When to Align, When to Predict: A Phase Diagram for Multimodal Learning
Pith reviewed 2026-06-27 14:07 UTC · model grok-4.3
The pith
A linear spiked model yields a phase diagram that partitions multimodal problems into four regimes for alignment versus prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
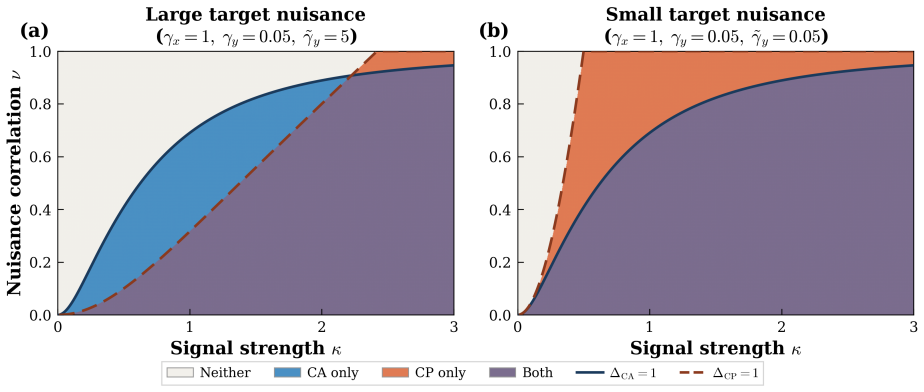
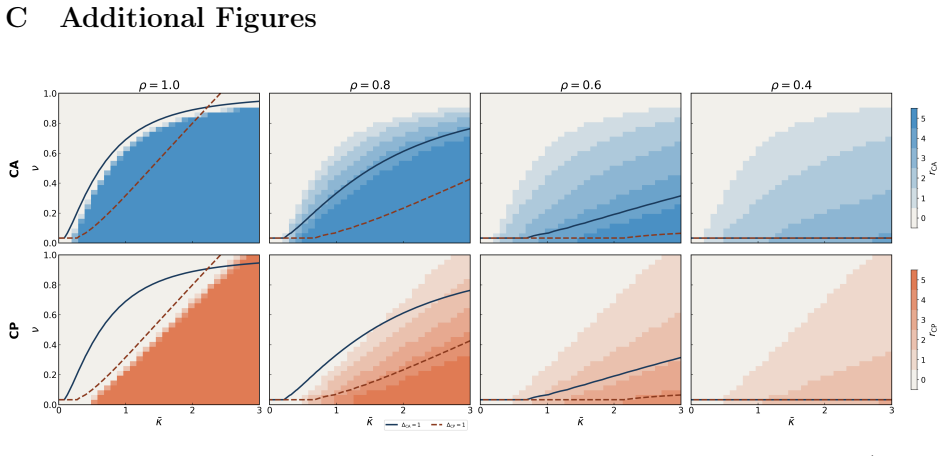
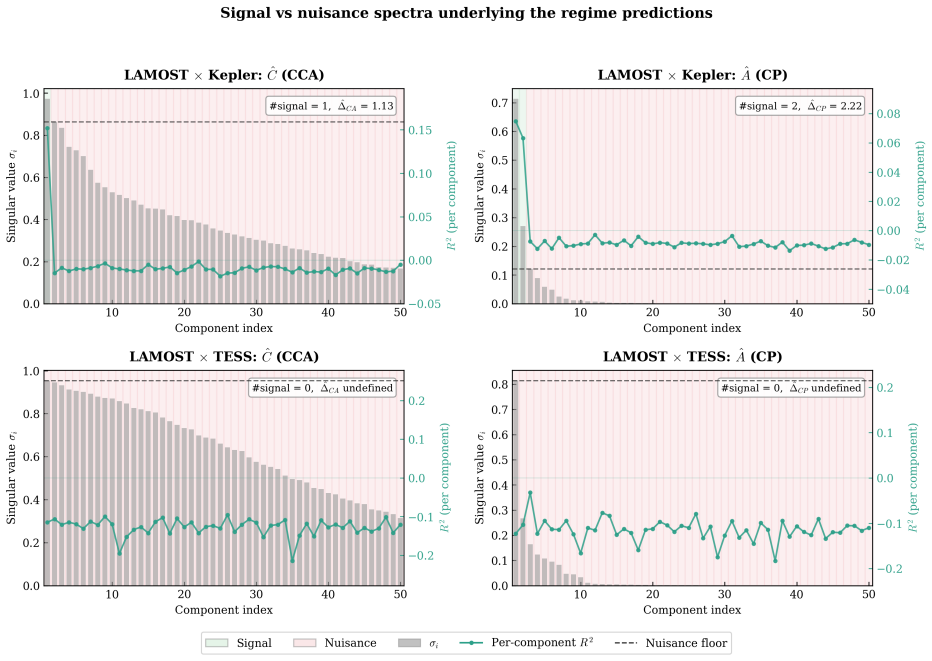
Under a spiked signal-plus-noise model with structured cross-modal nuisance correlation, alignment whitens each modality and fails when nuisance is strongly correlated across views; prediction encodes whatever is cross-predictable through a one-sided whitening, with recovery governed by source-modality quality. The resulting phase diagram partitions multimodal problems into four regimes: Both, CA only, CP only, and Neither. A data-driven procedure locates real-world datasets in this diagram using a small labeled subsample, identifying the preferred objective and prediction direction before any cross-modal training.
What carries the argument
Spiked signal-plus-noise model with structured cross-modal nuisance correlation, used to derive separation ratios for alignment and prediction objectives.
If this is right
- Alignment succeeds only when nuisance correlations across modalities are weak.
- Prediction succeeds when the source modality carries higher-quality signal than the target.
- In the Neither regime, cross-modal training is actively harmful relative to the best single-modality baseline.
- A small labeled subsample suffices to compute separation ratios and select the objective and direction without full training.
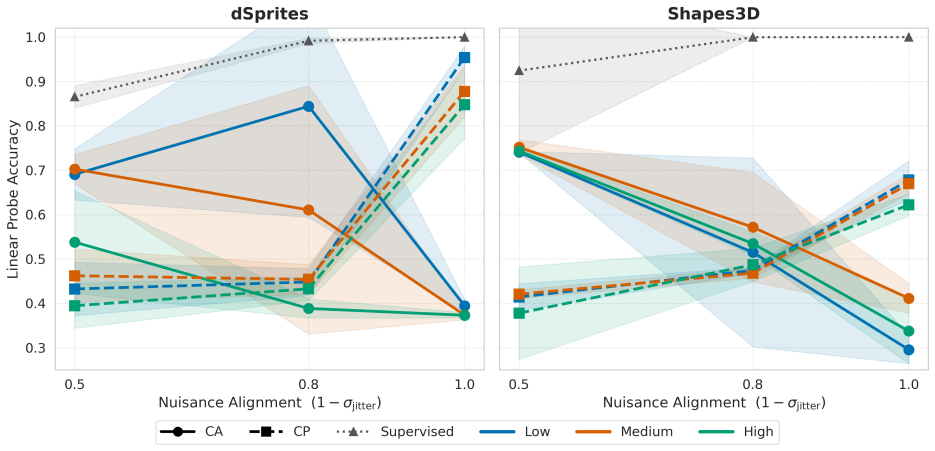
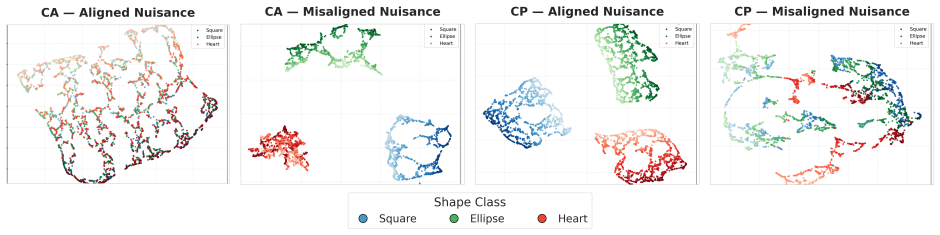
- The four regimes remain predictive after nonlinear training on synthetic, vision, caption, and astrophysical data.
Where Pith is reading between the lines
- The same separation-ratio test could be applied to decide between other objectives such as contrastive versus generative losses.
- Datasets in scientific domains with multiple measurement modalities can be pre-screened to avoid the Neither regime.
- If nuisance structure changes over time, the phase location of a problem may shift and require periodic re-testing.
- The linear derivation suggests a possible route to analytic bounds for kernel or neural versions of the same objectives.
Load-bearing premise
The data-generating process is exactly a linear spiked signal-plus-noise model whose nuisance correlations are structured across modalities.
What would settle it
Measure the empirical performance gap between CA and CP on a dataset whose nuisance correlation structure deviates from the linear spiked model; if the observed best method contradicts the regime predicted by the separation ratios, the phase boundaries lose their guarantees.
Figures

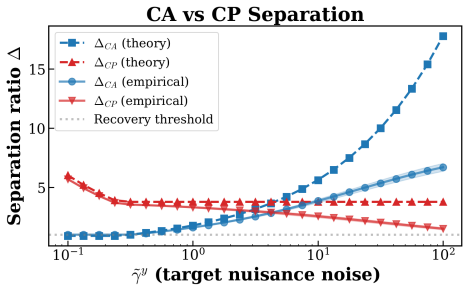
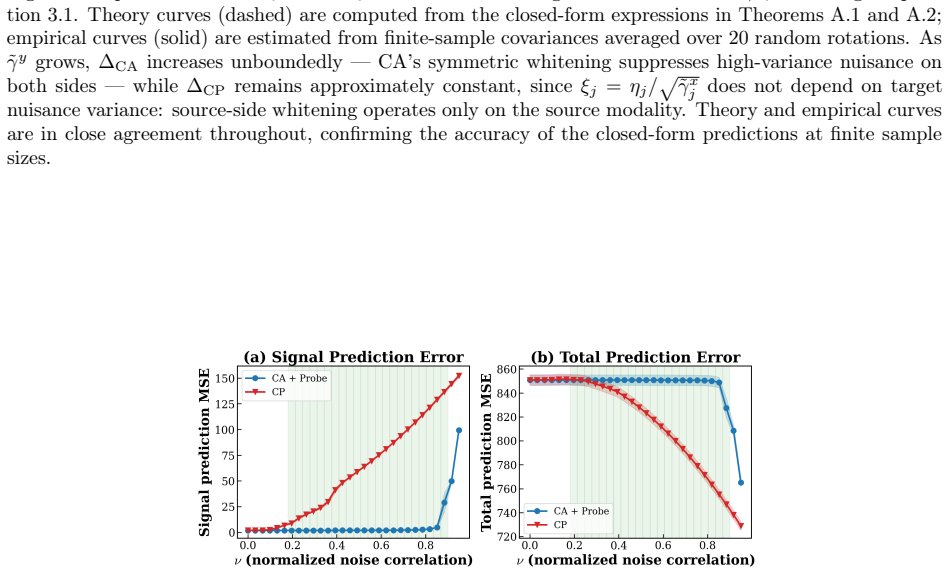
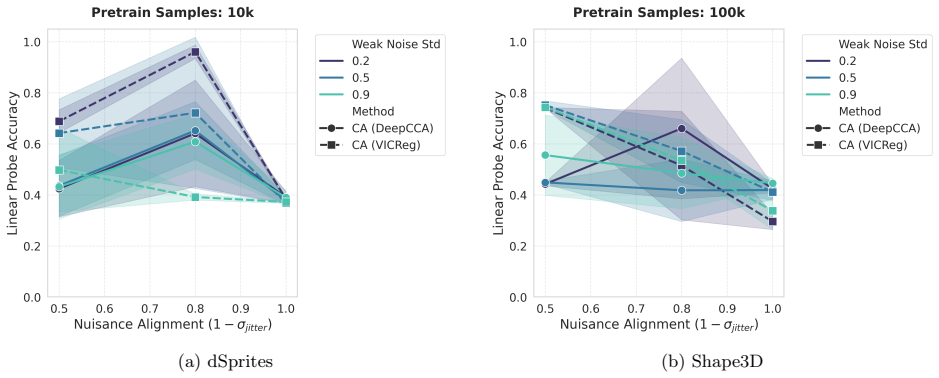
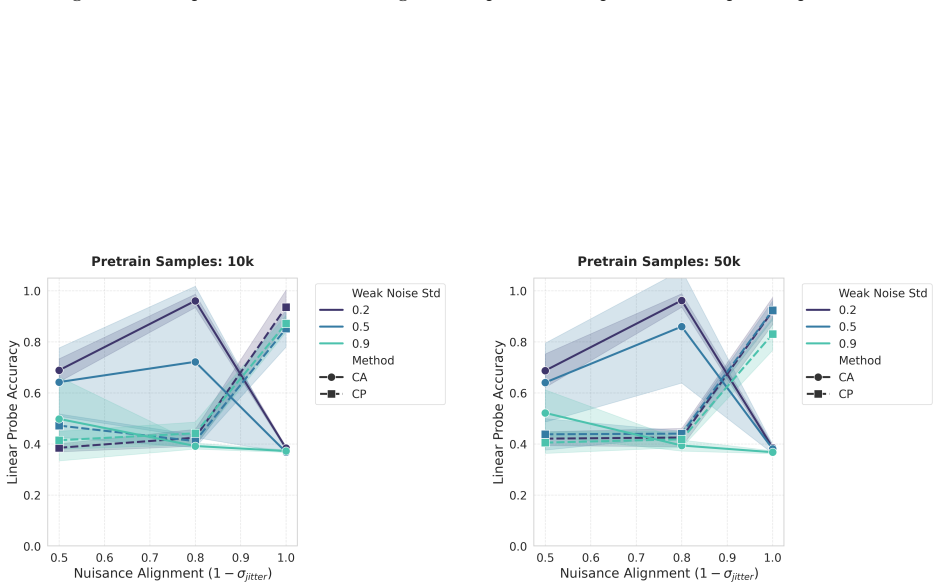
read the original abstract
Cross-modal alignment (CA) and cross-modal prediction (CP) are the dominant paradigms for multimodal representation learning, yet there is no systematic understanding of when each succeeds, when each fails, and when cross-modal training helps at all -- a gap that leaves practitioners, especially in scientific domains like biomedicine or astrophysics, with heterogeneous instruments and multiple levels of organization and measurement, unable to diagnose why standard methods underperform the best single modality. We develop a unified linear framework that addresses both questions. Under a spiked signal-plus-noise model with structured cross-modal nuisance correlation, we derive separation ratios for both objectives that expose complementary failure modes: alignment whitens each modality and fails when nuisance is strongly correlated across views; prediction encodes whatever is cross-predictable through a one-sided whitening, with recovery governed by source-modality quality. The resulting phase diagram partitions multimodal problems into four regimes: Both, CA only, CP only, and Neither. We present a data-driven procedure to locate real-world datasets in this diagram using a small labeled subsample, identifying the preferred objective and prediction direction before any cross-modal training. Experiments on synthetic data, stereo-vision benchmarks, image-caption pairs, and real astrophysical data validate the predictions in the nonlinear regime, including the Neither regime where cross-modal training is actively harmful. Our framework lets practitioners diagnose their multimodal problem and choose the right objective before committing to training. Code to reproduce the results is available at https://github.com/IlayMalinyak/mm_align_vs_pred.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a unified linear framework under a spiked signal-plus-noise model with structured cross-modal nuisance correlation. It derives separation ratios for cross-modal alignment (CA) and cross-modal prediction (CP) that expose complementary failure modes, yielding a phase diagram that partitions multimodal problems into four regimes (Both, CA only, CP only, Neither). A data-driven procedure is given to locate real datasets in the diagram using a small labeled subsample, and the predictions are validated on synthetic data, stereo-vision benchmarks, image-caption pairs, and astrophysical data (including the Neither regime).
Significance. If the central derivation holds, the work supplies a principled, pre-training diagnostic for choosing between alignment and prediction objectives in multimodal learning, addressing a practical gap for heterogeneous scientific data. Credit is due for the parameter-free derivation of the separation ratios directly from the model equations, the explicit four-regime partition as an output rather than an input, and the public release of reproducible code.
minor comments (1)
- [Abstract] Abstract: the claim of validation 'in the nonlinear regime' would be strengthened by a brief statement of how the synthetic nonlinear experiments were constructed and whether the phase boundaries remain qualitatively intact.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, accurate summary of its contributions, and recommendation to accept. We appreciate the recognition of the parameter-free derivation, the explicit four-regime partition, and the data-driven procedure for locating datasets in the phase diagram.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper derives separation ratios for alignment and prediction objectives, along with the resulting four-regime phase diagram, directly from the explicit assumptions of a linear spiked signal-plus-noise model with structured cross-modal nuisance correlations. These quantities are outputs of algebraic manipulation of the model equations rather than inputs, fitted parameters, or self-citation chains. No step reduces by construction to a renamed fit or an unverified self-citation; external validation on synthetic data and real benchmarks (including the Neither regime) is reported separately from the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data follows a linear spiked signal-plus-noise model with structured cross-modal nuisance correlation
Reference graph
Works this paper leans on
-
[1]
Flamingo: a Visual Language Model for Few-Shot Learning.arXiv e-prints, art
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski,...
-
[2]
Flamingo: a Visual Language Model for Few-Shot Learning
doi: 10.48550/arXiv.2204.14198. Galen Andrew, Raman Arora, Jeff Bilmes, and Karen Livescu. Deep canonical correlation analysis. In Proceedings of the 30th International Conference on International Conference on Machine Learning - Volume 28, ICML’13, page III–1247–III–1255. JMLR.org,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.14198
-
[3]
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael G
URLhttps://api.semanticscholar.org/CorpusID:67855945. Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael G. Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15619–15629,
2023
-
[4]
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli
URLhttps://api.semanticscholar.org/CorpusID:255999752. Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language.arXiv e-prints, art. arXiv:2202.03555, February
-
[5]
10 Randall Balestriero and Yann LeCun
doi: 10.48550/arXiv.2202.03555. 10 Randall Balestriero and Yann LeCun. Contrastive and non-contrastive self-supervised learning recover global and local spectral embedding methods.ArXiv, abs/2205.11508,
-
[6]
semanticscholar.org/CorpusID:248986152
URLhttps://api. semanticscholar.org/CorpusID:248986152. Randall Balestriero and Yann LeCun. LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics.arXiv e-prints, art. arXiv:2511.08544, November
-
[7]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
doi: 10.48550/arXiv.2511.08544. Adrien Bardes, Jean Ponce, and Yann LeCun. VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning.arXiv e-prints, art. arXiv:2105.04906, May
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.08544
-
[8]
doi: 10.48550/arXiv.2105. 04906. Cristian Bodnar, Wessel P. Bruinsma, Ana Lucic, Megan Stanley, Anna Vaughan, Johannes Brandstetter, Patrick Garvan, Maik Riechert, Jonathan A. Weyn, Haiyu Dong, Jayesh K. Gupta, Kit Thambiratnam, Alexander T. Archibald, Chun-Chieh Wu, Elizabeth Heider, Max Welling, Richard E. Turner, and Paris Perdikaris. A Foundation Mode...
-
[9]
doi: 10.48550/arXiv.2405.13063. Chris Burgess and Hyunjik Kim. 3d shapes dataset. https://github.com/deepmind/3d-shapes,
-
[10]
Unconstrained Stochastic CCA: Unifying Multiview and Self-Supervised Learning.arXiv e-prints, art
James Chapman, Lennie Wells, and Ana Lawry Aguila. Unconstrained Stochastic CCA: Unifying Multiview and Self-Supervised Learning.arXiv e-prints, art. arXiv:2310.01012, October
-
[12]
doi: 10.48550/arXiv.2011.10566. Haotian Cui, Alejandro Tejada-Lapuerta, Maria Brbić, Julio Saez-Rodriguez, Simona Cristea, Hani Goodarzi, Mohammad Lotfollahi, Fabian J. Theis, and Bo Wang. Towards multimodal foundation models in molecular cell biology.Nature, 640(8059):623–633, April
-
[13]
Claire Donnat and Elena Tuzhilina
doi: 10.1038/s41586-025-08710-y. Claire Donnat and Elena Tuzhilina. Canonical Correlation Analysis as Reduced Rank Regression in High Dimensions.arXiv e-prints, art. arXiv:2405.19539, May
-
[14]
doi: 10.48550/arXiv.2405.19539. Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank.Psychometrika, 1(3):211–218, September
-
[15]
ISSN 1860-0980. doi: 10.1007/BF02288367. URLhttps://doi.org/10. 1007/BF02288367. Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. ImageBind: One Embedding Space To Bind Them All.arXiv e-prints, art. arXiv:2305.05665, May
-
[16]
doi: 10.48550/arXiv.2305.05665. Jeff Z. HaoChen, Colin Wei, Adrien Gaidon, and Tengyu Ma. Provable guarantees for self-supervised deep learning with spectral contrastive loss. InAdvances in Neural Information Processing Systems, volume 34,
-
[17]
Masked Autoencoders Are Scalable Vision Learners.arXiv e-prints, art
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked Autoencoders Are Scalable Vision Learners.arXiv e-prints, art. arXiv:2111.06377, November
-
[18]
Masked Autoencoders Are Scalable Vision Learners
doi: 10.48550/arXiv. 2111.06377. Harold Hotelling. Relations between two sets of variates.Biometrika, 28(3/4):321–377,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[20]
URL https://arxiv.org/abs/2106.04538v2. 11 Alan Julian Izenman. Reduced-rank regression for the multivariate linear model.Journal of Multivariate Analysis, 5(2):248–264,
-
[21]
doi:https://doi.org/10.1016/0047-259X(75)90042-1 , issn =
ISSN 0047-259X. doi: https://doi.org/10.1016/0047-259X(75)90042-1. URL https://www.sciencedirect.com/science/article/pii/0047259X75900421. Ilay Kamai, Alex M. Bronstein, and Hagai B. Perets. Machine learning inference of stellar properties using integrated photometric and spectroscopic data.The Astrophysical Journal, 994,
-
[22]
Yann LeCun
URLhttps: //api.semanticscholar.org/CorpusID:280232312. Yann LeCun. A path towards autonomous machine intelligence version 0.9.2, 2022-06-27,
2022
-
[23]
Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Zou
URL https://www.semanticscholar.org/paper/775f42ed458b8c5b0f2094ea4ff5b64c557b1a34. Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Zou. Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning.arXiv e-prints, arXiv:2203.02053: arXiv:2203.02053, March
-
[24]
doi: 10.48550/arXiv.2203.02053. Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer,
-
[25]
A theory of multimodal learning.Neural Information Processing Systems, arXiv:2309.12458,
Zhou Lu. A theory of multimodal learning.Neural Information Processing Systems, arXiv:2309.12458,
-
[26]
URLhttps://arxiv.org/abs/2309.12458v2
doi: 10.48550/arxiv.2309.12458. URLhttps://arxiv.org/abs/2309.12458v2. Savita Mathur, Daniel Huber, Natalie M. Batalha, David R. Ciardi, Fabienne A. Bastien, Allyson Bieryla, Lars A. Buchhave, William D. Cochran, Michael Endl, Gilbert A. Esquerdo, Elise Furlan, Andrew Howard, Steve B. Howell, Howard Isaacson, David W. Latham, Phillip J. MacQueen, and Davi...
-
[27]
doi: 10.3847/1538-4365/229/2/30. URLhttps://dx.doi.org/ 10.3847/1538-4365/229/2/30. Loic Matthey, Irina Higgins, Demis Hassabis, and Alexander Lerchner. dsprites: Disentanglement testing sprites dataset. https://github.com/deepmind/dsprites-dataset/,
-
[29]
Pierre Mergny and Lenka Zdeborová
48550/arXiv.1802.03426. Pierre Mergny and Lenka Zdeborová. Spectral thresholds in correlated spiked models and fundamental limits of partial least squares.arXiv preprint arXiv:2510.17561,
-
[30]
doi: 10.1093/qmath/11.1.50. Liam Parker, Francois Lanusse, Jeff Shen, Ollie Liu, Tom Hehir, Leopoldo Sarra, Lucas Meyer, Micah Bowles, Sebastian Wagner-Carena, Helen Qu, Siavash Golkar, Alberto Bietti, Hatim Bourfoune, Nathan Casserau, Pierre Cornette, Keiya Hirashima, Geraud Krawezik, Ruben Ohana, Nicholas Lourie, Michael McCabe, Rudy Morel, Payel Mukhop...
-
[31]
doi: 10.48550/arXiv.2510.17960. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision.arXiv e-prints, art. arXiv:2103.00020, February
-
[32]
Learning Transferable Visual Models From Natural Language Supervision
doi: 10.48550/arXiv.2103.00020. George R. Ricker, Joshua N. Winn, Roland Vanderspek, David W. Latham, Gáspár Á. Bakos, Jacob L. Bean, Zachory K. Berta-Thompson, Timothy M. Brown, Lars Buchhave, Nathaniel R. Butler, R. Paul Butler, William J. Chaplin, David Charbonneau, Jørgen Christensen-Dalsgaard, Mark Clampin, Drake Deming, John Doty, Nathan De Lee, Cou...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.00020
-
[33]
Better Together: Cross and Joint Covariances Enhance Signal Detectability in Undersampled Data
doi: 10.1117/1.JATIS.1.1.014003. Arabind Swain, Sean Alexander Ridout, and Ilya Nemenman. Better Together: Cross and Joint Covariances Enhance Signal Detectability in Undersampled Data.arXiv e-prints, art. arXiv:2507.22207, July
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1117/1.jatis.1.1.014003
-
[34]
Better Together: Cross and Joint Covariances Enhance Signal Detectability in Undersampled Data
doi: 10.48550/arXiv.2507.22207. Hugo Tabanelli, Pierre Mergny, Lenka Zdeborova, and Florent Krzakala. Computational Thresholds in Multi-Modal Learning via the Spiked Matrix-Tensor Model.arXiv e-prints, art. arXiv:2506.02664, June
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.22207
-
[35]
Yonglong Tian, Xinlei Chen, and Surya Ganguli
doi: 10.48550/arXiv.2506.02664. Yonglong Tian, Xinlei Chen, and Surya Ganguli. Understanding self-supervised learning dynamics without contrastive pairs. InInternational Conference on Machine Learning,
-
[36]
Hugues Van Assel, Mark Ibrahim, Tommaso Biancalani, Aviv Regev, and Randall Balestriero. Joint Embed- ding vs Reconstruction: Provable Benefits of Latent Space Prediction for Self Supervised Learning.arXiv e-prints, art. arXiv:2505.12477, May
-
[37]
Meir Yossef Levi and Guy Gilboa
doi: 10.48550/arXiv.2505.12477. Meir Yossef Levi and Guy Gilboa. The Double-Ellipsoid Geometry of CLIP.arXiv e-prints, art. arXiv:2411.14517, November
-
[38]
Gang Zhao, Yong-Heng Zhao, Yao-Quan Chu, Yi-Peng Jing, and Li-Cai Deng
doi: 10.48550/arXiv.2411.14517. Gang Zhao, Yong-Heng Zhao, Yao-Quan Chu, Yi-Peng Jing, and Li-Cai Deng. LAMOST spectral survey — An overview.Research in Astronomy and Astrophysics, 12(7):723–734, July
-
[39]
doi: 10.1088/1674-4527/ 12/7/002. 13 A Closed-form solutions and spiked model derivations A.1 Full statement of closed-form solutions Theorem A.1(Closed-form solutions for CA).AssumeS xx andS yy are positive definite. LetC=PΦQ ⊤ be the SVD ofC:=S −1/2 xx SxyS−1/2 yy withrank(C) =r≥kandϕ 1 ≥ · · · ≥ϕ r >0. The minimizers of equation 1 with linear encoders ...
-
[40]
Training and evaluation follow the dSprites protocol withnsamples = 100k, 10 probe sizes (100 to 10,000), and 3–4 seeds
with FC layers1024→256→128. Training and evaluation follow the dSprites protocol withnsamples = 100k, 10 probe sizes (100 to 10,000), and 3–4 seeds. The entire sweep took approximately 24 hours on one L40S GPU. MS-COCO image-caption.We pair each COCO 2017 image with its associated caption, using the dominant-objectcategory(largestboundingbox, 80classes)as...
2017
-
[41]
Neither encoder uses pretrained weights
followed by mean pooling and a linear projection to128 dimensions. Neither encoder uses pretrained weights. Nuisance is injected into the image modality: each image is passed throughkindependent distortion groups (color cast, exposure, contrast, texture, saturation, spatial) drawn uniformly from six groups, withkcontrolled by a noise levelℓ∈ {0.0,0.2,0.5}...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.