SkillJuror: Measuring How Agent Skill Organization Changes Runtime Behavior
Pith reviewed 2026-06-27 10:09 UTC · model grok-4.3
The pith
Progressive Disclosure organizes agent skills so agents touch more resources and pass more trials than flat files.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
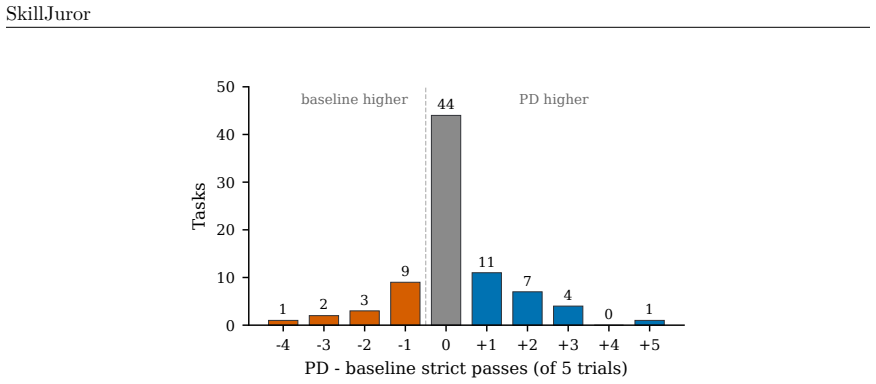
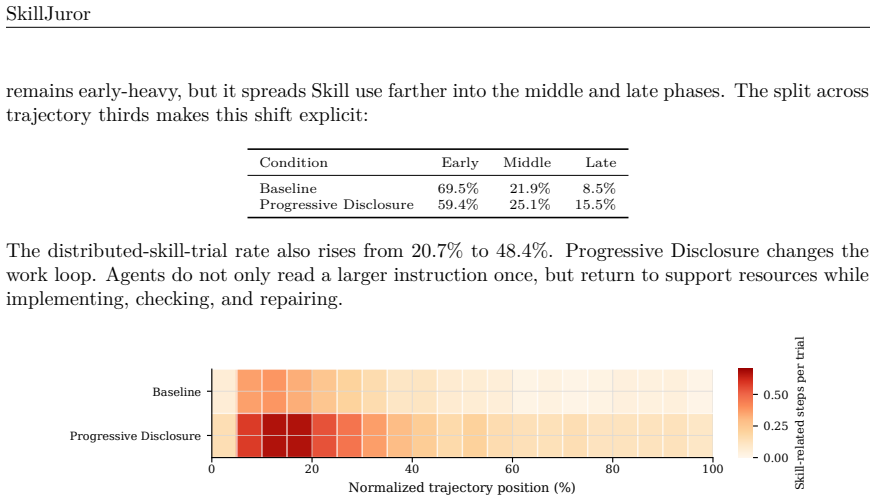
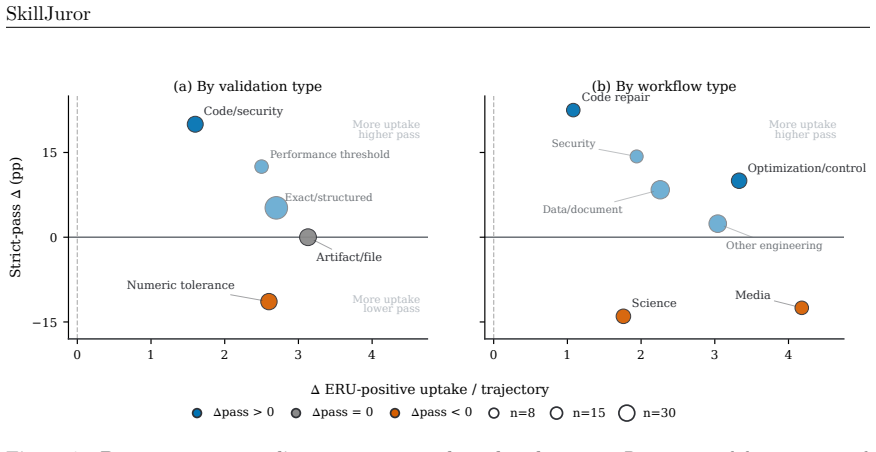
Progressive Disclosure changes runtime behavior before aggregate outcomes: distinct Skill resources touched per trajectory rise from 1.18 to 3.85, effective uptake events rise from 1.33 to 3.92, and it yields 17 additional verifier-passing trials out of 410 matched trials (+4.1%) over the normalized flat baseline. The benefit is task-dependent. Progressive Disclosure helps when supporting resources guide implementation, checking, or repair, but is weaker when success hinges on exact output conventions, numerical thresholds, or long artifact-generation pipelines.
What carries the argument
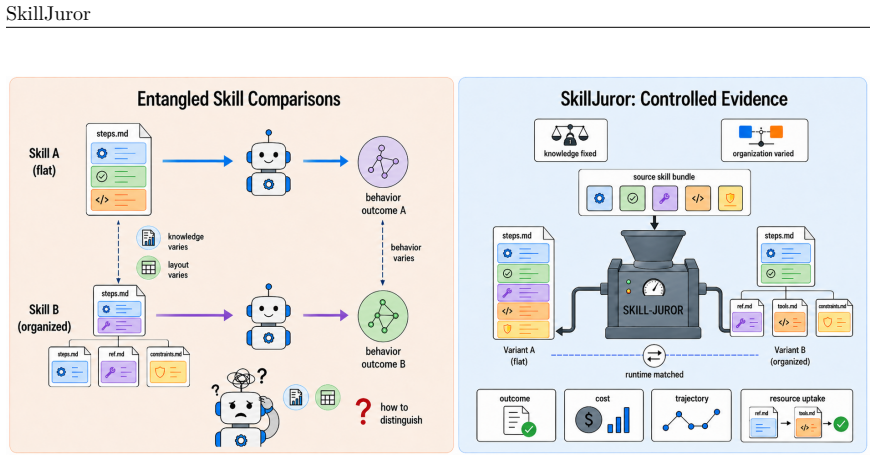
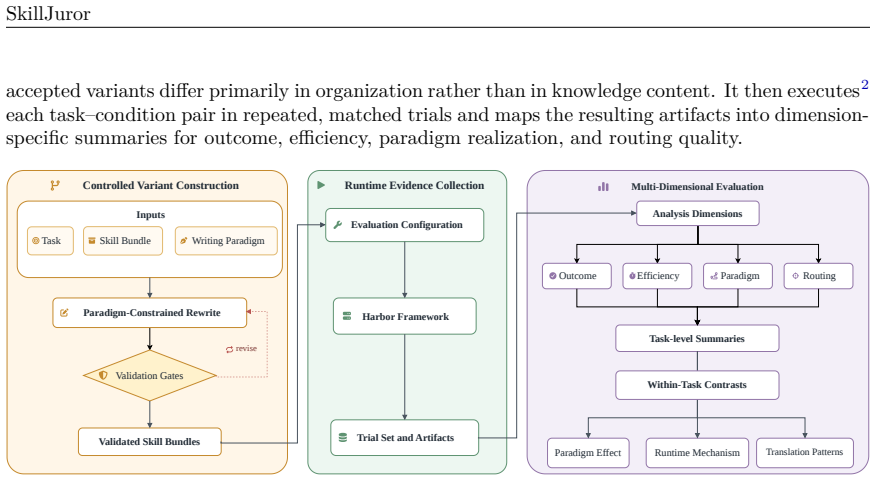
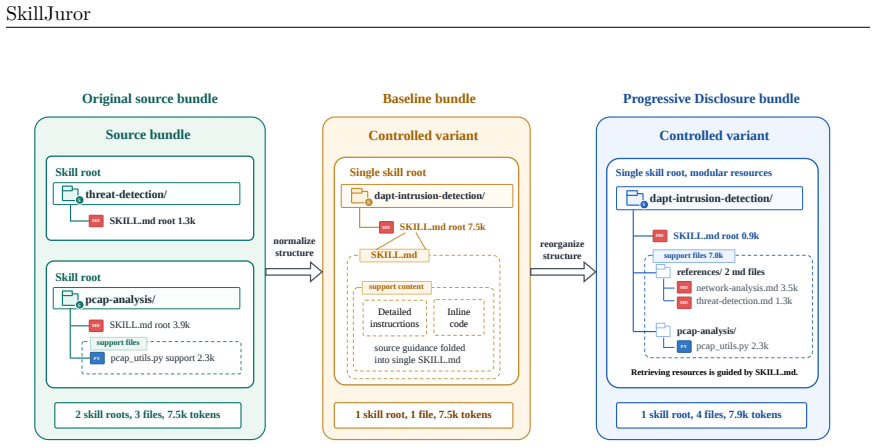
Progressive Disclosure, a skill-writing method in which a concise root file directs agents to supporting resources on demand, measured against a normalized flat baseline inside the SkillJuror framework that uses semantically controlled variants and trajectory logging.
If this is right
- Runtime behavior changes appear before any measurable gain in final task outcomes.
- Progressive Disclosure improves results mainly on tasks where supporting files can guide implementation, checking, or repair steps.
- Skill organization directly influences the search and application patterns agents follow during execution.
- Outcome improvements require that the newly exposed resources are actionable for the given task.
Where Pith is reading between the lines
- Skill writers could test modular disclosure first on tasks that require dynamic guidance rather than fixed output formats.
- Benchmarks that record only final answers will miss most of the behavioral effect shown here.
- The same organization contrast could be run on non-LLM agents to test whether the uptake pattern depends on language-model reasoning.
- Task-dependent results suggest hybrid skill files that adapt their disclosure depth to the problem type.
Load-bearing premise
The controlled variants truly separate organization effects from differences in the knowledge itself, and the logs correctly record when an agent has used a resource rather than merely opened the file.
What would settle it
A matched-trial replication that finds no rise in the number of distinct resources touched or uptake events under Progressive Disclosure would show that organization does not change runtime behavior.
Figures

read the original abstract
Agent Skills augment large language model (LLM) agents with procedural knowledge at inference time, but current benchmarks rarely distinguish what a Skill says from how it is organized. We study this distinction through Progressive Disclosure, where a concise root file points agents to supporting resources on demand, and compare it with a normalized flat baseline. We present SkillJuror, a framework for evaluating Skill writing paradigms through semantically controlled variants, matched multi-trial evaluations, and trajectory evidence while holding task knowledge fixed. In an 82-task SkillsBench study, Progressive Disclosure changes runtime behavior before aggregate outcomes: distinct Skill resources touched per trajectory rise from 1.18 to 3.85, and effective uptake events rise from 1.33 to 3.92. It also yields 17 additional verifier-passing trials out of 410 matched trials (+4.1%) over the normalized flat baseline. The benefit is task-dependent. Progressive Disclosure helps when supporting resources guide implementation, checking, or repair, but is weaker when success hinges on exact output conventions, numerical thresholds, or long artifact-generation pipelines. These results show that Skill organization is not mere presentation: it can change how agents search and apply procedural knowledge, while outcome gains depend on whether the exposed resources are actionable for the task. Code is available at https://github.com/zhiyuchen-ai/skill-juror.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillJuror, a framework using semantically controlled variants, matched multi-trial evaluations, and trajectory logging to compare Progressive Disclosure (concise root file pointing to resources on demand) against a normalized flat baseline on an 82-task SkillsBench. It reports that Progressive Disclosure increases distinct Skill resources touched per trajectory from 1.18 to 3.85 and effective uptake events from 1.33 to 3.92, yielding 17 additional verifier-passing trials out of 410 matched trials (+4.1%), with task-dependent benefits (stronger when resources guide implementation/checking/repair).
Significance. If the measurements hold, the work provides concrete empirical evidence that Skill organization affects agent search/apply behavior and modestly improves outcomes independently of content, with code release aiding reproducibility. This distinguishes organization effects from content and highlights when disclosure helps versus when exact conventions or long pipelines dominate.
major comments (2)
- [Trajectory logging subsection (Methods)] Trajectory logging subsection (Methods): the definitions of 'distinct Skill resources touched' and 'effective uptake events' must specify the parser criteria. If counters increment on any file reference/read rather than requiring evidence of content integration into subsequent reasoning, code, or outputs, the reported rises (1.18→3.85; 1.33→3.92) may reflect navigation encouraged by the root pointer rather than genuine organizational effects on knowledge application. This directly threatens the claim that organization changes runtime behavior while holding task knowledge fixed.
- [Results on matched trials (Section 4 or equivalent)] Results on matched trials (Section 4 or equivalent): the +4.1% lift (17/410) lacks reported error bars, confidence intervals, or exclusion criteria for the 410 matched trials. Without these, it is impossible to assess whether post-hoc task filtering or logging definitions affect the central outcome comparison.
minor comments (2)
- The abstract and results should explicitly state whether statistical significance testing was performed on the behavioral deltas and outcome lift.
- Clarify in the variant construction how semantic control was verified to ensure organization is isolated from content differences.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and statistical reporting while defending the core claims on the basis of our trajectory analysis.
read point-by-point responses
-
Referee: [Trajectory logging subsection (Methods)] Trajectory logging subsection (Methods): the definitions of 'distinct Skill resources touched' and 'effective uptake events' must specify the parser criteria. If counters increment on any file reference/read rather than requiring evidence of content integration into subsequent reasoning, code, or outputs, the reported rises (1.18→3.85; 1.33→3.92) may reflect navigation encouraged by the root pointer rather than genuine organizational effects on knowledge application. This directly threatens the claim that organization changes runtime behavior while holding task knowledge fixed.
Authors: We agree that the parser criteria require explicit specification. The current manuscript describes the metrics at a high level but omits the precise implementation details. In revision we will expand the Trajectory logging subsection to include the full parser rules and pseudocode. Distinct Skill resources touched counts only unique files whose content is subsequently referenced in agent reasoning, code, or outputs (via keyword/phrase matching from the resource in later steps). Effective uptake events further require evidence of integration, such as using the disclosed resource to guide implementation, checking, or repair actions. Counters are not incremented on bare file reads or navigation alone. This design isolates organizational effects on knowledge application rather than mere pointer following, consistent with the task-dependent outcome patterns reported. revision: yes
-
Referee: [Results on matched trials (Section 4 or equivalent)] Results on matched trials (Section 4 or equivalent): the +4.1% lift (17/410) lacks reported error bars, confidence intervals, or exclusion criteria for the 410 matched trials. Without these, it is impossible to assess whether post-hoc task filtering or logging definitions affect the central outcome comparison.
Authors: We acknowledge the omission of statistical details. In the revised manuscript we will report Wilson score confidence intervals around the per-condition success rates and the 17/410 difference. The 410 matched trials are defined as all trials in which both conditions completed without execution or logging failures; we will explicitly list the exclusion criteria (incomplete trajectories, verifier crashes, etc.) and confirm that no post-hoc task filtering beyond these objective criteria was applied. We will also note the modest overall effect size and its concentration in specific task categories, allowing readers to evaluate robustness directly. revision: yes
Circularity Check
No circularity: purely empirical comparison with explicit baseline
full rationale
The paper reports direct experimental measurements (resources touched 1.18→3.85, uptake events 1.33→3.92, +4.1% verifier passes) from matched trials on SkillsBench using Progressive Disclosure vs. normalized flat baseline. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes appear in the abstract or described claims. Trajectory logging and semantic controls are presented as measurement methods, not derivations that reduce to their own inputs. The evaluation is self-contained against the stated flat baseline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
16 SkillJuror Mehmet Hamza Erol, Batu El, Mirac Suzgun, Mert Yuksekgonul, and James Zou
Anthropic Engi- neering Blog. 16 SkillJuror Mehmet Hamza Erol, Batu El, Mirac Suzgun, Mert Yuksekgonul, and James Zou. Cost-of-pass: An economic framework for evaluating language models.arXiv preprint arXiv:2504.13359,
-
[2]
Shengda Fan, Xuyan Ye, Yupeng Huo, Zhi-Yuan Chen, Yiju Guo, Shenzhi Yang, Wenkai Yang, Shuqi Ye, Jingwen Chen, Haotian Chen, et al. Agentprocessbench: Diagnosing step-level process quality in tool-using agents.arXiv preprint arXiv:2603.14465,
-
[3]
Tingxu Han, Yi Zhang, Wei Song, Chunrong Fang, Zhenyu Chen, Youcheng Sun, and Lijie Hu. Swe-skills-bench: Do agent skills actually help in real-world software engineering?arXiv preprint arXiv:2603.15401,
-
[4]
Pengfei He, Zhenwei Dai, Bing He, Hui Liu, Xianfeng Tang, Hanqing Lu, Juanhui Li, Jiayuan Ding, Subhabrata Mukherjee, Suhang Wang, et al. Traject-bench: A trajectory-aware benchmark for evaluating agentic tool use.arXiv preprint arXiv:2510.04550,
-
[5]
Wonjoong Kim, Sangwu Park, Yeonjun In, Sein Kim, Dongha Lee, and Chanyoung Park. Beyond the final answer: Evaluating the reasoning trajectories of tool-augmented agents.arXiv preprint arXiv:2510.02837,
-
[6]
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670,
-
[7]
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460,
-
[8]
Skillgen: Verified inference-time agent skill synthesis.arXiv preprint arXiv:2605.10999,
Yuchen Ma, Yue Huang, Han Bao, Haomin Zhuang, Swadheen Shukla, Michel Galley, Xiangliang Zhang, and Stefan Feuerriegel. Skillgen: Verified inference-time agent skill synthesis.arXiv preprint arXiv:2605.10999,
-
[9]
Qirui Mi, Zhijian Ma, Mengyue Yang, Haoxuan Li, Yisen Wang, Haifeng Zhang, and Jun Wang. Skill-pro: Learning reusable skills from experience via non-parametric ppo for llm agents.arXiv preprint arXiv:2602.01869,
-
[10]
Quantifying language models’ sensitivity tospuriousfeaturesinpromptdesignor: Howilearnedtostartworryingaboutpromptformatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity tospuriousfeaturesinpromptdesignor: Howilearnedtostartworryingaboutpromptformatting. InInternational Conference on Learning Representations, volume 2024, pp. 25055–25083,
2024
-
[11]
Hongwen Song et al. More skills, worse agents? skill shadowing degrades performance when ex- panding skill libraries.arXiv preprint arXiv:2605.24050,
-
[12]
17 SkillJuror Yifan Song, Weimin Xiong, Dawei Zhu, Wenhao Wu, Han Qian, Mingbo Song, Hailiang Huang, Cheng Li, Ke Wang, Rong Yao, et al. Restgpt: Connecting large language models with real-world restful apis.arXiv preprint arXiv:2306.06624,
-
[13]
Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
-
[14]
Large language models as optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InInternational Conference on Learning Representations, volume 2024, pp. 12028–12068,
2024
-
[15]
Skillopt: Executive strategy for self-evolving agent skills.arXiv preprint arXiv:2605.23904,
Yifan Yang, Ziyang Gong, Weiquan Huang, Qihao Yang, Ziwei Zhou, Zisu Huang, Yan Li, Xuemei Gao, Qi Dai, Bei Liu, et al. Skillopt: Executive strategy for self-evolving agent skills.arXiv preprint arXiv:2605.23904,
-
[16]
Shanshan Zhong, Yi Lu, Jingjie Ning, Yibing Wan, Lihan Feng, Yuyi Ao, Leonardo FR Ribeiro, Markus Dreyer, Sean Ammirati, and Chenyan Xiong. Skilllearnbench: Benchmarking continual learning methods for agent skill generation on real-world tasks.arXiv preprint arXiv:2604.20087,
-
[17]
Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, et al. Externalization in llm agents: A unified review of memory, skills, protocols and harness engineering.arXiv preprint arXiv:2604.08224, 2026a. Yifan Zhou, Zhentao Zhang, Ziming Cheng, Shuo Zhang, Qizhen Lan, Zhangquan Chen, Zh...
-
[18]
The ERU- rate denominator excludes unknown events
21 SkillJuror Table 13: ERU raw counts.Mean columns divide by all 410 trajectories in each condition. The ERU- rate denominator excludes unknown events. Condition Traj. Events Yes No Unk. ERU rate Mean events Mean yes Baseline 410 717 545 172 0 76.0% 1.75 1.33 Progressive Disclosure 410 1902 1609 292 1 84.6% 4.64 3.92 Table 14: ERU-positive trajectory inc...
1902
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.