Traits Run Deeper: Trait-Specific Asymmetric Fusion for Personality Assessment
Pith reviewed 2026-06-27 14:06 UTC · model grok-4.3
The pith
Trait-specific asymmetric fusion improves personality assessment by letting each dimension select its own modality pathways.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that trait-specific modality preferences exist and can be captured by an asymmetric fusion mechanism in which each personality dimension independently chooses pathways from modality-specific modeling to complementary fusion, thereby reducing cross-modal contamination that uniform strategies create, while the foundation representation and calibration steps further stabilize the regression.
What carries the argument
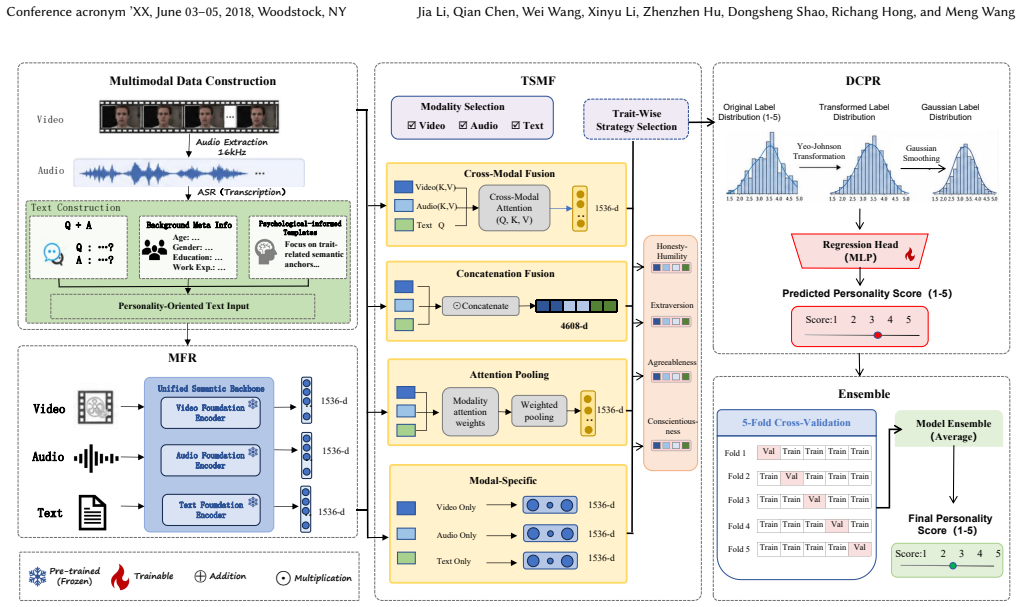
The Trait-Specific Modality Fusion (TSMF) module, an asymmetric fusion mechanism that lets each dimension selectively exploit different modality pathways from modality-specific modeling to complementary fusion.
If this is right
- Each personality dimension can draw on its own preferred combination of language, voice, and face cues rather than receiving the same fused input.
- Cross-modal contamination decreases because irrelevant modalities are down-weighted per trait.
- Target distribution calibration reduces the pull toward average scores that arises from label imbalance.
- Foundation models anchored by semantic templates extract more trait-relevant information than generic multimodal encoders.
Where Pith is reading between the lines
- The same per-output asymmetric selection pattern could be tested in other multimodal regression tasks where different output dimensions rely on different input cues, such as multi-attribute emotion or mental-health scoring.
- If trait-specific modality preferences prove stable, psychological measurement instruments might be redesigned to weight behavioral channels differently per trait.
- Generalization checks on datasets outside the AVI 2026 challenge would test whether the reported gains depend on the particular label distribution or annotation protocol of that competition.
Load-bearing premise
Different personality dimensions are revealed through distinct behavioral perspectives and uniform fusion creates cross-modal interference that asymmetric selection can reduce without introducing new biases or overfitting.
What would settle it
If a re-run on the AVI Challenge 2026 test set or an independent behavioral dataset shows that the trait-specific asymmetric method yields no MSE improvement over a uniform-fusion baseline, the claim that asymmetric fusion reduces interference would be falsified.
Figures
read the original abstract
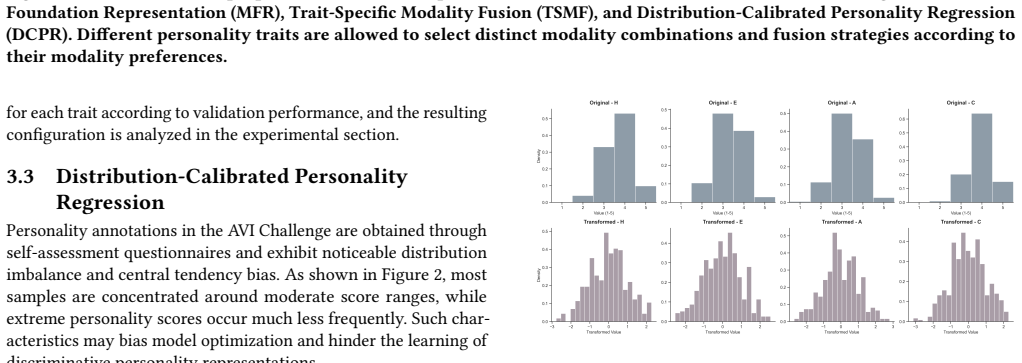
Personality assessment aims to infer stable personality traits from dynamic behaviors across language, voice, and facial cues. Since different personality dimensions are revealed through distinct behavioral perspectives, modeling trait-specific evidence is challenging. However, most existing approaches adopt a uniform multimodal fusion strategy across all dimensions, assuming identical modality contributions. This overlooks trait-specific modality preferences and introduces cross-modal interference. To address this issue, we propose a novel personality assessment framework called Traits Run Deeper, which consists of three components. Specifically, the Multimodal Foundation Representation (MFR) module constructs personality-oriented multimodal inputs and leverages psychology-informed semantic templates as anchors, enabling foundation models to capture trait-relevant information. Building upon MFR, the Trait-Specific Modality Fusion (TSMF) module acts as an asymmetric fusion mechanism, allowing each dimension to selectively exploit different modality pathways from modality-specific modeling to complementary fusion. Thus, TSMF captures heterogeneous modality preferences while reducing cross-modal contamination. Furthermore, the Distribution-Calibrated Personality Regression (DCPR) module mitigates label imbalance and central tendency bias through target distribution calibration, improving robustness and stability. Experimental results on the AVI Challenge 2026 validation set demonstrate the effectiveness of the proposed framework, reducing mean squared error (MSE) by approximately 25% compared with the baseline. Consistent improvements are observed on the official test set, where our method achieves the best performance and ranks first in the Personality Assessment Track. The source code will be made available at https://github.com/MSA-LMC/AVI2026.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the 'Traits Run Deeper' framework for inferring Big-Five personality traits from multimodal behavioral data (language, voice, face). It introduces three modules: Multimodal Foundation Representation (MFR) that builds psychology-informed semantic templates as anchors for foundation models; Trait-Specific Modality Fusion (TSMF) that performs asymmetric, trait-dependent fusion across modality pathways; and Distribution-Calibrated Personality Regression (DCPR) that corrects label imbalance and central-tendency bias. On the AVI Challenge 2026 validation set the method reportedly reduces MSE by ~25% relative to a baseline; on the official test set it ranks first in the Personality Assessment Track. Source code is promised at a GitHub repository.
Significance. If the performance gains are shown to stem specifically from the trait-specific asymmetric pathways rather than from foundation-model scaling or challenge tuning, the work would offer a concrete mechanism for reducing cross-modal interference in personality assessment. The promised code release supports reproducibility. The central claim, however, rests on an untested attribution of the observed MSE reduction to TSMF.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experimental Results): the 25% MSE reduction and first-place ranking are presented without any ablation that replaces TSMF with a uniform/shared fusion module while keeping MFR and DCPR fixed; therefore the claim that asymmetric fusion 'reduces cross-modal contamination' is not isolated from the contributions of the other two modules or from possible leaderboard tuning.
- [§3.2] §3.2 (TSMF description): the statement that each trait 'selectively exploit[s] different modality pathways' is not accompanied by any reported per-trait modality weights, attention maps, or quantitative interference metric (e.g., mutual information between modalities before/after fusion), leaving the mechanistic premise unverified.
- [§4] §4 and Table 2 (if present): no statistical significance tests, confidence intervals, or error bars are mentioned for the reported MSE values, making it impossible to assess whether the observed improvement exceeds run-to-run variance on the challenge data.
minor comments (1)
- [Abstract] The abstract states that source code 'will be made available' but does not provide a permanent DOI or commit hash; this should be updated before publication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): the 25% MSE reduction and first-place ranking are presented without any ablation that replaces TSMF with a uniform/shared fusion module while keeping MFR and DCPR fixed; therefore the claim that asymmetric fusion 'reduces cross-modal contamination' is not isolated from the contributions of the other two modules or from possible leaderboard tuning.
Authors: We agree that an explicit ablation isolating TSMF is needed to attribute gains specifically to the asymmetric fusion. In the revised manuscript we will add this ablation on the validation set, replacing TSMF with a uniform/shared fusion module while holding MFR and DCPR fixed, and report the resulting MSE to quantify TSMF's isolated contribution. revision: yes
-
Referee: [§3.2] §3.2 (TSMF description): the statement that each trait 'selectively exploit[s] different modality pathways' is not accompanied by any reported per-trait modality weights, attention maps, or quantitative interference metric (e.g., mutual information between modalities before/after fusion), leaving the mechanistic premise unverified.
Authors: We will add per-trait modality weights and attention coefficients from the TSMF module to the revised §3.2 and §4. We will also report a quantitative interference metric (reduction in cross-modal mutual information after fusion) to verify the selective exploitation and reduced contamination claim. revision: yes
-
Referee: [§4] §4 and Table 2 (if present): no statistical significance tests, confidence intervals, or error bars are mentioned for the reported MSE values, making it impossible to assess whether the observed improvement exceeds run-to-run variance on the challenge data.
Authors: We agree that statistical rigor is required. In the revision we will report error bars from multiple independent runs, 95% confidence intervals, and p-values from paired statistical tests (e.g., t-test) on the validation MSE values to demonstrate that improvements exceed run-to-run variance. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an empirical multimodal framework (MFR + TSMF + DCPR) whose central claims rest on reported MSE reductions and test-set ranking on an external AVI Challenge 2026 dataset. No equations, derivations, fitted-parameter predictions, self-citations, or ansatzes appear in the provided text that reduce any result to its own inputs by construction. The method description is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Different personality dimensions are revealed through distinct behavioral perspectives from language, voice, and facial cues.
Reference graph
Works this paper leans on
-
[1]
Michael C Ashton and Kibeom Lee. 2009. The HEXACO–60: A short measure of the major dimensions of personality.Journal of personality assessment91, 4 (2009), 340–345
2009
-
[2]
Süleyman Aslan, Uğur Güdükbay, and Hamdi Dibeklioğlu. 2021. Multimodal assessment of apparent personality using feature attention and error consistency constraint.Image Vis. Comput.110 (2021), 104163. https://api.semanticscholar. org/CorpusID:233657208
2021
-
[3]
Barrick and Michael K
Murray R. Barrick and Michael K. Mount. 1991. THE BIG FIVE PERSONAL- ITY DIMENSIONS AND JOB PERFORMANCE: A META-ANALYSIS.Personnel Psychology44 (1991), 1–26. https://api.semanticscholar.org/CorpusID:144689146
1991
-
[4]
Hyeonuk Bhin and Jongsuk Choi. 2025. Multimodal Personality Recognition Using Self-Attention-Based Fusion of Audio, Visual, and Text Features.Electronics 14, 14 (2025). doi:10.3390/electronics14142837
-
[5]
Oya Celiktutan and Hatice Gunes. 2017. Automatic Prediction of Impressions in Time and across Varying Context: Personality, Attractiveness and Likeability. IEEE Trans. Affect. Comput.8, 1 (Jan. 2017), 29–42. doi:10.1109/TAFFC.2015. 2513401
-
[6]
Yin Chen, Jia Li, Yu Zhang, Zhenzhen Hu, Shiguang Shan, Meng Wang, and Richang Hong. 2025. Static for Dynamic: Towards a Deeper Understanding of Dynamic Facial Expressions Using Static Expression Data.IEEE Transactions on Affective Computing(2025), 1–15. doi:10.1109/TAFFC.2025.3623135
-
[7]
Hao Cheng, Zhiwei Zhao, Yichao He, Zhenzhen Hu, Jia Li, Meng Wang, and Richang Hong. 2025. Vaemo: Efficient representation learning for visual-audio emotion with knowledge injection. InProceedings of the 33rd ACM International Conference on Multimedia. 5547–5556
2025
-
[8]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tai, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Web- son, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping...
2024
-
[9]
Jizhou Cui, Hanzhe Xu, Xuefei Liu, Zheng Lian, Zhengqi Wen, Heng Xie, Ruibo Fu, Yukun Liu, and Jianhua Tao. 2025. Less is More? Textual-Only Language Model for AVI challenge 2025. InProceedings of the 3rd International Workshop on Multimodal and Responsible Affective Computing. 69–74
2025
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy...
2019
-
[11]
Hugo Jair Escalante, Isabelle M Guyon, Sergio Escalera, Julio C. S. Jacques Junior, Meysam Madadi, Xavier Baró, S. Ayache, Evelyne Viegas, Yağmur Güçlütürk, Umut Güçlü, Marcel van Gerven, and Robert van Lier. 2017. Design of an explainable machine learning challenge for video interviews.2017 Interna- tional Joint Conference on Neural Networks (IJCNN)(2017...
2017
-
[12]
Gir- shick
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll’ar, and Ross B. Gir- shick. 2021. Masked Autoencoders Are Scalable Vision Learners.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2021), 15979– 15988. https://api.semanticscholar.org/CorpusID:243985980
2021
-
[13]
Oliver John. 1999. The Big-Five trait taxonomy: History, measurement, and theoretical perspectives.Published as(1999)
1999
-
[14]
Jinhyuk Lee, Feiyang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, Gustavo Hernández Ábrego, Zhe Li, Kaifeng Chen, Henrique Schechter Vera, Xiaoqi Ren, Shanfeng Zhang, Daniel Salz, Michael Boratko, Jay Han, Blair Chen, Shuo Huang, Vikram Rao, Paul Suganthan, Feng Han, Andreas Doumanoglou, Nithi Gupta, Fedor Moiseev, Cathy Yip, Aashi Jain...
Pith/arXiv arXiv 2025
-
[15]
Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R. Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, Yi Luan, Sai Meher Karthik Duddu, Gustavo Hernández Abrego, Wei Shi, Nithi Gupta, Aditya Kusupati, Pra- teek Jain, Siddhartha R. Jonnalagadda, Ming-Wei Chang, and Iftekhar Naim. 2024. Gecko: Versatile Text Embeddings Distilled fr...
arXiv 2024
-
[16]
Jia Li, Yichao He, Jiacheng Xu, Tianhao Luo, Zhenzhen Hu, Richang Hong, and Meng Wang. 2025. Traits Run Deep: Enhancing Personality Assessment via Psychology-Guided LLM Representations and Multimodal Apparent Behaviors. InProceedings of the 33rd ACM International Conference on Multimedia. 13901– 13908
2025
-
[17]
Rongfan Liao, Siyang Song, and Hatice Gunes. 2024. An Open-Source Bench- mark of Deep Learning Models for Audio-Visual Apparent and Self-Reported Personality Recognition.IEEE Trans. Affect. Comput.15, 3 (July 2024), 1590–1607. doi:10.1109/TAFFC.2024.3363710
-
[18]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692 [cs.CL] https://arxiv.org/abs/1907.11692
Pith/arXiv arXiv 2019
-
[19]
Ziyang Ma, Zhisheng Zheng, Jiaxin Ye, Jinchao Li, Zhifu Gao, ShiLiang Zhang, and Xie Chen. 2024. emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thaila...
-
[20]
Walker, Matthias R
François Mairesse, Marilyn A. Walker, Matthias R. Mehl, and Roger K. Moore. 2007. Using linguistic cues for the automatic recognition of personality in conversation and text.J. Artif. Int. Res.30, 1 (Nov. 2007), 457–500
2007
-
[21]
Ryo Masumura, Shota Orihashi, Mana Ihori, Tomohiro Tanaka, Naoki Mak- ishima, Satoshi Suzuki, Saki Mizuno, and Nobukatsu Hojo. 2025. Multimodal fine-grained apparent personality trait recognition: Joint modeling of big five and questionnaire item-level scores. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 1456–1464
2025
-
[22]
Tao Ning, Zhenghua Guo, and Qidong Hou. 2026. A DLF multi-scale quantitative research method for the big five personality traits.Scientific Reports16 (2026). https://api.semanticscholar.org/CorpusID:284474095
2026
-
[23]
OpenAI. 2024. text-embedding-3-small. Retrieved June 6, 2026 from https: //developers.openai.com/api/docs/models/text-embedding-3-small
2024
-
[24]
Hadjileontiadis, Alice H
Cheul Young Park, Narae Cha, Soowon Kang, Auk Kim, Ahsan Habib Khandoker, Leontios J. Hadjileontiadis, Alice H. Oh, Yong Jeong, and Uichin Lee. 2020. K- EmoCon, a multimodal sensor dataset for continuous emotion recognition in naturalistic conversations.Scientific Data7 (2020). https://api.semanticscholar. org/CorpusID:218571336
2020
-
[25]
S. V. Paunonen and Michael C Ashton. 2001. Big five factors and facets and the prediction of behavior.Journal of personality and social psychology81 3 (2001), 524–39. https://api.semanticscholar.org/CorpusID:30756422
2001
-
[26]
Pennebaker and Laura A
James W. Pennebaker and Laura A. King. 1999. Linguistic styles: language use as an individual difference.Journal of personality and social psychology77 6 (1999), 1296–312. https://api.semanticscholar.org/CorpusID:29567532
1999
-
[27]
Heinrich Peters and Sandra C. Matz. 2023. Large language models can infer psychological dispositions of social media users.PNAS Nexus3 (2023). https: //api.semanticscholar.org/CorpusID:262043671
2023
-
[28]
Hai Pham, Paul Pu Liang, Thomas Manzini, Louis philippe Morency, and Barnabás Póczos. 2018. Found in Translation: Learning Robust Joint Representations by Cyclic Translations Between Modalities.ArXivabs/1812.07809 (2018). https: //api.semanticscholar.org/CorpusID:53500027
arXiv 2018
-
[29]
Víctor Ponce-López, Baiyu Chen, Marc Oliu, Ciprian Corneanu, Albert Clapés, Isabelle Guyon, Xavier Baró, Hugo Jair Escalante, and Sergio Escalera. 2016. Chalearn lap 2016: First round challenge on first impressions-dataset and results. InEuropean conference on computer vision. Springer, 400–418
2016
-
[30]
Víctor Ponce-López, Baiyu Chen, Marc Oliu, Ciprian Adrian Corneanu, Albert Clapés, Isabelle M Guyon, Xavier Baró, Hugo Jair Escalante, and Sergio Escalera
-
[31]
InECCV Workshops
ChaLearn LAP 2016: First Round Challenge on First Impressions - Dataset and Results. InECCV Workshops. https://api.semanticscholar.org/CorpusID: 39164174
2016
-
[32]
Ricardo Dario Perez Principi, Cristina Palmero, Julio C. S. Jacques Junior, and Sergio Escalera. 2021. On the Effect of Observed Subject Biases in Apparent Personality Analysis From Audio-Visual Signals .IEEE Transactions on Affective Computing12, 03 (July 2021), 607–621. doi:10.1109/TAFFC.2019.2956030
-
[33]
Puetz, Jens U
Noah C. Puetz, Jens U. Brandt, Marc Hilbert, Elena Raponi, Thomas Bäck, and Thomas Bartz-Beielstein. 2026. Deconstructing deep imbalance regression: a comprehensive review and experimental evaluation.Artificial Intelligence Review (2026). https://api.semanticscholar.org/CorpusID:287705337
2026
-
[34]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision.ArXivabs/2103.00020 (2021). https://api. semanticscholar.org/CorpusID:231591445
Pith/arXiv arXiv 2021
-
[35]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine Mcleavey, and Ilya Sutskever. 2023. Robust Speech Recognition via Large-Scale Weak Super- vision. InProceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brun- skill, Kyunghyun Cho, Barbara Engelhardt, Siv...
2023
-
[36]
Jiawei Ren, Mingyuan Zhang, Cunjun Yu, and Ziwei Liu. 2022. Balanced MSE for Imbalanced Visual Regression.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2022), 7916–7925. https://api.semanticscholar. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Jia Li, Qian Chen, Wei Wang, Xinyu Li, Zhenzhen Hu, Dongsheng Shao, Richa...
2022
-
[37]
Elena Ryumina, Maxim Markitantov, Dmitry Ryumin, and Alexey Karpov. 2024. Gated Siamese Fusion Network based on multimodal deep and hand-crafted features for personality traits assessment.Pattern Recognition Letters185 (2024), 45–51
2024
-
[38]
Madhuri Shanbhogue, Zhe Li, Shanfeng Zhang, Gustavo Hernández Ábrego, Shih-Cheng Huang, Aashi Jain, Daniel Salz, Sonam Goenka, Chaitra Hegde, Ji Ma, Feiyang Chen, Jiaxing Wu, Tanmaya Dabral, Babak Samari, Kevin Poulet, Daniel Cer, Kaifeng Chen, Paul Suganathan, Hui Hui, Jovan Andonov, Philippe Schlat- tner, Jay Han, Iftekhar Naim, Wing Lowe, Vladimir Pche...
Pith/arXiv arXiv 2026
-
[39]
Hao Tan and Mohit Bansal. 2019. LXMERT: Learning Cross-Modality Encoder Representations from Transformers. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (Eds.). Associati...
-
[40]
Alessandro Vinciarelli and Gelareh Mohammadi. 2014. A Survey of Personality Computing.IEEE Transactions on Affective Computing5 (2014), 273–291. https: //api.semanticscholar.org/CorpusID:14688441
2014
-
[41]
Jialou Wang, Honglei Li, Wai Lok Woo, and Shan Shan. 2024. A single modality apparent first impression personality recognition model with temporal emotion based LSTM.Expert Syst. Appl.259 (2024), 125114. https://api.semanticscholar. org/CorpusID:272129536
2024
-
[42]
Longjiang Yang, Cong Yu, Chenxi Huang, Fengyu Zhang, Ran Liu, Zhuofan Wen, Shun Chen, Hailiang Yao, Bin Liu, Zheng Lian, et al. 2025. Enhancing Multimodal Personality Assessment with LLM-Augmented Hierarchical Fusion. InProceedings of the 33rd ACM International Conference on Multimedia. 13917–13923
2025
-
[43]
In-Kwon Yeo and Richard A. Johnson. 2000. A new family of power transforma- tions to improve normality or symmetry.Biometrika87, 4 (12 2000), 954–959. arXiv:https://academic.oup.com/biomet/article-pdf/87/4/954/633221/870954.pdf doi:10.1093/biomet/87.4.954
-
[44]
Chen-Lin Zhang, Hao Zhang, Xiu-Shen Wei, and Jianxin Wu. 2016. Deep Bimodal Regression for Apparent Personality Analysis. InECCV Workshops. https://api. semanticscholar.org/CorpusID:26959563
2016
-
[45]
Tianyi Zhang, Tianhua Qi, Reinout E de Vries, Wenming ZHENG, Janneke Oost- rom, Djurre Holtrop, Yuan Zong, and Antonios Koutsoumpis. [n. d.]. AVI Chal- lenge 2026: Assessing True Personality Traits and Cognitive Ability from Asyn- chronous Video Interviews (AVIs). ([n. d.])
2026
-
[46]
Yi Zhang, Mingyuan Chen, Jundong Shen, and Chongjun Wang. 2022. Tailor Versatile Multi-modal Learning for Multi-label Emotion Recognition.ArXiv abs/2201.05834 (2022). https://api.semanticscholar.org/CorpusID:246015645
arXiv 2022
-
[47]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[48]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
Pith/arXiv arXiv 2025
-
[49]
Xiaoming Zhao, Yuehui Liao, Zhiwei Tang, Yicheng Xu, Xin Tao, Dandan Wang, Guoyu Wang, and Hongsheng Lu. 2023. Integrating audio and visual modalities for multimodal personality trait recognition via hybrid deep learning.Frontiers in Neuroscience16 (2023), 1107284
2023
-
[50]
Xiaoming Zhao, Zhiwei Tang, and Shiqing Zhang. 2022. Deep Personality Trait Recognition: A Survey.Frontiers in Psychology13 (2022). https://api. semanticscholar.org/CorpusID:248530069
2022
-
[51]
Weiyao Zhu, Ou Wu, and Nan Yang. 2024. IRDA: Implicit data augmenta- tion for deep imbalanced regression.Inf. Sci.677 (2024), 120873. https: //api.semanticscholar.org/CorpusID:270319009
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.