Lip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Synchronization
Pith reviewed 2026-06-27 13:38 UTC · model grok-4.3
The pith
Lip Forcing distills a 14B bidirectional diffusion teacher into causal students that generate lip-synced video in two denoising steps without CFG.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
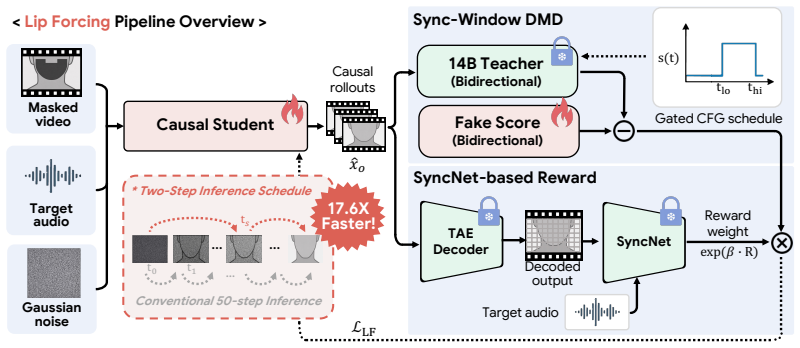
Lip Forcing distills the 14B teacher into 1.3B and 14B causal students using three components derived from lip-sync-specific teacher-trajectory analysis: Sync-Window DMD, a two-step inference schedule, and a SyncNet-based reward. The students generate each chunk in only two denoising steps without inference-time CFG, enabling real-time performance. The 1.3B student reaches 31 FPS (17.6 times faster than its same-scale bidirectional model) and the 14B student runs 39.8 times faster than its teacher at comparable reference fidelity, with sub-millisecond time-to-first-frame at both scales.
What carries the argument
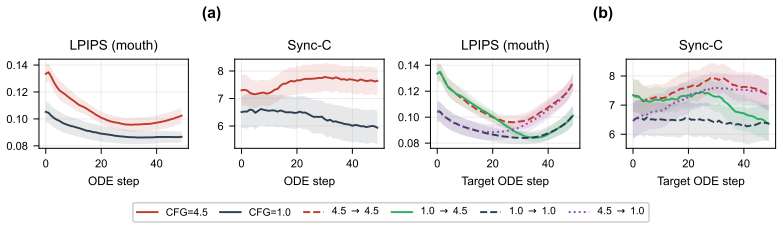
The lip-sync-specific teacher-trajectory analysis that identifies the CFG fidelity-sync tradeoff and produces the three components (Sync-Window DMD, two-step schedule, SyncNet reward) for distilling bidirectional teachers into causal autoregressive students.
If this is right
- The 1.3B student crosses into real-time streaming at 31 FPS.
- The 14B student achieves a 39.8 times speedup over its teacher at comparable reference fidelity.
- Time-to-first-frame falls below one millisecond at both model scales.
- Real-time lip synchronization becomes feasible for streaming applications without inference-time classifier-free guidance.
Where Pith is reading between the lines
- The same distillation pattern could apply to other conditional video-to-video tasks that require causal generation rather than full bidirectional context.
- Longer test sequences might expose limits in maintaining temporal consistency that shorter evaluation clips do not reveal.
- The sub-millisecond latency opens direct use in interactive settings such as live dubbing or avatar systems where bidirectional models cannot run.
Load-bearing premise
The assumption that the lip-sync-specific trajectory analysis and its three derived components transfer quality from the bidirectional teacher to the causal students without significant degradation in long-sequence coherence or audio-visual alignment.
What would settle it
Measuring audio-visual synchronization error and visual coherence metrics on video sequences substantially longer than the training clips to check whether degradation appears relative to the bidirectional teacher.
Figures


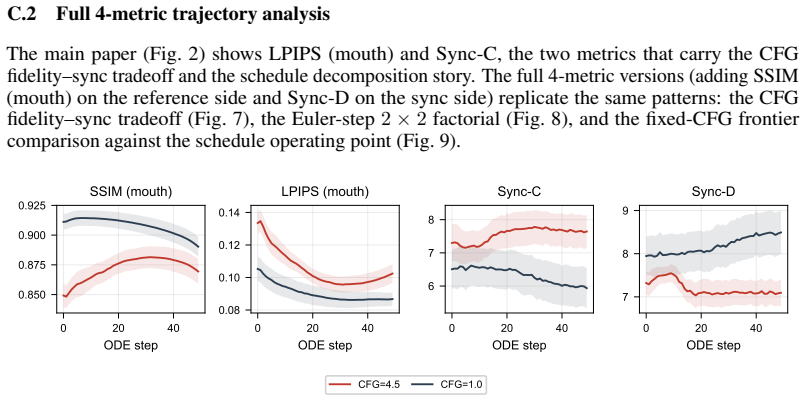
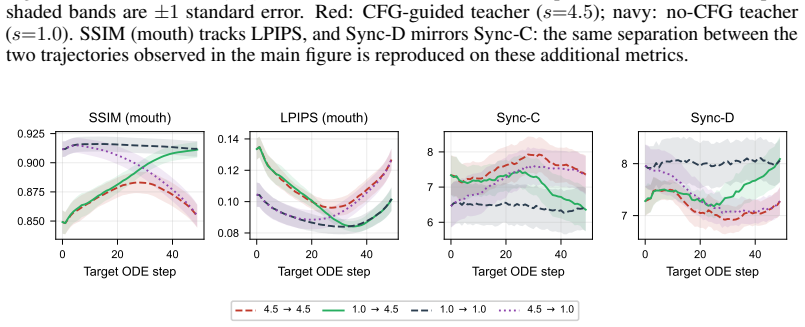
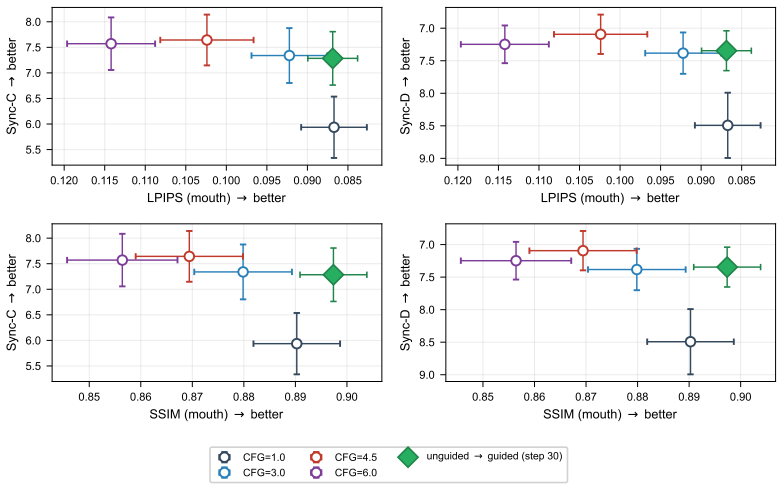
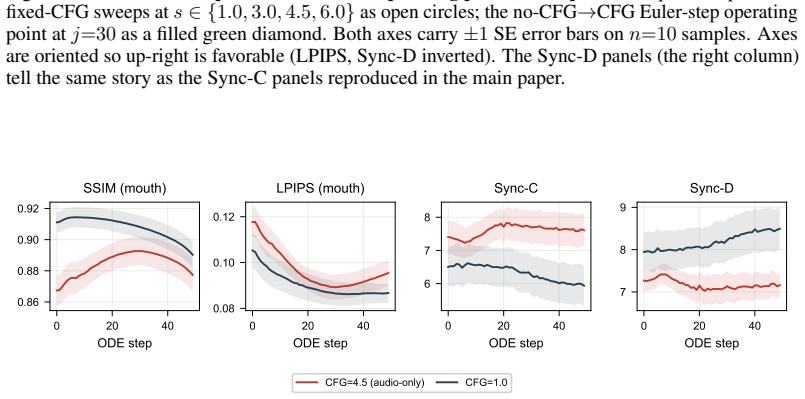
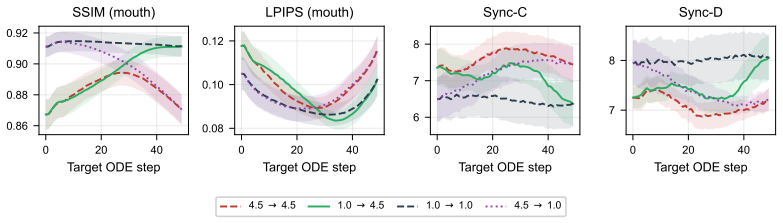
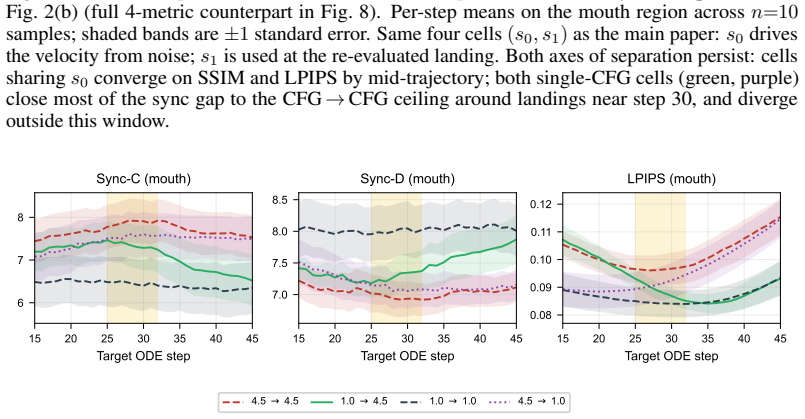
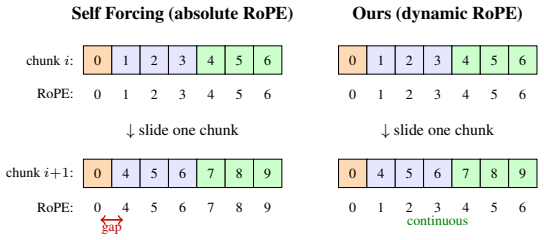
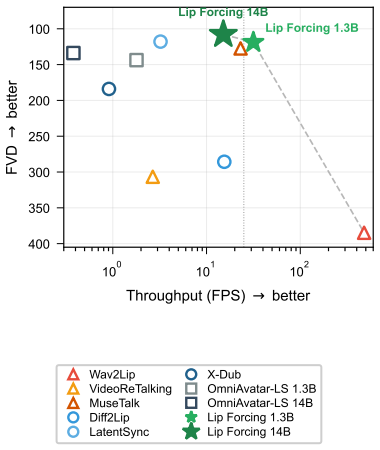




read the original abstract
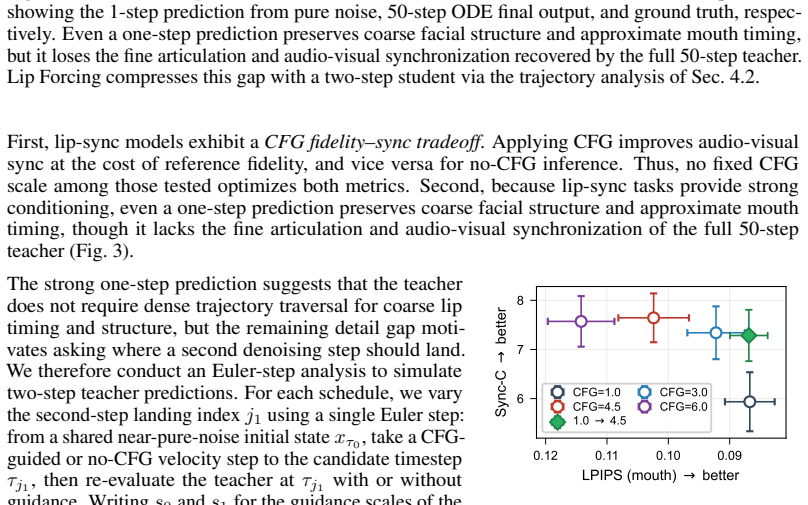
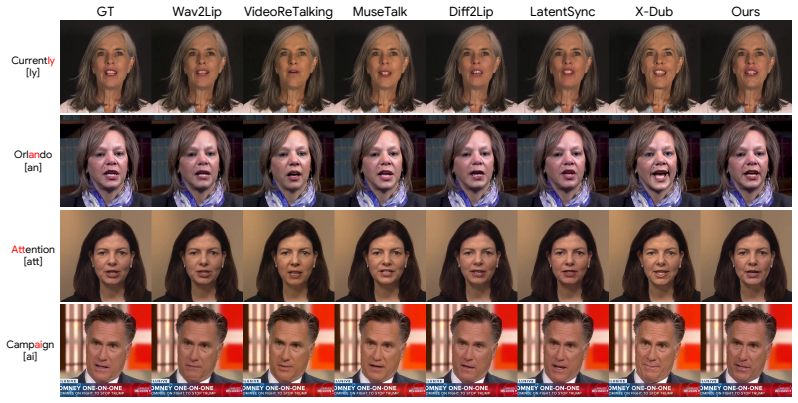
Diffusion-based lip synchronization models achieve strong visual quality and audio-visual alignment, but full-sequence bidirectional attention and many denoising steps make them impractical for real-time inference. We present Lip Forcing, to our knowledge the first autoregressive diffusion method for video-to-video (V2V) lip synchronization, which distills a 14B audio-conditioned bidirectional video diffusion teacher into causal students. At inference, the students generate each chunk in only two denoising steps without inference-time CFG, enabling real-time lip synchronization. A lip-sync-specific teacher-trajectory analysis reveals a CFG fidelity-sync tradeoff: no-CFG predictions favor reference fidelity, whereas CFG-guided predictions favor synchronization within a mid-trajectory band. Lip Forcing translates this finding into three analysis-derived components: Sync-Window DMD, a two-step inference schedule, and a SyncNet-based reward. We validate Lip Forcing at two student scales, both distilled from the 14B teacher. The 1.3B student crosses into real-time streaming at 31 FPS, $17.6\times$ faster than its same-scale bidirectional model. The 14B student, the largest diffusion model reported for V2V lip synchronization, runs $39.8\times$ faster than its teacher at comparable reference fidelity. Time-to-first-frame is sub-millisecond at both scales, far below every diffusion baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Lip Forcing, the first autoregressive diffusion method for video-to-video lip synchronization. It distills a 14B bidirectional audio-conditioned video diffusion teacher into causal student models (1.3B and 14B scales) that generate each chunk in only two denoising steps without inference-time CFG. The method is derived from a lip-sync-specific teacher-trajectory analysis identifying a CFG fidelity-sync tradeoff, yielding three components (Sync-Window DMD, two-step inference schedule, SyncNet-based reward). Reported results include the 1.3B student reaching 31 FPS (17.6× faster than same-scale bidirectional) and the 14B student running 39.8× faster than its teacher at comparable reference fidelity, with sub-millisecond time-to-first-frame.
Significance. If the quality transfer holds, the work would enable practical real-time diffusion-based V2V lip synchronization by overcoming bidirectional attention and multi-step denoising costs. The trajectory analysis and distillation components offer a targeted approach to balancing fidelity and synchronization in few-step causal generation, with potential impact on streaming video applications.
major comments (2)
- [Abstract] Abstract: The headline performance claims (31 FPS, 17.6× and 39.8× speedups at comparable reference fidelity) rest on unspecified validation; no details are provided on the metrics or procedures used to measure reference fidelity and synchronization, baseline comparisons, error bars, dataset splits, or long-sequence evaluation.
- [Abstract] Abstract: The central assumption that the CFG fidelity-sync tradeoff analysis and its three derived components (Sync-Window DMD, two-step schedule, SyncNet reward) successfully transfer bidirectional teacher quality to causal students without degradation in long-sequence coherence or audio-visual alignment is load-bearing for the speedups, yet no quantitative long-horizon metrics or ablations on coherence drift over sequences longer than training chunks are reported.
minor comments (1)
- [Abstract] Abstract: The claim of being 'to our knowledge the first autoregressive diffusion method for V2V lip synchronization' would benefit from explicit citations to related autoregressive or few-step diffusion works for context.
Simulated Author's Rebuttal
We thank the referee for the review and the identification of areas where the abstract could better contextualize our claims. We respond to each major comment below with references to the manuscript content and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claims (31 FPS, 17.6× and 39.8× speedups at comparable reference fidelity) rest on unspecified validation; no details are provided on the metrics or procedures used to measure reference fidelity and synchronization, baseline comparisons, error bars, dataset splits, or long-sequence evaluation.
Authors: The abstract is a high-level summary; full specification of metrics (SyncNet confidence for synchronization, FID/LPIPS for reference fidelity), evaluation procedures, baseline models, dataset splits, and error bars from repeated runs appear in Sections 4.1–4.2 and the supplementary material. We will revise the abstract to include a short clause directing readers to these sections for the validation protocol. revision: yes
-
Referee: [Abstract] Abstract: The central assumption that the CFG fidelity-sync tradeoff analysis and its three derived components (Sync-Window DMD, two-step schedule, SyncNet reward) successfully transfer bidirectional teacher quality to causal students without degradation in long-sequence coherence or audio-visual alignment is load-bearing for the speedups, yet no quantitative long-horizon metrics or ablations on coherence drift over sequences longer than training chunks are reported.
Authors: Section 3.1 presents the teacher-trajectory analysis that motivates the three components, and Section 4 reports that the distilled students achieve comparable reference fidelity to the teacher at the evaluated chunk lengths. We agree that explicit quantitative ablations measuring coherence drift on sequences substantially longer than the training chunks are not included in the manuscript. revision: partial
- No quantitative long-horizon metrics or ablations on coherence drift over sequences longer than training chunks are available in the current work.
Circularity Check
Derivation chain is self-contained; no load-bearing step reduces to input by construction
full rationale
The paper's central chain—teacher-trajectory analysis of CFG fidelity-sync tradeoff yielding Sync-Window DMD, two-step schedule, and SyncNet reward, followed by distillation into causal students—relies on an external 14B bidirectional teacher and empirical analysis rather than self-definition or fitted-parameter renaming. No equation or component is shown to equal its input by construction, and SyncNet appears as an external reward model. Claims of speed and fidelity are presented as experimental outcomes, not definitional. This is the common non-circular case for distillation papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A 14B audio-conditioned bidirectional video diffusion model exists and produces high-quality lip synchronization outputs suitable for distillation.
- domain assumption The CFG fidelity-sync tradeoff observed in the teacher trajectory generalizes to the student models and can be exploited via Sync-Window DMD and SyncNet reward.
Reference graph
Works this paper leans on
-
[1]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations, 2020. URL https://arxiv.org/abs/2006.11477
-
[2]
Taehv: Tiny autoencoder for hunyuan video
Ollin Boer Bohan. Taehv: Tiny autoencoder for hunyuan video. https://github.com/madebyollin/ taehv, 2025
2025
-
[3]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
2024
-
[4]
Talkvid: A large-scale diversified dataset for audio-driven talking head synthesis, 2025
Shunian Chen, Hejin Huang, Yexin Liu, Zihan Ye, Pengcheng Chen, Chenghao Zhu, Michael Guan, Rongsheng Wang, Junying Chen, Guanbin Li, Ser-Nam Lim, Harry Yang, and Benyou Wang. Talkvid: A large-scale diversified dataset for audio-driven talking head synthesis, 2025. URL https://arxiv.org/ abs/2508.13618
-
[5]
VideoReTalking: Audio-based lip synchronization for talking head video editing in the wild, 2022
Kun Cheng, Xiaodong Cun, Yong Zhang, Menghan Xia, Fei Yin, Mingrui Zhu, Xuan Wang, Jue Wang, and Nannan Wang. VideoReTalking: Audio-based lip synchronization for talking head video editing in the wild, 2022. URLhttps://arxiv.org/abs/2211.14758
-
[6]
Out of time: automated lip sync in the wild
Joon Son Chung and Andrew Zisserman. Out of time: automated lip sync in the wild. InAsian conference on computer vision, pages 251–263. Springer, 2016
2016
-
[7]
V oxceleb2: Deep speaker recognition
Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. V oxceleb2: Deep speaker recognition. In Interspeech 2018, page 1086–1090. ISCA, September 2018. doi: 10.21437/interspeech.2018-1929. URL http://dx.doi.org/10.21437/Interspeech.2018-1929
-
[8]
Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer, 2025
Jiahao Cui, Hui Li, Yun Zhan, Hanlin Shang, Kaihui Cheng, Yuqi Ma, Shan Mu, Hang Zhou, Jingdong Wang, and Siyu Zhu. Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer, 2025. URLhttps://arxiv.org/abs/2412.00733
-
[9]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690–4699, 2019
2019
-
[10]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024. URLhttps://arxiv.org/abs/2403.03206
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Qijun Gan, Ruizi Yang, Jianke Zhu, Shaofei Xue, and Steven Hoi. Omniavatar: Efficient audio-driven avatar video generation with adaptive body animation.arXiv preprint arXiv:2506.18866, 2025. 10
-
[12]
Generative Adversarial Networks
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks, 2014. URL https://arxiv.org/abs/ 1406.2661
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[13]
Accelerate: Training and inference at scale made simple, efficient and adaptable.https://github.com/huggingface/accelerate, 2022
Sylvain Gugger, Lysandre Debut, Thomas Wolf, Philipp Schmid, Zachary Mueller, Sourab Mangrulkar, Marc Sun, and Benjamin Bossan. Accelerate: Training and inference at scale made simple, efficient and adaptable.https://github.com/huggingface/accelerate, 2022
2022
-
[14]
Xu He, Haoxian Zhang, Hejia Chen, Changyuan Zheng, Liyang Chen, Songlin Tang, Jiehui Huang, Xiaoqiang Liu, Pengfei Wan, and Zhiyong Wu. From inpainting to editing: A self-bootstrapping framework for context-rich visual dubbing.arXiv preprint arXiv:2512.25066, 2025
-
[15]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium, 2018. URL https: //arxiv.org/abs/1706.08500
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[17]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[18]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self Forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Live Avatar: Streaming Real-time Audio-Driven Avatar Generation with Infinite Length
Yubo Huang, Hailong Guo, Fangtai Wu, Shifeng Zhang, Shijie Huang, Qijun Gan, Lin Liu, Sirui Zhao, Enhong Chen, Jiaming Liu, and Steven Hoi. Live avatar: Streaming real-time audio-driven avatar generation with infinite length, 2025. URLhttps://arxiv.org/abs/2512.04677
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
MATRIX: Mask Track Alignment for Interaction-aware Video Generation
Siyoon Jin, Seongchan Kim, Dahyun Chung, Jaeho Lee, Hyunwook Choi, Jisu Nam, Jiyoung Kim, and Seungryong Kim. Matrix: Mask track alignment for interaction-aware video generation, 2025. URL https://arxiv.org/abs/2510.07310
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Moditalker: Motion-disentangled diffusion model for high-fidelity talking head generation, 2024
Seyeon Kim, Siyoon Jin, Jihye Park, Kihong Kim, Jiyoung Kim, Jisu Nam, and Seungryong Kim. Moditalker: Motion-disentangled diffusion model for high-fidelity talking head generation, 2024. URL https://arxiv.org/abs/2403.19144
-
[22]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
V-warper: Appearance-consistent video diffusion personalization via value warping, 2025
Hyunkoo Lee, Wooseok Jang, Jini Yang, Taehwan Kim, Sangoh Kim, Sangwon Jung, and Seungryong Kim. V-warper: Appearance-consistent video diffusion personalization via value warping, 2025. URL https://arxiv.org/abs/2512.12375
-
[24]
3d scene prompting for scene-consistent camera-controllable video generation, 2025
JoungBin Lee, Jaewoo Jung, Jisang Han, Takuya Narihira, Kazumi Fukuda, Junyoung Seo, Sunghwan Hong, Yuki Mitsufuji, and Seungryong Kim. 3d scene prompting for scene-consistent camera-controllable video generation, 2025. URLhttps://arxiv.org/abs/2510.14945
-
[25]
Chunyu Li, Chao Zhang, Weikai Xu, Jingyu Lin, Jinghui Xie, Weiguo Feng, Bingyue Peng, Cunjian Chen, and Weiwei Xing. LatentSync: Taming audio-conditioned latent diffusion models for lip sync with SyncNet supervision.arXiv preprint arXiv:2412.09262, 2024
-
[26]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time, 2025. URLhttps://arxiv.org/abs/2509.25161
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Yunhong Lu, Yanhong Zeng, Haobo Li, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Jiapeng Zhu, Hengyuan Cao, Zhipeng Zhang, Xing Zhu, et al. Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation.arXiv preprint arXiv:2512.04678, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
SayAnything: Audio-driven lip synchronization with conditional video diffusion, 2025
Junxian Ma, Shiwen Wang, Jian Yang, Junyi Hu, Jian Liang, Guosheng Lin, Jingbo Chen, Kai Li, and Yu Meng. SayAnything: Audio-driven lip synchronization with conditional video diffusion, 2025. URL https://arxiv.org/abs/2502.11515. 11
-
[31]
Diff2lip: Audio conditioned diffusion models for lip-synchronization, 2023
Soumik Mukhopadhyay, Saksham Suri, Ravi Teja Gadde, and Abhinav Shrivastava. Diff2lip: Audio conditioned diffusion models for lip-synchronization, 2023. URL https://arxiv.org/abs/2308. 09716
2023
-
[32]
Omnisync: Towards universal lip synchronization via diffusion transformers, 2025
Ziqiao Peng, Jiwen Liu, Haoxian Zhang, Xiaoqiang Liu, Songlin Tang, Pengfei Wan, Di Zhang, Hongyan Liu, and Jun He. Omnisync: Towards universal lip synchronization via diffusion transformers, 2025. URL https://arxiv.org/abs/2505.21448
-
[33]
In: Proceedings of the 28th ACM International Conference on Multimedia
K R Prajwal, Rudrabha Mukhopadhyay, Vinay P. Namboodiri, and C.V . Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. InProceedings of the 28th ACM International Conference on Multimedia, MM ’20, page 484–492. ACM, October 2020. doi: 10.1145/3394171.3413532. URL http://dx.doi.org/10.1145/3394171.3413532
-
[34]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[35]
Sand.ai, Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, W. Q. Zhang, Weifeng Luo, Xiaoyang Kang, Yuchen Sun, Yue Cao, Yunpeng Huang, Yutong Lin, Yuxin Fang, Zewei Tao, Zheng Zhang, Zhongshu Wang, Zixun Liu, Dai Shi, Guoli Su, Hanwen Sun, Hong Pan, Jie Wang, Jiexin Sheng, Min Cui, Min Hu, Ming Yan, Shucheng...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Joonghyuk Shin, Zhengqi Li, Richard Zhang, Jun-Yan Zhu, Jaesik Park, Eli Shechtman, and Xun Huang. Motionstream: Real-time video generation with interactive motion controls, 2025. URL https://arxiv. org/abs/2511.01266
-
[37]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022. URL https://arxiv.org/abs/2010.02502
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Blindly assess image quality in the wild guided by a self-adaptive hyper network
Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun, and Yanning Zhang. Blindly assess image quality in the wild guided by a self-adaptive hyper network. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3667–3676, 2020
2020
-
[39]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges, 2019. URL https://arxiv.org/abs/1812.01717
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[40]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Jiadong Wang, Xinyuan Qian, Malu Zhang, Robby T. Tan, and Haizhou Li. Seeing what you said: Talking face generation guided by a lip reading expert, 2023. URLhttps://arxiv.org/abs/2303.17480
-
[42]
Fantasytalking: Realistic talking portrait generation via coherent motion synthesis, 2025
Mengchao Wang, Qiang Wang, Fan Jiang, Yaqi Fan, Yunpeng Zhang, Yonggang Qi, Kun Zhao, and Mu Xu. Fantasytalking: Realistic talking portrait generation via coherent motion synthesis, 2025. URL https://arxiv.org/abs/2504.04842
-
[43]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[44]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, Song Han, and Yukang Chen. LongLive: Real-time interactive long video generation, 2025. URLhttps://arxiv.org/abs/2509.22622
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. CogVideoX: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forc- ing: Training-free long video generation with deep sink and participative compression.arXiv preprint arXiv:2512.05081, 2025
-
[47]
Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
2024
-
[48]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[49]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22963–22974, 2025
2025
-
[50]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[51]
MuseTalk: Real-time high-fidelity video dubbing via spatio-temporal sampling, 2025
Yue Zhang, Zhizhou Zhong, Minhao Liu, Zhaokang Chen, Bin Wu, Yubin Zeng, Chao Zhan, Yingjie He, Junxin Huang, and Wenjiang Zhou. MuseTalk: Real-time high-fidelity video dubbing via spatio-temporal sampling, 2025. URLhttps://arxiv.org/abs/2410.10122
-
[52]
Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset
Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3661–3670, 2021. 13 Appendix A Index of supplementary material This appendix is organized into seven sections. Section B ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.