When is Your LLM Steerable?
Pith reviewed 2026-06-27 09:59 UTC · model grok-4.3
The pith
Early hidden states encode enough information to predict whether activation steering will succeed, fail, or over-steer in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
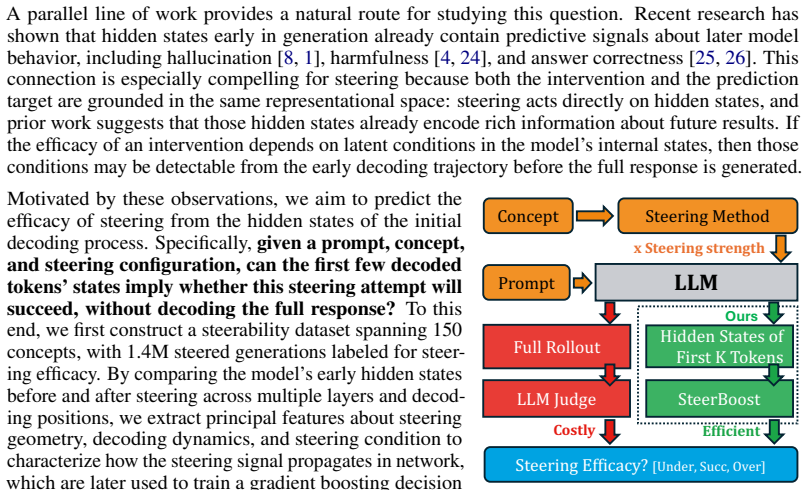
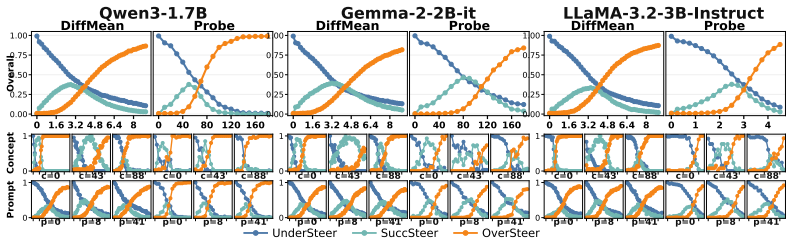
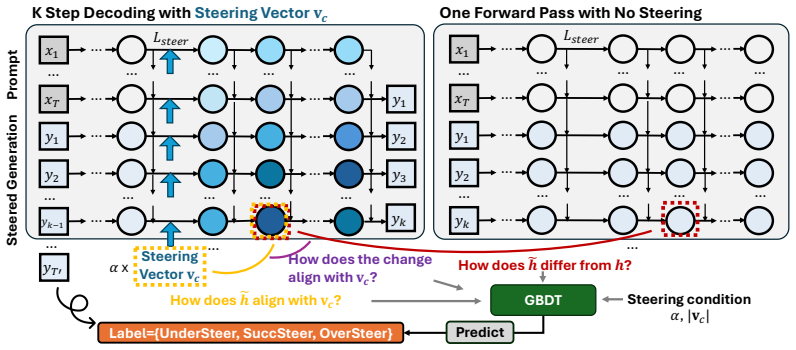
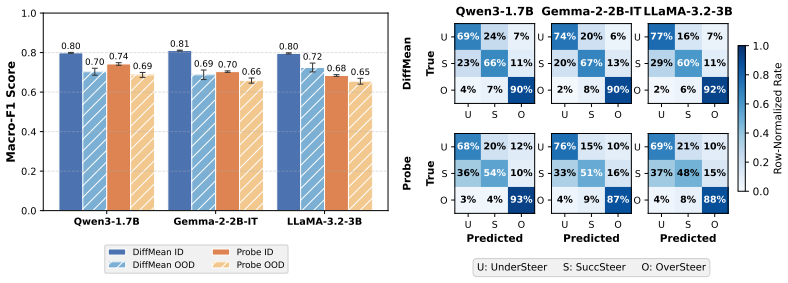
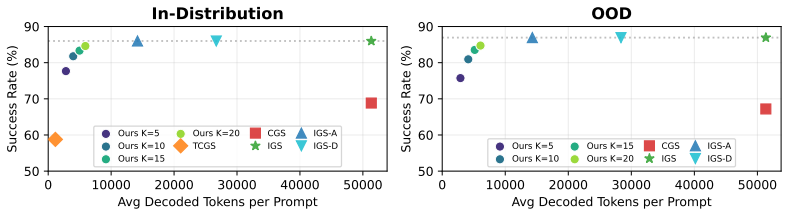
The paper introduces the ASTEER testbed containing 1.4M steered generations spanning 150 concepts, each labeled for steering success or failure. It shows that features comparing hidden states before and after steering, taken across layers and the first few decoding steps, contain structured information about eventual outcome. A Gradient Boosting Decision Trees classifier trained on these features predicts whether an intervention will under-steer, succeed, or over-steer at roughly 0.7 macro-F1 on unseen concepts, and the predictor can be used to search steering strengths while incurring only a small fraction of the usual decoding cost.
What carries the argument
The ASTEER testbed together with the GBDT classifier operating on hidden-state difference features across layers and initial token positions.
If this is right
- Steering outcomes can be classified without running complete autoregressive rollouts.
- The predictor supplies a low-cost signal for choosing effective steering strengths.
- Differences in early hidden states trace how the steering effect moves through layers and token positions.
- The 0.7 F1 level on unseen concepts indicates that the early-state signal generalizes beyond the training concepts.
Where Pith is reading between the lines
- If early states are diagnostic, an LLM could monitor its own steerability on the fly and adjust or abort an intervention before full generation.
- The same early-state comparison idea might apply to other inference-time methods such as prompt editing or representation surgery.
- Because the testbed uses only 150 concepts, deployment on specialized domains would still require checking whether the predictor transfers.
- Pairing the predictor with parallel decoding or speculative methods could shrink the remaining search cost even further.
Load-bearing premise
The selected early-state comparison features capture enough information to forecast the result of a full autoregressive generation.
What would settle it
Evaluating the same classifier on a fresh set of concepts or a different model family and observing macro-F1 well below 0.7 would show that early hidden states do not reliably encode steering efficacy.
Figures



read the original abstract
Activation steering offers a lightweight approach to control language models' behavior at inference time, but whether it succeeds or fails heavily depends on the prompt, concept, model, and steering configuration. Finding the regime and boundaries of successful steering typically requires expensive grid searches and post-hoc evaluation of full autoregressive rollouts. In this work, we investigate whether steerability can be predicted from the model's internal states at the beginning of the generation process, e.g., after generating the first few tokens, and how to leverage such a predictor to improve steering success rate. To this end, we first introduce ASTEER, a testbed including 1.4M steered generations, spanning 150 concepts with each steering success/failure labeled. Leveraging this testbed, we analyze the model's early decoding dynamics by extracting features that compare hidden states before and after steering across layers and initial decoding steps. These features help us understand how steering's effects propagate along layers and token positions, which provide key information for steerability prediction. We then train a Gradient Boosting Decision Trees (GBDT) classifier on these features to predict whether an intervention will under-steer, succeed, or over-steer without requiring full rollout. Our predictor achieves around 0.7 macro-F1 score on unseen concepts, demonstrating that early hidden states encode substantial, structured information about eventual steering efficacy. We further leverage this steerability predictor as guidance for steering strength searching, achieving near-optimal performance with a small fraction of decoding cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ASTEER testbed of 1.4M steered generations spanning 150 concepts with success/failure labels. It extracts features comparing hidden states before and after steering across layers and early decoding steps, trains a GBDT classifier on these features to predict under-steer/success/over-steer outcomes without full rollouts, reports ~0.7 macro-F1 on unseen concepts, and uses the predictor to guide steering-strength search for near-optimal results at reduced cost.
Significance. If the central result holds, the work shows that early hidden-state dynamics encode structured, predictive information about eventual steering efficacy, enabling cheaper optimization of activation steering. The ASTEER testbed itself is a substantial empirical contribution that could support follow-on analyses of steering boundaries. The efficiency gain from predictor-guided search is a practical advance for inference-time control methods.
major comments (3)
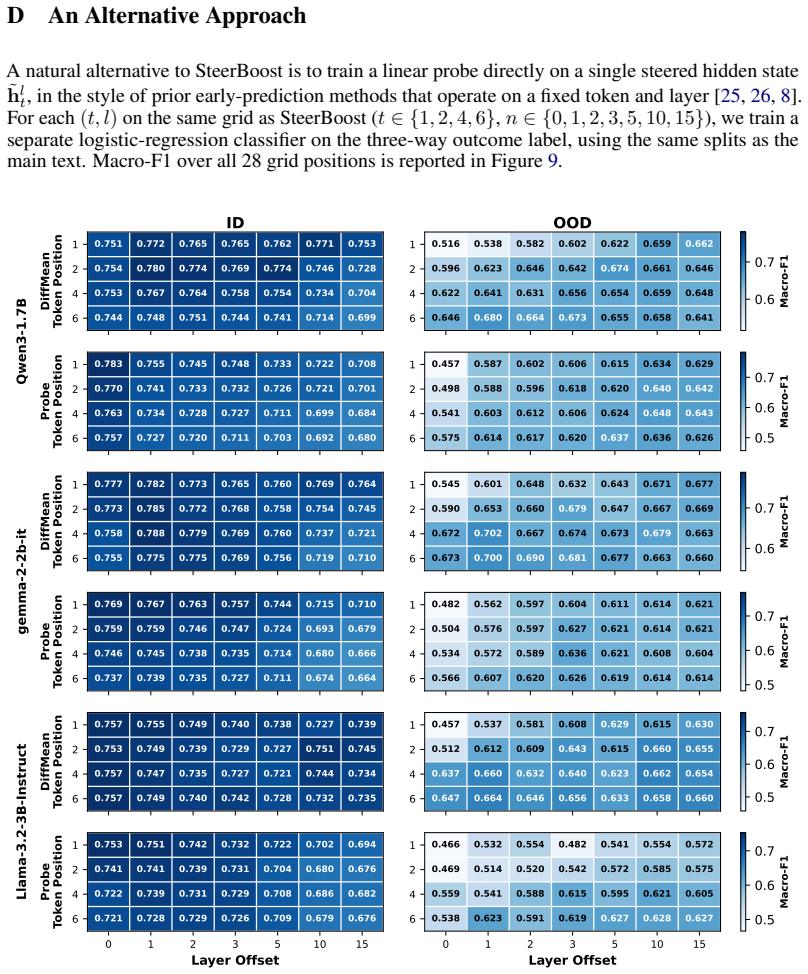
- [§4] §4 (Results) and the abstract: the reported ~0.7 macro-F1 on unseen concepts is presented as a single aggregate number with no accompanying table or text detailing the train/test split over the 150 concepts, the exact feature definitions (layer indices, token positions, before/after difference operators), labeling criteria for under-/over-/success, or any measure of statistical significance or variance across random seeds. Without these, it is impossible to verify whether the score supports the claim that early states encode substantial information about steering efficacy.
- [§3.2] §3.2 (Testbed construction) and §5 (Generalization discussion): the load-bearing assumption that the 150 concepts are representative enough for held-out performance to imply broader applicability is not supported by any analysis of concept diversity (semantic clustering, coverage of factual vs. behavioral vs. stylistic targets, or performance stratified by concept type). If the concepts share latent structure, the F1 may reflect memorization rather than discovery of general early-state signals.
- [§4.3] §4.3 (Predictor ablations): no ablation is reported that isolates the contribution of layer-wise vs. token-position features or that compares the GBDT against a simple baseline using only the steering strength hyperparameter; without this, it remains unclear whether the extracted hidden-state features are actually necessary or sufficient to forecast full-rollout labels.
minor comments (2)
- [§3.1] The notation for the before/after hidden-state difference features is introduced without an explicit equation; adding a short definition (e.g., Eq. (X)) would improve clarity.
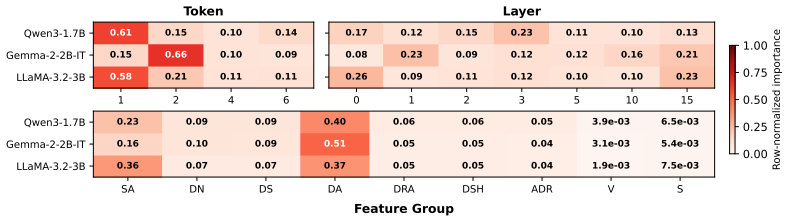
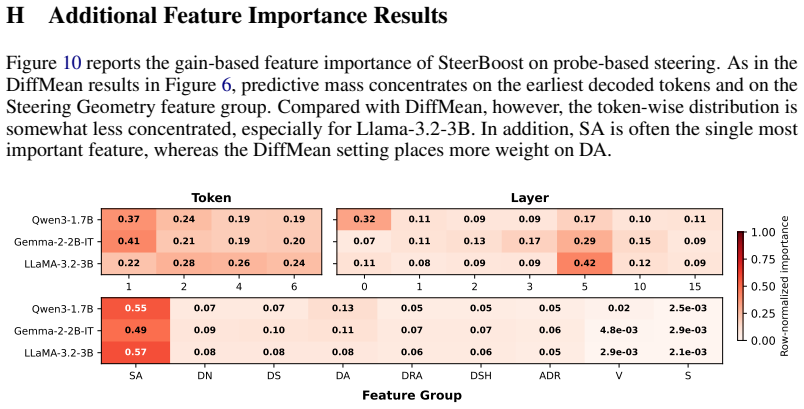
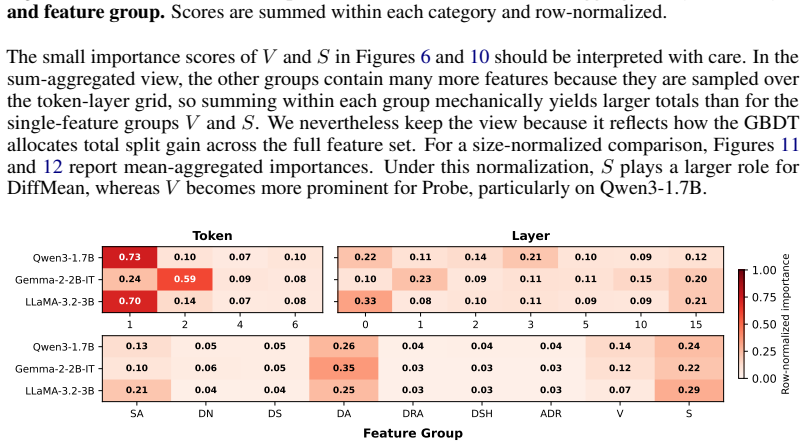
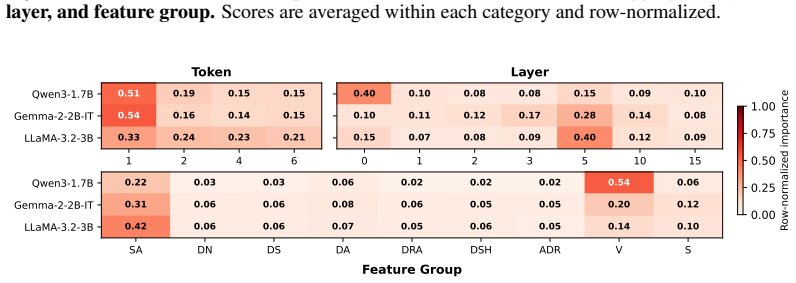
- [Figure 3] Figure 3 (feature importance) lacks error bars or confidence intervals on the reported importances; adding them would make the ranking more interpretable.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We address each major comment below and will revise the manuscript accordingly to improve reproducibility, support for generalization claims, and clarity on feature contributions.
read point-by-point responses
-
Referee: [§4] §4 (Results) and the abstract: the reported ~0.7 macro-F1 on unseen concepts is presented as a single aggregate number with no accompanying table or text detailing the train/test split over the 150 concepts, the exact feature definitions (layer indices, token positions, before/after difference operators), labeling criteria for under-/over-/success, or any measure of statistical significance or variance across random seeds. Without these, it is impossible to verify whether the score supports the claim that early states encode substantial information about steering efficacy.
Authors: We agree these details are required for verification. In the revision we will add to §4 a table and accompanying text specifying: the train/test split (120 concepts train, 30 held-out test, with concept IDs listed), exact features (hidden-state differences at layers 1-8 and tokens 1-4 using subtraction operator), labeling criteria (success if target concept match rate ≥0.7, under-steer <0.3, over-steer >1.5 deviation from target), and macro-F1 with mean±std across five random seeds. This will directly support the early-state encoding claim. revision: yes
-
Referee: [§3.2] §3.2 (Testbed construction) and §5 (Generalization discussion): the load-bearing assumption that the 150 concepts are representative enough for held-out performance to imply broader applicability is not supported by any analysis of concept diversity (semantic clustering, coverage of factual vs. behavioral vs. stylistic targets, or performance stratified by concept type). If the concepts share latent structure, the F1 may reflect memorization rather than discovery of general early-state signals.
Authors: The 150 concepts were selected to cover factual, behavioral, and stylistic targets (enumerated in Appendix A), but we did not quantify diversity or stratify results. We will add to §5 an analysis of semantic diversity via embedding clustering and report predictor F1 stratified by category. This will either strengthen the generalization argument or surface limitations for discussion. revision: yes
-
Referee: [§4.3] §4.3 (Predictor ablations): no ablation is reported that isolates the contribution of layer-wise vs. token-position features or that compares the GBDT against a simple baseline using only the steering strength hyperparameter; without this, it remains unclear whether the extracted hidden-state features are actually necessary or sufficient to forecast full-rollout labels.
Authors: We will expand §4.3 with the requested ablations: (i) GBDT using only layer-wise features, (ii) only token-position features, and (iii) a baseline using solely the steering-strength value as input. These results will quantify the incremental value of the hidden-state features over the hyperparameter alone. revision: yes
Circularity Check
No significant circularity in the steerability predictor derivation.
full rationale
The paper builds an external testbed of 1.4M full-rollout generations across 150 concepts to obtain ground-truth under-/success-/over-steer labels. It then extracts before/after hidden-state features from early decoding steps and trains a GBDT classifier to map those features to the labels, reporting macro-F1 on held-out concepts. This is a standard supervised-learning pipeline in which the learned mapping is not equivalent to the inputs by construction, nor does any equation or self-citation reduce the reported performance to a fitted quantity. The central claim (early states encode structured information about steering efficacy) rests on empirical out-of-sample accuracy rather than definitional equivalence or load-bearing self-citation. No steps matching the enumerated circularity patterns are present.
Axiom & Free-Parameter Ledger
free parameters (1)
- GBDT hyperparameters
axioms (1)
- domain assumption Labeled success/failure from full rollouts provides ground truth for training an early-state predictor
Reference graph
Works this paper leans on
-
[1]
Factcheckmate: Pre- emptively detecting and mitigating hallucinations in lms, 2025
Deema Alnuhait, Neeraja Kirtane, Muhammad Khalifa, and Hao Peng. Factcheckmate: Pre- emptively detecting and mitigating hallucinations in lms, 2025. URL https://arxiv.org/ abs/2410.02899
-
[2]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction, 2024. URL https://arxiv.org/abs/2406.11717
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Activation steering for chain-of-thought compression, 2025
Seyedarmin Azizi, Erfan Baghaei Potraghloo, and Massoud Pedram. Activation steering for chain-of-thought compression, 2025. URLhttps://arxiv.org/abs/2507.04742
- [4]
-
[5]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 785–794. ACM, August 2016. doi: 10.1145/2939672.2939785. URL http://dx.doi.org/10.1145/2939672.2939785
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, and et.al. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/ 2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Amoukou, Tom Bewley, Saumitra Mishra, and Manuela Veloso
Anna Hedström, Salim I. Amoukou, Tom Bewley, Saumitra Mishra, and Manuela Veloso. To steer or not to steer? mechanistic error reduction with abstention for language models, 2025. URLhttps://arxiv.org/abs/2510.13290
-
[8]
LLM internal states reveal hallucination risk faced with a query
Ziwei Ji, Delong Chen, Etsuko Ishii, Samuel Cahyawijaya, Yejin Bang, Bryan Wilie, and Pascale Fung. LLM internal states reveal hallucination risk faced with a query. In Yonatan Belinkov, Najoung Kim, Jaap Jumelet, Hosein Mohebbi, Aaron Mueller, and Hanjie Chen, editors, Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Network...
-
[9]
Improving activation steering in language models with mean-centring, 2023
Ole Jorgensen, Dylan Cope, Nandi Schoots, and Murray Shanahan. Improving activation steering in language models with mean-centring, 2023. URL https://arxiv.org/abs/ 2312.03813
-
[10]
Bruce W. Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar. Programming refusal with conditional activation steering, 2025. URLhttps://arxiv.org/abs/2409.05907
-
[11]
Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
2023
-
[12]
Investigating bias representations in llama 2 chat via activation steering, 2024
Dawn Lu and Nina Rimsky. Investigating bias representations in llama 2 chat via activation steering, 2024. URLhttps://arxiv.org/abs/2402.00402
-
[13]
Gpt-5.5 system card, 2026
OpenAI. Gpt-5.5 system card, 2026. URL https://deploymentsafety.openai.com/ gpt-5-5/introduction
2026
-
[14]
Steering Llama 2 via Contrastive Activation Addition
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition, 2024. URL https://arxiv.org/ abs/2312.06681
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, and et.al. Openai gpt-5 system card, 2025. URLhttps://arxiv.org/abs/2601.03267. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Activation scaling for steering and interpreting language models
Niklas Stoehr, Kevin Du, Vésteinn Snæbjarnarson, Robert West, Ryan Cotterell, and Aaron Schein. Activation scaling for steering and interpreting language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 8189–8200, Miami, Florida, USA, November 2024. As- socia...
- [17]
-
[18]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023
2023
-
[19]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, and et.al. Gemma 2: Improving open language models at a practical size, 2024. URLhttps://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Manning, and Christopher Potts
Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D. Manning, and Christopher Potts. Axbench: Steering llms? even simple baselines outperform sparse autoencoders, 2025. URLhttps://arxiv.org/abs/2501.17148
-
[23]
Enhancing multiple dimensions of trustworthiness in llms via sparse activation control, 2024
Yuxin Xiao, Chaoqun Wan, Yonggang Zhang, Wenxiao Wang, Binbin Lin, Xiaofei He, Xu Shen, and Jieping Ye. Enhancing multiple dimensions of trustworthiness in llms via sparse activation control, 2024. URLhttps://arxiv.org/abs/2411.02461
-
[24]
ShieldHead: Decoding-time Safeguard for Large Language Models
Zitao Xuan, Xiaofeng Mao, Da Chen, Xin Zhang, Yuhan Dong, and Jun Zhou. ShieldHead: Decoding-time safeguard for large language models. In Wanxiang Che, Joyce Nabende, Ekate- rina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computa- tional Linguistics: ACL 2025, pages 18129–18143, Vienna, Austria, July 2025. Association fo...
-
[25]
Reasoning models know when they’re right: Probing hidden states for self-verification, 2025
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification, 2025. URL https://arxiv.org/abs/2504.05419
-
[26]
Qingjie Zhang, Yujia Fu, Yang Wang, Liu Yan, Tao Wei, Ke Xu, Minlie Huang, and Han Qiu. Stop before you fail: Operational capability boundaries for mitigating unproductive reasoning in large reasoning models, 2026. URLhttps://arxiv.org/abs/2509.24711
-
[27]
Bleeding pathways: Vanishing discriminability in llm hidden states fuels jailbreak attacks, 2025
Yingjie Zhang, Tong Liu, Zhe Zhao, Guozhu Meng, and Kai Chen. Bleeding pathways: Vanishing discriminability in llm hidden states fuels jailbreak attacks, 2025. URL https: //arxiv.org/abs/2503.11185
-
[28]
Beyond single concept vector: Modeling concept subspace in llms with gaussian distribution, 2025
Haiyan Zhao, Heng Zhao, Bo Shen, Ali Payani, Fan Yang, and Mengnan Du. Beyond single concept vector: Modeling concept subspace in llms with gaussian distribution, 2025. URL https://arxiv.org/abs/2410.00153
-
[29]
Adasteer: Your aligned llm is inherently an adaptive jailbreak defender, 2025
Weixiang Zhao, Jiahe Guo, Yulin Hu, Yang Deng, An Zhang, Xingyu Sui, Xinyang Han, Yanyan Zhao, Bing Qin, Tat-Seng Chua, and Ting Liu. Adasteer: Your aligned llm is inherently an adaptive jailbreak defender, 2025. URLhttps://arxiv.org/abs/2504.09466
-
[30]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 11 A Detailed Related Work A.1 LLM steering and inference-time intervention Although the term “steerin...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
boundary information
found that hidden states corresponding to the last input token encode capability “boundary information", allowing the solvability of the problem to be predicted before the reasoning process even begins. On the truthfulness side, Ji et al. [8] established that internal activations immediately after processing a query reveal model uncertainty and familiarit...
-
[32]
show that linear probes over Chain-of-Thought activations can detect unsafe responses before generation, and Xuan et al. [24] proposed ShieldHead, a lightweight classification head on last-layer hidden states for decoding-time harmful-content detection, while Zhang et al. [27] observe that separability between safe and harmful representations degrades ove...
-
[33]
An original prompt/instruction
-
[34]
A target concept that should be steered towards
-
[35]
response with emojis
A model’s response after steering Evaluation criteria: Rate the response on a scale of 0–2: 0 — Under-steering (concept missing) • The response doesnotincorporate the target concept • The response is coherent and relevant to the prompt, but lacks the desired steering • Example: target “response with emojis” but the response contains no emojis 1 — Successf...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.