Geometric bias in eigenspace perturbation under random heterogeneous noise
Pith reviewed 2026-06-27 11:38 UTC · model grok-4.3
The pith
Heterogeneous noise variances cause a deterministic geometric bias in empirical eigenvectors that standard perturbation theory overlooks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
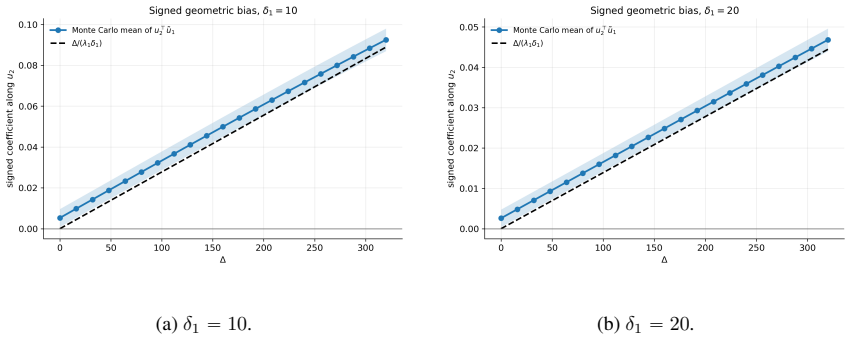
Under sparse random noise with arbitrary inhomogeneous variance profile, the empirical leading eigenvectors exhibit a systematic geometric bias term in their perturbation expansion, which can be characterized using the solution to the quadratic vector equation and is invisible to operator-norm based bounds such as Davis-Kahan.
What carries the argument
The quadratic vector equation (QVE) that governs the bias and the fine-grained isotropic local laws that control the fluctuations.
If this is right
- If the claim holds, then perturbation bounds for eigenspaces can be refined to include an explicit bias correction term based on the variance profile.
- The operator and 2-to-infinity norm bounds become near-optimal by separating the three contributions.
- Classical bounds remain valid but loose when the noise variance profile correlates with the signal geometry.
- Methods relying on eigenvector stability, such as spectral clustering, must account for this bias in heterogeneous settings.
Where Pith is reading between the lines
- If the bias is deterministic and predictable, one could design a correction step to debias the eigenvectors using an estimate of the variance profile.
- This geometric bias might appear in other random matrix models beyond sparse noise, such as in covariance estimation with heteroscedastic errors.
- The approach may extend to non-sparse noise if the local laws can be adapted.
Load-bearing premise
That the quadratic vector equation and fine-grained isotropic local laws hold for signal-plus-noise matrices with arbitrary inhomogeneous sparse random noise variance profiles.
What would settle it
Generate a low-rank signal matrix plus sparse noise with known heterogeneous variances, compute the empirical eigenvectors, and check whether the observed deviation from the true eigenvectors matches the predicted geometric bias term up to the stochastic fluctuation size.
Figures
read the original abstract
Spectral methods rely fundamentally on the stability of principal eigenspaces under random perturbations. Classically, this stability is quantified by the Davis-Kahan and Wedin theorems, which bound the eigenspace error using the operator norm of the noise and the relevant spectral gaps. While these worst-case bounds are sharp for arbitrary deterministic perturbations, they can be wasteful in the low-rank signal-plus-random-noise setting, as they fail to capture the fine-grained interaction between the signal geometry and the noise distribution. In this paper, we study the spectral perturbation of signal-plus-noise matrices corrupted by sparse, random noise with an arbitrary, inhomogeneous variance profile. We demonstrate that under heterogeneous noise variances, the empirical eigenvectors suffer a systematic, deterministic geometric bias that is entirely invisible to classical perturbation bounds. By leveraging the Quadratic Vector Equation (QVE) and establishing fine-grained isotropic local laws, we derive near-optimal, non-asymptotic perturbation bounds for the leading eigenspaces in the operator and $2\to\infty$ norms. The bounds separate the usual signal-to-noise contribution, stochastic fluctuations, and structured geometric bias terms determined by the alignment between the signal eigenspaces and the row-wise variance profile.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies spectral perturbation for low-rank signal-plus-noise matrices corrupted by sparse random noise with arbitrary inhomogeneous variance profiles. It claims that empirical eigenvectors exhibit a systematic deterministic geometric bias arising from alignment between signal eigenspaces and the row-wise variance profile; this bias is invisible to classical Davis-Kahan/Wedin bounds. Leveraging the quadratic vector equation (QVE) and fine-grained isotropic local laws, the authors derive near-optimal non-asymptotic bounds on leading eigenspace error in the operator and 2→∞ norms, separating the usual signal-to-noise term, stochastic fluctuations, and the structured geometric bias.
Significance. If the local laws hold under the stated assumptions, the work offers a finer decomposition of eigenspace error sources than classical worst-case bounds, which could improve analysis of spectral methods in settings with heterogeneous noise (e.g., certain covariance estimation or PCA tasks). The explicit separation of a deterministic geometric component and the focus on 2→∞ norms are strengths; the attempt to obtain non-asymptotic, near-optimal rates is also noteworthy.
major comments (2)
- [Abstract and local-laws section] Abstract and the section establishing the isotropic local laws: the central claim that a deterministic geometric bias term can be extracted and is invisible to Davis-Kahan/Wedin rests on the QVE and fine-grained isotropic local laws applying directly to signal-plus-noise matrices with arbitrary inhomogeneous sparse variance profiles. Standard QVE theory requires regularity conditions (uniform boundedness of entries, row/column sum control, or Lipschitz continuity of the profile) for uniqueness of the fixed-point solution and error control in the local law. The manuscript must explicitly state and verify these conditions for the claimed 'arbitrary' profiles; without them the bias term is not rigorously justified.
- [Main theorem on perturbation bounds] Main theorem on the perturbation bounds (likely the result separating the three error sources): the near-optimality assertion and the claim that the geometric bias is 'entirely invisible' to classical bounds require the explicit form of the bias term (how it depends on the alignment between signal subspaces and the variance profile) to be displayed and compared against the operator-norm bound. If this term is only implicit in the QVE solution, the separation into signal-to-noise, stochastic, and geometric components cannot be verified as load-bearing.
minor comments (2)
- [Introduction] Clarify the precise notion of 'near-optimal' (with respect to which minimax rate or information-theoretic lower bound) already in the introduction, rather than only in the abstract.
- [Assumptions section] Notation for the variance profile matrix should be introduced with an explicit display equation early in the assumptions section to avoid ambiguity when referring to row-wise inhomogeneity.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable comments. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and local-laws section] Abstract and the section establishing the isotropic local laws: the central claim that a deterministic geometric bias term can be extracted and is invisible to Davis-Kahan/Wedin rests on the QVE and fine-grained isotropic local laws applying directly to signal-plus-noise matrices with arbitrary inhomogeneous sparse variance profiles. Standard QVE theory requires regularity conditions (uniform boundedness of entries, row/column sum control, or Lipschitz continuity of the profile) for uniqueness of the fixed-point solution and error control in the local law. The manuscript must explicitly state and verify these conditions for the claimed 'arbitrary' profiles; without them the bias term is not rigorously justified.
Authors: We agree that the regularity conditions underlying the QVE must be stated explicitly to justify the applicability to the variance profiles considered. The manuscript assumes the variance profile satisfies the standard conditions for QVE uniqueness and local law error bounds, including bounded maximum entry size, controlled row and column sums, and appropriate regularity for the sparse inhomogeneous case. To address this, we will add an explicit statement of these assumptions in the local laws section, along with a verification that they hold for the class of profiles under consideration. This will clarify that 'arbitrary' refers to arbitrary profiles within this regularity class, under which the geometric bias is rigorously derived. revision: yes
-
Referee: [Main theorem on perturbation bounds] Main theorem on the perturbation bounds (likely the result separating the three error sources): the near-optimality assertion and the claim that the geometric bias is 'entirely invisible' to classical bounds require the explicit form of the bias term (how it depends on the alignment between signal subspaces and the variance profile) to be displayed and compared against the operator-norm bound. If this term is only implicit in the QVE solution, the separation into signal-to-noise, stochastic, and geometric components cannot be verified as load-bearing.
Authors: The explicit form of the geometric bias is obtained by solving the QVE for the heterogeneous variance profile and comparing to the homogeneous case; it takes the form of a deterministic shift in the eigenvector directions proportional to the projection of the signal vectors onto the variance profile. We will revise the main theorem section to display this explicit expression and include a direct comparison showing that the classical Davis-Kahan bound, which depends only on the operator norm of the noise, does not capture this alignment-dependent term. This makes the separation into the three components explicit and verifies that the geometric bias is indeed invisible to classical bounds. revision: yes
Circularity Check
No significant circularity detected; derivation relies on external QVE and local laws
full rationale
The paper's central derivation leverages the Quadratic Vector Equation and establishes fine-grained isotropic local laws to separate signal-to-noise, stochastic, and geometric bias terms in the perturbation bounds. No steps reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations whose content is unverified within the paper. The assumptions on the variance profile are stated as part of the setup for applying these tools, without the target bounds being tautological to the inputs. This is the standard case of a paper building on established external theory.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Noise entries are independent with row-wise variance profile that can be arbitrary
- domain assumption Quadratic vector equation and fine-grained isotropic local laws hold for this inhomogeneous noise model
Reference graph
Works this paper leans on
-
[1]
E. Abbe, J. Fan, and K. Wang. Anℓ p theory of PCA and spectral clustering.The Annals of Statistics, 50(4):2359–2385, 2022. 97
2022
-
[2]
E. Abbe, J. Fan, K. Wang, and Y . Zhong. Entrywise eigenvector analysis of random matrices with low expected rank.The Annals of Statistics, 48(3):1452–1474, 2020
2020
-
[3]
J. Agterberg. Distributional theory and statistical inference for linear functions of eigenvec- tors with small eigengaps.arXiv preprint arXiv:2308.02480, 2023
Pith/arXiv arXiv 2023
-
[4]
Agterberg, Z
J. Agterberg, Z. Lubberts, and C. E. Priebe. Entrywise estimation of singular vectors of low-rank matrices with heteroskedasticity and dependence.IEEE Trans. Inform. Theory, 68(7):4618–4650, 2022
2022
-
[5]
L. V . Ahlfors and L. V . Ahlfors.Complex analysis, volume 3. McGraw-Hill New York, 1979
1979
-
[6]
Ajanki, L
O. Ajanki, L. Erd ˝os, and T. Kr¨uger.Quadratic vector equations on complex upper half-plane, volume 261. American Mathematical Society, 2019
2019
-
[7]
Allez and J.-P
R. Allez and J.-P. Bouchaud. Eigenvector dynamics under free addition.Random Matrices Theory Appl., 3(3):1450010, 17, 2014
2014
-
[8]
N. Alon, M. Krivelevich, and B. Sudakov. Finding a large hidden clique in a random graph. Random Structures & Algorithms, 13(3-4):457–466, 1998
1998
-
[9]
Arias-Castro and N
E. Arias-Castro and N. Verzelen. Community detection in dense random networks.The Annals of Statistics, 42(3):940–969, 2014
2014
-
[10]
Bai and J
Z. Bai and J. Yao. Central limit theorems for eigenvalues in a spiked population model.Ann. Inst. H. Poincar´e Probab. Statist., 44(3):447–474, 2008
2008
-
[11]
J. Baik, G. B. Arous, S. P ´ech´e, et al. Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices.The Annals of Probability, 33(5):1643–1697, 2005
2005
-
[12]
Baik and J
J. Baik and J. W. Silverstein. Eigenvalues of large sample covariance matrices of spiked population models.Journal of Multivariate Analysis, 97(6):1382–1408, 2006
2006
-
[13]
Balakrishnan, M
S. Balakrishnan, M. Kolar, A. Rinaldo, A. Singh, and L. Wasserman. Statistical and com- putational tradeoffs in biclustering. InNIPS 2011 Workshop on Computational Trade-offs in Statistical Learning, volume 4, 2011
2011
-
[14]
A. S. Bandeira and R. van Handel. Sharp nonasymptotic bounds on the norm of random matrices with independent entries.The Annals of Probability, 44(4):2479–2506, 2016
2016
-
[15]
Z. Bao, K. M. Cheong, J. Lee, and Y . Li. Signal detection from spiked noise via asym- metrization.arXiv preprint arXiv:2504.19450, 2025
arXiv 2025
-
[16]
Z. Bao, X. Ding, J. Wang, and K. Wang. Statistical inference for principal components of spiked covariance matrices.The Annals of Statistics, 50(2):1144–1169, 2022
2022
-
[17]
Z. Bao, X. Ding, and K. Wang. Singular vector and singular subspace distribution for the matrix denoising model.The Annals of Statistics, 49(1):370–392, 2021. 98
2021
-
[18]
Bao and D
Z. Bao and D. Wang. Eigenvector distribution in the critical regime of BBP transition.Prob- ability Theory and Related Fields, pages 1–81, 2021
2021
-
[19]
Benaych-Georges, N
F. Benaych-Georges, N. Enriquez, and A. Micha ¨ıl. Eigenvectors of a matrix under random perturbation.Random Matrices Theory Appl., 10(2):2150023, 2021
2021
-
[20]
Benaych-Georges, A
F. Benaych-Georges, A. Guionnet, and M. Maida. Fluctuations of the extreme eigenvalues of finite rank deformations of random matrices.Electron. J. Probab., 16:1621–1662, 2011
2011
-
[21]
Benaych-Georges and R
F. Benaych-Georges and R. R. Nadakuditi. The eigenvalues and eigenvectors of finite, low rank perturbations of large random matrices.Advances in Mathematics, 227(1):494–521, 2011
2011
-
[22]
Benaych-Georges and R
F. Benaych-Georges and R. R. Nadakuditi. The singular values and vectors of low rank per- turbations of large rectangular random matrices.Journal of Multivariate Analysis, 111:120– 135, 2012
2012
-
[23]
L. Benigni. Eigenvectors distribution and quantum unique ergodicity for deformed wigner matrices.Annales de l’Institut Henri Poincar´e-Probabilit´es et Statistiques, 56(4):2822–2867, 2020
2020
-
[24]
Bhardwaj and V
A. Bhardwaj and V . Vu. Matrix perturbation: Davis-Kahan in the infinity norm. InPro- ceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 880–934. SIAM, 2024
2024
-
[25]
Bhatia.Matrix analysis, volume 169 ofGraduate Texts in Mathematics
R. Bhatia.Matrix analysis, volume 169 ofGraduate Texts in Mathematics. Springer-Verlag, New York, 1997
1997
-
[26]
B. Bhattacharya, A. Chakrabarty, and R. S. Hazra. Outlier eigenvalues and eigen- vectors of generalized wigner matrices with finite-rank perturbations.arXiv preprint arXiv:2601.10204, 2026
arXiv 2026
-
[27]
Bloemendal, A
A. Bloemendal, A. Knowles, H.-T. Yau, and J. Yin. On the principal components of sample covariance matrices.Probability Theory and Related Fields, 164(1-2):459–552, 2016
2016
-
[28]
Brailovskaya and R
T. Brailovskaya and R. Van Handel. Extremal random matrices with independent entries and matrix superconcentration inequalities.The Annals of Probability, 54(2):669–704, 2026
2026
-
[29]
Brennan, G
M. Brennan, G. Bresler, and W. Huleihel. Reducibility and computational lower bounds for problems with planted sparse structure. InConference On Learning Theory, pages 48–166. PMLR, 2018
2018
-
[30]
Butucea and Y
C. Butucea and Y . I. Ingster. Detection of a sparse submatrix of a high-dimensional noisy matrix.Bernoulli, 19(5B):2652–2688, 2013
2013
-
[31]
Butucea, Y
C. Butucea, Y . I. Ingster, and I. A. Suslina. Sharp variable selection of a sparse submatrix in a high-dimensional noisy matrix.ESAIM: Probability and Statistics, 19:115–134, 2015. 99
2015
-
[32]
C. Cai, G. Li, Y . Chi, H. V . Poor, and Y . Chen. Subspace estimation from unbalanced and incomplete data matrices:ℓ 2,8 statistical guarantees.The Annals of Statistics, 49(2):944– 967, 2021
2021
-
[33]
T. T. Cai, T. Liang, and A. Rakhlin. Computational and statistical boundaries for submatrix localization in a large noisy matrix.The Annals of Statistics, 45(4):1403–1430, 2017
2017
-
[34]
T. T. Cai and A. Zhang. Rate-optimal perturbation bounds for singular subspaces with appli- cations to high-dimensional statistics.The Annals of Statistics, 46(1):60–89, 2018
2018
-
[35]
E. J. Cand `es and Y . Plan. Matrix completion with noise.Proceedings of the IEEE, 98:925– 936, 2010
2010
-
[36]
E. J. Cand `es and B. Recht. Exact matrix completion via convex optimization.Found. Com- put. Math., 9(6):717–772, 2009
2009
-
[37]
J. Cape, M. Tang, and C. E. Priebe. The two-to-infinity norm and singular subspace geometry with applications to high-dimensional statistics.The Annals of Statistics, 47(5):2405–2439, 2019
2019
-
[38]
Capitaine
M. Capitaine. Limiting eigenvectors of outliers for Spiked Information-Plus-Noise type ma- trices.S ´eminaire de Probabilit´es XLIX, pages 119–164, 2018
2018
-
[39]
Capitaine and C
M. Capitaine and C. Donati-Martin. Non universality of fluctuations of outlier eigenvectors for block diagonal deformations of wigner matrices.ALEA: Latin American Journal of Probability and Mathematical Statistics, 18(1):129–165, 2021
2021
-
[40]
J. Chang and J. Cape. Extreme value theory for singular subspace estimation in the matrix denoising model.arXiv preprint arXiv:2507.19978, 2025
arXiv 2025
-
[41]
Y . Chen, Y . Chi, J. Fan, and C. Ma. Spectral methods for data science: A statistical perspec- tive.Foundations and Trends® in Machine Learning, 14(5):566–806, 2021
2021
-
[42]
Y . Chen, J. Fan, C. Ma, and K. Wang. Spectral method and regularized MLE are both optimal for top-K ranking.The Annals of Statistics, 47(4):2204–2235, 2019
2019
-
[43]
Chen and J
Y . Chen and J. Xu. Statistical-computational tradeoffs in planted problems and submatrix localization with a growing number of clusters and submatrices.The Journal of Machine Learning Research, 17(1):882–938, 2016
2016
-
[44]
Cheng, Y
C. Cheng, Y . Wei, and Y . Chen. Tackling small eigen-gaps: Fine-grained eigenvector estima- tion and inference under heteroscedastic noise.IEEE Transactions on Information Theory, 67(11):7380–7419, 2021
2021
-
[45]
Comtet.Advanced Combinatorics: The art of finite and infinite expansions
L. Comtet.Advanced Combinatorics: The art of finite and infinite expansions. Springer Science & Business Media, 2012
2012
-
[46]
Dadon, W
M. Dadon, W. Huleihel, and T. Bendory. Detection and recovery of hidden submatrices. IEEE Transactions on Signal and Information Processing over Networks, 2024. 100
2024
-
[47]
Davis and W
C. Davis and W. M. Kahan. The rotation of eigenvectors by a perturbation. III.SIAM J. Numer. Anal., 7:1–46, 1970
1970
-
[48]
Dekel, O
Y . Dekel, O. Gurel-Gurevich, and Y . Peres. Finding hidden cliques in linear time with high probability.Combinatorics, Probability and Computing, 23(1):29–49, 2014
2014
-
[49]
Eldridge, M
J. Eldridge, M. Belkin, and Y . Wang. Unperturbed: spectral analysis beyond Davis-Kahan. InAlgorithmic Learning Theory, pages 321–358. PMLR, 2018
2018
-
[50]
J. Fan, Y . Fan, X. Han, and J. Lv. Asymptotic theory of eigenvectors for large random matrices.Journal of the American Statistical Association, 117(538):996–1009, 2022
2022
-
[51]
J. Fan, W. Wang, and Y . Zhong. Anℓ8 eigenvector perturbation bound and its application to robust covariance estimation.Journal of Machine Learning Research, 18:207–207, 2018
2018
-
[52]
Feige and D
U. Feige and D. Ron. Finding hidden cliques in linear time. InDiscrete Mathematics and Theoretical Computer Science, pages 189–204. Discrete Mathematics and Theoretical Com- puter Science, 2010
2010
-
[53]
L. S. Ferreira and F. L. Metz. BBP transition and the leading eigenvector of the spiked wigner model with inhomogeneous noise.arXiv preprint arXiv:2604.18523, 2026
Pith/arXiv arXiv 2026
-
[54]
I. C. Gohberg and E. I. Sigal. An operator generalization of the logarithmic residue theorem and the theorem of Rouch´e.Mathematics of the USSR-Sbornik, 13(4):603–625, 1971
1971
-
[55]
Guionnet, J
A. Guionnet, J. Ko, F. Krzakala, and L. Zdeborov ´a. Low-rank matrix estimation with inho- mogeneous noise.Information and Inference: A Journal of the IMA, 14(2):iaaf010, 2025
2025
-
[56]
Hajek, Y
B. Hajek, Y . Wu, and J. Xu. Achieving exact cluster recovery threshold via semidefinite programming.IEEE Transactions on Information Theory, 62(5):2788–2797, 2016
2016
-
[57]
Y . He, A. Knowles, and R. Rosenthal. Isotropic self-consistent equations for mean-field random matrices.Probab. Theory Related Fields, 171(1-2):203–249, 2018
2018
-
[58]
D. Hong, L. Balzano, and J. A. Fessler. Asymptotic performance of PCA for high- dimensional heteroscedastic data.Journal of Multivariate Analysis, 167:435–452, 2018
2018
-
[59]
D. Hong, K. Gilman, L. Balzano, and J. A. Fessler. HePPCAT: Probabilistic PCA for data with heteroscedastic noise.IEEE Transactions on Signal Processing, 69:4819–4834, 2021
2021
-
[60]
D. Hong, F. Yang, J. A. Fessler, and L. Balzano. Optimally weighted PCA for high- dimensional heteroscedastic data.SIAM Journal on Mathematics of Data Science, 5(1):222– 250, 2023
2023
-
[61]
Keshavan, A
R. Keshavan, A. Montanari, and S. Oh. Matrix completion from noisy entries.Advances in Neural Information Processing Systems, 22, 2009
2009
-
[62]
Kolar, S
M. Kolar, S. Balakrishnan, A. Rinaldo, and A. Singh. Minimax localization of structural information in large noisy matrices.Advances in Neural Information Processing Systems, 24, 2011. 101
2011
-
[63]
Koltchinskii and D
V . Koltchinskii and D. Xia. Perturbation of linear forms of singular vectors under Gaussian noise. InHigh dimensional probability VII, volume 71 ofProgr. Probab., pages 397–423. Springer, [Cham], 2016
2016
-
[64]
L. Lei. Unifiedℓ 2Ñ8 eigenspace perturbation theory for symmetric random matrices.arXiv preprint arXiv:1909.04798, 2019
arXiv 1909
-
[65]
G. Li, C. Cai, H. V . Poor, and Y . Chen. Minimax estimation of linear functions of eigenvec- tors in the face of small eigen-gaps.IEEE Transactions on Information Theory, 71(2):1200– 1247, 2024
2024
-
[66]
L ¨offler, A
M. L ¨offler, A. Y . Zhang, and H. H. Zhou. Optimality of spectral clustering in the gaussian mixture model.The Annals of Statistics, 49(5):2506–2530, 2021
2021
-
[67]
Y . Luo, R. Han, and A. R. Zhang. A Schatten-qlow-rank matrix perturbation analysis via perturbation projection error bound.Linear Algebra and its Applications, 630:225–240, 2021
2021
-
[68]
Ma and Y
Z. Ma and Y . Wu. Computational barriers in minimax submatrix detection.The Annals of Statistics, pages 1089–1116, 2015
2015
-
[69]
McSherry
F. McSherry. Spectral partitioning of random graphs. InProceedings 42nd IEEE Symposium on Foundations of Computer Science, pages 529–537. IEEE, 2001
2001
-
[70]
Montanari, D
A. Montanari, D. Reichman, and O. Zeitouni. On the limitation of spectral methods: From the gaussian hidden clique problem to rank-one perturbations of gaussian tensors.Advances in Neural Information Processing Systems, 28, 2015
2015
-
[71]
O’Rourke, V
S. O’Rourke, V . Vu, and K. Wang. Eigenvectors of random matrices: A survey.Journal of Combinatorial Theory, Series A, 144:361 – 442, 2016. Fifty Years of the Journal of Combinatorial Theory
2016
-
[72]
O’Rourke, V
S. O’Rourke, V . Vu, and K. Wang. Random perturbation of low rank matrices: improving classical bounds.Linear Algebra Appl., 540:26–59, 2018
2018
-
[73]
O’Rourke, V
S. O’Rourke, V . Vu, and K. Wang. Matrices with Gaussian noise: optimal estimates for singular subspace perturbation.IEEE Transactions on Information Theory, 70(3):1978– 2002, 2024
1978
-
[74]
O’Rourke and N
S. O’Rourke and N. Williams. Pairing between zeros and critical points of random polyno- mials with independent roots.Trans. Amer. Math. Soc., 371(4):2343–2381, 2019
2019
-
[75]
D. Paul. Asymptotics of sample eigenstructure for a large dimensional spiked covariance model.Statistica Sinica, 17(4):1617–1642, 2007
2007
-
[76]
Tran and V
P. Tran and V . Vu. New matrix perturbation bounds via combinatorial expansion I: Perturba- tion of eigenspaces.arXiv e-prints, pages arXiv–2409, 2024
2024
-
[77]
P. Tran and V . Vu. New matrix perturbation bounds with relative norm: Perturbation of eigenspaces.arXiv preprint arXiv:2409.20207, 2024. 102
arXiv 2024
-
[78]
Vershynin.High-dimensional probability: An introduction with applications in data sci- ence, volume 47
R. Vershynin.High-dimensional probability: An introduction with applications in data sci- ence, volume 47. Cambridge university press, 2018
2018
-
[79]
V on Luxburg, M
U. V on Luxburg, M. Belkin, and O. Bousquet. Consistency of spectral clustering.The Annals of Statistics, 36(2):555–586, 2008
2008
-
[80]
V . Vu. Singular vectors under random perturbation.Random Structures & Algorithms, 39(4):526–538, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.