Task Robustness via Re-Labelling Vision-Action Robot Data
Pith reviewed 2026-06-27 12:45 UTC · model grok-4.3
The pith
Re-labelling existing robot data using vision-language models leads to policies that generalize better to novel tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
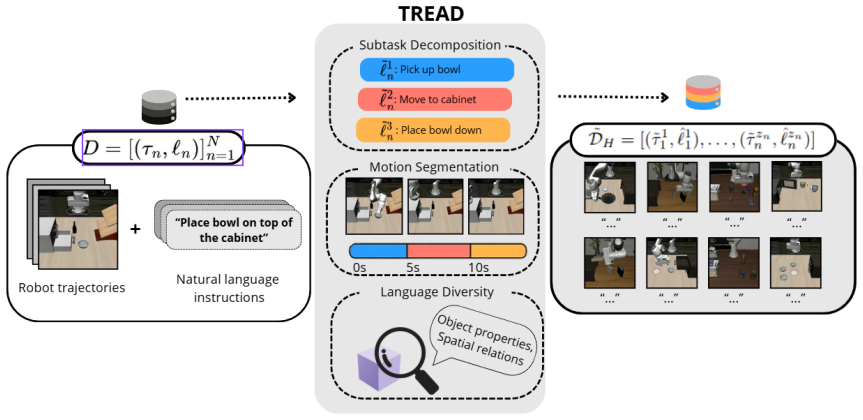
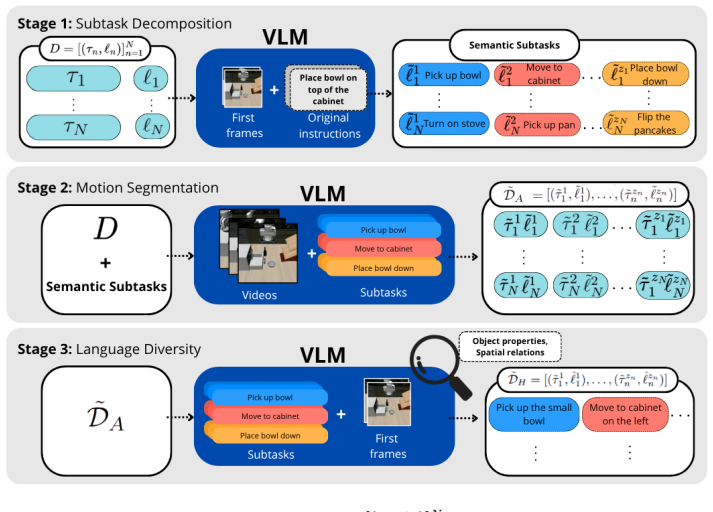
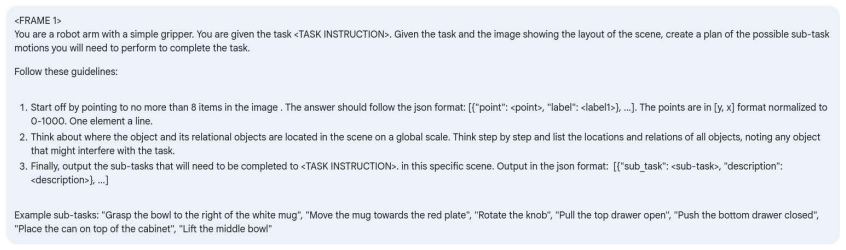
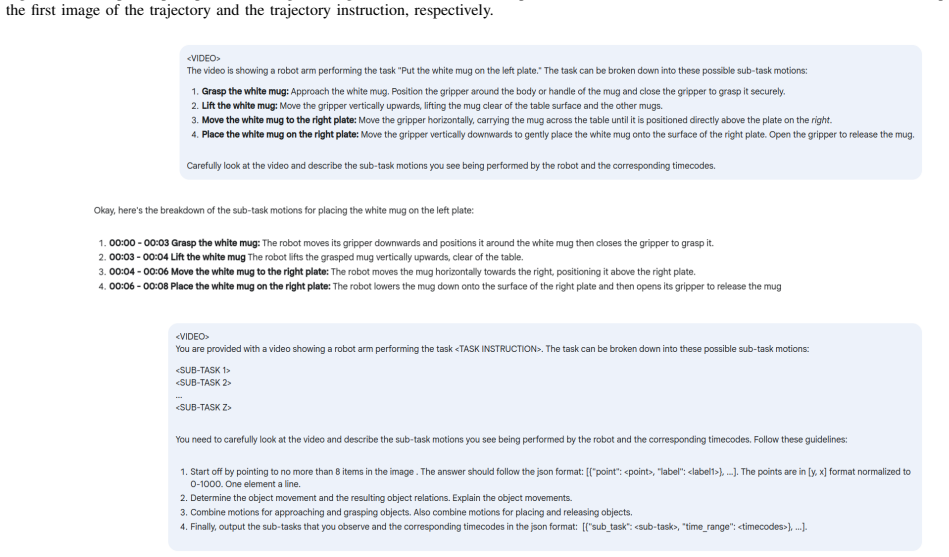
TREAD applies a pretrained VLM in three stages—generating semantic sub-tasks from original instruction labels and initial scenes, segmenting demonstration videos conditioned on those sub-tasks, and producing diverse instructions that incorporate object properties—to decompose longer demonstrations into grounded language-action pairs and augment the data with linguistically varied text goals, resulting in policies that exhibit improved performance on novel unseen tasks and goals in LIBERO evaluations.
What carries the argument
Three-stage VLM pipeline that generates sub-tasks, performs conditioned video segmentation, and creates diverse instructions from original vision-action data.
If this is right
- Policies show improved performance on novel unseen tasks and goals after training on the augmented data.
- Trajectory decomposition enhances planning generalization.
- Increased linguistic diversity improves language-conditioned policy generalization.
- The approach scales dataset diversity without requiring additional robot data collection.
Where Pith is reading between the lines
- Reusing existing datasets this way could reduce the overall cost of training capable manipulation policies.
- The same re-labelling strategy might transfer to other domains that rely on limited demonstration data such as navigation or assembly.
- Combining VLM outputs with selective human review could be tested to handle cases where model-generated labels contain errors.
Load-bearing premise
The sub-task labels and segmentations generated by the VLM are accurate enough that they do not introduce noise or bias that degrades policy learning.
What would settle it
Training policies on TREAD-augmented datasets and finding no improvement or worse performance compared with original datasets on novel unseen tasks in the LIBERO benchmark would falsify the central claim.
Figures


read the original abstract
The recent trend in scaling models for robot learning has resulted in impressive policies that can perform various manipulation tasks and generalize to novel scenarios. However, these policies continue to struggle with following instructions, likely due to the limited linguistic and action sequence diversity in existing robotics datasets. This paper introduces Task Robustness via Re-Labelling Vision-Action Robot Data (TREAD), a scalable framework that leverages large Vision-Language Models (VLMs) to augment existing robotics datasets without additional data collection, harnessing the transferable knowledge embedded in these models. Our approach leverages a pretrained VLM through three stages: generating semantic sub-tasks from original instruction labels and initial scenes, segmenting demonstration videos conditioned on these sub-tasks, and producing diverse instructions that incorporate object properties, effectively decomposing longer demonstrations into grounded language-action pairs. We further enhance robustness by augmenting the data with linguistically diverse versions of the text goals. Evaluations on LIBERO demonstrate that policies trained on our augmented datasets exhibit improved performance on novel, unseen tasks and goals. Our results show that TREAD enhances both planning generalization through trajectory decomposition and language-conditioned policy generalization through increased linguistic diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TREAD, a three-stage framework that uses pretrained VLMs to re-label existing vision-action robot datasets: generating semantic sub-tasks from instructions and scenes, segmenting demonstration videos on those sub-tasks, and producing linguistically diverse instructions that incorporate object properties. The central claim is that policies trained on the resulting augmented datasets show improved performance on novel, unseen tasks and goals in the LIBERO benchmark.
Significance. If the VLM-generated labels prove accurate and the reported gains hold under controlled evaluation, the approach would offer a scalable route to increasing linguistic and task diversity in robot datasets without new collection, directly addressing generalization limits in language-conditioned imitation learning.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation section: the headline claim of improved LIBERO performance on novel tasks/goals is stated without any quantitative numbers, error bars, baseline comparisons, or controls for VLM error rates, so the magnitude and reliability of the result cannot be assessed from the provided text.
- [§3] §3 (TREAD pipeline description): the three-stage VLM procedure for sub-task generation, video segmentation, and instruction augmentation lacks any reported accuracy metric (human agreement, segmentation IoU, or ablation removing low-confidence outputs), which is load-bearing because systematic VLM errors could add noise rather than signal and thereby explain or negate downstream policy gains.
minor comments (1)
- [Abstract] The abstract's description of how the VLM is conditioned across the three stages could be expanded with example prompts or conditioning details for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the presentation of our results and the validation of the VLM pipeline components. We address each major comment below and will incorporate revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the headline claim of improved LIBERO performance on novel tasks/goals is stated without any quantitative numbers, error bars, baseline comparisons, or controls for VLM error rates, so the magnitude and reliability of the result cannot be assessed from the provided text.
Authors: We agree that the abstract would benefit from explicit quantitative results. The evaluation section of the manuscript includes tables reporting success rates on LIBERO novel tasks and goals, with comparisons to baselines (original dataset and alternative augmentation methods) and standard deviations across multiple random seeds. To address the concern directly, we will revise the abstract to include key performance metrics (e.g., absolute and relative improvements) along with a brief mention of the controls. We will also expand the evaluation section discussion to explicitly address potential VLM error propagation via the existing ablations on each pipeline stage. revision: yes
-
Referee: [§3] §3 (TREAD pipeline description): the three-stage VLM procedure for sub-task generation, video segmentation, and instruction augmentation lacks any reported accuracy metric (human agreement, segmentation IoU, or ablation removing low-confidence outputs), which is load-bearing because systematic VLM errors could add noise rather than signal and thereby explain or negate downstream policy gains.
Authors: We recognize that direct validation metrics for the VLM stages would strengthen the claims, as downstream gains alone do not fully isolate label quality. The current manuscript relies on end-to-end policy performance and stage-wise ablations as indirect evidence. In revision, we will add a new subsection with human agreement rates on sub-task generation (sampled annotations), segmentation quality metrics, and an ablation that removes low-confidence VLM outputs to demonstrate that the observed gains are not attributable to noise. revision: yes
Circularity Check
No circularity: derivation relies on external VLMs and benchmark evaluation
full rationale
The paper presents a three-stage pipeline using pretrained VLMs to generate sub-task labels, segmentations, and diverse instructions from existing robot data, followed by policy training and evaluation on the external LIBERO benchmark. No equations, fitted parameters, or self-referential definitions appear in the provided text. The central claim (improved generalization on novel tasks) is supported by empirical results on an independent benchmark rather than reducing to a self-citation chain, ansatz, or input-by-construction prediction. The approach is self-contained against external benchmarks and pretrained models.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam et al. “Gpt-4 technical report”. In:arXiv preprint arXiv:2303.08774(2023)
Pith/arXiv arXiv 2023
-
[2]
Shuai Bai et al.Qwen2.5-VL Technical Report. 2025. arXiv:2502. 13923 [cs.CV]
2025
-
[3]
Paligemma: A versatile 3b vlm for transfer
Lucas Beyer et al. “Paligemma: A versatile 3b vlm for transfer”. In: arXiv preprint arXiv:2407.07726(2024)
Pith/arXiv arXiv 2024
-
[4]
Roboagent: Generalization and effi- ciency in robot manipulation via semantic augmentations and action chunking
Homanga Bharadhwaj et al. “Roboagent: Generalization and effi- ciency in robot manipulation via semantic augmentations and action chunking”. In:IEEE International Conference on Robotics and Automation. 2024, pp. 4788–4795
2024
-
[5]
Kevin Black et al.π 0: A Vision-Language-Action Flow Model for General Robot Control. 2025. arXiv:2410.24164 [cs.LG]
Pith/arXiv arXiv 2025
-
[6]
Scaling Robot Policy Learning via Zero-Shot Labeling with Foundation Models
Nils Blank et al. “Scaling Robot Policy Learning via Zero-Shot Labeling with Foundation Models”. In:Proceedings of Conference on Robot Learning. 2024
2024
-
[7]
Rt-1: Robotics transformer for real-world control at scale
Anthony Brohan et al. “Rt-1: Robotics transformer for real-world control at scale”. In:Proceedings of Robotics: Science and Systems. 2022
2022
-
[8]
Jingjing Chen et al.Towards Effective Utilization of Mixed-Quality Demonstrations in Robotic Manipulation via Segment-Level Selec- tion and Optimization. 2025. arXiv:2409.19917 [cs.RO]
arXiv 2025
-
[9]
GenAug: Retargeting behaviors to unseen situ- ations via Generative Augmentation
Qiuyu Chen et al. “GenAug: Retargeting behaviors to unseen situ- ations via Generative Augmentation”. In:Proceedings of Robotics: Science and Systems. 2023.DOI:10.15607/RSS.2023.XIX. 010
-
[10]
Gheorghe Comanici et al.Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Gen- eration Agentic Capabilities. 2025. arXiv:2507.06261 [cs.CL]
Pith/arXiv arXiv 2025
-
[11]
Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot
Hao-Shu Fang et al. “Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot”. In:IEEE International Confer- ence on Robotics and Automation. 2024, pp. 653–660
2024
-
[12]
ReMix: Optimizing Data Mixtures for Large Scale Imitation Learning
Joey Hejna et al. “ReMix: Optimizing Data Mixtures for Large Scale Imitation Learning”. In:Proceedings of Conference on Robot Learning. V ol. 270. Proceedings of Machine Learning Research. PMLR, 2025, pp. 145–164
2025
-
[13]
Bc-z: Zero-shot task generalization with robotic imitation learning
Eric Jang et al. “Bc-z: Zero-shot task generalization with robotic imitation learning”. In:Conference on Robot Learning. PMLR. 2022, pp. 991–1002
2022
-
[14]
VIMA: Robot Manipulation with Multimodal Prompts
Yunfan Jiang et al. “VIMA: Robot Manipulation with Multimodal Prompts”. In:Proceedings of Conference on Machine Learning. V ol. 202. Proceedings of Machine Learning Research. PMLR, 2023, pp. 14975–15022
2023
-
[15]
Scaling Up Multi-Task Robotic Re- inforcement Learning
Dmitry Kalashnikov et al. “Scaling Up Multi-Task Robotic Re- inforcement Learning”. In:Proceedings of Conference on Robot Learning. V ol. 164. Proceedings of Machine Learning Research. PMLR, 2022, pp. 557–575
2022
-
[16]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky et al. “DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset”. In:Robotics: Science and Systems. 2024
2024
-
[17]
Fine-Tuning Vision- Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. “Fine-Tuning Vision- Language-Action Models: Optimizing Speed and Success”. In:arXiv preprint arXiv:2502.19645(2025)
Pith/arXiv arXiv 2025
-
[18]
Openvla: An open-source vision-language-action model
Moo Jin Kim et al. “Openvla: An open-source vision-language-action model”. In:arXiv preprint arXiv:2406.09246(2024)
Pith/arXiv arXiv 2024
-
[19]
Data scaling laws in imitation learning for robotic manipulation
Fanqi Lin et al. “Data scaling laws in imitation learning for robotic manipulation”. In:arXiv preprint arXiv:2410.18647(2024)
arXiv 2024
-
[20]
Libero: Benchmarking knowledge transfer for lifelong robot learning
Bo Liu et al. “Libero: Benchmarking knowledge transfer for lifelong robot learning”. In:Advances in Neural Information Processing Systems36 (2023), pp. 44776–44791
2023
-
[21]
Visual Instruction Tuning
Haotian Liu et al. “Visual Instruction Tuning”. In:NeurIPS. 2023
2023
-
[22]
Rdt-1b: a diffusion foundation model for bi- manual manipulation
Songming Liu et al. “Rdt-1b: a diffusion foundation model for bi- manual manipulation”. In:arXiv preprint arXiv:2410.07864(2024)
Pith/arXiv arXiv 2024
-
[23]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. “SGDR: Stochastic Gradient Descent with Warm Restarts”. In:5th International Conference on Learning Representations. 2017
2017
-
[24]
Interactive language: Talking to robots in real time,
Corey Lynch et al. “Interactive Language: Talking to Robots in Real Time”. In:IEEE Robotics and Automation Letters(2023), pp. 1–8. DOI:10.1109/LRA.2023.3295255
-
[25]
Cacti: A framework for scalable multi-task multi- scene visual imitation learning
Zhao Mandi et al. “Cacti: A framework for scalable multi-task multi- scene visual imitation learning”. In:arXiv preprint arXiv:2212.05711 (2022)
arXiv 2022
-
[26]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill et al. “Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0”. In:IEEE In- ternational Conference on Robotics and Automation. 2024, pp. 6892– 6903
2024
-
[27]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team et al. “Octo: An Open-Source Generalist Robot Policy”. In:Proceedings of Robotics: Science and Systems. 2024
2024
-
[28]
Karl Pertsch et al.FAST: Efficient Action Tokenization for Vision- Language-Action Models. 2025. arXiv:2501.09747 [cs.RO]
Pith/arXiv arXiv 2025
-
[29]
Learning Temporally Composable Task Seg- mentations with Language
Divyanshu Raj et al. “Learning Temporally Composable Task Seg- mentations with Language”. In:IEEE/RSJ International Conference on Intelligent Robots and Systems. 2024, pp. 5195–5202
2024
-
[30]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke et al. “Bridgedata v2: A dataset for robot learning at scale”. In:Proceedings of Conference on Robot Learning. V ol. 229. PMLR. 2023, pp. 1723–1736
2023
-
[31]
Robotic Skill Acquisition via Instruction Augmen- tation with Vision-Language Models
Ted Xiao et al. “Robotic Skill Acquisition via Instruction Augmen- tation with Vision-Language Models”. In:Proceedings of Robotics: Science and Systems. 2023
2023
-
[32]
Decomposing the generalization gap in imitation learning for visual robotic manipulation
Annie Xie et al. “Decomposing the generalization gap in imitation learning for visual robotic manipulation”. In:IEEE International Conference on Robotics and Automation. 2024, pp. 3153–3160
2024
-
[33]
Scaling Robot Learning with Semantically Imag- ined Experience
Tianhe Yu et al. “Scaling Robot Learning with Semantically Imag- ined Experience”. In:Proceedings of Robotics: Science and Systems. 2023.DOI:10.15607/RSS.2023.XIX.027
-
[34]
Boqiang Zhang et al.VideoLLaMA 3: Frontier Multimodal Foun- dation Models for Image and Video Understanding. 2025. arXiv: 2501.13106 [cs.CV]
Pith/arXiv arXiv 2025
-
[35]
Sprint: Scalable policy pre-training via lan- guage instruction relabeling
Jesse Zhang et al. “Sprint: Scalable policy pre-training via lan- guage instruction relabeling”. In:IEEE International Conference on Robotics and Automation. 2024, pp. 9168–9175
2024
-
[36]
Yuanhan Zhang et al.Video Instruction Tuning With Synthetic Data
-
[37]
arXiv:2410.02713 [cs.CV]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.