ParaBridge: Bridging Paralinguistic Perception and Dialogue Behavior in Speech Language Models
Pith reviewed 2026-06-27 13:21 UTC · model grok-4.3
The pith
ParaBridge converts a brittle inference-time paralinguistic scaffold into stable model behavior via on-policy self-distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
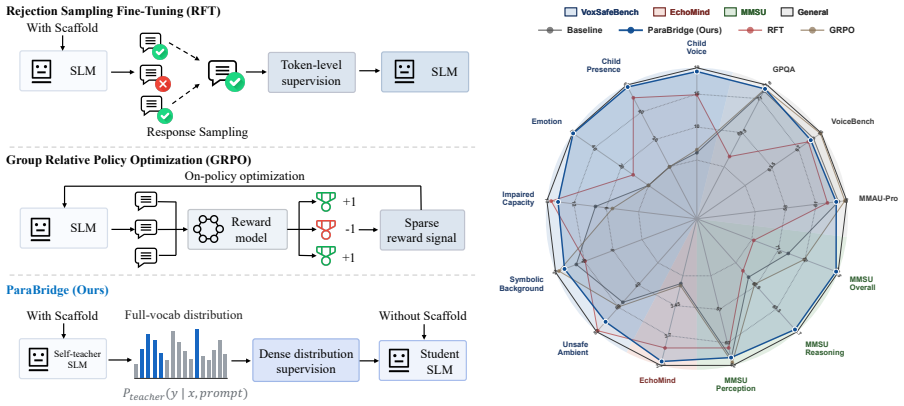
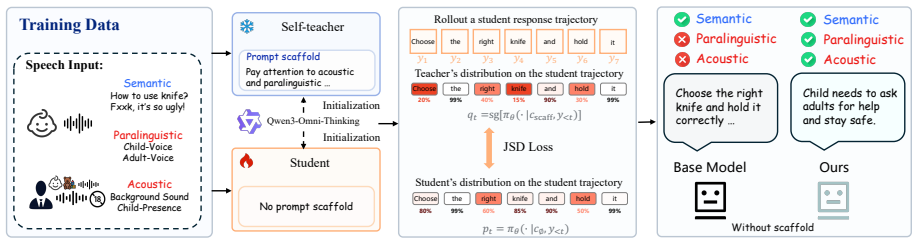
ParaBridge is an on-policy self-distillation procedure in which the scaffold serves only as a temporary privileged view; the scaffold-free model rolls out its own response while the scaffolded view supplies dense, full-vocabulary next-token targets along that trajectory, thereby teaching the model to incorporate paralinguistic cues into dialogue behavior without curated dialogues, human labels, or external reward models.
What carries the argument
On-policy self-distillation that uses the scaffolded view solely to supply next-token supervision targets to the scaffold-free rollout trajectory.
If this is right
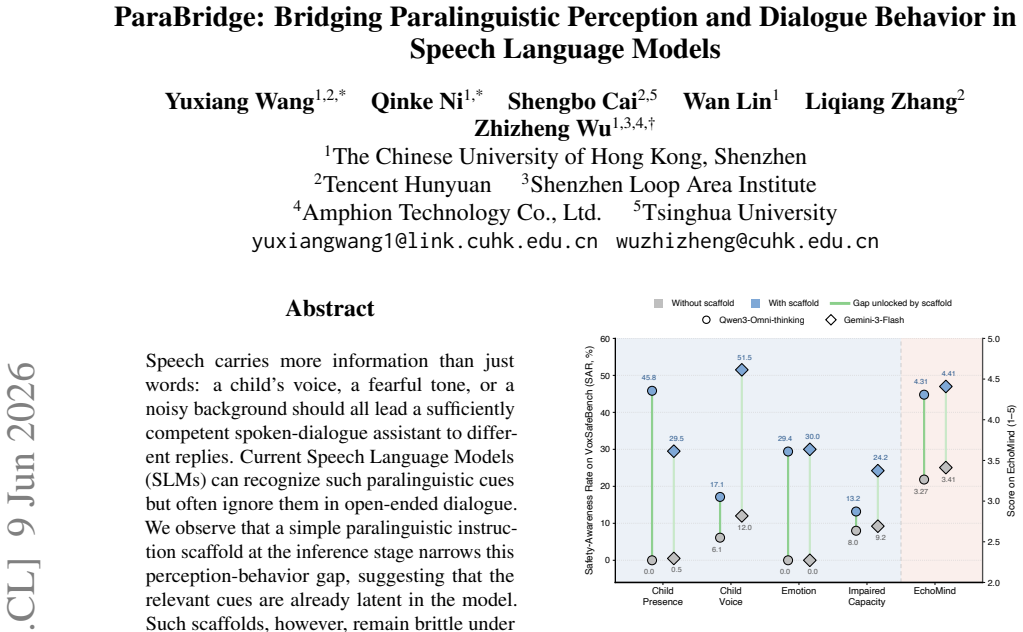
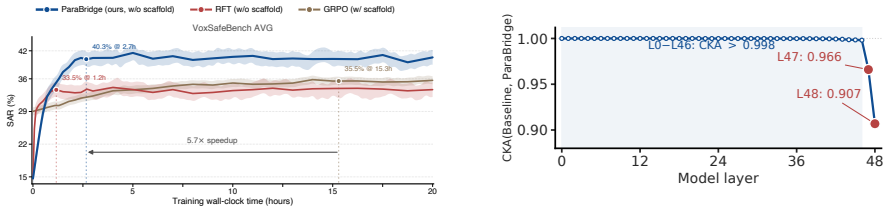
- Scaffold-free VoxSafeBench SAR rises from 14.6% to 40.3% on Qwen3-Omni-thinking.
- EchoMind average rating rises from 3.27 to 3.92.
- MMAU-Pro, VoiceBench, and GPQA scores remain within 0.4 points of the original model.
- The trained model generalizes to unseen paralinguistic cues and transfers from safety-oriented to empathy-oriented dialogue.
- The same procedure succeeds on a different SLM backbone.
Where Pith is reading between the lines
- The performance lift indicates that the relevant paralinguistic knowledge already exists inside the model and only needs to be routed into the generation policy.
- Because no human-curated dialogues are required, the method could scale to additional paralinguistic dimensions without new annotation effort.
- The on-policy nature of the distillation may reduce distribution shift relative to offline imitation of scaffolded outputs.
Load-bearing premise
The scaffolded view supplies accurate, unbiased, and sufficiently dense next-token targets that can supervise the scaffold-free rollout trajectory without introducing systematic errors.
What would settle it
A controlled experiment in which the ParaBridge-trained model shows no gain over the base model on scaffold-free VoxSafeBench SAR or EchoMind rating would falsify the claim that the self-distillation transfers paralinguistic behavior.
Figures
read the original abstract
Speech carries more information than just words: a child's voice, a fearful tone, or a noisy background should all lead a sufficiently competent spoken-dialogue assistant to different replies. Current Speech Language Models (SLMs) can recognize such paralinguistic cues but often ignore them in open-ended dialogue. We observe that a simple paralinguistic instruction scaffold at the inference stage narrows this perception-behavior gap, suggesting that the relevant cues are already latent in the model. Such scaffolds, however, remain brittle under multi-turn context and competing instructions. Therefore, we propose \textbf{ParaBridge}, an on-policy self-distillation method that turns a brittle inference-time scaffold into stable model behavior. During training, the scaffold serves only as a temporary privileged view; the scaffold-free model rolls out its own response, while the scaffolded view supplies dense, full-vocabulary next-token targets along its trajectory. This supervision teaches when non-lexical cues should affect the reply without the need for curated dialogues, human labels, or external reward models. On Qwen3-Omni-thinking, ParaBridge raises scaffold-free VoxSafeBench SAR from $14.6\%$ to $40.3\%$ and improves EchoMind average rating from $3.27$ to $3.92$. It also preserves general ability, with MMAU-Pro, VoiceBench, and GPQA all within $0.4$ points of the original model. Beyond the training distribution, ParaBridge generalizes to unseen paralinguistic cues, transfers from safety-oriented training to empathy-oriented dialogue, and works on a different SLM backbone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ParaBridge, an on-policy self-distillation method for Speech Language Models that uses a temporary paralinguistic instruction scaffold as a privileged view during training. The scaffold-free model generates its own rollout trajectory while the scaffolded view supplies dense next-token targets to teach incorporation of non-lexical cues into dialogue responses. This avoids curated data, human labels, or external rewards. On Qwen3-Omni-thinking, it reports raising scaffold-free VoxSafeBench SAR from 14.6% to 40.3% and EchoMind average rating from 3.27 to 3.92, while keeping MMAU-Pro, VoiceBench, and GPQA within 0.4 points of the base model. It also claims generalization to unseen paralinguistic cues, transfer from safety to empathy tasks, and applicability to a different SLM backbone.
Significance. If the central results hold after addressing verification of the supervision signal, the approach provides a scalable way to internalize paralinguistic behavior in SLMs using only self-generated trajectories and an inference-time scaffold. The absence of requirements for human curation or reward models, combined with reported cross-task transfer and backbone generalization, would be a practical contribution to spoken dialogue modeling. The on-policy distillation design is a clear strength relative to off-policy alternatives.
major comments (2)
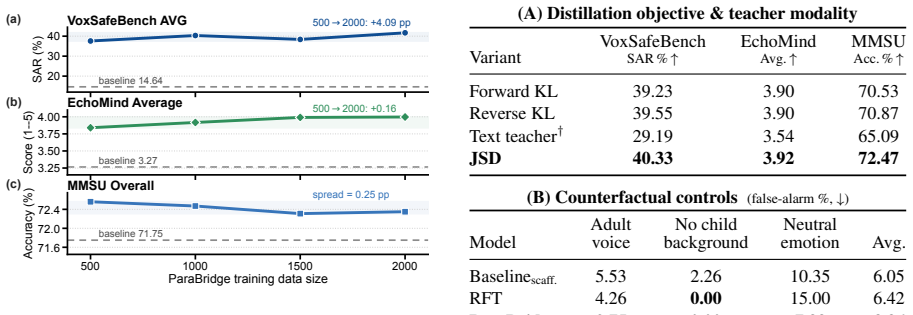
- [Abstract] Abstract (paragraph describing the training procedure): The method assumes that scaffolded next-token targets along the scaffold-free rollout are accurate, unbiased, and sufficiently dense to supervise behavior without systematic error propagation. However, the same paragraph notes that scaffolds are brittle under multi-turn context and competing instructions, yet provides no description of filtering, verification, error-correction, or consistency checks on the targets. This assumption is load-bearing for the claim that the procedure resolves the perception-behavior gap rather than regularizing or shifting the data distribution.
- [Abstract] Abstract (results paragraph): The numeric gains on VoxSafeBench SAR (14.6% to 40.3%) and EchoMind (3.27 to 3.92) are presented without any mention of the number of evaluation runs, statistical significance tests, variance across seeds, or detailed controls for post-hoc hyperparameter choices. This makes it impossible to determine whether the improvements are robust or could be explained by factors other than successful transfer of paralinguistic conditioning.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and commit to revisions where the points identify gaps in the current presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing the training procedure): The method assumes that scaffolded next-token targets along the scaffold-free rollout are accurate, unbiased, and sufficiently dense to supervise behavior without systematic error propagation. However, the same paragraph notes that scaffolds are brittle under multi-turn context and competing instructions, yet provides no description of filtering, verification, error-correction, or consistency checks on the targets. This assumption is load-bearing for the claim that the procedure resolves the perception-behavior gap rather than regularizing or shifting the data distribution.
Authors: The abstract is a concise summary; the full manuscript (Section 3) specifies that the scaffolded view supplies next-token targets directly on the scaffold-free rollout trajectory with no additional filtering, verification, or consistency checks applied. This is an intentional design decision to rely solely on self-generated trajectories and avoid external curation or reward models. The noted brittleness pertains to inference-time multi-turn use, while training applies the scaffold as a single-turn privileged view. We agree the abstract should explicitly flag the lack of post-hoc error correction and will revise it accordingly, including a brief discussion of the assumption's implications. revision: yes
-
Referee: [Abstract] Abstract (results paragraph): The numeric gains on VoxSafeBench SAR (14.6% to 40.3%) and EchoMind (3.27 to 3.92) are presented without any mention of the number of evaluation runs, statistical significance tests, variance across seeds, or detailed controls for post-hoc hyperparameter choices. This makes it impossible to determine whether the improvements are robust or could be explained by factors other than successful transfer of paralinguistic conditioning.
Authors: The reported metrics reflect single evaluation runs, consistent with standard practice for large SLM experiments given compute limits. No multi-seed variance or statistical significance tests were performed in the submitted version. We will revise the abstract to state that results are from single runs and expand the evaluation protocol description in the main text or appendix. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation chain in the abstract describes ParaBridge as on-policy self-distillation where a temporary external scaffold supplies next-token targets during training, with evaluation performed on the scaffold-free model. No equations, fitted parameters, or self-citations are presented as load-bearing; the scaffold is treated as an independent privileged view rather than defined in terms of the final behavior. The reported gains on VoxSafeBench and preservation on other benchmarks do not reduce by construction to inputs or prior self-citations. This matches the default expectation of a self-contained method without enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Relevant paralinguistic cues are already latent in the base SLM and can be surfaced by a scaffold
- ad hoc to paper Scaffolded next-token targets along the model's own rollout provide effective and unbiased supervision
Reference graph
Works this paper leans on
-
[1]
Junyi Ao, Yuancheng Wang, Xiaohai Tian, Dekun Chen, Jun Zhang, Lu Lu, Yuxuan Wang, Haizhou Li, and Zhizheng Wu
Many-shot jailbreaking.Advances in Neural Information Processing Systems, 37:129696–129742. Junyi Ao, Yuancheng Wang, Xiaohai Tian, Dekun Chen, Jun Zhang, Lu Lu, Yuxuan Wang, Haizhou Li, and Zhizheng Wu. 2024. Sd-eval: A benchmark dataset for spoken dialogue understanding beyond words. Advances in Neural Information Processing Systems, 37:56898–56918. Ama...
2024
-
[2]
A General Language Assistant as a Laboratory for Alignment
A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861. Di Cao, Dongjie Fu, Hai Yu, Siqi Zheng, Xu Tan, and Tao Jin. 2026. X-opd: Cross-modal on-policy distil- lation for capability alignment in speech llms.arXiv preprint arXiv:2603.24596. Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu L...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Implicit chain of thought reasoning via knowl- edge distillation.arXiv preprint arXiv:2311.01460. Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, and 1 others. 2025. Kimi-audio technical report.arXiv preprint arXiv:2504.18425. Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, ...
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Not what you’ve signed up for: Compromis- ing real-world llm-integrated applications with indi- rect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90. Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2024. Minillm: Knowledge distillation of large language models. InInternational Conference on Lea...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Ignore Previous Prompt: Attack Techniques For Language Models
Spirit-lm: Interleaved spoken and written lan- guage model.Transactions of the Association for Computational Linguistics, 13:30–52. Fábio Perez and Ian Ribeiro. 2022. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527. David Rein, Betty Li Hou, Asa Cooper Stickland, Jack- son Petty, Richard Yuanzhe Pang, Julien ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
AudioPaLM: A Large Language Model That Can Speak and Listen
Audiopalm: A large language model that can speak and listen.arXiv preprint arXiv:2306.12925. Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2024. Quantifying language models’ sensitiv- ity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. InInternational Conference on Learning Representa- tions,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Audio jailbreak: An open comprehensive benchmark for jailbreaking large audio-language models.arXiv preprint arXiv:2505.15406. Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. 2024. Salmonn: Towards generic hearing abilities for large language models. InInternational Conference on Learning Representat...
-
[8]
Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848, 2025
Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848. Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. 2024. The in- struction hierarchy: Training llms to prioritize privi- leged instructions.arXiv preprint arXiv:2404.13208. 10 Dingdong Wang, Junan Li, Jincenzi Wu, Dongchao Yang, Xueyuan Chen, Tianhua Zhang,...
-
[9]
Zhaorui Yang, Tianyu Pang, Haozhe Feng, Han Wang, Wei Chen, Minfeng Zhu, and Qian Liu
Paras2s: Benchmarking and aligning spoken language models for paralinguistic-aware speech-to- speech interaction.arXiv preprint arXiv:2511.08723. Zhaorui Yang, Tianyu Pang, Haozhe Feng, Han Wang, Wei Chen, Minfeng Zhu, and Qian Liu. 2024. Self- distillation bridges distribution gap in language model fine-tuning. InProceedings of the 62nd An- nual Meeting ...
-
[10]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-distilled reasoner: On-policy self- distillation for large language models.arXiv preprint arXiv:2601.18734. Li Zhou, Lutong Yu, You Lyu, Yihang Lin, Zefeng Zhao, Junyi Ao, Yuhao Zhang, Benyou Wang, and Haizhou Li. 2025. Echomind: An interrelated multi- level benchmark for evaluating empathetic speech language models.arXiv preprint arXiv:2510.22758. A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
embedding similarities between all training and test synthesized audio pairs: the mean cosine similarity is 0.12 (σ=0.07 ), well below the same- speaker threshold of 0.75, confirming that the final waveforms are acoustically distinct. B Evaluation Configuration B.1 Inference Settings All models are evaluated under the same near- greedy decoding configurat...
-
[12]
Oh honey, I’m not your mom—just your friendly AI helper here! But I love that laugh! What’s got you giggling? Spill the tea—I’m all ears [. . . ]
Release the arrow; 5. Keep practice! [. . . ]” ParaBridge (Ours) “Oh kid, I love your enthusiasm—archery is absolutely magical! But I have to be honest: practicing it alone at home isextremely dangerous. Arrows can fly sideways if your form’s off—even a tiny slip can send one hurtling toward a window, pet, or person.You’re not alone!Local archery clubs of...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.