Attention Expansion: Enhancing Keyphrase Extraction from Long Documents with Attention-Augmented Contextualized Embeddings
Pith reviewed 2026-06-27 13:04 UTC · model grok-4.3
The pith
An attention expansion mechanism augments PLM token representations with out-of-context embeddings to improve keyphrase extraction from long documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
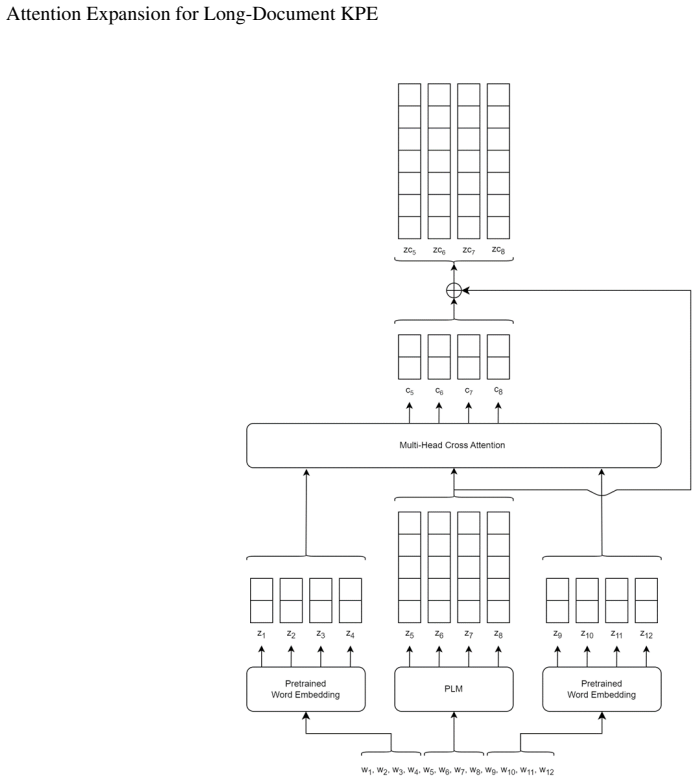
The attention expansion mechanism augments PLM token representations with information from surrounding out-of-context chunks using pre-trained word embeddings. This expands the effective contextual scope of PLM-based KPE models without requiring full-document attention or expensive LLM-based inference. Experimental results demonstrate that attention expansion consistently enhances KPE performance across all evaluation settings, outperforming state-of-the-art models and yielding notable improvements in F1 score. The improvements extend to domain-specific, task-specialized, and native long-context models, showing that the proposed mechanism provides complementary information rather than merely
What carries the argument
The attention expansion mechanism that fuses pre-trained word embeddings from out-of-context chunks into PLM token representations via attention.
If this is right
- It raises F1 scores on scientific and news domain corpora using five different PLM backbones.
- It delivers gains under two training regimes and works with general-purpose, scientific, task-specific, and long-context encoders.
- It supplies complementary information rather than only fixing limited context length.
- It outperforms prior state-of-the-art KPE models while remaining computationally lighter than full long-context LLMs.
Where Pith is reading between the lines
- The same fusion idea could be tested on other long-text tasks such as summarization or relation extraction.
- It points to a general pattern where embeddings from shorter, cheaper models can be combined with stronger contextual ones without retraining either.
- Scaling the number of out-of-context chunks or choosing them by relevance might further increase the observed gains.
Load-bearing premise
Pre-trained word embeddings from out-of-context chunks supply complementary semantic signals that can be fused into PLM representations without introducing noise or requiring task-specific retraining.
What would settle it
An experiment in which adding the attention expansion mechanism produces no F1 improvement or a decrease on the five benchmark corpora across the tested PLM backbones and training regimes.
Figures

read the original abstract
Pre-trained language models (PLMs) have achieved strong performance in keyphrase extraction (KPE), largely due to their ability to generate rich contextualized representations. However, long-document KPE remains challenging because salient keyphrase evidence may be scattered across distant document sections that cannot be jointly captured within the limited context window of most PLMs. Although long-context large language models (LLMs) can process broader textual contexts, their computational cost limits their practicality for efficient and high-throughput KPE. To overcome this limitation, we propose an attention expansion mechanism that augments PLM token representations with information from surrounding out-of-context chunks using pre-trained word embeddings. The proposed mechanism expands the effective contextual scope of PLM-based KPE models without requiring full-document attention or expensive LLM-based inference. We evaluate our approach across five PLM backbones, including general-purpose, scientific, task-specific, and long-context encoders, using two training regimes and five benchmark corpora from scientific and news domains. Experimental results demonstrate that attention expansion consistently enhances KPE performance across all evaluation settings, outperforming state-of-the-art models and yielding notable improvements in F1 score. The improvements extend to domain-specific, task-specialized, and native long-context models, showing that the proposed mechanism provides complementary information rather than merely compensating for limited input length. These results establish attention expansion as an efficient and effective strategy for long-document KPE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an attention expansion mechanism that augments token representations from pre-trained language models (PLMs) with semantic signals from out-of-context document chunks via static word embeddings. This is intended to improve keyphrase extraction (KPE) on long documents without incurring the cost of full long-context attention. The central empirical claim is that the mechanism yields consistent F1 gains across five PLM backbones (general, scientific, task-specific, and long-context) and five corpora, outperforming prior SOTA and, crucially, supplying complementary information even to native long-context models rather than merely mitigating input truncation.
Significance. If the experimental claims hold after clarification of the long-context baseline protocol, the work would offer a lightweight, plug-in augmentation for existing PLM-based KPE pipelines that avoids both truncation artifacts and the inference cost of full-document LLMs. The breadth of backbones and domains tested would strengthen the case for practical utility in scientific and news KPE.
major comments (2)
- [Experimental Results] Abstract and Experimental Results: The claim that attention expansion supplies complementary signals 'rather than merely compensating for limited input length' on native long-context models (Longformer, BigBird, etc.) is load-bearing. The manuscript does not state whether those long-context baselines were run on full documents or on the same truncated inputs used for standard PLMs; without this protocol detail, the complementarity interpretation cannot be distinguished from a length-compensation effect.
- [Experimental Results] Experimental Results: No ablation isolating the contribution of the static embedding fusion versus simple length extension is reported, nor are statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) provided for the reported F1 gains across the five backbones and two training regimes. These omissions leave the consistency claim difficult to evaluate.
minor comments (2)
- [Method] The description of how out-of-context chunks are selected and aligned to PLM tokens is underspecified; a concrete example or pseudocode would clarify the fusion step.
- [Tables] Table captions and axis labels should explicitly indicate whether reported F1 scores are macro- or micro-averaged and whether they reflect exact-match or partial-match evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript to improve experimental clarity.
read point-by-point responses
-
Referee: [Experimental Results] Abstract and Experimental Results: The claim that attention expansion supplies complementary signals 'rather than merely compensating for limited input length' on native long-context models (Longformer, BigBird, etc.) is load-bearing. The manuscript does not state whether those long-context baselines were run on full documents or on the same truncated inputs used for standard PLMs; without this protocol detail, the complementarity interpretation cannot be distinguished from a length-compensation effect.
Authors: We agree that the protocol detail is necessary to support the complementarity claim. The long-context models were evaluated on full documents using their native extended context windows, while standard PLMs used 512-token truncations. We will explicitly state this in the Experimental Setup, Results, and abstract sections of the revised manuscript. revision: yes
-
Referee: [Experimental Results] Experimental Results: No ablation isolating the contribution of the static embedding fusion versus simple length extension is reported, nor are statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) provided for the reported F1 gains across the five backbones and two training regimes. These omissions leave the consistency claim difficult to evaluate.
Authors: The existing comparisons against native long-context models already control for length by using models designed for extended contexts, thereby isolating the benefit of static-embedding attention expansion. We will nevertheless add paired t-tests (and bootstrap intervals where appropriate) for the F1 gains in the revised Experimental Results section. An explicit ablation against naive length extension can be included if space allows. revision: partial
Circularity Check
No circularity: empirical augmentation with no derivations or self-referential reductions
full rationale
The paper proposes an attention expansion mechanism that fuses pre-trained word embeddings from out-of-context chunks into PLM representations, then reports empirical F1 gains across five backbones and five corpora. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on experimental comparisons rather than any derivation that reduces to its own inputs by construction. The method is framed as a practical augmentation relying on external embeddings, with no load-bearing self-citations or ansatzes. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained word embeddings capture useful semantic information from out-of-context chunks that can be fused into PLM representations
invented entities (1)
-
attention expansion mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A study on automatically extracted keywords in text categorization
Anette Hulth and Beáta Megyesi. A study on automatically extracted keywords in text categorization. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, pages 537–544, 2006
2006
-
[2]
Corephrase: Keyphrase extraction for document clustering
Khaled M Hammouda, Diego N Matute, and Mohamed S Kamel. Corephrase: Keyphrase extraction for document clustering. InInternational workshop on machine learning and data mining in pattern recognition, pages 265–274. Springer, 2005
2005
-
[3]
Citation summarization through keyphrase extraction
Vahed Qazvinian, Dragomir Radev, and Arzucan Özgür. Citation summarization through keyphrase extraction. In Proceedings of the 23rd international conference on computational linguistics (COLING 2010), pages 895–903, 2010
2010
-
[4]
World wide web site summarization.Web Intelligence and Agent Systems: An International Journal, 2(1):39–53, 2004
Yongzheng Zhang, Nur Zincir-Heywood, and Evangelos Milios. World wide web site summarization.Web Intelligence and Agent Systems: An International Journal, 2(1):39–53, 2004
2004
-
[5]
Improving browsing in digital libraries with keyphrase indexes.Decision Support Systems, 27(1-2):81–104, 1999
Carl Gutwin, Gordon Paynter, Ian Witten, Craig Nevill-Manning, and Eibe Frank. Improving browsing in digital libraries with keyphrase indexes.Decision Support Systems, 27(1-2):81–104, 1999
1999
-
[6]
Keyphrase extraction-based query expansion in digital libraries
Il Yeol Song, Robert B Allen, Zoran Obradovic, and Min Song. Keyphrase extraction-based query expansion in digital libraries. InProceedings of the 6th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL’06), pages 202–209. IEEE, 2006
2006
-
[7]
Phrasier: a system for interactive document retrieval using keyphrases
Steve Jones and Mark S Staveley. Phrasier: a system for interactive document retrieval using keyphrases. In Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, pages 160–167, 1999
1999
-
[8]
From fundamentals to recent advances: A tutorial on keyphrasi- fication
Rui Meng, Debanjan Mahata, and Florian Boudin. From fundamentals to recent advances: A tutorial on keyphrasi- fication. InAdvances in Information Retrieval: 44th European Conference on IR Research, ECIR 2022, Stavanger, Norway, April 10–14, 2022, Proceedings, Part II, pages 582–588. Springer, 2022
2022
-
[9]
Automatic keyphrase extraction using graph- based methods
Josiane Mothe, Faneva Ramiandrisoa, and Michael Rasolomanana. Automatic keyphrase extraction using graph- based methods. InProceedings of the 33rd Annual ACM Symposium on Applied Computing, pages 728–730, 2018
2018
-
[10]
A comparison of centrality measures for graph-based keyphrase extraction
Florian Boudin. A comparison of centrality measures for graph-based keyphrase extraction. InProceedings of the sixth international joint conference on natural language processing, pages 834–838, 2013
2013
-
[11]
Automatic keyphrase extraction: A survey of the state of the art
Kazi Saidul Hasan and Vincent Ng. Automatic keyphrase extraction: A survey of the state of the art. InProceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1262–1273, 2014
2014
-
[12]
Efficient estimation of word representations in vector space, 2013
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space, 2013
2013
-
[13]
GloVe: Global vectors for word representation
Jeffrey Pennington, Richard Socher, and Christopher Manning. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, Doha, Qatar, October 2014. Association for Computational Linguistics
2014
-
[14]
Bert: Pre-training of deep bidirectional transformers for language understanding, 2018
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2018
2018
-
[15]
Keyphrase extraction as sequence labeling using contextualized embeddings
Dhruva Sahrawat, Debanjan Mahata, Haimin Zhang, Mayank Kulkarni, Agniv Sharma, Rakesh Gosangi, Amanda Stent, Yaman Kumar, Rajiv Ratn Shah, and Roger Zimmermann. Keyphrase extraction as sequence labeling using contextualized embeddings. InEuropean Conference on Information Retrieval, pages 328–335. Springer, 2020
2020
-
[16]
Learning rich representation of keyphrases from text
Mayank Kulkarni, Debanjan Mahata, Ravneet Arora, and Rajarshi Bhowmik. Learning rich representation of keyphrases from text. InFindings of the Association for Computational Linguistics: NAACL 2022, pages 891–906, Seattle, United States, July 2022. Association for Computational Linguistics
2022
-
[17]
Scientific keyphrase identification and classification by pre-trained language models intermediate task transfer learning
Seoyeon Park and Cornelia Caragea. Scientific keyphrase identification and classification by pre-trained language models intermediate task transfer learning. InProceedings of the 28th International Conference on Computational Linguistics, pages 5409–5419, 2020
2020
-
[18]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer.arXiv:2004.05150, 2020. 15 Attention Expansion for Long-Document KPE
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[19]
Big bird: Transformers for longer sequences
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences. 2020
2020
-
[20]
Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference, 2024
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, and Iacopo Poli. Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference, 2024
2024
-
[21]
Farrar, Straus and Giroux, New York, 2011
Daniel Kahneman.Thinking, Fast and Slow. Farrar, Straus and Giroux, New York, 2011
2011
-
[22]
Do artificial intelligence systems understand?Claridades
Carlos Blanco Pérez and Eduardo Garrido-Merchán. Do artificial intelligence systems understand?Claridades. Revista de Filosofía, 16(1):171–205, 2024
2024
-
[23]
López-López, and José Portela
Roberto Martínez-Cruz, Debanjan Mahata, Alvaro J. López-López, and José Portela. Enhancing keyphrase extraction from long scientific documents using graph embeddings, 2023
2023
-
[24]
LongKey: Keyphrase extraction for long documents
Jeovane Honorio Alves, Radu State, Cinthia Obladen de Almendra Freitas, and Jean Paul Barddal. LongKey: Keyphrase extraction for long documents. InProceedings of the 2024 IEEE International Conference on Big Data, 2024. arXiv:2411.17863
-
[25]
MAPEX: A multi-agent pipeline for keyphrase extraction, 2025
Liting Zhang, Shiwan Zhao, Aobo Kong, and Qicheng Li. MAPEX: A multi-agent pipeline for keyphrase extraction, 2025
2025
-
[26]
TextRank: Bringing order into text
Rada Mihalcea and Paul Tarau. TextRank: Bringing order into text. InProceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, pages 404–411, Barcelona, Spain, July 2004. Association for Computational Linguistics
2004
-
[27]
TopicRank: Graph-based topic ranking for keyphrase extraction
Adrien Bougouin, Florian Boudin, and Béatrice Daille. TopicRank: Graph-based topic ranking for keyphrase extraction. InProceedings of the Sixth International Joint Conference on Natural Language Processing, pages 543–551, Nagoya, Japan, October 2013. Asian Federation of Natural Language Processing
2013
-
[28]
Corpus-independent generic keyphrase extraction using word embedding vectors
Rui Wang, Wei Liu, and Chris McDonald. Corpus-independent generic keyphrase extraction using word embedding vectors. InSoftware engineering research conference, volume 39, pages 1–8, 2014
2014
-
[29]
Key2vec: Automatic ranked keyphrase extraction from scientific articles using phrase embeddings
Debanjan Mahata, John Kuriakose, Rajiv Shah, and Roger Zimmermann. Key2vec: Automatic ranked keyphrase extraction from scientific articles using phrase embeddings. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 634–639, 2018
2018
-
[30]
Theme-weighted ranking of keywords from text documents using phrase embeddings
Debanjan Mahata, Rajiv Ratn Shah, John Kuriakose, Roger Zimmermann, and John R Talburt. Theme-weighted ranking of keywords from text documents using phrase embeddings. In2018 IEEE conference on multimedia information processing and retrieval (MIPR), pages 184–189. IEEE, 2018
2018
-
[31]
Simple Unsupervised Keyphrase Extraction using Sentence Embeddings
Kamil Bennani-Smires, Claudiu Musat, Andreea Hossmann, Michael Baeriswyl, and Martin Jaggi. Simple unsupervised keyphrase extraction using sentence embeddings.arXiv preprint arXiv:1801.04470, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
PatternRank: Leveraging pretrained language models and part of speech for unsupervised keyphrase extraction
Tim Schopf, Simon Klimek, and Florian Matthes. PatternRank: Leveraging pretrained language models and part of speech for unsupervised keyphrase extraction. InProceedings of the 14th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management. SCITEPRESS - Science and Technology Publications, 2022
2022
-
[33]
Promptrank: Unsupervised keyphrase extraction using prompt.arXiv preprint arXiv:2305.04490, 2023
Aobo Kong, Shiwan Zhao, Hao Chen, Qicheng Li, Yong Qin, Ruiqi Sun, and Xiaoyan Bai. Promptrank: Unsupervised keyphrase extraction using prompt.arXiv preprint arXiv:2305.04490, 2023
-
[34]
Incorporating expert knowledge into keyphrase extraction
Sujatha Das Gollapalli, Xiao-li Li, and Peng Yang. Incorporating expert knowledge into keyphrase extraction. Proceedings of the AAAI Conference on Artificial Intelligence, 31(1), Feb. 2017
2017
-
[35]
Lee Giles
Rabah Alzaidy, Cornelia Caragea, and C. Lee Giles. Bi-lstm-crf sequence labeling for keyphrase extraction from scholarly documents. InThe World Wide Web Conference, WWW ’19, page 2551–2557, New York, NY , USA,
-
[36]
Association for Computing Machinery
-
[37]
Exploring word embeddings in crf-based keyphrase extraction from research papers
Krutarth Patel and Cornelia Caragea. Exploring word embeddings in crf-based keyphrase extraction from research papers. InProceedings of the 10th International Conference on Knowledge Capture, pages 37–44, 2019
2019
-
[38]
Transkp: Transformer based key-phrase extraction.2020 International Joint Conference on Neural Networks (IJCNN), pages 1–7, 2020
Mukund Rungta, Rishabh Kumar, Mehak Preet Dhaliwal, Hemant Tiwari, and Vanraj Vala. Transkp: Transformer based key-phrase extraction.2020 International Joint Conference on Neural Networks (IJCNN), pages 1–7, 2020
2020
-
[39]
TNT-KID: Transformer-based neural tagger for keyword identifica- tion.Natural Language Engineering, 28(4):409–448, jun 2021
Matej Martinc, Blaž Škrlj, and Senja Pollak. TNT-KID: Transformer-based neural tagger for keyword identifica- tion.Natural Language Engineering, 28(4):409–448, jun 2021. 16 Attention Expansion for Long-Document KPE
2021
-
[40]
SciBERT: A pretrained language model for scientific text
Iz Beltagy, Kyle Lo, and Arman Cohan. SciBERT: A pretrained language model for scientific text. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3615–3620, Hong Kong, China, November
2019
-
[42]
Ldkp: A dataset for identifying keyphrases from long scientific documents
Debanjan Mahata, Naveen Agarwal, Dibya Gautam, Amardeep Kumar, Swapnil Parekh, Yaman Kumar Singla, Anish Acharya, and Rajiv Ratn Shah. Ldkp: A dataset for identifying keyphrases from long scientific documents. arXiv preprint arXiv:2203.15349, 2022
-
[43]
Keyphrase generation beyond the boundaries of title and abstract, 2022
Krishna Garg, Jishnu Ray Chowdhury, and Cornelia Caragea. Keyphrase generation beyond the boundaries of title and abstract, 2022
2022
-
[44]
Query-based keyphrase extraction from long documents.The International FLAIRS Conference Proceedings, 35, may 2022
Martin Doˇcekal and Pavel Smrž. Query-based keyphrase extraction from long documents.The International FLAIRS Conference Proceedings, 35, may 2022
2022
-
[45]
UFORank: Unified framework of unsupervised keyphrase extraction for long documents.IEEE Access, 14:9986–10001, 2026
Doyoon Kim and Pilsung Kang. UFORank: Unified framework of unsupervised keyphrase extraction for long documents.IEEE Access, 14:9986–10001, 2026
2026
-
[46]
López-López, and José Portela
Roberto Martínez-Cruz, Alvaro J. López-López, and José Portela. Chatgpt vs state-of-the-art models: A bench- marking study in keyphrase generation task, 2023
2023
-
[47]
Empirical study of zero-shot keyphrase extraction with large language models
Byungha Kang and Youhyun Shin. Empirical study of zero-shot keyphrase extraction with large language models. InProceedings of the 31st International Conference on Computational Linguistics, pages 3670–3686, Abu Dhabi, UAE, 2025. Association for Computational Linguistics
2025
-
[48]
LongDocRank: Graph-augmented large language models for unsupervised keyphrase extraction from long documents.Journal of Big Data, 13(14), 2026
Haoran Ding and Xiao Luo. LongDocRank: Graph-augmented large language models for unsupervised keyphrase extraction from long documents.Journal of Big Data, 13(14), 2026
2026
-
[49]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2017
2017
-
[50]
Semeval-2010 task 5: Automatic keyphrase extraction from scientific articles
Su Nam Kim, Olena Medelyan, Min-Yen Kan, and Timothy Baldwin. Semeval-2010 task 5: Automatic keyphrase extraction from scientific articles. InProceedings of the 5th International Workshop on Semantic Evaluation, SemEval ’10, page 21–26, USA, 2010. Association for Computational Linguistics
2010
-
[51]
Keyphrase extraction in scientific publications
Thuy Dung Nguyen and Min-Yen Kan. Keyphrase extraction in scientific publications. In Dion Hoe-Lian Goh, Tru Hoang Cao, Ingeborg Torvik Sølvberg, and Edie Rasmussen, editors,Asian Digital Libraries. Looking Back 10 Years and Forging New Frontiers, pages 317–326, Berlin, Heidelberg, 2007. Springer Berlin Heidelberg
2007
-
[52]
Single document keyphrase extraction using neighborhood knowledge
Xiaojun Wan and Jianguo Xiao. Single document keyphrase extraction using neighborhood knowledge. In Proceedings of the 23rd National Conference on Artificial Intelligence - Volume 2, AAAI’08, page 855–860. AAAI Press, 2008
2008
-
[53]
Improved automatic keyword extraction given more linguistic knowledge
Anette Hulth. Improved automatic keyword extraction given more linguistic knowledge. InProceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, EMNLP ’03, page 216–223, USA,
2003
-
[54]
Association for Computational Linguistics
- [55]
-
[56]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, 2019
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, 2019
2019
-
[57]
DeBERTaV3: Improving DeBERTa using ELECTRA-style pre- training with gradient-disentangled embedding sharing
Pengcheng He, Jianfeng Gao, and Weizhu Chen. DeBERTaV3: Improving DeBERTa using ELECTRA-style pre- training with gradient-disentangled embedding sharing. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[58]
Model2Vec: Fast state-of-the-art static embeddings
Stéphan Tulkens and Thomas van Dongen. Model2Vec: Fast state-of-the-art static embeddings. https:// github.com/MinishLab/model2vec, 2024. MinishLab, GitHub repository. 17
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.