Teaching Diffusion to Speculate Left-to-Right
Pith reviewed 2026-06-27 10:04 UTC · model grok-4.3
The pith
Three training interventions for diffusion drafters close the bidirectional-to-left-to-right gap and raise accepted speculative length by 21-76%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
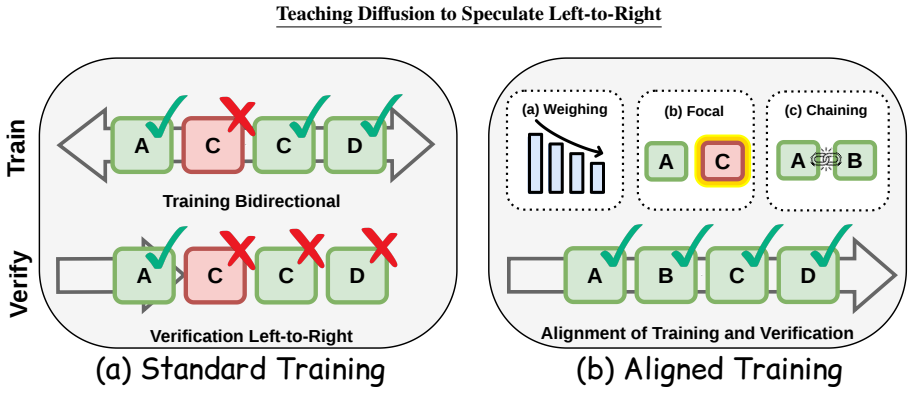
Diffusion drafters generate tokens symmetrically inside each block during training, yet verification by an autoregressive target model scores them sequentially from left to right; the resulting gap is narrowed by three orthogonal losses—positional weighting that emphasizes earlier tokens, focal loss on the first position that breaks the accepted prefix, and a differentiable chain-loss surrogate for expected accepted length—producing drafts that survive more verification steps and yield 21-76% longer accepted sequences on average.
What carries the argument
The three training-time interventions (token positional weighting, first-error focal loss, chain loss term) that act on position, block-conditional first error, and joint prefix axes respectively.
If this is right
- The three interventions compose additively with one another.
- They remain orthogonal to test-time mechanisms such as multi-draft self-selection.
- Gains appear across four target models and six reasoning, code, and dialogue benchmarks.
- No extra forward passes are introduced at inference time.
- The exactness contract of rejection sampling stays unchanged.
Where Pith is reading between the lines
- The same training-verification mismatch may limit other non-autoregressive drafting approaches beyond diffusion.
- The chain loss formulation could be adapted to optimize directly for accepted length in additional block-generation settings.
- Testing whether the positional weighting schedule transfers to different block sizes would clarify its generality.
Load-bearing premise
The main performance gap comes from the training-verification mismatch, and the three losses close it without degrading draft quality or creating new biases that would shrink gains on new data.
What would settle it
Retraining a diffusion drafter with the three losses and measuring accepted length on a held-out benchmark; if the increase over the position-uniform baseline falls below the reported range or vanishes when the target model changes, the central claim would be falsified.
Figures

read the original abstract
Large language models (LLMs) achieve remarkable performance across a wide range of tasks, but their autoregressive decoding process incurs substantial inference costs due to inherently sequential token generation. Speculative decoding addresses this bottleneck by employing a lightweight draft model to propose multiple future tokens that are subsequently verified in parallel by a larger target model. Recent work has demonstrated that diffusion language models are well suited for this setting, as they can generate entire blocks of draft tokens in parallel and thereby alleviate the sequential constraints of autoregressive drafting. A subtlety of this regime is that block-diffusion drafters generate tokens bidirectionally within a block, whereas verification is performed by an autoregressive target model that evaluates tokens in a strictly left-to-right manner, leaving a gap between the symmetric training-time objective and the asymmetric verification-time reward. In this work, we offer an empirical analysis of three training-time interventions that narrow this gap: token positional weighting, a first-error focal loss that targets the position that breaks the accepted prefix within each block, and a chain loss term that substitutes a differentiable surrogate for the expected accepted length. The three interventions act along orthogonal axes (position, block-conditional first error, joint prefix) and compose additively; they are likewise orthogonal to test-time alignment mechanisms such as multi-draft self-selection, with which they can in principle be combined. Across four target models and six reasoning, code, and dialogue benchmarks, the three interventions raise accepted draft length by 21-76% per benchmark over a position-uniform baseline, without adding additional forward passes and without changing the inference pipeline or the rejection-sampling exactness contract.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that three training interventions for diffusion-based draft models in speculative decoding—token positional weighting, first-error focal loss, and a chain loss surrogate—narrow the gap between bidirectional block training and left-to-right target-model verification. These yield 21-76% higher accepted draft lengths per benchmark across four target models and six tasks, without extra forward passes or changes to the rejection-sampling pipeline.
Significance. If the gains prove robust, the work would provide a practical way to improve speculative decoding efficiency with diffusion drafters by aligning training objectives more closely with verification dynamics. The claimed orthogonality of the interventions to each other and to test-time methods is a notable strength if substantiated.
major comments (2)
- [Abstract] Abstract: The chain loss is described as substituting a differentiable surrogate for expected accepted length, yet no derivation of the surrogate or empirical correlation measurement against actual target-model acceptance decisions (via left-to-right probabilities) is supplied. Because acceptance is governed by the frozen target, imperfect correlation between the surrogate (computed from draft scores) and verified length risks gradients that do not reliably increase accepted length on unseen data.
- [Abstract] Abstract: The reported 21-76% gains are presented as consistent across models and benchmarks, but the text supplies no variance estimates, statistical significance tests, or ablations on random seeds/data splits. This leaves open whether the improvements survive the variability inherent in training and evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and results reporting. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the chain loss and the statistical robustness of the reported gains.
read point-by-point responses
-
Referee: [Abstract] Abstract: The chain loss is described as substituting a differentiable surrogate for expected accepted length, yet no derivation of the surrogate or empirical correlation measurement against actual target-model acceptance decisions (via left-to-right probabilities) is supplied. Because acceptance is governed by the frozen target, imperfect correlation between the surrogate (computed from draft scores) and verified length risks gradients that do not reliably increase accepted length on unseen data.
Authors: We agree that an explicit derivation of the chain-loss surrogate and direct empirical correlation measurements with target-model acceptance decisions would improve clarity and address the concern about gradient reliability. The full manuscript contains the mathematical definition of the surrogate, but we will expand the methods section with a step-by-step derivation and add a new table/figure reporting Pearson/Spearman correlations between surrogate values and verified accepted lengths across all benchmarks and target models. This will also allow us to quantify how closely the surrogate tracks left-to-right verification outcomes. revision: yes
-
Referee: [Abstract] Abstract: The reported 21-76% gains are presented as consistent across models and benchmarks, but the text supplies no variance estimates, statistical significance tests, or ablations on random seeds/data splits. This leaves open whether the improvements survive the variability inherent in training and evaluation.
Authors: We concur that variance estimates, significance testing, and multi-seed ablations are necessary to substantiate robustness. We will augment the results section with per-benchmark standard deviations computed over at least three random seeds, paired statistical significance tests (e.g., Wilcoxon signed-rank), and an ablation table showing performance under different data splits. These additions will be reflected in both the main tables and the abstract summary of gains. revision: yes
Circularity Check
No significant circularity; empirical gains measured on held-out benchmarks
full rationale
The paper proposes three training interventions (positional weighting, first-error focal loss, chain loss surrogate) to align bidirectional diffusion drafting with left-to-right verification. All reported improvements (21-76% accepted draft length) are presented as direct empirical measurements on held-out benchmarks across four target models and six tasks. No equation or claim reduces a prediction to a fitted input by construction, no self-citation is invoked as load-bearing uniqueness, and the chain loss is treated as a surrogate whose value is validated externally rather than assumed identical to the target objective. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2107.03374 , year =
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =
-
[2]
Rozi. Code. arXiv preprint arXiv:2308.12950 , year =
-
[3]
arXiv preprint arXiv:2412.16720 , year =
-
[4]
arXiv preprint arXiv:2501.12948 , year =
-
[5]
Proceedings of Machine Learning and Systems (MLSys) , year =
Efficiently Scaling Transformer Inference , author =. Proceedings of Machine Learning and Systems (MLSys) , year =
-
[6]
Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke , booktitle =
-
[7]
Frantar, Elias and Ashkboos, Saleh and Hoefler, Torsten and Alistarh, Dan , booktitle =
-
[8]
Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Chen, Wei-Ming and Wang, Wei-Chen and Xiao, Guangxuan and Dang, Xingyu and Gan, Chuang and Han, Song , booktitle =
-
[9]
Xiao, Guangxuan and Lin, Ji and Seznec, Mickael and Wu, Hao and Demouth, Julien and Han, Song , booktitle =
-
[10]
Frantar, Elias and Alistarh, Dan , booktitle =
-
[11]
International Conference on Learning Representations (ICLR) , year =
A Simple and Effective Pruning Approach for Large Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[12]
arXiv preprint arXiv:1503.02531 , year =
Distilling the Knowledge in a Neural Network , author =. arXiv preprint arXiv:1503.02531 , year =
-
[13]
Sanh, Victor and Debut, Lysandre and Chaumond, Julien and Wolf, Thomas , journal =
-
[14]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[15]
Dao, Tri , booktitle =
-
[16]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with
-
[17]
Yu, Gyeong-In and Jeong, Joo Seong and Kim, Geon-Woo and Kim, Soojeong and Chun, Byung-Gon , booktitle =
-
[18]
and Ramjee, Ramachandran , journal =
Agrawal, Amey and Panwar, Ashish and Mohan, Jayashree and Kwatra, Nipun and Gulavani, Bhargav S. and Ramjee, Ramachandran , journal =
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Blockwise Parallel Decoding for Deep Autoregressive Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[20]
International Conference on Machine Learning (ICML) , year =
Fast Inference from Transformers via Speculative Decoding , author =. International Conference on Machine Learning (ICML) , year =
-
[21]
arXiv preprint arXiv:2302.01318 , year =
Accelerating Large Language Model Decoding with Speculative Sampling , author =. arXiv preprint arXiv:2302.01318 , year =
-
[22]
Miao, Xupeng and Oliaro, Gabriele and Zhang, Zhihao and Cheng, Xinhao and Wang, Zeyu and Zhang, Zhengxin and Wong, Rae Ying Yee and Zhu, Alan and Yang, Lijie and Shi, Xiaoxiang and Shi, Chunan and Chen, Zhuoming and Arfeen, Daiyaan and Abhyankar, Reyna and Jia, Zhihao , booktitle =
-
[23]
and Chen, Deming and Dao, Tri , booktitle =
Cai, Tianle and Li, Yuhong and Geng, Zhengyang and Peng, Hongwu and Lee, Jason D. and Chen, Deming and Dao, Tri , booktitle =
-
[24]
Break the Sequential Dependency of
Fu, Yichao and Bailis, Peter and Stoica, Ion and Zhang, Hao , booktitle =. Break the Sequential Dependency of
-
[25]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[26]
International Conference on Machine Learning (ICML) , year =
Online Speculative Decoding , author =. International Conference on Machine Learning (ICML) , year =
-
[27]
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , booktitle =
-
[28]
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , journal =
-
[29]
Ankner, Zachary and Parthasarathy, Rishab and Nrusimha, Aniruddha and Rinard, Christopher and Ragan-Kelley, Jonathan and Brandon, William , booktitle =
-
[30]
Du, Cunxiao and Jiang, Jing and Yuanchen, Xu and Wu, Jiawei and Yu, Sicheng and Li, Yongqi and Li, Shengju and Xu, Kai and Nie, Liqiang and Tu, Zhaopeng and You, Yang , booktitle =
-
[31]
Liu, Fangcheng and Tang, Yehui and Liu, Zhenhua and Ni, Yunsheng and Han, Kai and Wang, Yunhe , booktitle =
-
[32]
arXiv preprint arXiv:2408.15766 , year =
Learning Harmonized Representations for Speculative Sampling , author =. arXiv preprint arXiv:2408.15766 , year =
-
[33]
International Conference on Learning Representations (ICLR) , year =
Non-Autoregressive Neural Machine Translation , author =. International Conference on Learning Representations (ICLR) , year =
-
[34]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2018
-
[35]
Ghazvininejad, Marjan and Levy, Omer and Liu, Yinhan and Zettlemoyer, Luke , booktitle =
-
[36]
International Conference on Learning Representations (ICLR) , year =
Step-unrolled Denoising Autoencoders for Text Generation , author =. International Conference on Learning Representations (ICLR) , year =
-
[37]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Structured Denoising Diffusion Models in Discrete State-Spaces , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[38]
, booktitle =
Li, Xiang Lisa and Thickstun, John and Gulrajani, Ishaan and Liang, Percy and Hashimoto, Tatsunori B. , booktitle =
-
[39]
Gong, Shansan and Li, Mukai and Feng, Jiangtao and Wu, Zhiyong and Kong, Lingpeng , booktitle =
-
[40]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Likelihood-Based Diffusion Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[41]
International Conference on Machine Learning (ICML) , year =
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author =. International Conference on Machine Learning (ICML) , year =
-
[42]
arXiv preprint arXiv:2502.09992 , year =
Large Language Diffusion Models , author =. arXiv preprint arXiv:2502.09992 , year =
-
[43]
International Conference on Learning Representations (ICLR) , year =
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[44]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal =. The
-
[45]
2024 , howpublished =
2024
-
[46]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chengyuan and Huang, Chengen and Lv, Chenxuan and others , journal =
-
[47]
Chen, Jian and Liang, Yesheng and Liu, Zhijian , booktitle =
-
[48]
Samarin, Alexander and Krutikov, Sergei and Shevtsov, Anton and Skvortsov, Sergei and Fisin, Filipp and Golubev, Alexander , booktitle =
-
[49]
arXiv preprint arXiv:2604.12989 , year =
Accelerating Speculative Decoding with Block Diffusion Draft Trees , author =. arXiv preprint arXiv:2604.12989 , year =
-
[50]
and Hartvigsen, Thomas and Fioretto, Ferdinando , journal =
Sandler, Jameson and Christopher, Jacob K. and Hartvigsen, Thomas and Fioretto, Ferdinando , journal =
-
[51]
Wu, Tianyu and Yao, Yu and Qi, Zhenting and Zheng, Han and Wang, Zhuohan and Ma, Haoran and Liao, Lawrence and Lakkaraju, Himabindu and Li, Ju and Du, Yilun , journal =
-
[52]
North American Chapter of the Association for Computational Linguistics (NAACL) , year =
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion , author =. North American Chapter of the Association for Computational Linguistics (NAACL) , year =
-
[53]
2025 , howpublished =
Nathawani, Devvrit and. 2025 , howpublished =
2025
-
[54]
Chaudhary, Sahil , year =. Code
-
[55]
International Conference on Learning Representations (ICLR) , year =
Zhou, Yongchao and Lyu, Kaifeng and Rawat, Ankit Singh and Menon, Aditya Krishna and Rostamizadeh, Afshin and Kumar, Sanjiv and Kag. International Conference on Learning Representations (ICLR) , year =
-
[56]
2023 , howpublished =
2023
-
[57]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging
-
[58]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[59]
arXiv preprint arXiv:2108.07732 , year =
Program Synthesis with Large Language Models , author =. arXiv preprint arXiv:2108.07732 , year =
-
[60]
Jain, Naman and Han, King and Gu, Alex and Li, Wen-Ding and Yan, Fanjia and Zhang, Tianjun and Wang, Sida and Solar-Lezama, Armando and Sen, Koushik and Stoica, Ion , journal =
-
[61]
2022 , howpublished =
2022
-
[62]
Li, Shenggui and Zhu, Yikai and Wang, Chao and Yin, Fan and Shi, Shuai and Wang, Yubo and Zhang, Yi and Huang, Yingyi and Zheng, Haoshuai and Zhang, Yineng , year =
-
[63]
2025 , eprint=
TiDAR: Think in Diffusion, Talk in Autoregression , author=. 2025 , eprint=
2025
-
[64]
2026 , eprint=
Efficient-DLM: From Autoregressive to Diffusion Language Models, and Beyond in Speed , author=. 2026 , eprint=
2026
-
[65]
2026 , note =
Nemotron-Labs-Diffusion: A Tri-Mode Language Model Unifying Autoregressive, Diffusion, and Self-Speculation Decoding , author =. 2026 , note =
2026
-
[66]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.