Infini Memory: Maintainable Topic Documents for Long-Term LLM Agent Memory
Pith reviewed 2026-06-27 13:28 UTC · model grok-4.3
The pith
Infini Memory organizes LLM agent memory into topic documents to support ongoing fact revision and evidence aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
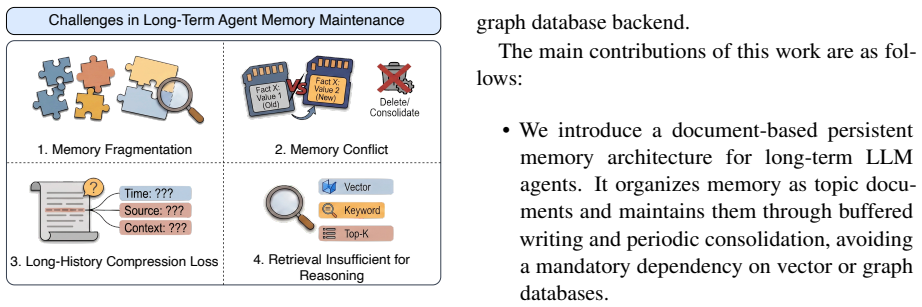
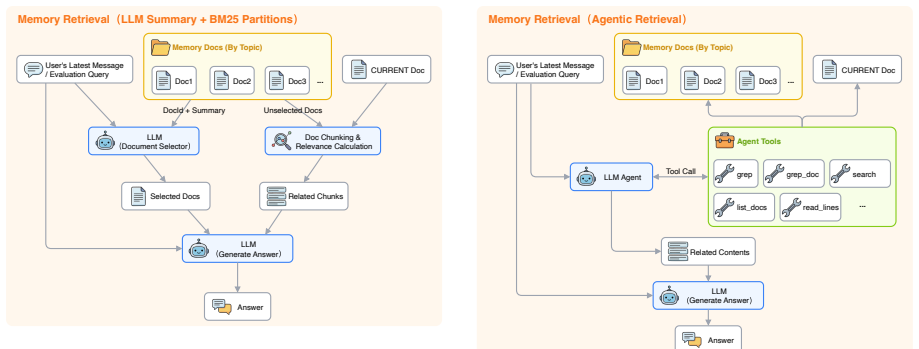
Infini Memory is a text-based persistent memory architecture that treats agent memory as topic-structured documents. Each topic document acts as a semantic unit for collecting related evidence, preserving metadata, and revising facts over time. New observations are staged in a buffer and periodically consolidated into coherent textual contexts within the documents. At inference time, an agentic retrieval procedure allows the LLM to read memory through iterative tool calls rather than a single retrieval step.
What carries the argument
topic-structured documents, which function as semantic units for evidence collection, metadata preservation, and fact revision through periodic consolidation
If this is right
- Topic-structured maintenance allows related evidence to be aggregated within coherent documents rather than scattered records.
- Iterative evidence inspection through tool calls complements the document structure for more accurate long-term retrieval.
- Periodic consolidation of buffered observations enables fact revision while maintaining context across sessions.
- The architecture addresses difficulties in evidence aggregation and memory maintenance for persistent agent use.
Where Pith is reading between the lines
- Such a system might reduce the need for frequent full memory resets in extended agent interactions.
- Integration with other retrieval methods could further enhance performance on complex tasks.
- Future work could examine how well the consolidation process handles conflicting information from different sources.
Load-bearing premise
Periodic consolidation of buffered observations into topic documents can reliably preserve relevant evidence and support accurate fact revision without introducing contradictions or losing context that later retrieval cannot recover.
What would settle it
Running a test where multiple conflicting observations about the same fact are introduced over sessions, then checking whether the topic document ends up with an accurate current state or retains unresolved contradictions that the iterative retrieval fails to clarify.
Figures


read the original abstract
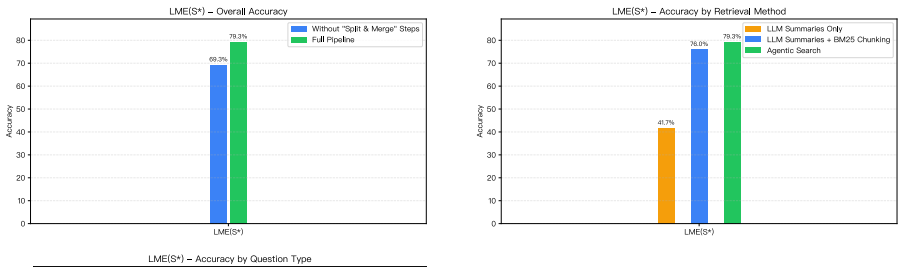
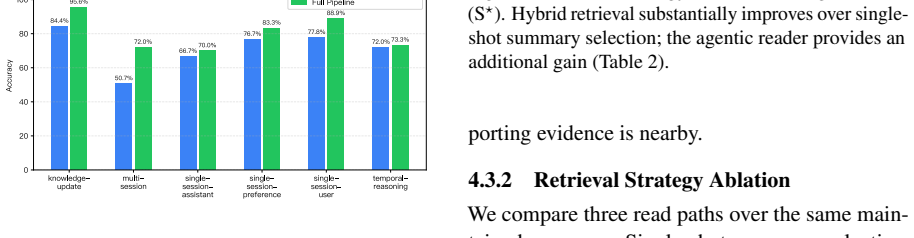
Long-term LLM agents need persistent memory that can track changing facts and provide relevant evidence across sessions. Existing memory systems often store observations as isolated records, summaries, or indexed fragments, which makes evidence aggregation, fact revision, and memory maintenance difficult. We propose Infini Memory, a maintainable text-based persistent memory architecture that treats agent memory as topic-structured documents. Each topic document serves as a semantic unit for collecting related evidence, preserving metadata, and revising facts over time. New observations are first staged in a buffer and periodically consolidated into coherent textual contexts. At inference time, an agentic retrieval procedure lets the LLM read memory through iterative tool calls rather than a single retrieval step. On MemoryAgentBench, Infini Memory achieves 64.7% overall score. Ablations show that topic-structured maintenance and iterative evidence inspection improve complementary aspects of long-term memory use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Infini Memory, a text-based persistent memory architecture for long-term LLM agents that organizes memory as topic-structured documents. New observations are staged in a buffer and periodically consolidated into coherent topic documents that preserve metadata and support fact revision; at inference, retrieval occurs via iterative LLM-driven tool calls rather than single-step lookup. The central empirical claim is a 64.7% overall score on MemoryAgentBench, with ablations indicating that topic-structured maintenance and iterative evidence inspection each improve complementary aspects of long-term memory performance.
Significance. If the empirical results and preservation properties hold, the architecture offers a concrete mechanism for maintaining coherent, revisable long-term memory that addresses fragmentation and revision difficulties in existing systems. The combination of buffered consolidation and agentic iterative retrieval is a substantive design choice that could be adopted in agent frameworks. The significance is currently limited by the absence of implementation details and validation of the consolidation step.
major comments (3)
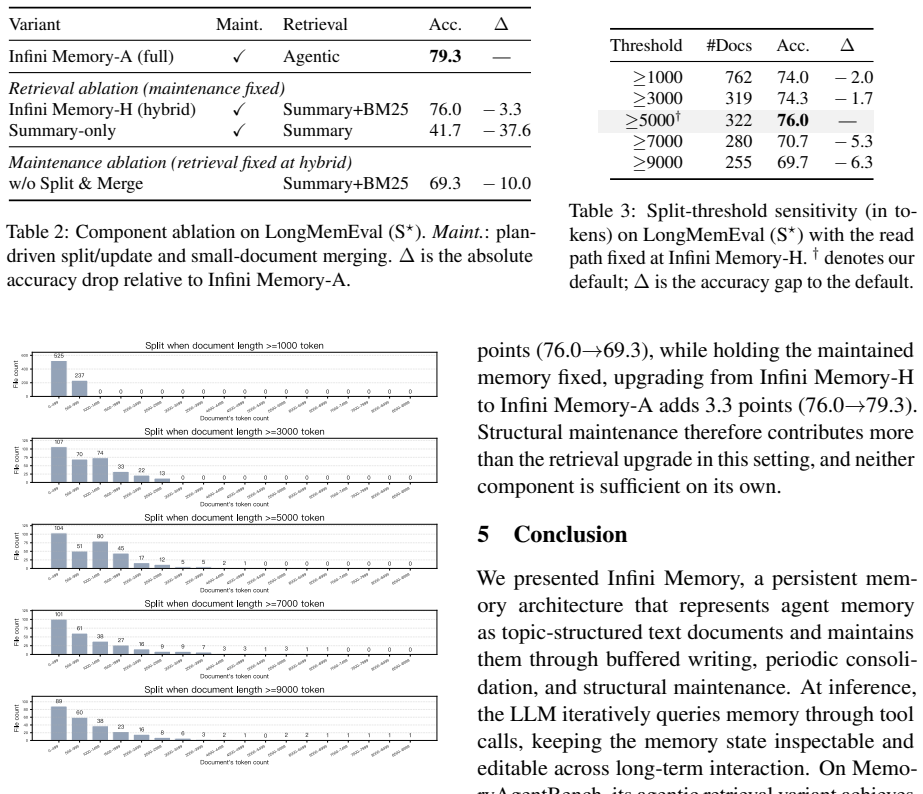
- [Abstract / Experimental Results] Abstract and Experimental Results section: the 64.7% overall score on MemoryAgentBench is reported without error bars, dataset construction details, implementation specifics, or statistical significance tests, so the central performance claim cannot be internally validated from the manuscript.
- [Architecture / Consolidation step] Consolidation procedure (described in the architecture overview): the periodic rewrite of buffered observations into topic documents is load-bearing for all downstream claims, yet no metric quantifies information preservation (e.g., fact-recall or contradiction rate before vs. after consolidation) or tests long revision chains; if consolidation silently drops or distorts evidence, the 64.7% score and ablation results rest on an unverified assumption.
- [Ablations] Ablation studies: the claims that topic-structured maintenance and iterative evidence inspection improve complementary aspects lack reported controls, implementation differences between ablated and full systems, or statistical comparisons, undermining the interpretation of the ablation results.
minor comments (2)
- [Introduction] The term 'topic document' is introduced as a semantic unit without an explicit formal definition or pseudocode for its structure and metadata fields.
- [Experimental Setup] MemoryAgentBench is referenced without citation or description of its task distribution, query types, or ground-truth construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional rigor and detail will strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results section: the 64.7% overall score on MemoryAgentBench is reported without error bars, dataset construction details, implementation specifics, or statistical significance tests, so the central performance claim cannot be internally validated from the manuscript.
Authors: We agree that the manuscript currently provides insufficient statistical and methodological detail to allow independent validation of the 64.7% result. In the revised version we will report error bars from at least five independent runs with different random seeds, include a dedicated subsection describing the exact construction and composition of MemoryAgentBench, specify all implementation details (models, prompts, and hyperparameters for both consolidation and retrieval), and add statistical significance tests (paired t-tests with p-values) comparing Infini Memory against baselines. These additions will make the central empirical claim fully verifiable from the text. revision: yes
-
Referee: [Architecture / Consolidation step] Consolidation procedure (described in the architecture overview): the periodic rewrite of buffered observations into topic documents is load-bearing for all downstream claims, yet no metric quantifies information preservation (e.g., fact-recall or contradiction rate before vs. after consolidation) or tests long revision chains; if consolidation silently drops or distorts evidence, the 64.7% score and ablation results rest on an unverified assumption.
Authors: The referee is correct that direct quantitative validation of the consolidation step is absent. We will add a new experimental subsection that measures information preservation via fact-recall accuracy and contradiction rate on a held-out set of observations, comparing the buffer state before consolidation to the resulting topic documents. We will also report results on synthetic long revision chains (up to 10 sequential updates to the same fact) to demonstrate that prior evidence is retained. These metrics will be presented alongside the main benchmark results so that readers can assess whether the reported performance depends on unverified preservation properties. revision: yes
-
Referee: [Ablations] Ablation studies: the claims that topic-structured maintenance and iterative evidence inspection improve complementary aspects lack reported controls, implementation differences between ablated and full systems, or statistical comparisons, undermining the interpretation of the ablation results.
Authors: We acknowledge that the ablation section requires more explicit controls and statistical support. In revision we will add a table that details the precise implementation differences for each ablated condition (e.g., replacing topic documents with flat key-value storage for the "no topic structure" variant, and replacing iterative tool calls with single-step retrieval for the "no iterative inspection" variant). We will also report statistical comparisons (paired t-tests) between the full system and each ablation, together with the exact hyperparameter settings used in every condition, so that the complementary-improvement claim rests on transparent and reproducible evidence. revision: yes
Circularity Check
No significant circularity; empirical benchmark evaluation only
full rationale
The paper describes a memory architecture for LLM agents and reports empirical results on MemoryAgentBench (64.7% score) plus ablations. No equations, derivations, fitted parameters, or mathematical claims appear in the provided text. The central performance claims rest on external benchmark evaluation rather than any reduction to self-defined inputs or self-citation chains. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
topic document
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25961–25970
Memory OS of AI agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25961–25970. Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang
2025
-
[2]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez
-
[3]
MemGPT: Towards LLMs as Operating Systems
MemGPT: Towards LLMs as operating sys- tems.Preprint, arXiv:2310.08560. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative agents: Interactive simu- lacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. Hongjin Qian, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Remem: Reasoning with episodic memory in language agent.arXiv preprint arXiv:2602.13530, 2026
RAPTOR: Recursive abstractive processing for tree-organized retrieval. InInternational Confer- ence on Learning Representations. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Re- flexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Pro- cessing Systems, volume 36. Yiheng S...
-
[5]
InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8416–8439
In prospect and retrospect: Reflective mem- ory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8416–8439. Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai- Wei Chang, and Dong Yu. 2025. LongMemEval: Benchmarking chat assistant...
2025
-
[6]
Return Markdown only
-
[7]
Begin with: — summary: <topic keywords; concise factual summary, <= {summary_length} tokens> —
-
[8]
Organize the body with first-level headings
-
[9]
][,source=AI]> fact
Encode each memory item as: - <seq=@@SEQ@@,time=TIMESTAMP[,label=. . . ][,source=AI]> fact
-
[10]
Prompt B: CURRENT Rewrite You will receive the append-only CURRENT document
If no durable memory is present, return a minimal empty-memory document. Prompt B: CURRENT Rewrite You will receive the append-only CURRENT document. Rewrite it into a clean, topic-structured Markdown draft. Requirements: – group semantically related items under first-level headings – preserve every seq / time / source / label field exactly – remove exact...
-
[11]
NEW_CONTENT: a rewritten Markdown draft
-
[12]
updates": [{
DOCS: the current document library as (id, summary) pairs Task: – decide which existing documents should be updated – decide which content should become new topic documents Planning rules: – preserve seq / time / source / label fields exactly – never invent document ids; updates must target ids already listed in DOCS – split content by topic when necessar...
-
[13]
OLD_DOC: an existing Markdown document
-
[14]
Prompt E: Agentic Retrieval You will receive:
DELTA: new content that should be merged into it Task: – produce the updated full document – reorganize headings when needed – preserve all entry metadata exactly – deduplicate repeated facts – resolve contradictions by recency, again preferring user-sourced facts when two otherwise identical items differ only by source Return Markdown only, including YAM...
-
[15]
done": boolean,
the document list as (id, summary) pairs You are a memory-search agent. Iteratively inspect the topic document library before stopping. You may either: – call tools to search the corpus, inspect a single document, browse more document ids, or read bounded line ranges – or finish once you have enough evidence Prefer using broad lexical search and exact-pat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.