N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
Pith reviewed 2026-06-27 13:59 UTC · model grok-4.3
The pith
Semantic Neighbor Mixing in N-GRPO adds rollout diversity while preserving semantic consistency for better math reasoning in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
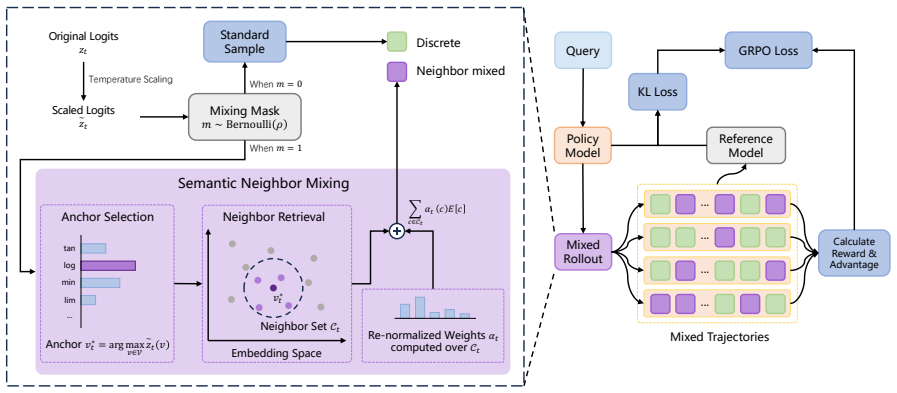
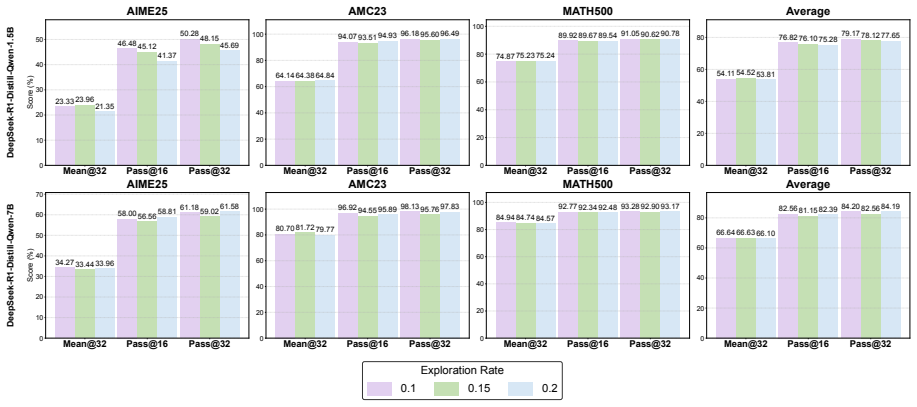
N-GRPO integrates Semantic Neighbor Mixing into the Group Relative Policy Optimization framework. Rather than token-level sampling or random noise, the method dynamically builds input representations by combining the embeddings of an anchor token with its nearest semantic neighbors. This injects diversity while strictly adhering to the local semantic manifold. Evaluations on DeepSeek-R1-Distill-Qwen models of varying sizes show consistent gains over baselines on math reasoning benchmarks together with strong performance on out-of-distribution tasks.
What carries the argument
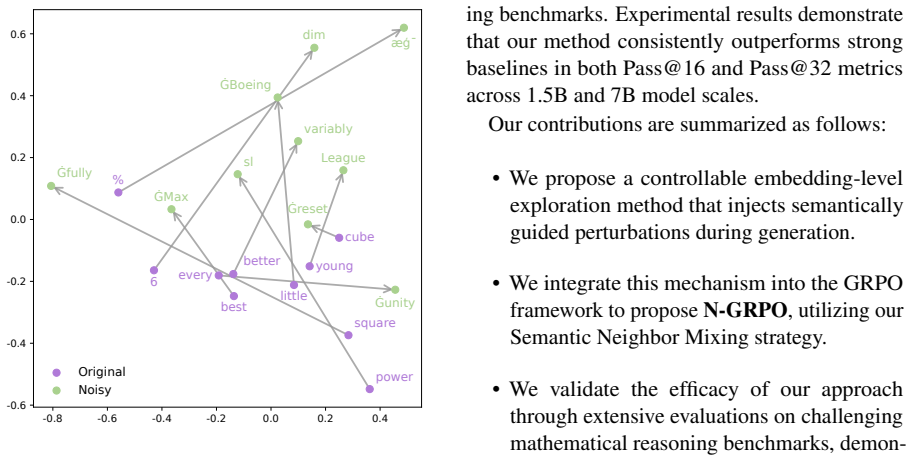
Semantic Neighbor Mixing: the mechanism that constructs input representations by mixing an anchor token's embedding with embeddings of its nearest semantic neighbors to balance diversity and consistency inside GRPO rollouts.
If this is right
- N-GRPO produces consistent accuracy gains over strong baselines on math reasoning benchmarks.
- The method shows robust generalization on out-of-distribution tasks.
- Rollout trajectories gain diversity without increasing redundancy or semantic drift.
- Solution validity remains intact across model sizes tested.
- The approach works within the existing GRPO optimization loop without requiring new sampling primitives.
Where Pith is reading between the lines
- The mixing step could be applied to other reinforcement-learning loops for language models where local semantic neighborhoods are easy to define.
- It might lower the number of rollouts needed to reach a given performance level by reducing wasted near-duplicate trajectories.
- Extending neighbor selection beyond immediate semantic space to include syntactic or logical neighbors could be tested as a direct follow-up.
- The same mixing logic might transfer to non-reasoning generation tasks such as code or dialogue if neighbor quality can be maintained.
Load-bearing premise
Mixing embeddings of an anchor token with its nearest semantic neighbors injects useful diversity while strictly preserving semantic consistency and solution validity during rollout.
What would settle it
A controlled experiment in which N-GRPO produces either lower accuracy or higher rates of invalid solutions than standard GRPO on the same math reasoning benchmarks would falsify the claim.
Figures
read the original abstract
The success of Large Language Models in mathematical reasoning relies heavily on the generation of diverse and valid solution paths during the rollout phase. However, current rollout techniques face a fundamental trade-off: token-level sampling often yields redundant trajectories that differ only in rephrasing, while embedding-level methods utilizing random noise frequently disrupt semantic consistency. To resolve this, we introduce N-GRPO, a novel exploration strategy integrated into the Group Relative Policy Optimization (GRPO) framework. Rather than relying on token-level sampling or native embedding-level noise, our approach leverages Semantic Neighbor Mixing. This mechanism dynamically constructs input representations by mixing the embeddings of an anchor token and its nearest semantic neighbors, thereby injecting diversity while strictly adhering to the local semantic manifold. Experimental evaluations on the DeepSeek-R1-Distill-Qwen models across different sizes show that N-GRPO not only achieves consistent improvements over strong baselines on math reasoning benchmarks but also exhibits robust generalization capabilities on out-of-distribution tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces N-GRPO, an extension to Group Relative Policy Optimization (GRPO) that replaces token-level sampling or random embedding noise with Semantic Neighbor Mixing. This constructs input representations by mixing the embedding of an anchor token with those of its nearest semantic neighbors, with the goal of increasing trajectory diversity while remaining on the local semantic manifold. The manuscript claims this yields consistent performance gains over strong baselines on math reasoning benchmarks together with improved generalization on out-of-distribution tasks, evaluated on DeepSeek-R1-Distill-Qwen models of varying sizes.
Significance. If the empirical claims are substantiated with rigorous controls, the approach could offer a useful addition to exploration strategies in RL-based LLM reasoning by providing a more controlled form of embedding-level diversity than additive noise, potentially improving sample quality without sacrificing solution validity.
major comments (2)
- Abstract: the claims of 'consistent improvements over strong baselines' and 'robust generalization capabilities' are asserted without any reported metrics, baseline names, statistical tests, ablation results, or experimental controls, leaving the central empirical claim without verifiable support in the manuscript.
- Method description (Semantic Neighbor Mixing): the text states that the operator 'injects diversity while strictly adhering to the local semantic manifold' and preserves solution validity, yet supplies no projection step from mixed embeddings back to discrete tokens, no validity filter on generated paths, and no statistic on the fraction of mathematically correct trajectories (as opposed to merely nearby in embedding space). This absence makes it impossible to confirm that performance differences arise from the claimed property of the mixing operator rather than from other GRPO mechanics or increased sampling volume.
minor comments (1)
- Abstract: the description of the models and benchmarks remains generic; naming the specific sizes, datasets, and baseline methods would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below, providing clarifications and committing to revisions that strengthen the empirical support and methodological transparency of the manuscript.
read point-by-point responses
-
Referee: Abstract: the claims of 'consistent improvements over strong baselines' and 'robust generalization capabilities' are asserted without any reported metrics, baseline names, statistical tests, ablation results, or experimental controls, leaving the central empirical claim without verifiable support in the manuscript.
Authors: We agree that the abstract would be strengthened by greater specificity. In the revised manuscript we will update the abstract to report concrete metrics (e.g., average accuracy gains on MATH and GSM8K), explicitly name the baselines (GRPO and its variants), and reference the model sizes and evaluation protocol. These additions will make the central claims directly verifiable while preserving the abstract’s brevity. revision: yes
-
Referee: Method description (Semantic Neighbor Mixing): the text states that the operator 'injects diversity while strictly adhering to the local semantic manifold' and preserves solution validity, yet supplies no projection step from mixed embeddings back to discrete tokens, no validity filter on generated paths, and no statistic on the fraction of mathematically correct trajectories (as opposed to merely nearby in embedding space). This absence makes it impossible to confirm that performance differences arise from the claimed property of the mixing operator rather than from other GRPO mechanics or increased sampling volume.
Authors: Semantic Neighbor Mixing constructs the input embedding for each rollout step by linearly combining an anchor token embedding with its nearest semantic neighbors; the resulting vector is passed directly to the transformer’s embedding layer for autoregressive generation. Validity of the resulting trajectories is enforced by the same outcome-based reward model already used in GRPO. We acknowledge that the current text omits an explicit description of this integration and lacks quantitative statistics on trajectory validity. We will add (i) a precise algorithmic description of the mixing operator and its interface with the generation loop, (ii) a short analysis of the fraction of mathematically correct trajectories under N-GRPO versus baselines, and (iii) an ablation isolating the effect of neighbor mixing from simple increases in sampling volume. These additions will allow readers to verify that gains derive from the claimed semantic-manifold property. revision: partial
Circularity Check
No circularity: no derivation chain or equations present to inspect
full rationale
The abstract and available text introduce N-GRPO via Semantic Neighbor Mixing as an empirical exploration strategy within GRPO, claiming diversity injection while preserving semantic consistency. No equations, fitted parameters, predictions, uniqueness theorems, or self-citations appear. The central claims are descriptive and benchmark-based rather than derived from first principles that could reduce to inputs by construction. Without a load-bearing derivation chain, no circularity of any enumerated kind can be exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[2]
arXiv preprint arXiv:2507.18071 , year=
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
-
[3]
arXiv preprint arXiv:2501.12735 , year=
Online preference alignment for language models via count-based exploration , author=. arXiv preprint arXiv:2501.12735 , year=
-
[4]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[5]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[6]
arXiv preprint arXiv:2505.18454 , year=
Hybrid Latent Reasoning via Reinforcement Learning , author=. arXiv preprint arXiv:2505.18454 , year=
-
[7]
arXiv preprint arXiv:2510.09388 , year=
HINT: Helping Ineffective Rollouts Navigate Towards Effectiveness , author=. arXiv preprint arXiv:2510.09388 , year=
-
[8]
arXiv preprint arXiv:2506.02177 , year=
Act Only When It Pays: Efficient Reinforcement Learning for LLM Reasoning via Selective Rollouts , author=. arXiv preprint arXiv:2506.02177 , year=
-
[9]
arXiv preprint arXiv:2507.04632 , year=
Can prompt difficulty be online predicted for accelerating rl finetuning of reasoning models? , author=. arXiv preprint arXiv:2507.04632 , year=
-
[10]
arXiv preprint arXiv:2502.11476 , year=
Fastmcts: A simple sampling strategy for data synthesis , author=. arXiv preprint arXiv:2502.11476 , year=
-
[11]
arXiv preprint arXiv:2412.06769 , year=
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
-
[12]
arXiv preprint arXiv:2505.15778 , year=
Soft thinking: Unlocking the reasoning potential of llms in continuous concept space , author=. arXiv preprint arXiv:2505.15778 , year=
-
[13]
arXiv preprint arXiv:2502.21074 , year=
Codi: Compressing chain-of-thought into continuous space via self-distillation , author=. arXiv preprint arXiv:2502.21074 , year=
-
[14]
arXiv preprint arXiv:2502.15589 , year=
Lightthinker: Thinking step-by-step compression , author=. arXiv preprint arXiv:2502.15589 , year=
-
[15]
arXiv preprint arXiv:2509.20317 , year=
SIM-CoT: Supervised Implicit Chain-of-Thought , author=. arXiv preprint arXiv:2509.20317 , year=
-
[16]
arXiv preprint arXiv:2505.16552 , year=
Think Silently, Think Fast: Dynamic Latent Compression of LLM Reasoning Chains , author=. arXiv preprint arXiv:2505.16552 , year=
-
[17]
arXiv preprint arXiv:2508.00574 , year=
Synadapt: Learning adaptive reasoning in large language models via synthetic continuous chain-of-thought , author=. arXiv preprint arXiv:2508.00574 , year=
-
[18]
arXiv preprint arXiv:2412.16720 , year=
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
-
[19]
arXiv preprint arXiv:2503.14476 , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
-
[20]
arXiv preprint arXiv:2508.09726 , year=
Sample more to think less: Group filtered policy optimization for concise reasoning , author=. arXiv preprint arXiv:2508.09726 , year=
-
[21]
arXiv preprint arXiv:2512.13996 , year=
Sparsity-Controllable Dynamic Top-p MoE for Large Foundation Model Pre-training , author=. arXiv preprint arXiv:2512.13996 , year=
-
[22]
arXiv preprint arXiv:2505.13500 , year=
Noise Injection Systemically Degrades Large Language Model Safety Guardrails , author=. arXiv preprint arXiv:2505.13500 , year=
-
[23]
arXiv preprint arXiv:2505.24688 , year=
Soft Reasoning: Navigating Solution Spaces in Large Language Models through Controlled Embedding Exploration , author=. arXiv preprint arXiv:2505.24688 , year=
-
[24]
arXiv preprint arXiv:2407.01082 , year=
Turning up the heat: Min-p sampling for creative and coherent llm outputs , author=. arXiv preprint arXiv:2407.01082 , year=
-
[25]
Notion Blog , year=
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl , author=. Notion Blog , year=
-
[26]
Measuring Mathematical Problem Solving With the MATH Dataset , url =
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving With the MATH Dataset , url =
-
[27]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[28]
arXiv preprint arXiv:2511.06411 , year=
SofT-GRPO: Surpassing Discrete-Token LLM Reinforcement Learning via Gumbel-Reparameterized Soft-Thinking Policy Optimization , author=. arXiv preprint arXiv:2511.06411 , year=
-
[29]
arXiv preprint arXiv:1508.02297 , year=
Measuring word significance using distributed representations of words , author=. arXiv preprint arXiv:1508.02297 , year=
-
[30]
arXiv preprint arXiv:2508.10003 , year=
Semantic structure in large language model embeddings , author=. arXiv preprint arXiv:2508.10003 , year=
-
[31]
International Conference on Learning Representations , year=
Representation Degeneration Problem in Training Natural Language Generation Models , author=. International Conference on Learning Representations , year=
-
[32]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[33]
arXiv preprint arXiv:2509.19170 , year=
Soft tokens, hard truths , author=. arXiv preprint arXiv:2509.19170 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.