Do Transformers Actually Help Intrusion Detection? A Temporal Sequence Evaluation on CIC-IDS2017
Pith reviewed 2026-06-27 12:32 UTC · model grok-4.3
The pith
Padding convention determines whether Transformers outperform other models on temporal network intrusion detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
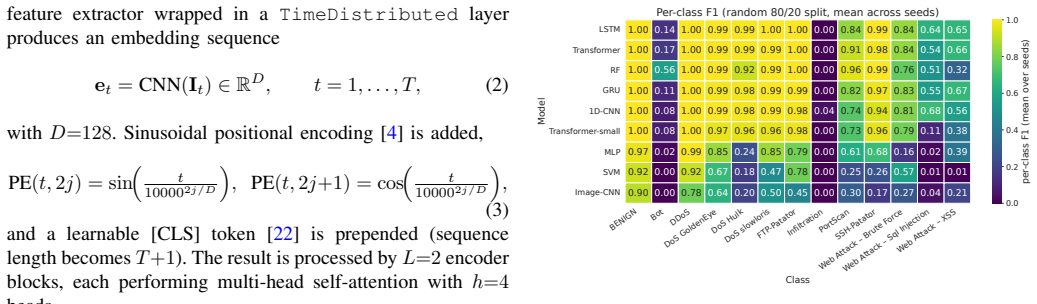
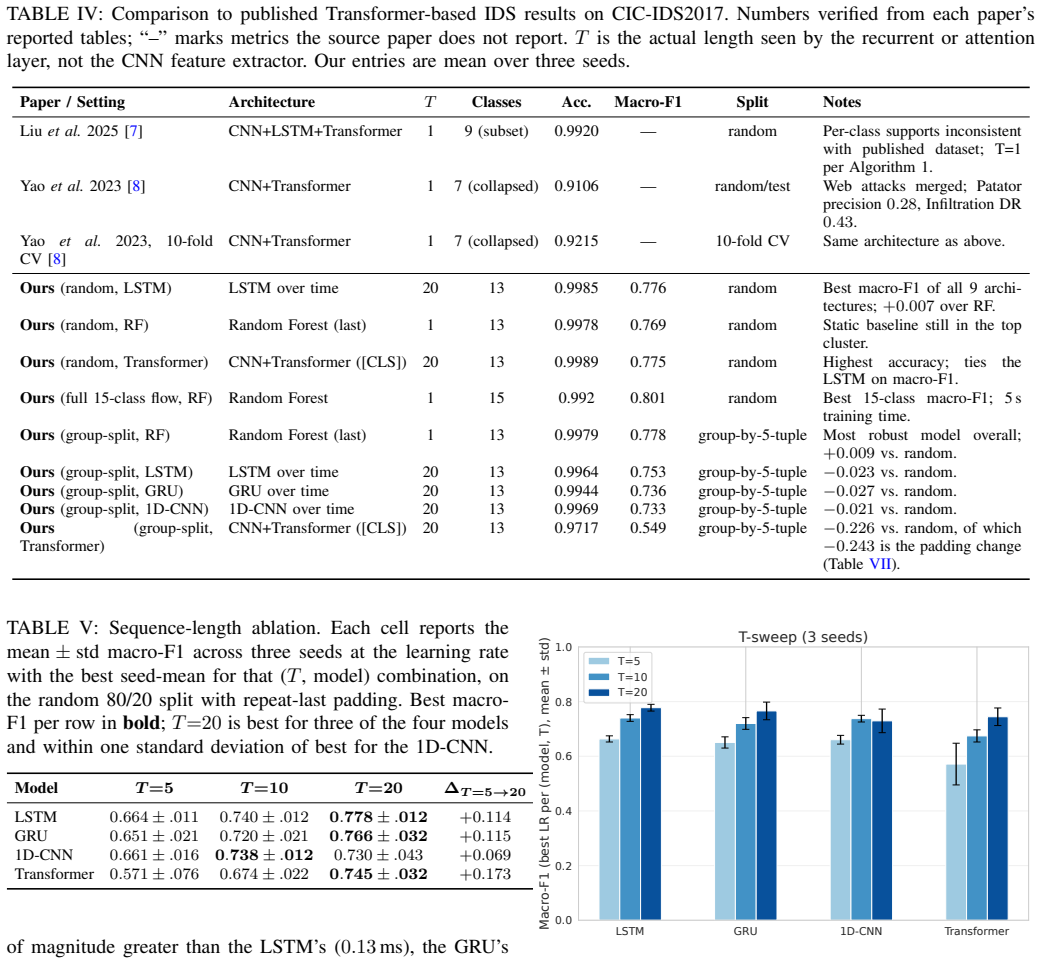
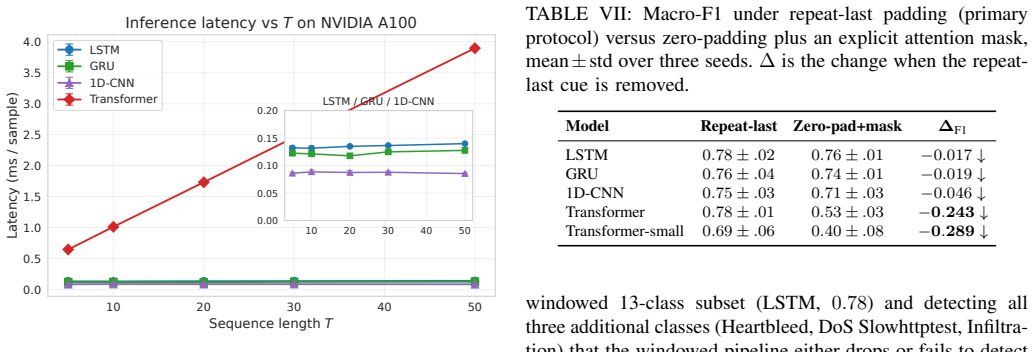
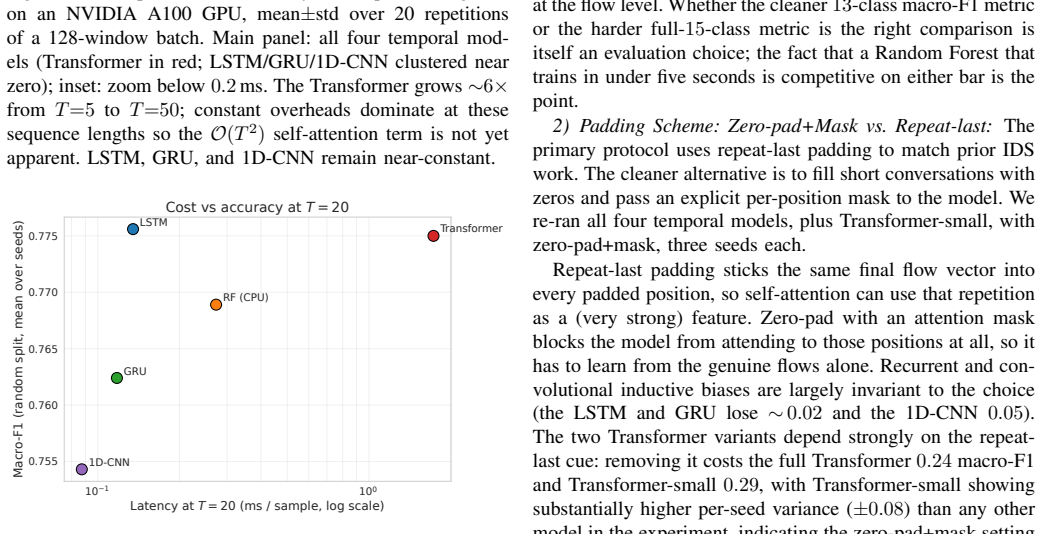
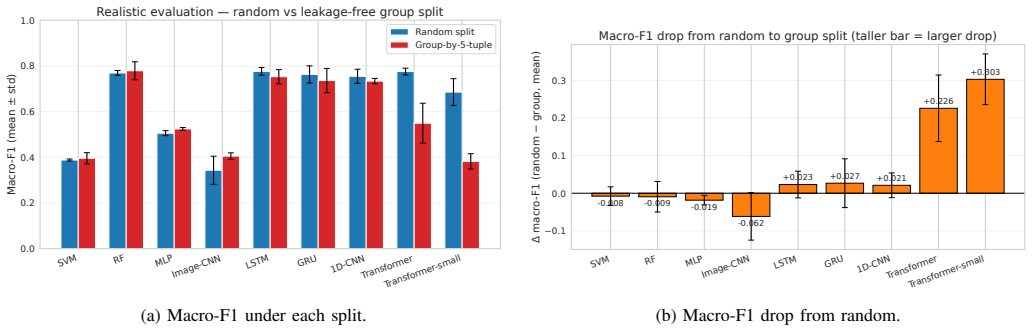
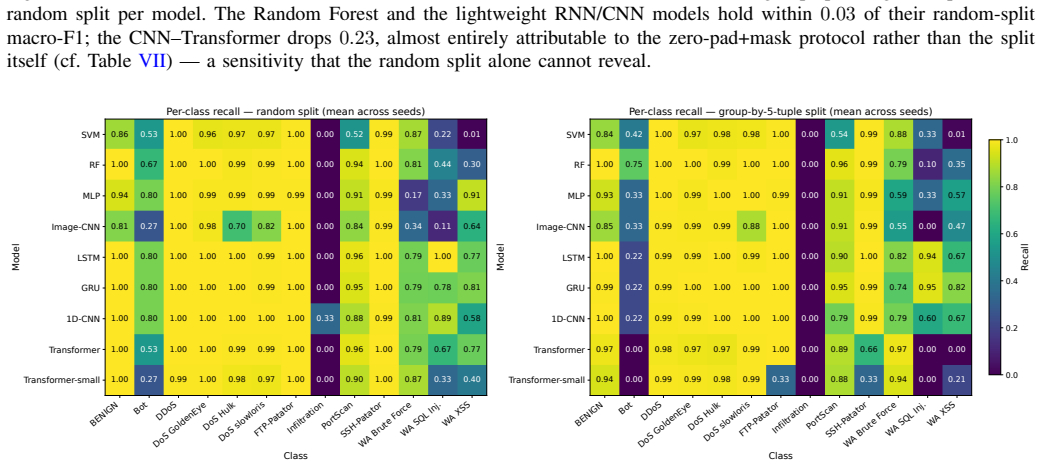
When CIC-IDS2017 is turned into ordered flow sequences, the Transformer records the highest macro-F1 of any tested model on genuinely sequential non-padded windows, yet the same model loses 0.24 macro-F1 under zero-pad-plus-mask evaluation while recurrent and convolutional baselines remain unchanged; under leakage-free group splits the Random Forest proves most stable and the Transformer false-alarm rate increases 67-fold.
What carries the argument
Padding convention (non-padded windows versus zero-pad-plus-mask) together with train-test split protocol (random versus leakage-free group splits) applied to ordered flow sequences.
If this is right
- Transformers need non-padded sequence inputs to realize their reported advantage on this task.
- Zero-padding plus masking produces results that do not reflect the model's behavior on actual sequential inputs.
- Leakage-free group splits expose a large increase in Transformer false alarms that random splits conceal.
- Random Forest remains the most stable model once padding and split artifacts are removed.
- Reported near-perfect scores on CIC-IDS2017 can be inflated by up to 0.24 macro-F1 when padding and split choices favor one architecture.
Where Pith is reading between the lines
- The same padding sensitivity may appear in other security tasks that turn packet streams into fixed-length windows.
- Future benchmarks could test whether the performance gap closes when all models receive identical non-padded variable-length inputs.
- Researchers working with any recurrent or attention model on network data may need to publish padding code alongside accuracy numbers.
Load-bearing premise
That the ordered flow sequences built from CIC-IDS2017 conversations contain genuine temporal structure and no artificial patterns or label leakage.
What would settle it
Re-running the nine-model comparison on the same ordered sequences but with a different padding scheme that keeps the Transformer macro-F1 within 0.05 of its non-padded value while the other models stay unchanged.
Figures



read the original abstract
Recent deep learning approaches for network intrusion detection increasingly incorporate temporal architectures such as recurrent networks and Transformers, often reporting near-perfect performance on CIC-IDS2017. However, many existing studies neither supply their temporal modules with genuine sequence inputs nor evaluate under realistic, leakage-free conditions, making it unclear whether reported gains arise from true sequence-modeling capability. In this work, we reformulate CIC-IDS2017 as a temporal intrusion-detection task by constructing ordered flow sequences from network conversations and benchmarking nine classical and deep learning architectures under a random split, two leakage-free splits, and a padding-scheme ablation. The central finding is that padding convention, not architecture, determines the Transformer's performance: on genuinely sequential (non-padded) windows the Transformer achieves the highest macro-F1 of any model in the experiment (0.89); under zero-pad+mask evaluation it drops markedly (-0.24 macro-F1), while LSTM, GRU, and 1D-CNN remain stable. Under leakage-free group evaluation the Random Forest is the most robust model (+0.009), while the Transformer's false-alarm rate grows from 0.04% to 2.7%, a 67-fold increase invisible under conventional protocols. These findings demonstrate that evaluation methodology -- specifically padding convention and split protocol -- has a larger effect on reported performance than architectural choice, and that widely used random splits with repeat-last padding can overestimate model robustness by up to 0.24 macro-F1. We advocate leakage-free splits, explicit padding disclosure, and sequence-aware benchmarking as standard practice in future IDS research. Code and implementation details are available at https://github.com/zachmocz/temporal-ids-bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reformulates CIC-IDS2017 as a temporal task by constructing ordered flow sequences from network conversations and benchmarks nine models (including Transformer, LSTM, GRU, 1D-CNN, and Random Forest) under random splits, two leakage-free group splits, and a padding-scheme ablation. The central claim is that padding convention—not architecture—drives Transformer performance: non-padded sequential windows yield the highest macro-F1 (0.89) for the Transformer, while zero-pad+mask evaluation causes a -0.24 macro-F1 drop (with LSTM/GRU/1D-CNN remaining stable); under leakage-free splits the Random Forest is most robust (+0.009) while the Transformer’s false-alarm rate rises from 0.04% to 2.7%. The work concludes that evaluation methodology has a larger effect on reported performance than architectural choice and advocates leakage-free splits plus explicit padding disclosure.
Significance. If the empirical results hold, the paper demonstrates that widely used random splits with repeat-last padding can overestimate robustness by up to 0.24 macro-F1 and that many prior Transformer claims in IDS may be artifacts of evaluation choices rather than genuine sequence-modeling gains. The explicit ablations, leakage tests via group splits, and public code release constitute a reproducible benchmark that directly supports falsifiable claims about padding sensitivity and split leakage, strengthening the case for revised standards in temporal IDS evaluation.
minor comments (2)
- The abstract states that sequences are 'constructed from network conversations' but does not specify the exact windowing parameters or flow aggregation rules; a brief methods paragraph or table listing these choices would aid replication even though the GitHub link is provided.
- Figure or table captions could explicitly label the padding condition (non-padded vs. zero-pad+mask) alongside each macro-F1 column to make the ablation comparison immediately visible without cross-referencing text.
Simulated Author's Rebuttal
We thank the referee for their positive review, accurate summary of our contributions, and recommendation to accept the manuscript. We appreciate the recognition that our ablations on padding and leakage-free splits provide a reproducible benchmark for temporal IDS evaluation.
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical benchmarking study that constructs ordered flow sequences from CIC-IDS2017, evaluates nine models under random and leakage-free splits, and performs an explicit padding-scheme ablation. No equations, derivations, or predictions are present that reduce by construction to fitted inputs or self-citations. Central claims rest on reported macro-F1, false-alarm rates, and ablation deltas from direct experiments on a public dataset, with code released. Sequence construction is presented as a standard reformulation rather than a derived result, and leakage testing is performed explicitly via group splits. No steps match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CIC-IDS2017 dataset provides accurate flow labels and timestamps that permit construction of genuine temporal sequences without label leakage
Reference graph
Works this paper leans on
-
[1]
A survey of network-based intrusion detection data sets,
M. Ring, S. Wunderlich, D. Scheuring, D. Landes, and A. Hotho, “A survey of network-based intrusion detection data sets,”Computers & Security, vol. 86, pp. 147–167,
-
[2]
A com- prehensive survey on intrusion detection systems with advances in machine learning, deep learning and emerg- ing cybersecurity challenges,
A. Hozouri, A. Mirzaei, and M. Effatparvar, “A com- prehensive survey on intrusion detection systems with advances in machine learning, deep learning and emerg- ing cybersecurity challenges,”Discover Artificial Intelli- gence, vol. 5, p. 314, 2025. 1, 2
2025
-
[3]
Toward generating a new intrusion detection dataset and intrusion traffic characterization,
I. Sharafaldin, A. H. Lashkari, and A. A. Ghorbani, “Toward generating a new intrusion detection dataset and intrusion traffic characterization,”Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP), pp. 108–116, 2018. 1, 2, 8
2018
-
[4]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in Neural Infor- mation Processing Systems (NeurIPS), vol. 30, 2017. 1, 2, 4
2017
-
[5]
A transformer-based framework for multi- variate time series representation learning,
G. Zerveas, S. Jayaraman, D. Patel, A. Bhamidipaty, and C. Eickhoff, “A transformer-based framework for multi- variate time series representation learning,”Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pp. 2114–2124, 2021. 1, 2
2021
-
[6]
Temporal fusion transformers for interpretable multi-horizon time series forecasting,
B. Lim, S. O. Arik, N. Loeff, and T. Pfister, “Temporal fusion transformers for interpretable multi-horizon time series forecasting,”International Journal of Forecasting, vol. 37, no. 4, pp. 1748–1764, 2021. 1, 2
2021
-
[7]
Deep learning-based intrusion detection: A CNN-LSTM-Transformer approach for en- hanced network security,
D. Liu, X. Zheng, P. Wang, J. Chuan, Y . Lv, B. Zhou, X. Zan, and W. Jiao, “Deep learning-based intrusion detection: A CNN-LSTM-Transformer approach for en- hanced network security,” inProceedings of the 10th International Conference on Cyber Security and Infor- mation Engineering (ICCSIE), 2025, pp. 319–326. 1, 2, 3, 4, 6
2025
-
[8]
A CNN-Transformer hybrid approach for an intrusion detection system in advanced metering infrastructure,
R. Yao, N. Wang, P. Chen, D. Ma, and X. Sheng, “A CNN-Transformer hybrid approach for an intrusion detection system in advanced metering infrastructure,” Multimedia Tools and Applications, vol. 82, no. 13, pp. 19 463–19 486, 2023. 1, 2, 3, 4, 6
2023
-
[9]
Transformers and large language models for efficient intrusion detection systems: A comprehen- sive survey,
H. Kheddar, “Transformers and large language models for efficient intrusion detection systems: A comprehen- sive survey,”Information Fusion, vol. 124, p. 103347,
-
[10]
FlowTrans- former: A transformer framework for flow-based network intrusion detection systems,
L. D. Manocchio, S. Layeghy, W. W. Lo, G. K. Ku- latilleke, M. Sarhan, and M. Portmann, “FlowTrans- former: A transformer framework for flow-based network intrusion detection systems,”Expert Systems with Appli- cations, vol. 241, p. 122564, 2024. 2
2024
-
[11]
RTIDS: A robust transformer-based approach for intrusion detection system,
Z. Wu, H. Zhang, P. Wang, and Z. Sun, “RTIDS: A robust transformer-based approach for intrusion detection system,”IEEE Access, vol. 10, pp. 64 375–64 387, 2022. 1, 2
2022
-
[12]
Troubleshooting an intrusion detection dataset: the CICIDS2017 case study,
G. Engelen, V . Rimmer, and W. Joosen, “Troubleshooting an intrusion detection dataset: the CICIDS2017 case study,”IEEE Security and Privacy Workshops (SPW), pp. 7–12, 2021. 1, 2, 9
2021
-
[13]
Random forests,
L. Breiman, “Random forests,”Machine Learning, vol. 45, no. 1, pp. 5–32, 2001. 2, 3
2001
-
[14]
Support-vector networks,
C. Cortes and V . Vapnik, “Support-vector networks,” Machine Learning, vol. 20, no. 3, pp. 273–297, 1995. 2, 3
1995
-
[15]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735– 1780, 1997. 2, 3
1997
-
[16]
Learning phrase representations using RNN encoder-decoder for statistical machine translation,
K. Cho, B. van Merri ¨enboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using RNN encoder-decoder for statistical machine translation,”Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1724–1734, 2014. 2, 3
2014
-
[17]
A deep learning approach for intrusion detection using recurrent neural networks,
C. Yin, Y . Zhu, J. Fei, and X. He, “A deep learning approach for intrusion detection using recurrent neural networks,”IEEE Access, vol. 5, pp. 21 954–21 961, 2017. 2
2017
-
[18]
Introduction to sequence modeling with transformers,
J.-K. K ¨am¨ar¨ainen, “Introduction to sequence modeling with transformers,”arXiv preprint arXiv:2502.19597,
-
[19]
Goodfellow, Y
I. Goodfellow, Y . Bengio, and A. Courville,Deep Learn- ing. MIT Press, 2016. 3
2016
-
[20]
Batch normalization: Accelerat- ing deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerat- ing deep network training by reducing internal covariate shift,”Proceedings of the 32nd International Conference on Machine Learning (ICML), pp. 448–456, 2015. 3
2015
-
[21]
Dropout: A simple way to prevent neural networks from overfitting,
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,”Journal of Machine Learning Research, vol. 15, no. 56, pp. 1929–1958, 2014. 3
1929
-
[22]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the As- sociation for Computational Linguistics (NAACL-HLT), 2019, pp. 4171–4186. 4
2019
-
[23]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normal- ization,”arXiv preprint arXiv:1607.06450, 2016. 4
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Adam: A method for stochas- tic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochas- tic optimization,”International Conference on Learning Representations (ICLR), 2015. 5
2015
-
[25]
The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets,
T. Saito and M. Rehmsmeier, “The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets,”PLOS ONE, vol. 10, no. 3, p. e0118432, 2015. 4
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.