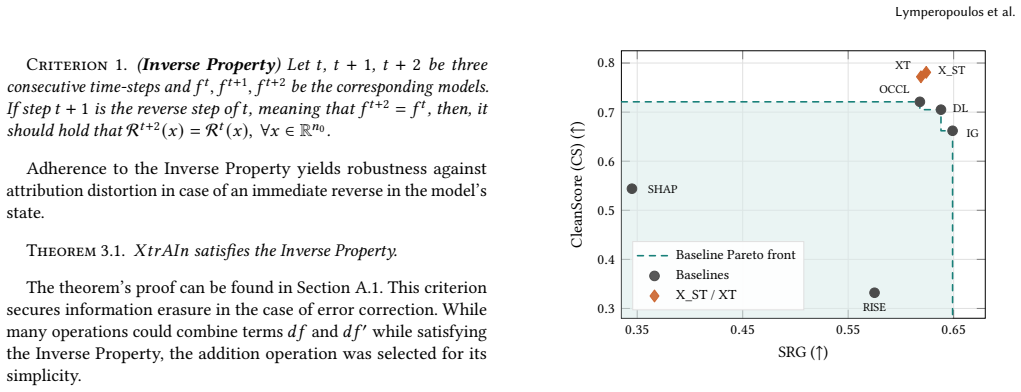
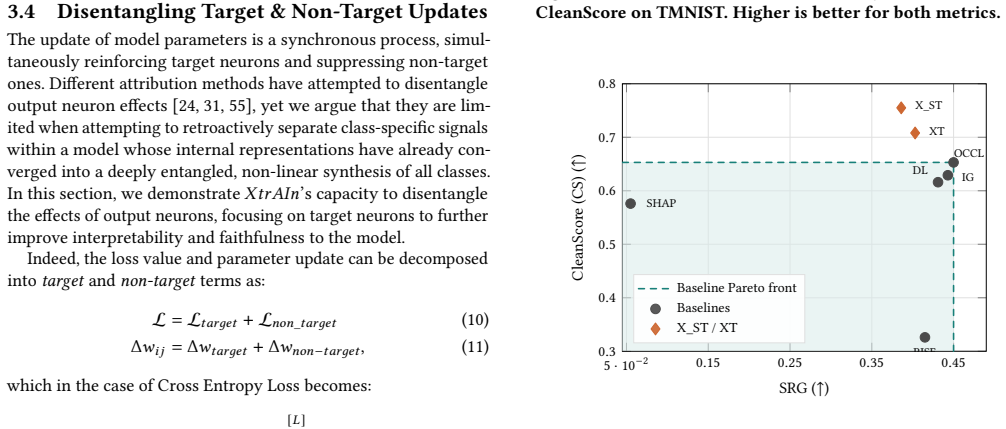
XtrAIn: Training-Guided Occlusion for Feature Attribution
Pith reviewed 2026-06-27 13:36 UTC · model grok-4.3
The pith
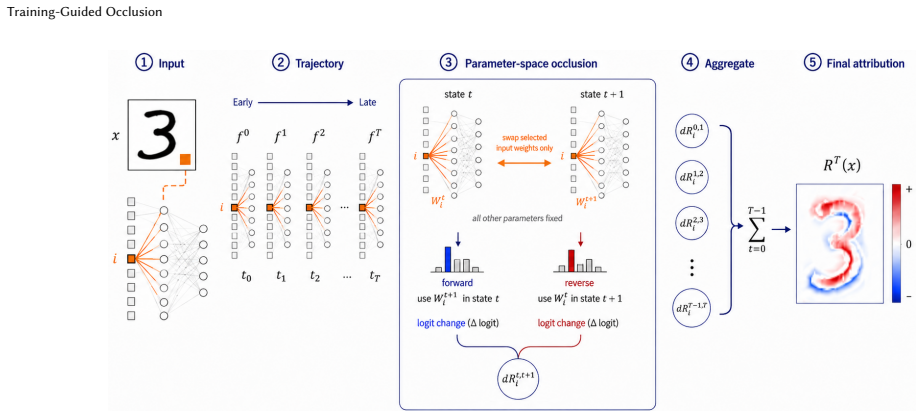
XtrAIn attributes features by measuring how their linked parameter updates change model outputs along the training trajectory rather than by occluding input values.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By transferring the occlusion operation from the input space to the parameter space and measuring the effect of feature-associated parameter updates on output logits along the training trajectory, XtrAIn generates attribution scores that sidestep baseline bias and attribution shift, yielding more stable and interpretable explanations than conventional occlusion techniques.
What carries the argument
Training-guided occlusion that follows the model's training trajectory to measure the output impact of updates to parameters associated with individual input features.
If this is right
- Attribution patterns are cleaner and more interpretable than those produced by standard input-space baselines.
- Xstep supplies a lightweight approximation that reduces computation while preserving the core training-guided mechanism.
- The XtrAIn+ variant focuses on target-class-aligned updates to produce more directed explanations.
- The method functions as a diagnostic for examining how feature-level evidence forms across training epochs.
Where Pith is reading between the lines
- The same training-trajectory lens could be applied to detect when a model begins to rely on spurious correlations by watching which parameter groups update earliest.
- Comparing XtrAIn attributions across different optimizers or learning-rate schedules might reveal how training choices shape which features the model ultimately treats as important.
- Extending the approach beyond image and tabular data to sequence models could test whether parameter-update attributions remain stable when features interact over long ranges.
Load-bearing premise
That tracking feature-linked parameter updates during training will reflect true feature importance without introducing fresh biases or shifts from the training dynamics themselves.
What would settle it
Construct a synthetic dataset with known ground-truth feature importances, compute attributions with XtrAIn and with standard occlusion baselines, and check which set of scores recovers the known importances more accurately.
Figures

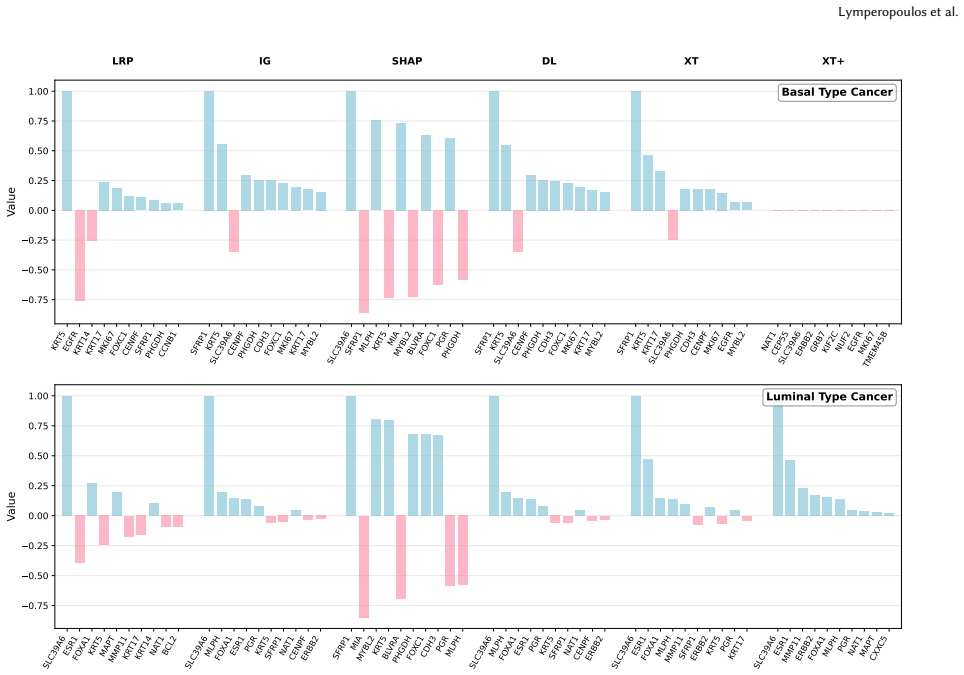
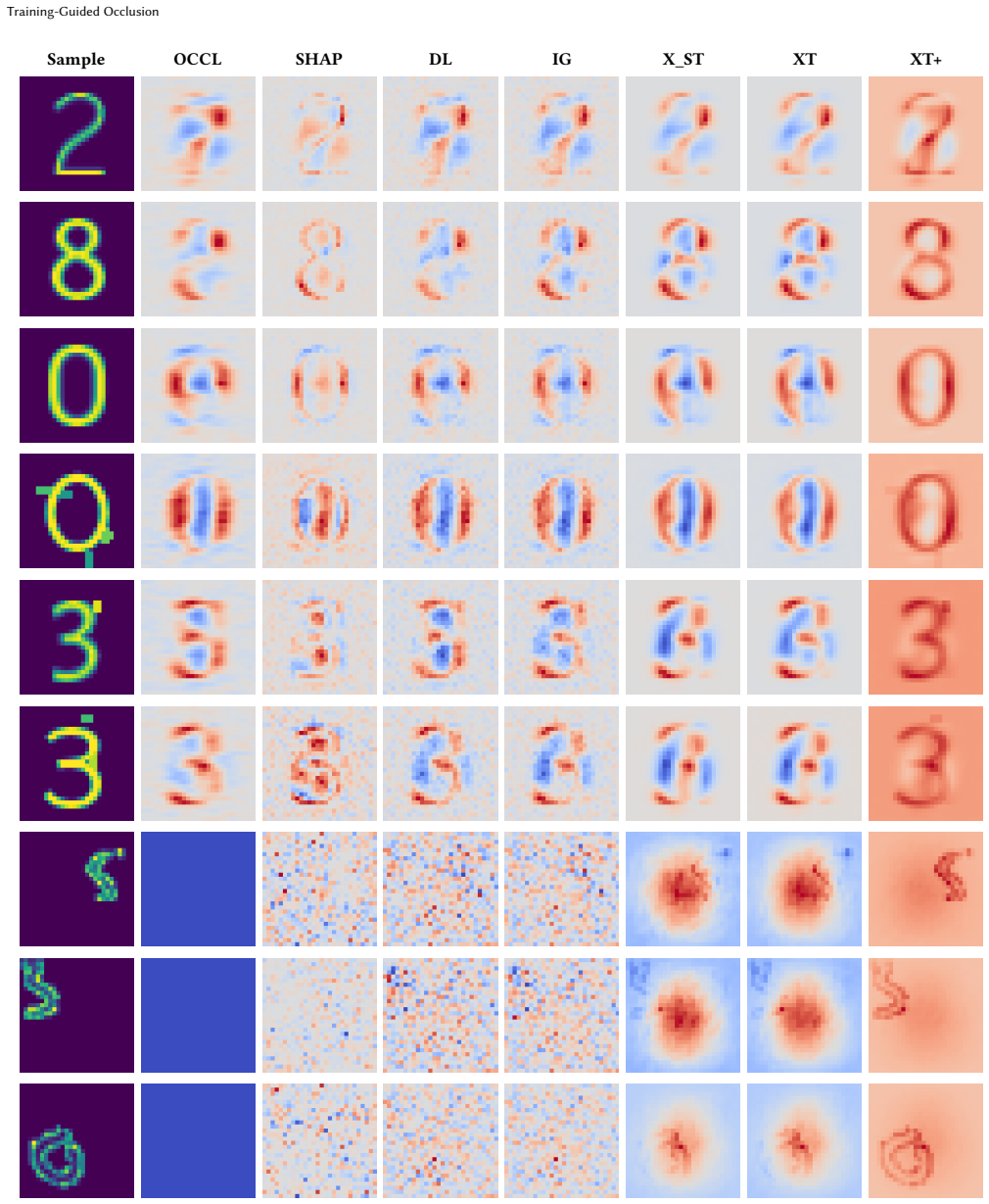
read the original abstract
Occlusion-based attribution methods provide an intuitive way to estimate feature importance by perturbing input features and measuring the resulting change in model output. However, their reliability is strongly affected by how feature removal is implemented: externally selected baselines can introduce bias, out-of-distribution samples, and unstable explanations, while in nonlinear models the occlusion of a set of features can also alter the contribution of non-occluded features. We refer to this effect as attribution shift, as the attribution scores of the non-occluded features drift from their initial values. To challenge these major issues that render explanations unstable, we introduce XtrAIn, a training-guided attribution method that transfers the occlusion operation from the input space to the parameter space. Instead of replacing input values with hand-crafted baselines, XtrAIn follows the model's training trajectory and measures how feature-associated parameter updates affect the output logits. We further introduce Xstep, a lightweight approximation for reducing computational cost, and XtrAIn+, a target-focused variant that emphasizes updates aligned with the target class. Experiments on controlled image datasets and PAM50 breast-cancer subtype classification show that the proposed methods produce cleaner and more interpretable attribution patterns than standard attribution baselines. Overall, XtrAIn provides a training-aware perspective on feature attribution and offers a useful diagnostic tool for studying how feature-level evidence is formed during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces XtrAIn, a training-guided attribution method that transfers the occlusion operation from input space to parameter space by following the model's training trajectory and measuring how feature-associated parameter updates affect output logits. It further proposes Xstep as a lightweight approximation and XtrAIn+ as a target-focused variant. Experiments on controlled image datasets and PAM50 breast-cancer subtype classification are reported to produce cleaner and more interpretable attribution patterns than standard baselines.
Significance. If the central claim holds under quantitative validation, the approach could provide a useful training-aware perspective on feature attribution that mitigates baseline bias and attribution shift, serving as a diagnostic tool for studying feature evidence formation during training in domains such as medical imaging.
major comments (3)
- [Abstract] Abstract: the assertion of superior performance and 'cleaner and more interpretable attribution patterns' supplies no quantitative metrics, controls, error analysis, or statistical comparisons, leaving the empirical claims unsupported by the reported evidence.
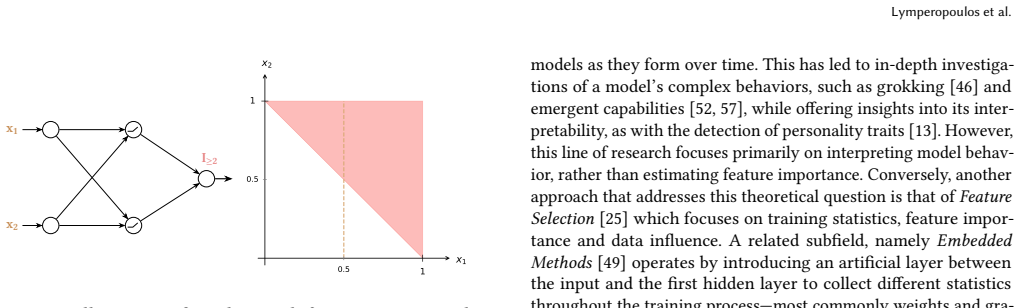
- [Method] Method description: no explicit equation or construction is given for linking a feature to a subset of weights or for isolating feature-associated parameter deltas without introducing new mapping artifacts, rendering the isolation mechanism under-specified.
- [Experiments] Experiments section: the description of results on controlled image data and PAM50 classification provides no details on ground-truth attribution comparisons, ablation studies for architecture-specific parameter sharing, or invariance tests, so the claim of freedom from new biases cannot be evaluated.
minor comments (2)
- Clarify the computational complexity of Xstep relative to full XtrAIn and provide pseudocode for the approximation.
- Ensure all method variants are accompanied by explicit algorithmic steps to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of superior performance and 'cleaner and more interpretable attribution patterns' supplies no quantitative metrics, controls, error analysis, or statistical comparisons, leaving the empirical claims unsupported by the reported evidence.
Authors: The abstract provides a high-level summary of findings detailed in the Experiments section. We agree that referencing quantitative metrics would better support the claims. We will revise the abstract to include key metrics and statistical comparisons from the results. revision: yes
-
Referee: [Method] Method description: no explicit equation or construction is given for linking a feature to a subset of weights or for isolating feature-associated parameter deltas without introducing new mapping artifacts, rendering the isolation mechanism under-specified.
Authors: The Method section describes the conceptual approach of transferring occlusion to parameter space via the training trajectory. We will add explicit equations defining the feature-to-weight association and delta isolation to fully specify the mechanism. revision: yes
-
Referee: [Experiments] Experiments section: the description of results on controlled image data and PAM50 classification provides no details on ground-truth attribution comparisons, ablation studies for architecture-specific parameter sharing, or invariance tests, so the claim of freedom from new biases cannot be evaluated.
Authors: Experiments rely on qualitative visual comparisons since ground-truth attributions are unavailable for these tasks. We will add ablation studies on parameter sharing and invariance tests to the revised Experiments section. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and method description introduce XtrAIn by transferring occlusion to parameter space and measuring training-trajectory updates, without any equations, derivations, or self-citations shown. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations are present. The central claim rests on an independent empirical comparison to baselines rather than reducing to its own inputs by construction. This matches the expectation of a self-contained method description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. 2020. Sanity Checks for Saliency Maps. arXiv:1810.03292 [cs.CV] https://arxiv.org/abs/1810.03292
arXiv 2020
-
[2]
Chirag Agarwal and Anh Nguyen. 2020. Explaining Image Classifiers by Re- moving Input Features Using Generative Models. InComputer Vision – ACCV 2020: 15th Asian Conference on Computer Vision, Kyoto, Japan, November 30 – December 4, 2020, Revised Selected Papers, Part VI(Kyoto, Japan). Springer-Verlag, Berlin, Heidelberg, 101–118. doi:10.1007/978-3-030-69544-6_7
-
[3]
Daniel W. Apley and Jingyu Zhu. 2019. Visualizing the Effects of Predictor Variables in Black Box Supervised Learning Models. arXiv:1612.08468 [stat.ME] https://arxiv.org/abs/1612.08468
arXiv 2019
-
[4]
Maximilian Augustin, Yannic Neuhaus, and Matthias Hein. 2024. DiG- IN: Diffusion Guidance for Investigating Networks – Uncovering Classifier Differences Neuron Visualisations and Visual Counterfactual Explanations. arXiv:2311.17833 [cs.CV] https://arxiv.org/abs/2311.17833
arXiv 2024
-
[5]
Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. 2015. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation.PLOS ONE10 (07 2015), 1–46. doi:10.1371/journal.pone.0130140
-
[6]
Deepshikha Bhati, MD Amiruzzaman, Ye Zhao, Angela Guercio, and Tram Le
-
[7]
A Survey of Post-Hoc XAI Methods From a Visualization Perspective: Challenges and Opportunities.IEEE Access13 (2025), 120785–120806. doi:10. 1109/ACCESS.2025.3581136
arXiv 2025
-
[8]
Stefan Bluecher, Johanna Vielhaben, and Nils Strodthoff. 2024. Decoupling Pixel Flipping and Occlusion Strategy for Consistent XAI Benchmarks.Transac- tions on Machine Learning Research(2024). https://openreview.net/forum?id= bIiLXdtUVM
2024
-
[9]
Lennart Brocki and Neo Christopher Chung. 2023. Feature perturbation aug- mentation for reliable evaluation of importance estimators in neural networks. Pattern Recognition Letters176 (2023), 131–139. doi:10.1016/j.patrec.2023.10.012
-
[10]
Nadia Burkart and Marco F. Huber. 2021. A Survey on the Explainability of Supervised Machine Learning.J. Artif. Int. Res.70 (May 2021), 245–317. doi:10. 1613/jair.1.12228
2021
-
[11]
Ho Chan and Eduardo Veas. 2024. Importance Estimate of Features via analysis of their Weight and Gradient profile. (04 2024). doi:10.21203/rs.3.rs-4217886/v1
-
[12]
Chun-Hao Chang, Elliot Creager, Anna Goldenberg, and David Duve- naud. 2019. Explaining Image Classifiers by Counterfactual Generation. arXiv:1807.08024 [cs.CV] https://arxiv.org/abs/1807.08024
Pith/arXiv arXiv 2019
-
[13]
Aditya Chattopadhyay, Piyushi Manupriya, Anirban Sarkar, and Vineeth N Bala- subramanian. 2019. Neural Network Attributions: A Causal Perspective. InPro- ceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdi- nov (Eds.). PMLR, 981–990. https://proceed...
2019
-
[14]
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. 2025. Persona Vectors: Monitoring and Controlling Character Traits in Language Models. arXiv:2507.21509 [cs.CL] https://arxiv.org/abs/2507.21509
Pith/arXiv arXiv 2025
-
[15]
Ian Covert, Chanwoo Kim, and Su-In Lee. 2023. Learning to Estimate Shapley Values with Vision Transformers. arXiv:2206.05282 [cs.CV] https://arxiv.org/ abs/2206.05282
arXiv 2023
-
[16]
Ian Covert, Scott Lundberg, and Su-In Lee. 2021. Explaining by Removing: A Unified Framework for Model Explanation.Journal of Machine Learning Research 22, 209 (2021), 1–90. http://jmlr.org/papers/v22/20-1316.html
2021
-
[17]
Aaron Fisher, Cynthia Rudin, and Francesca Dominici. 2019. All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously.Journal of Machine Learning Research20, 177 (2019), 1–81. http://jmlr.org/papers/v20/18-760.html
2019
-
[18]
Fong and Andrea Vedaldi
Ruth C. Fong and Andrea Vedaldi. 2017. Interpretable Explanations of Black Boxes by Meaningful Perturbation. In2017 IEEE International Conference on Computer Vision (ICCV). Association for Computing Machinery, 3449–3457. doi:10.1109/ ICCV.2017.371
2017
-
[19]
10 Evaluating Bivariate Causal Statements Based on Mutual Compatibility Richardson, T
Jerome H. Friedman. 2001. Greedy function approximation: A gradient boosting machine.The Annals of Statistics29, 5 (2001), 1189 – 1232. doi:10.1214/aos/ 1013203451
-
[20]
Ruigang Fu, Qingyong Hu, Xiaohu Dong, Yulan Guo, Yinghui Gao, and Biao Li
-
[21]
arXiv:2008.02312 [cs.CV] https://arxiv.org/abs/2008.02312
Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs. arXiv:2008.02312 [cs.CV] https://arxiv.org/abs/2008.02312
arXiv 2008
-
[22]
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christo- pher Potts, and Thomas Icard. 2025. Causal Abstraction: A Theoretical Founda- tion for Mechanistic Interpretability. arXiv:2301.04709 [cs.AI] https://arxiv.org/ abs/2301.04709
arXiv 2025
-
[23]
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. 2021. Causal Abstractions of Neural Networks. InAdvances in Neural In- formation Processing Systems, M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (Eds.), Vol. 34. Curran Associates, Inc., 9574–9586. https://proceedings.neurips.cc/paper_files/paper/2021/file/ 4f5c...
2021
-
[24]
Arne Gevaert, Axel-Jan Rousseau, Thijs Becker, Dirk Valkenborg, Tijl De Bie, and Yvan Saeys. 2024. Evaluating feature attribution methods in the image domain.Machine Learning113, 9 (01 Sep 2024), 6019–6064. doi:10.1007/s10994- 024-06550-x
-
[25]
Tristan Gomez, Thomas Fréour, and Harold Mouchère. 2022. Metrics for saliency map evaluation of deep learning explanation methods. InPattern Recognition and Artificial Intelligence: Third International Conference, ICPRAI 2022, Paris, France, June 1–3, 2022, Proceedings, Part I(Paris, France). Springer-Verlag, Berlin, Heidelberg, 84–95. doi:10.1007/978-3-0...
-
[26]
Jindong Gu, Yinchong Yang, and Volker Tresp. 2019. Understanding Individual Decisions of CNNs via Contrastive Backpropagation. arXiv:1812.02100 [cs.CV] https://arxiv.org/abs/1812.02100
arXiv 2019
-
[27]
Isabelle Guyon and André Elisseeff. 2003. An introduction to variable and feature selection.J. Mach. Learn. Res.3, null (March 2003), 1157–1182
2003
-
[28]
Peter Hase, Harry Xie, and Mohit Bansal. 2021. The out-of-distribution problem in explainability and search methods for feature importance explanations. In Proceedings of the 35th International Conference on Neural Information Processing Systems (NIPS ’21). Curran Associates Inc., Red Hook, NY, USA, Article 279, 17 pages
2021
-
[29]
Stefan Haufe, Rick Wilming, Benedict Clark, Rustam Zhumagambetov, Ahcène Boubekki, Jörg Martin, and Danny Panknin. 2026. Explainable AI needs formal- ization.npj Artificial Intelligence2, 1 (April 2026), 42. doi:10.1038/s44387-026- 00095-1
-
[30]
Johannes Haug, Stefan Zurn, Peter El-Jiz, and Gjergji Kasneci. 2021. On Base- lines for Local Feature Attributions.ArXivabs/2101.00905 (2021). https: //api.semanticscholar.org/CorpusID:230435957
arXiv 2021
-
[31]
Giles Hooker, Lucas Mentch, and Siyu Zhou. 2021. Unrestricted permutation forces extrapolation: variable importance requires at least one more model, or there is no free variable importance.Statistics and Computing31, 6 (Nov. 2021), 16 pages. doi:10.1007/s11222-021-10057-z
-
[32]
2019.A benchmark for interpretability methods in deep neural networks
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, and Been Kim. 2019.A benchmark for interpretability methods in deep neural networks. Curran Associates Inc., Red Hook, NY, USA
2019
-
[33]
Brian Kenji Iwana, Ryohei Kuroki, and Seiichi Uchida. 2019. Explaining Convo- lutional Neural Networks using Softmax Gradient Layer-wise Relevance Propa- gation. arXiv:1908.04351 [cs.CV] https://arxiv.org/abs/1908.04351
arXiv 2019
-
[34]
Cosimo Izzo, Aldo Lipani, Ramin Okhrati, and Francesca Medda. 2021. A Baseline for Shapley Values in MLPs: from Missingness to Neutrality. InESANN 2021 proceedings (ESANN 2021). Ciaco - i6doc.com, 605–610. doi:10.14428/esann/2021. es2021-18
-
[35]
Saachi Jain, Hadi Salman, Eric Wong, Pengchuan Zhang, Vibhav Vineet, Sai Vemprala, and Aleksander Madry. 2022. Missingness Bias in Model Debugging. arXiv:2204.08945 [cs.CV] https://arxiv.org/abs/2204.08945
arXiv 2022
-
[36]
Elizabeth Kumar, Suresh Venkatasubramanian, Carlos Scheidegger, and Sorelle Friedler
I. Elizabeth Kumar, Suresh Venkatasubramanian, Carlos Scheidegger, and Sorelle Friedler. 2020. Problems with Shapley-value-based explanations as feature impor- tance measures. InProceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 119), Hal Daumé III and Aarti Singh (Eds.). PMLR, 5491–5500. h...
2020
-
[37]
Zachary C. Lipton. 2018. The mythos of model interpretability.Commun. ACM 61, 10 (Sept. 2018), 36–43. doi:10.1145/3233231
-
[38]
Lundberg and Su-In Lee
Scott M. Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 4768–4777
2017
-
[39]
Thodoris Lymperopoulos and Denia Kanellopoulou. 2026. From Weight Pertur- bation to Feature Attribution for Explaining Fully Connected Neural Networks. arXiv:2605.15328 [cs.LG] https://arxiv.org/abs/2605.15328
Pith/arXiv arXiv 2026
-
[40]
K Scott Mader. 2013. affNIST (Affine MNIST). Department of Computer Science, University of toronto. https://www.cs.toronto.edu/~tijmen/affNIST/
2013
-
[41]
Antonios Mamalakis, Elizabeth A. Barnes, and Imme Ebert-Uphoff. 2023. Care- fully Choose the Baseline: Lessons Learned from Applying XAI Attribution Methods for Regression Tasks in Geoscience.Artificial Intelligence for the Earth Systems2, 1 (2023), e220058. doi:10.1175/AIES-D-22-0058.1
-
[42]
Jacqueline Michelle Metsch and Anne-Christin Hauschild. 2025. BenchXAI: Comprehensive benchmarking of post-hoc explainable AI methods on multi- modal biomedical data.Computers in Biology and Medicine191 (2025), 110124. doi:10.1016/j.compbiomed.2025.110124
-
[43]
Fuseini Mumuni and Alhassan G. Mumuni. 2025. Explainable artificial intel- ligence (XAI): from inherent explainability to large language models.ArXiv abs/2501.09967 (2025). https://api.semanticscholar.org/CorpusID:275606857
arXiv 2025
-
[44]
National Cancer Institute. n.d.. Genomic Data Commons Data Portal. https: //portal.gdc.cancer.gov/. Accessed: 2025-11-10
2025
-
[45]
Meike Nauta, Jan Trienes, Shreyasi Pathak, Elisa Nguyen, Michelle Peters, Yasmin Schmitt, Jörg Schlötterer, Maurice van Keulen, and Christin Seifert. 2023. From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review 10 Training-Guided Occlusion on Evaluating Explainable AI.Comput. Surveys55, 13s (July 2023), 1–42. doi:10. 1145/3583558
2023
-
[46]
Parker, Michael Mullins, Maggie C.U
Joel S. Parker, Michael Mullins, Maggie C.U. Cheang, Samuel Leung, David Voduc, Tammi Vickery, Sherri Davies, Christiane Fauron, Xiaping He, Zhiyuan Hu, John F. Quackenbush, Inge J. Stijleman, Juan Palazzo, J.S. Marron, Andrew B. Nobel, Elaine Mardis, Torsten O. Nielsen, Matthew J. Ellis, Charles M. Perou, and Philip S. Bernard. 2009. Supervised Risk Pred...
-
[47]
Vitali Petsiuk, Abir Das, and Kate Saenko. 2018. RISE: Randomized Input Sampling for Explanation of Black-box Models. arXiv:1806.07421 [cs.CV] https://arxiv.org/abs/1806.07421
Pith/arXiv arXiv 2018
-
[48]
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra
-
[49]
arXiv:2201.02177 [cs.LG] https://arxiv.org/abs/2201.02177
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. arXiv:2201.02177 [cs.LG] https://arxiv.org/abs/2201.02177
-
[50]
Ren, Zhanpeng Zhou, Qirui Chen, and Quanshi Zhang
J. Ren, Zhanpeng Zhou, Qirui Chen, and Quanshi Zhang. 2023. Can We Faithfully Represent Absence States to Compute Shapley Values on a DNN?. InInterna- tional Conference on Learning Representations. https://api.semanticscholar.org/ CorpusID:259298245
2023
-
[51]
Yao Rong, Tobias Leemann, Vadim Borisov, Gjergji Kasneci, and Enkelejda Kas- neci. 2022. A Consistent and Efficient Evaluation Strategy for Attribution Meth- ods. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Ste- fanie Jegelka, Le Song, Csaba Szepesvari, Ga...
2022
-
[52]
Shota Saito, Shinichi Shirakawa, and Youhei Akimoto. 2018. Embedded feature se- lection using probabilistic model-based optimization. InProceedings of the Genetic and Evolutionary Computation Conference Companion(Kyoto, Japan)(GECCO ’18). Association for Computing Machinery, New York, NY, USA, 1922–1925. doi:10.1145/3205651.3208227
-
[53]
Mohammadreza Salehi, Hossein Mirzaei, Dan Hendrycks, Yixuan Li, Moham- mad Hossein Rohban, and Mohammad Sabokrou. 2022. A Unified Survey on Anomaly, Novelty, Open-Set, and Out of-Distribution Detection: Solutions and Future Challenges.Transactions on Machine Learning Research(2022). https://openreview.net/forum?id=aRtjVZvbpK
2022
-
[54]
Anders, and Klaus-Robert Müller
Wojciech Samek, Grégoire Montavon, Sebastian Lapuschkin, Christopher J. An- ders, and Klaus-Robert Müller. 2021. Explaining Deep Neural Networks and Beyond: A Review of Methods and Applications.Proc. IEEE109, 3 (2021), 247–278. doi:10.1109/JPROC.2021.3060483
-
[55]
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. 2023. Are Emergent Abilities of Large Language Models a Mirage? arXiv:2304.15004 [cs.AI] https://arxiv.org/ abs/2304.15004
arXiv 2023
-
[56]
Fabian Schmeisser, Adriano Lucieri, Andreas Dengel, and Sheraz Ahmed. 2026. Spectral Occlusion - Attribution Beyond Spatial Relevance Heatmaps. InExplain- able Artificial Intelligence, Riccardo Guidotti, Ute Schmid, and Luca Longo (Eds.). Springer Nature Switzerland, Cham, 159–183
2026
-
[57]
Rui Shi, Tianxing Li, and Yasushi Yamaguchi. 2022. Output-targeted baseline for neuron attribution calculation.Image Vision Comput.124, C (Aug. 2022), 13 pages. doi:10.1016/j.imavis.2022.104516
-
[58]
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. 2019. Learn- ing Important Features Through Propagating Activation Differences. arXiv:1704.02685 [cs.CV] https://arxiv.org/abs/1704.02685
arXiv 2019
-
[59]
Suraj Srinivas and Francois Fleuret. 2019. Full-Gradient Representation for Neural Network Visualization. arXiv:1905.00780 [cs.LG] https://arxiv.org/abs/ 1905.00780
arXiv 2019
-
[60]
Jacob Steinhardt. 2023. Emergent Deception and Emergent Optimization. https: //bounded-regret.ghost.io/emergent-deception-optimization/
2023
-
[61]
Pascal Sturmfels, Scott Lundberg, and Su-In Lee. 2020. Visualizing the Im- pact of Feature Attribution Baselines.Distill(2020). doi:10.23915/distill.00022 https://distill.pub/2020/attribution-baselines
-
[62]
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic Attribution for Deep Networks. arXiv:1703.01365 [cs.LG] https://arxiv.org/abs/1703.01365
Pith/arXiv arXiv 2017
-
[63]
Michael Tsang, Sirisha Rambhatla, and Yan Liu. 2020. How does This In- teraction Affect Me? Interpretable Attribution for Feature Interactions. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ran- zato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Associates, Inc., 6147–6159. https://proceedings.neurips.cc/paper_file...
2020
-
[64]
Pedro Valois, Koichiro Niinuma, and Kazuhiro Fukui. 2024. Occlusion Sensitivity Analysis with Augmentation Subspace Perturbation in Deep Feature Space. 4817–
2024
-
[65]
doi:10.1109/WACV57701.2024.00476
-
[66]
Giulia Vilone and Luca Longo. 2020. Explainable Artificial Intelligence: a Sys- tematic Review. arXiv:2006.00093 [cs.AI] https://arxiv.org/abs/2006.00093
arXiv 2020
-
[67]
Saurabh Vyawahare. 2024. TMNIST (Typeface MNIST). Kaggle. https://www. kaggle.com/datasets/saurabhvyawahare/tmnist-typeface-mnist
2024
-
[68]
Zeiler and Rob Fergus
Matthew D. Zeiler and Rob Fergus. 2014. Visualizing and Understanding Convo- lutional Networks. InComputer Vision – ECCV 2014, David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars (Eds.). Springer International Publishing, Cham, 818–833. 11 Lymperopoulos et al. A Proofs A.1 Inverse Property of Attribution Proof. First, we expressR𝑡+2 in terms of...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.