospective cold-start prediction of crowd highlights.
Reference graph
Works this paper leans on
-
[1]
K. Nakayashiki and K. Watanabe. Personal Salience: Highlighting Is Social, but Individuality Lives in Selection. arXiv:2606.09024, 2026
Pith/arXiv arXiv 2026
-
[2]
J. S. Park et al. Generative Agent Simulations of 1,000 People. arXiv:2411.10109, 2024
Pith/arXiv arXiv 2024
-
[3]
Salemi et al
A. Salemi et al. LaMP: When Large Language Models Meet Personalization. ACL, 2024
2024
-
[4]
Ao et al
X. Ao et al. PENS: A Dataset and Generic Framework for Personalized News Headline Gener- ation. ACL, 2021
2021
-
[5]
Gygli and M
M. Gygli and M. Soleymani. PHD-GIFs: Personalized Highlight Detection for Automatic GIF Creation. ACM MM, 2018
2018
-
[6]
Vansh, D
R. Vansh, D. Rank, S. Dasgupta, and T. Chakraborty. Accuracy Is Not Enough: Evaluating Personalization in Summarizers. Findings of EMNLP, 2023
2023
-
[7]
S. Dasgupta et al. PerSEval: Assessing Personalization in Text Summarizers. arXiv:2407.00453, 2024
arXiv 2024
-
[8]
Krichene and S
W. Krichene and S. Rendle. On Sampled Metrics for Item Recommendation. KDD, 2020. 8
2020
-
[9]
Y. Ji, A. Sun, J. Zhang, and C. Li. A Re-visit of the Popularity Baseline in Recommender Systems. SIGIR, 2020
2020
-
[10]
J. Trienes et al. Behavioral Analysis of Information Salience in Large Language Models. arXiv:2502.14613, 2025
arXiv 2025
-
[11]
Winchell et al
A. Winchell et al. Highlights as an Early Predictor of Student Comprehension and Interests. Cognitive Science, 2020
2020
-
[12]
Schoenegger et al
P. Schoenegger et al. Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy. Science Advances, 2024. 9
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.