A prior-free blind detection of information leakage from model predictions
Pith reviewed 2026-06-27 14:02 UTC · model grok-4.3
The pith
A near-deterministic subgroup produced by near-label leakage creates a sustained unit-purity head in predictions that no honest predictor of a non-deterministic outcome can generate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Leakage falls into three exhaustive classes. Miscalibrated leakage is visible to any proper scoring rule. Broad-calibrated leakage that matches an honest model’s discrimination is invisible to every functional of the prediction vector unless an external ceiling on achievable discrimination is supplied. Deterministic leakage, however, is revealed by the unit-purity head: a subgroup whose predictions are exactly 1 or exactly 0 and whose outcomes match those predictions with probability 1. No predictor that is calibrated and whose labels remain stochastic can produce such a head; its existence is therefore decisive evidence of a near-label leak.
What carries the argument
the sustained unit-purity head: the longest prefix of a sorted prediction vector in which every prediction equals 1 (or 0) and every corresponding outcome equals the prediction, whose length cannot be manufactured by any honest predictor of a non-deterministic label
If this is right
- Miscalibrated leakage is detected by any proper scoring rule applied to the prediction-outcome pairs.
- Broad-calibrated leakage remains undetectable from output alone once its discrimination equals the best honest discrimination.
- Deterministic leakage is detected by the length of the unit-purity head without any external prior or training code.
- The numerical detection floor is endpoint- and cohort-specific; the structural impossibility result is not.
- The entire procedure runs on a prediction vector alone and returns a verdict in under a second.
Where Pith is reading between the lines
- Auditors holding only a deployed model’s output file can now screen for the most severe form of leakage without access to training code or external data.
- The trichotomy suggests that any future output-only detector must first test for the unit-purity head before attempting to bound the remaining two classes.
- If the unit-purity test is negative, residual leakage smaller than the supplied discrimination ceiling cannot be distinguished from an honestly stronger model on the same endpoint.
- The same head statistic may be usable as a diagnostic for label noise or for deterministic sub-populations that were never intended to be modeled probabilistically.
Load-bearing premise
An external upper bound on achievable discrimination must be supplied before the broad recalibrated class can be ruled out.
What would settle it
A single legitimate predictor of a non-deterministic binary outcome that nevertheless sustains a unit-purity head of positive length over any subgroup would falsify the claim that only near-label leakage can produce the head.
Figures
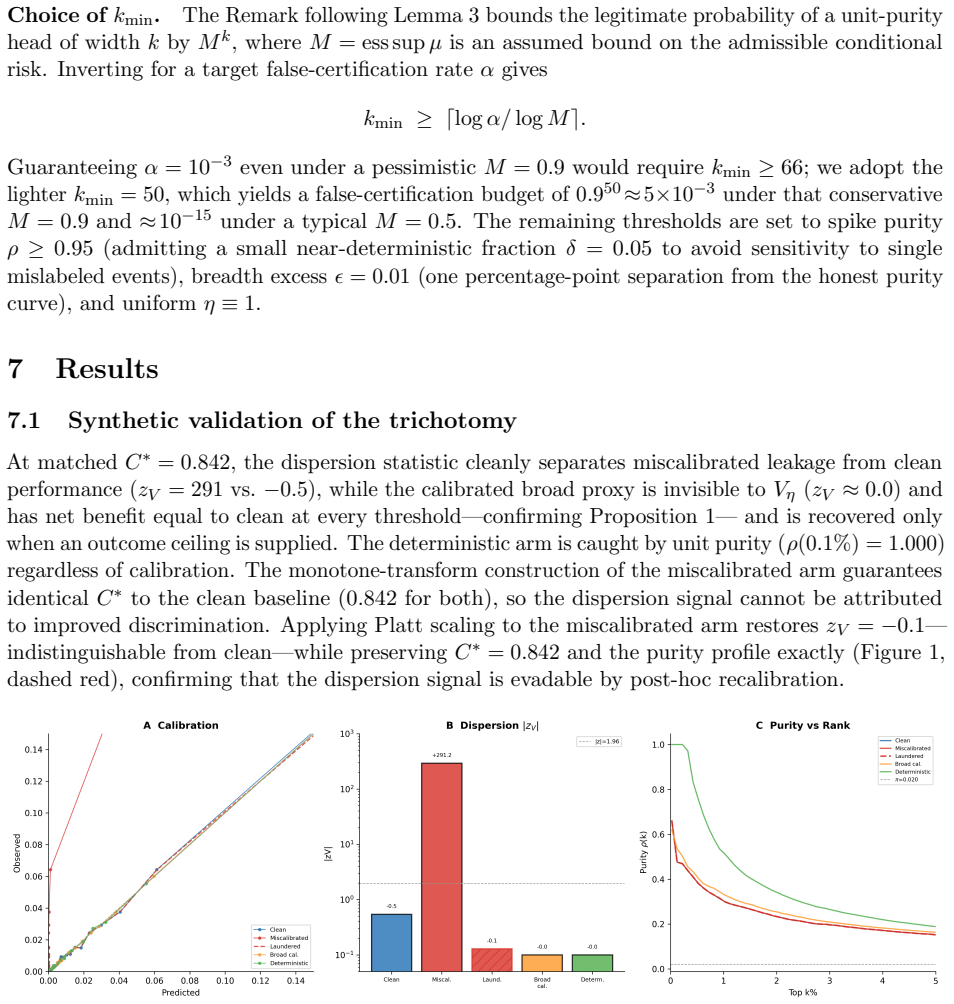
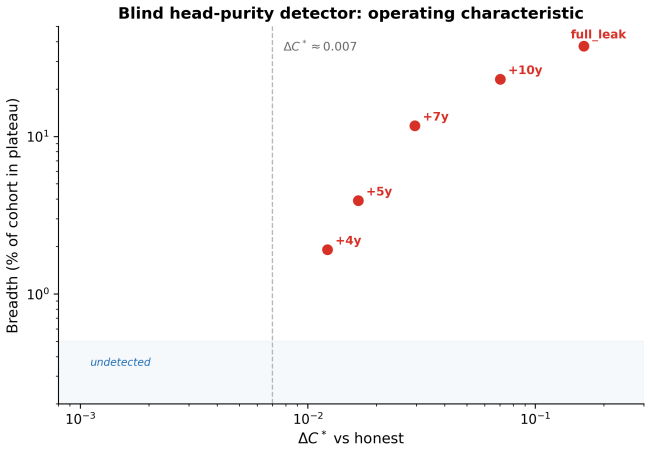
read the original abstract
Data leakage -- contamination of a model with information unavailable at baseline -- is the dominant reproducibility failure in machine-learning-based science, yet detection tools require training code, external data, or domain expertise. None operates on the artifact an auditor most often holds: the model's output. We ask what can be decided about leakage from predictions and outcomes alone. We give a decision-theoretic framework in which leakage diagnostics are functionals of the predicted-risk/outcome law, parameterized by a threshold-weighting linked to proper scoring rules and decision-curve analysis. We prove a sharp impossibility: a recalibrated leak matching an honest model's calibration and discrimination is indistinguishable from honest performance by \emph{any} function of the predictions, so the broad class is detectable only against an externally supplied ceiling on achievable discrimination. We then prove what leakage cannot hide: a near-deterministic subgroup -- the signature of a near-label leak -- produces a sustained unit-purity head that no legitimate predictor of a non-deterministic outcome can manufacture, yielding a prior-free test. These results organize leakage into a trichotomy -- miscalibrated, broad-calibrated, and deterministic -- each with a matched detector and failure mode. We validate on UK Biobank using time-windowed comorbidity leakage with known, graded severity, measuring a detection floor of $\Delta\cstar \approx 0.007$ on this endpoint, below which residual leakage is undetectable from output and too small to alter conclusions. The numerical floor is cohort- and endpoint-specific; the structural lesson is general: output-only detection fails where residual leakage is indistinguishable from an honestly stronger predictor. The test returns a verdict on a prediction vector in under a second on commodity hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a decision-theoretic framework in which leakage diagnostics are functionals of the predicted-risk/outcome distribution, parameterized by threshold weightings derived from proper scoring rules and decision-curve analysis. It proves an impossibility result: any recalibrated leak that matches an honest model in both calibration and discrimination is indistinguishable from honest performance by any functional of the predictions alone, so broad-class detection requires an externally supplied ceiling on achievable discrimination. It further proves that a near-deterministic subgroup (signature of near-label leakage) produces a sustained unit-purity head that no honest predictor of a non-deterministic outcome can produce, yielding a prior-free detector. Leakage is organized into a trichotomy (miscalibrated, broad-calibrated, deterministic) with matched detectors; the framework is validated on UK Biobank time-windowed comorbidity leakage, reporting a cohort-specific detection floor of Δc* ≈ 0.007 below which residual leakage is undetectable from output alone. The test runs in under a second on commodity hardware.
Significance. If the stated theorems hold, the work supplies a principled, output-only method for detecting a practically important subclass of leakage (near-label) without training code, external data, or domain expertise—an advance for reproducibility auditing in ML-based science. The impossibility result usefully delineates the limits of output-only detection, while the unit-purity test is prior-free by construction. The empirical measurement of a concrete detection floor on real data and the explicit link to decision-curve analysis are additional strengths. The trichotomy organizes the problem space clearly.
minor comments (2)
- The abstract states that the proofs exist and that the detection floor is measured, yet supplies neither the derivations nor the explicit computation of Δc*; the full manuscript must place both in the main text (or a clearly referenced appendix) so that the central claims can be verified.
- Notation for the threshold-weighting functional and the unit-purity head should be introduced with a single, self-contained definition early in the methods section rather than distributed across the trichotomy discussion.
Simulated Author's Rebuttal
We thank the referee for their careful summary of the manuscript, for highlighting the decision-theoretic framing and the trichotomy of leakage types, and for noting the practical value of the prior-free unit-purity detector together with the measured detection floor on UK Biobank data. We appreciate the positive assessment of significance. No major comments were listed in the report, so we have no point-by-point responses to provide. We remain available to address any further questions or clarifications the referee may wish to raise.
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The framework is parameterized by threshold-weighting linked to proper scoring rules and decision-curve analysis (external standards). The sharp impossibility result for recalibrated leaks and the unit-purity head detector for near-deterministic subgroups are presented as theorems following from the predicted-risk/outcome law; neither reduces to a fitted parameter or self-citation. The trichotomy organizes leakage types with matched detectors and failure modes. Validation uses external cohort data (UK Biobank) with known leakage. No load-bearing step equates a prediction to its input by construction or imports uniqueness via author self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard axioms of probability and decision theory underlying proper scoring rules and decision-curve analysis
Reference graph
Works this paper leans on
-
[1]
Shachar Kaufman, Saharon Rosset, Claudia Perlich, and Ori Stitelman. Leakage in data mining: Formulation, detection, and avoidance.ACM Transactions on Knowledge Discovery from Data, 6(4):1–21, 2012. doi: 10.1145/2382577.2382579. Article 15
-
[2]
Michael A. Lones. How to avoid machine learning pitfalls: a guide for academic researchers. arXiv preprint, 2024. arXiv:2108.02497v4
arXiv 2024
-
[3]
Sayash Kapoor and Arvind Narayanan. Leakage and the reproducibility crisis in machine- learning-based science.Patterns, 4(9):100804, 2023. doi: 10.1016/j.patter.2023.100804
-
[4]
Aviles-Rivero, Christian Etmann, Cathal McCague, Lucian Beer, Jonathan R
Michael Roberts, Derek Driggs, Matthew Thorpe, Julian Gilbey, Michael Yeung, Stephan Ur- sprung, Angelica I. Aviles-Rivero, Christian Etmann, Cathal McCague, Lucian Beer, Jonathan R. Weir-McCall, Zhongzhao Teng, Effrossyni Gkrania-Klotsas, James H. F. Rudd, Evis Sala, and Carola-Bibiane Sch¨ onlieb. Common pitfalls and recommendations for using machine le...
-
[5]
Cynthia Dwork, Vitaly Feldman, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Aaron Roth. The reusable holdout: Preserving validity in adaptive data analysis.Science, 349(6248): 636–638, 2015. doi: 10.1126/science.aaa9375
-
[6]
Chenyang Yang, Rachel A. Brower-Sinning, Grace A. Lewis, and Christian K¨ astner. Data leakage in notebooks: Static detection and better processes. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2022. doi: 10.1145/3551349.3556918. Article 30
-
[7]
Robert F. Wolff, Karel G. M. Moons, Richard D. Riley, Penny F. Whiting, Marie Westwood, Gary S. Collins, Johannes B. Reitsma, Jos Kleijnen, and Sue Mallett. PROBAST: A tool to assess the risk of bias and applicability of prediction model studies.Annals of Internal Medicine, 170(1):51–58, 2019. doi: 10.7326/M18-1376. 12
-
[8]
Cantrell, Kenny Peng, Thanh Hien Pham, Christopher A
Sayash Kapoor, Emily M. Cantrell, Kenny Peng, Thanh Hien Pham, Christopher A. Bail, Odd Erik Gundersen, Jake M. Hofman, Jessica Hullman, Michael A. Lones, Momin M. Ma- lik, Priyanka Nanayakkara, Russell A. Poldrack, Inioluwa Deborah Raji, Michael Roberts, Matthew J. Salganik, Marta Serra-Garcia, Brandon M. Stewart, Gilles Vandewiele, and Arvind Narayanan....
-
[9]
Collins, Johannes B
Gary S. Collins, Johannes B. Reitsma, Douglas G. Altman, and Karel G. M. Moons. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): The TRIPOD statement.Annals of Internal Medicine, 162(1):55–63, 2015. doi: 10.7326/ M14-0697
2015
-
[10]
Gary S. Collins, Karel G. M. Moons, Paula Dhiman, Richard D. Riley, Andrew L. Beam, Ben Van Calster, Marzyeh Ghassemi, Xiaoxuan Liu, Johannes B. Reitsma, Maarten van Smeden, Anne-Laure Boulesteix, Jennifer C. Camaradou, Leo Anthony Celi, Spiros Denaxas, Alastair K. Denniston, Ben Glocker, Robert M. Golub, Hugh Harvey, Georg Heinze, Michael M. Hoffman, And...
-
[11]
Ben Van Calster, Daan Nieboer, Yvonne Vergouwe, Bavo De Cock, Michael J. Pencina, and Ewout W. Steyerberg. A calibration hierarchy for risk models was defined: From utopia to empirical data.Journal of Clinical Epidemiology, 74:167–176, 2016. doi: 10.1016/j.jclinepi. 2015.12.005
-
[12]
Calibration: the Achilles heel of predictive analytics
Ben Van Calster, David J. McLernon, Maarten van Smeden, Laure Wynants, and Ewout W. Steyerberg. Calibration: The Achilles heel of predictive analytics.BMC Medicine, 17:230, 2019. doi: 10.1186/s12916-019-1466-7
-
[13]
Harrell, Kerry L
Frank E. Harrell, Kerry L. Lee, and Daniel B. Mark. Multivariable prognostic models: Issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Statistics in Medicine, 15(4):361–387, 1996
1996
-
[14]
Vickers and Elena B
Andrew J. Vickers and Elena B. Elkin. Decision curve analysis: A novel method for eval- uating prediction models.Medical Decision Making, 26(6):565–574, 2006. doi: 10.1177/ 0272989X06295361
2006
-
[15]
Jacobs and Andrew J
Laurence A. Jacobs and Andrew J. Vickers. Expected net benefit: From decision curve analysis to a prior-weighted summary measure for evaluating clinical prediction models. Nature Methods — In review, 2026
2026
-
[16]
Mark J. Schervish. A general method for comparing probability assessors.The Annals of Statistics, 17(4):1856–1879, 1989. doi: 10.1214/aos/1176347398
-
[17]
Werner Ehm, Tilmann Gneiting, Alexander Jordan, and Fabian Kr¨ uger. Of quantiles and expectiles: Consistent scoring functions, Choquet representations and forecast rankings.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 78(3):505–562, 2016. doi: 10.1111/rssb.12154. 13
-
[18]
Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and estimation.Journal of the American Statistical Association, 102(477):359–378, 2007
2007
-
[19]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE Symposium on Security and Privacy (S&P), pages 3–18, 2017. doi: 10.1109/SP.2017.41
-
[20]
John C. Platt. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. In Alexander J. Smola, Peter L. Bartlett, Bernhard Sch¨ olkopf, and Dale Schuurmans, editors,Advances in Large Margin Classifiers, pages 61–74. MIT Press, 1999
1999
-
[21]
PLoS Med.12(3), e1001779 (2015).https://doi.org/10.1371/journal.pmed.1001779
Cathie Sudlow, John Gallacher, Naomi Allen, Valerie Beral, Paul Burton, John Danesh, Paul Downey, Paul Elliott, Jane Green, Martin Landray, Bette Liu, Paul Matthews, Giok Ong, Jill Pell, Alan Silman, Alan Young, Tim Sprosen, Tim Peakman, and Rory Collins. UK Biobank: An open access resource for identifying the causes of a wide range of complex diseases of...
-
[22]
Robert Tibshirani. Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288, 1996. doi: 10.1111/j.2517-6161. 1996.tb02080.x
-
[23]
Morris H. DeGroot and Stephen E. Fienberg. The comparison and evaluation of forecasters. Journal of the Royal Statistical Society: Series D (The Statistician), 32(1-2):12–22, 1983. doi: 10.2307/2987588
-
[24]
Lieb and Michael Loss.Analysis, volume 14 ofGraduate Studies in Mathematics
Elliott H. Lieb and Michael Loss.Analysis, volume 14 ofGraduate Studies in Mathematics. American Mathematical Society, 2nd edition, 2001
2001
-
[25]
David W. Hosmer and Stanley Lemeshow. Goodness-of-fit tests for the multiple logistic regression model.Communications in Statistics — Theory and Methods, 9(10):1043–1069, 1980. doi: 10.1080/03610928008827941
-
[26]
David J. Spiegelhalter. Probabilistic prediction in patient management and clinical trials. Statistics in Medicine, 5(5):421–433, 1986. doi: 10.1002/sim.4780050506. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.