LakeQA: An Exploratory QA Benchmark over a Million-Scale Data Lake
Pith reviewed 2026-06-27 13:39 UTC · model grok-4.3
The pith
LakeQA is a benchmark that tests whether language models can search a 9.5 TB data lake and compose multi-hop answers from heterogeneous sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
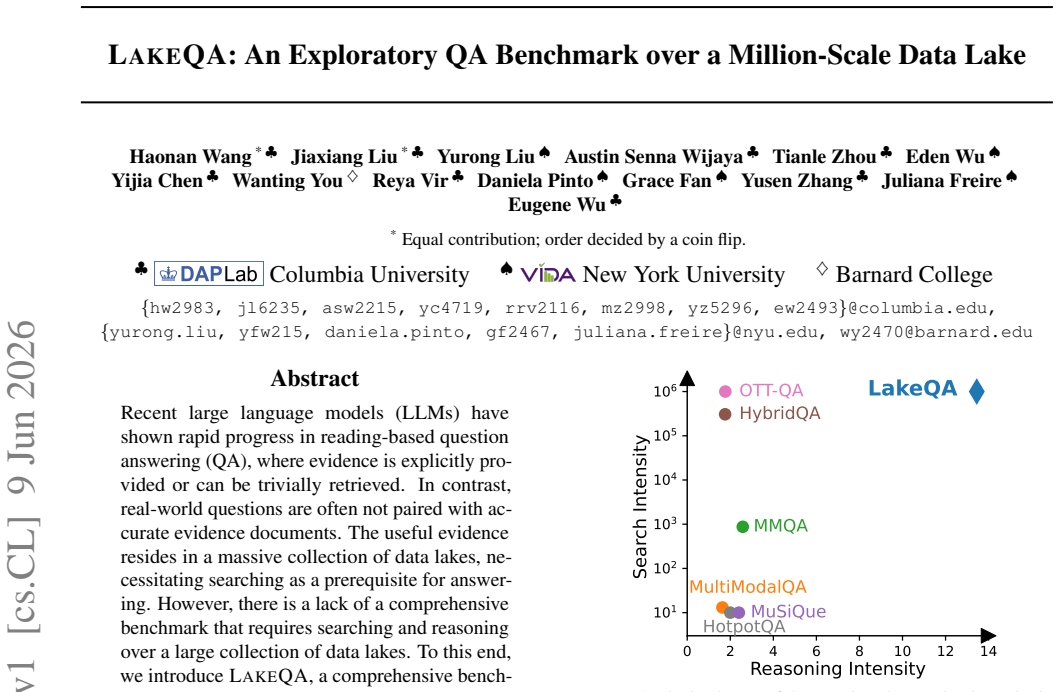
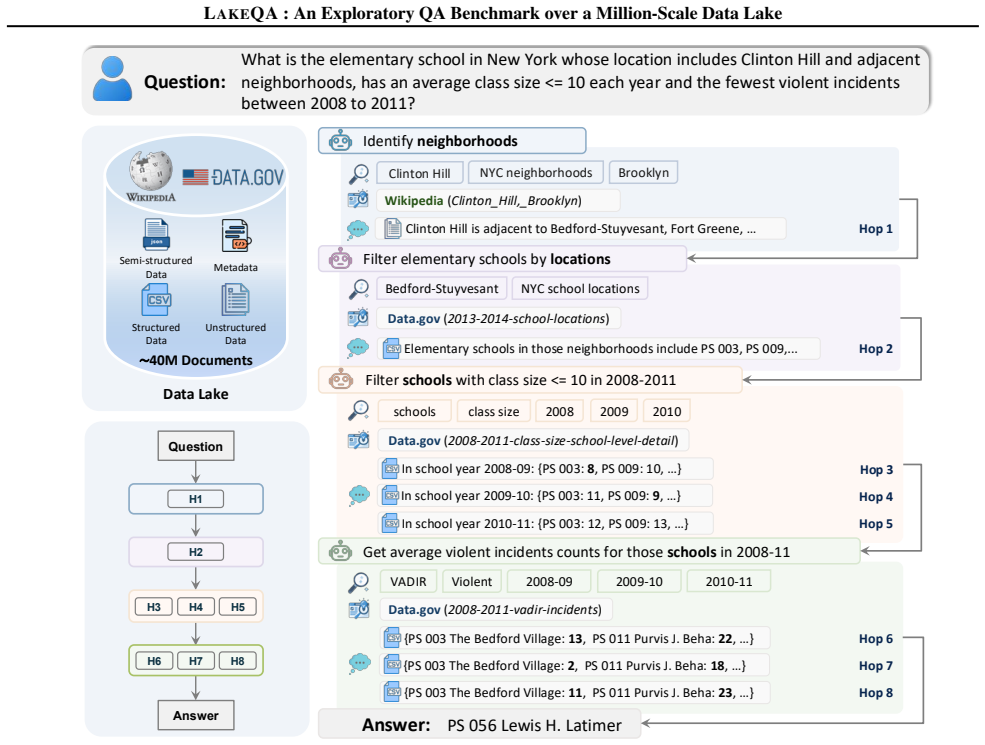
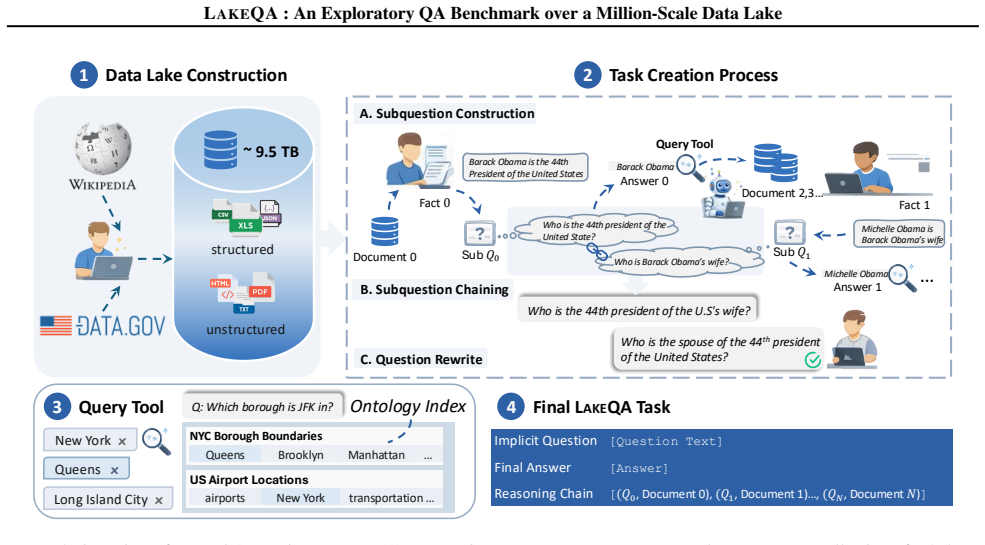
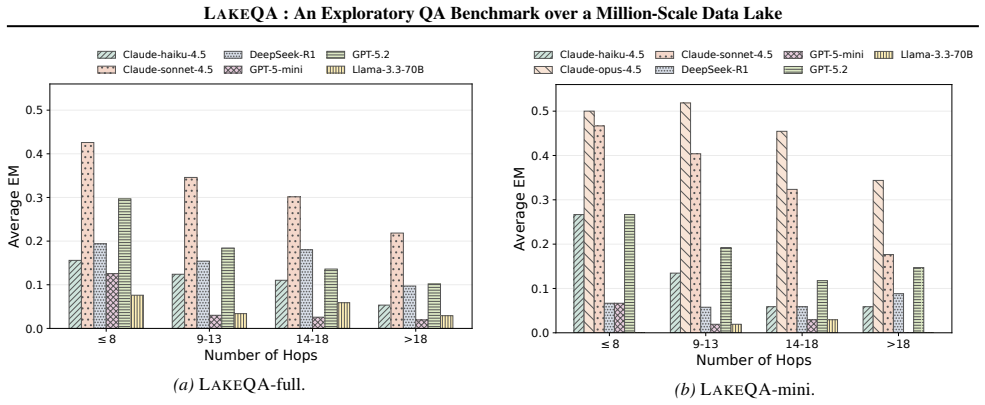
LakeQA is a comprehensive benchmark for search-centric question answering over data lakes that jointly emphasizes searching and reasoning capabilities. It is built on a heterogeneous collection of approximately 9.5 TB of text resources from Wikipedia and open-source government data. Each sample is annotated by at least one Ph.D.-level expert, and each task requires long-horizon multi-hop reasoning with implicit intermediate steps: agents need to discover the correct documents and then compose evidence across sources to produce the answer. Experimental results on seven frontier LLMs demonstrate that LakeQA is challenging, with GPT-5.2 achieving only an exact-match score of 18.37 percent.
What carries the argument
LakeQA benchmark, a collection of expert-annotated questions over 9.5 TB of mixed structured and unstructured sources that forces an agent to locate documents before performing multi-hop composition.
If this is right
- Current LLMs cannot reliably answer questions whose supporting facts are scattered across a data lake and must be located first.
- Progress on LakeQA would require agents that interleave document discovery with evidence composition.
- The benchmark supplies a concrete testbed for measuring whether new retrieval-augmented or agentic systems close the observed performance gap.
- Scores on LakeQA are expected to remain low until models improve at handling implicit multi-hop paths rather than surface-level retrieval.
Where Pith is reading between the lines
- Success on LakeQA would likely transfer to private enterprise data lakes that share the same scale and heterogeneity.
- The construction method could be reused to create similar benchmarks for domains such as scientific literature or legal corpora.
- If models improve on LakeQA while retrieval quality is held fixed, the gain would isolate advances in the reasoning step itself.
Load-bearing premise
Expert annotation by Ph.D.-level reviewers guarantees that every question truly demands long-horizon search and multi-hop reasoning across heterogeneous sources rather than being solvable from a single document or trivial lookup.
What would settle it
A controlled experiment in which frontier models, given only the LakeQA questions and no retrieval tools, achieve exact-match scores above 70 percent, or an audit showing that most questions can be answered from one document without implicit intermediate steps.
Figures
read the original abstract
Recent large language models (LLMs) have shown rapid progress in reading-based question answering (QA), where evidence is explicitly provided or can be trivially retrieved. In contrast, real-world questions are often not paired with accurate evidence documents. The useful evidence resides in massive data lakes, making search a prerequisite for answering. However, there is a lack of comprehensive benchmarks that require both searching and reasoning over large data lakes. To this end, we introduce LakeQA, a comprehensive benchmark for search-centric question answering over data lakes that jointly emphasizes searching and reasoning capabilities. LakeQA is built on a heterogeneous collection of approximately 9.5 TB of text resources from Wikipedia and open-source government data, spanning structured and unstructured data. To ensure task quality, each sample is annotated by at least one Ph.D.-level expert. Each task requires long-horizon multi-hop reasoning with implicit intermediate steps: agents need to discover the correct documents and then compose evidence across sources to produce the answer. Experimental results on seven frontier LLMs demonstrate that LakeQA is challenging. For instance, GPT-5.2 achieves only an exact-match score of 18.37% on LakeQA. Overall, LakeQA provides a realistic testbed for developing LLM agents that can both find and analyze data in modern data lakes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LakeQA, a benchmark for search-centric question answering over heterogeneous data lakes (~9.5 TB from Wikipedia and open government sources). It claims that each of its tasks requires long-horizon multi-hop reasoning with implicit intermediate steps across sources, ensured by annotation from at least one Ph.D.-level expert, and reports that seven frontier LLMs perform poorly (e.g., GPT-5.2 achieves 18.37% exact-match).
Significance. If the tasks are verifiably multi-hop and search-dependent, LakeQA would address a genuine gap between reading-based QA benchmarks and realistic data-lake settings, providing a useful testbed for agentic systems that must both retrieve and compose evidence.
major comments (3)
- [Abstract and §3] Abstract and §3 (Benchmark Construction): the central claim that 'each task requires long-horizon multi-hop reasoning with implicit intermediate steps' and that 'agents need to discover the correct documents and then compose evidence across sources' rests solely on the statement that samples were annotated by Ph.D.-level experts. No inter-annotator agreement, no per-task reasoning-depth statistics, no pilot comparisons against single-hop or direct-lookup baselines, and no failure analysis of simpler retrieval methods are reported; without these, the 'search-centric' and 'multi-hop' characterizations cannot be assessed.
- [§3 and §4] §3 and §4 (Data Construction and Evaluation): the manuscript provides no description of sampling strategy, exclusion rules, how heterogeneity across structured/unstructured sources is operationalized, or the precise evaluation metrics (exact match is mentioned but not defined or justified relative to partial credit or retrieval-aware measures). These omissions make it impossible to reproduce or interpret the reported LLM scores.
- [§5] §5 (Experiments): the claim that LakeQA is 'challenging' is supported only by aggregate scores on seven LLMs; no ablation isolating search difficulty from reasoning difficulty, no error analysis by hop count, and no comparison to non-LLM baselines are supplied, weakening the assertion that the benchmark jointly tests both capabilities.
minor comments (2)
- [Abstract] The scale claim ('million-scale data lake') should be accompanied by explicit counts of documents, tables, and entities rather than only the 9.5 TB figure.
- [§4] Notation for the exact-match metric and any retrieval metrics should be defined in a dedicated evaluation subsection.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will make substantial revisions to improve documentation, add supporting analyses, and enhance reproducibility.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Benchmark Construction): the central claim that 'each task requires long-horizon multi-hop reasoning with implicit intermediate steps' and that 'agents need to discover the correct documents and then compose evidence across sources' rests solely on the statement that samples were annotated by Ph.D.-level experts. No inter-annotator agreement, no per-task reasoning-depth statistics, no pilot comparisons against single-hop or direct-lookup baselines, and no failure analysis of simpler retrieval methods are reported; without these, the 'search-centric' and 'multi-hop' characterizations cannot be assessed.
Authors: We agree that additional quantitative support would strengthen the multi-hop and search-centric claims beyond expert annotation. The revised manuscript will report inter-annotator agreement on a multi-annotated subset, per-task reasoning-depth statistics extracted from expert notes, a pilot comparison of single-hop variants versus the full tasks, and failure rates of simpler retrieval baselines to better validate the characterizations. revision: yes
-
Referee: [§3 and §4] §3 and §4 (Data Construction and Evaluation): the manuscript provides no description of sampling strategy, exclusion rules, how heterogeneity across structured/unstructured sources is operationalized, or the precise evaluation metrics (exact match is mentioned but not defined or justified relative to partial credit or retrieval-aware measures). These omissions make it impossible to reproduce or interpret the reported LLM scores.
Authors: We acknowledge these omissions hinder reproducibility. The revised §3 and §4 will detail the sampling strategy from the 9.5 TB lake, explicit exclusion rules, how heterogeneity is operationalized (e.g., source-type distributions per question), and a precise definition of exact match with justification relative to alternatives such as token-level F1 or retrieval-aware metrics. revision: yes
-
Referee: [§5] §5 (Experiments): the claim that LakeQA is 'challenging' is supported only by aggregate scores on seven LLMs; no ablation isolating search difficulty from reasoning difficulty, no error analysis by hop count, and no comparison to non-LLM baselines are supplied, weakening the assertion that the benchmark jointly tests both capabilities.
Authors: We accept that aggregate LLM scores alone do not fully isolate search versus reasoning difficulty. The revised §5 will incorporate an ablation separating retrieval and composition stages, error analysis broken down by estimated hop count, and comparisons to non-LLM baselines (e.g., BM25 retrieval plus heuristic reasoning) to more rigorously demonstrate the joint challenges. revision: yes
Circularity Check
No derivations, equations, or fitted quantities present
full rationale
LakeQA is a benchmark introduction paper with no mathematical derivations, equations, parameter fittings, or prediction steps. Claims about task properties rest on expert annotation rather than any self-referential construction or self-citation chain that reduces to inputs. No load-bearing steps match the enumerated circularity patterns; the work is self-contained as a dataset description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ph.D.-level expert annotation ensures task quality and realism
Reference graph
Works this paper leans on
-
[1]
Chen, W., Chang, M.-W., Schlinger, E., Wang, W., and 9 LAKEQA : An Exploratory QA Benchmark over a Million-Scale Data Lake Cohen, W. W. Open question answering over tables and text.arXiv preprint arXiv:2010.10439, 2020a. Chen, W., Zha, H., Chen, Z., Xiong, W., Wang, H., and Wang, W. Y . Hybridqa: A dataset of multi-hop question answering over tabular and ...
arXiv 2010
-
[2]
Lakebench: A benchmark for discovering joinable and unionable tables in data lakes
Deng, Y ., Chai, C., Li, L., Luo, S., Qin, Y ., Lian, J., and Li, G. Lakebench: A benchmark for discovering joinable and unionable tables in data lakes. InProceedings of the VLDB Endowment, volume 17, pp. 1925–1938,
1925
-
[3]
Dua, D., Wang, Y ., Dasigi, P., Stanovsky, G., Singh, S., and Gardner, M. Drop: A reading comprehension bench- mark requiring discrete reasoning over paragraphs.arXiv preprint arXiv:1903.00161,
Pith/arXiv arXiv 1903
-
[4]
F., Olston, C., Polyzotis, N., Roy, S., and Whang, S
Halevy, A., Korn, F., Noy, N. F., Olston, C., Polyzotis, N., Roy, S., and Whang, S. E. Goods: Organizing google’s datasets. InProceedings of the 2016 International Con- ference on Management of Data, pp. 795–806,
2016
-
[5]
Characterizing deep research: A benchmark and formal definition.arXiv preprint arXiv:2508.04183,
Java, A., Khandelwal, A., Midigeshi, S., Halfaker, A., Desh- pande, A., Goyal, N., Gupta, A., Natarajan, N., and Sharma, A. Characterizing deep research: A benchmark and formal definition.arXiv preprint arXiv:2508.04183,
-
[6]
Dense passage retrieval for open-domain question answering
Karpukhin, V ., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6769–6781,
2020
-
[7]
Looking beyond the surface: A challenge set for reading comprehension over multiple sentences
Khashabi, D., Chaturvedi, S., Roth, M., Upadhyay, S., and Roth, D. Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. InPro- ceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 252–262,
2018
-
[8]
Li, S., Bu, X., Wang, W., Liu, J., Dong, J., He, H., Lu, H., Zhang, H., Jing, C., Li, Z., et al. Mm-browsecomp: A comprehensive benchmark for multimodal browsing agents.arXiv preprint arXiv:2508.13186,
-
[9]
doi: 10.1109/TPAMI.2018.2889473. Microsoft. Overview of copilot in Fabric. https://le arn.microsoft.com/en-us/fabric/funda mentals/copilot-fabric-overview,
-
[10]
J., Pu, K
Nargesian, F., Zhu, E., Miller, R. J., Pu, K. Q., and Arocena, P. C. Data lake management: challenges and opportu- nities.Proceedings of the VLDB Endowment, 12(12): 1986–1989,
1986
-
[11]
Accessed: 2026-05-27. OpenAI. Inside OpenAI’s in-house data agent. https: //openai.com/index/inside-our-in-hou se-data-agent/,
2026
-
[12]
Lancedb - embracing composability in the storage layer
Pace, W., She, C., Xu, L., Jones, W., Meng, R., and Cen, Y . Lancedb - embracing composability in the storage layer. InVLDB 2025 Workshop: Third International Workshop on Composable Data Management Systems,
2025
-
[13]
Parikh, A
URL https://www.vldb.org/2025/Workshops/ VLDB-Workshops-2025/CDMS/CDMS25_15.p df. Parikh, A. P., Wang, X., Gehrmann, S., Faruqui, M., Dhin- gra, B., Yang, D., and Das, D. Totto: A controlled table- to-text generation dataset. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1173–1186,
2025
-
[14]
Know what you don’t know: Unanswerable questions for squad.arXiv preprint arXiv:1806.03822,
Rajpurkar, P., Jia, R., and Liang, P. Know what you don’t know: Unanswerable questions for squad.arXiv preprint arXiv:1806.03822,
-
[15]
The Web as a Knowledge-base for Answering Complex Questions
doi: 10.1561/1500000019. Talmor, A. and Berant, J. The web as a knowledge- base for answering complex questions.arXiv preprint arXiv:1803.06643,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1561/1500000019
-
[16]
Talmor, A., Yoran, O., Catav, A., Lahav, D., Wang, Y ., Asai, A., Ilharco, G., Hajishirzi, H., and Berant, J. Multi- modalqa: Complex question answering over text, tables and images.arXiv preprint arXiv:2104.06039,
-
[17]
Wei, J., Sun, Z., Papay, S., McKinney, S., Han, J., Fulford, I., Chung, H. W., Passos, A. T., Fedus, W., and Glaese, A. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516,
-
[18]
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhut- dinov, R., and Manning, C. D. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380,
2018
-
[19]
Zhang, H., Liu, Y ., Santos, A., Hung, W.-L., and Freire, J. Autoddg: Automated dataset description generation using large language models.arXiv preprint arXiv:2502.01050, 2025a. Zhang, S. and Balog, K. Web table extraction, retrieval, and augmentation: A survey.ACM Transactions on Intelligent Systems and Technology, 11(2):1–35,
-
[20]
Zhang, Y ., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., Huang, F., and Zhou, J. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025b. Zhu, E., Deng, D., Nargesian, F., and Miller, R. J. JOSIE: Overlap set similarity search for finding joinable tabl...
Pith/arXiv arXiv 2019
-
[21]
[Text, Table, Image, Explicit Multi-hop Reasoning] MultiModalQA extends existing reading comprehension datasets such as Natural Questions (NQ) (Kwiatkowski et al., 2019), BoolQ (Clark et al., 2019), and HotpotQA (Yang et al.,
2019
-
[22]
[Table, Free-form Response, Wikipedia] FETAQA extends existing table QA benchmarks whose answers are typically short answers evaluated by exact matching by introducing long, informative free-form answers grounded in a single Wikipedia table. To construct such questions, FETAQA starts from ToTTo (Parikh et al., 2020), a large-scale table-to-text dataset co...
2020
-
[23]
result": ...} or {
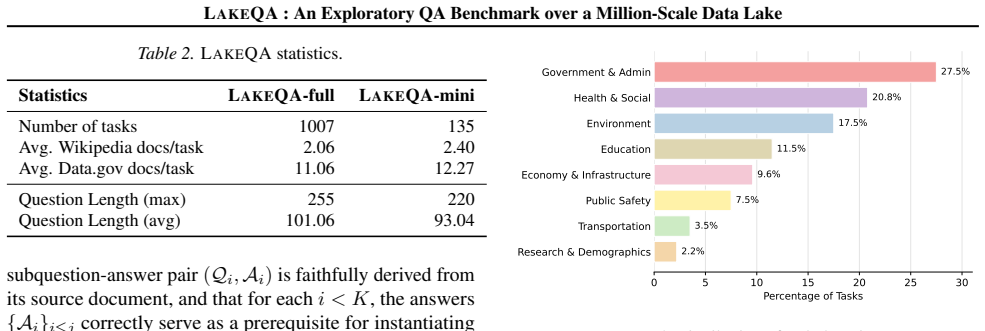
Table 9.Distribution of benchmark tasks across data.gov theme categories. Theme Category Tasks Government & Admin 428 Environment 272 Transportation 54 Health & Social 324 Research & Demographics 35 Economy & Infrastructure 149 Public Safety 116 Education 179 F . Agent Interface Tool Implementations.All data access tools operate over a fixed S3 data lake ...
2020
-
[24]
question
who is US president after 2000 , and in a hop, we take an intersection between the two subquestions: who is a Democratics US President after 2000 , as long as the answer to the intersection is correct, the task is fine – because eventually each task is consist of the final question and its answer, all subquestion and facts are just for the sake of creatin...
2000
-
[25]
, "revision_subquestion
The intersection of all nodes in node 4 are still 12 districts. Yet, they somehow all transform into the 6 counties that contain those 12 districts any sources.", "revision_subquestion": "Add nodes 4 and 5 to convert the districts into counties. Here are the districts: Camas School DistrictCarbonado School DistrictColfax School DistrictDieringer School Di...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.