From Prompts to Tokens: Internalizing Causal Supervision in Vision-Language Model for Multi-Image Causal Reasoning
Pith reviewed 2026-06-27 10:16 UTC · model grok-4.3
The pith
BridgeVLM converts induced causal graphs from multi-image inputs into structured tokens executed by RAMP layers for internalized causal message passing in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
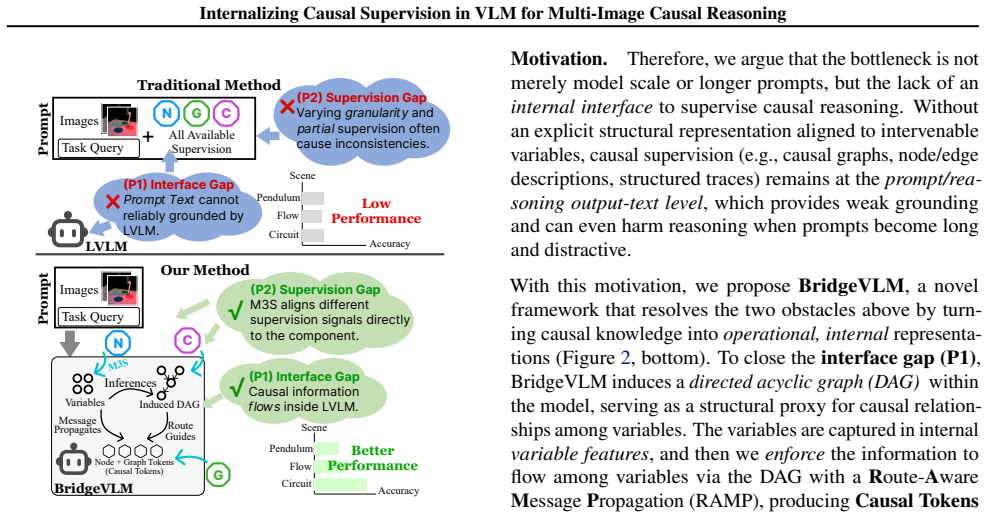
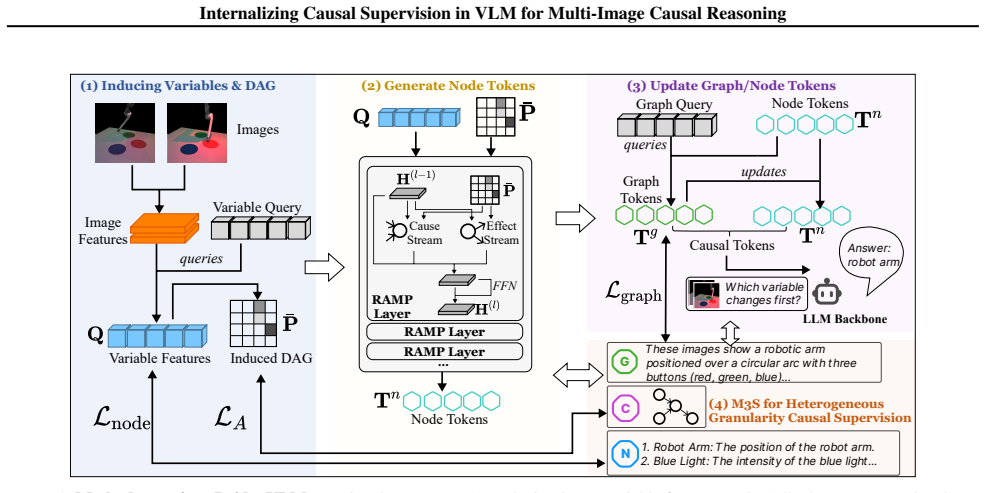
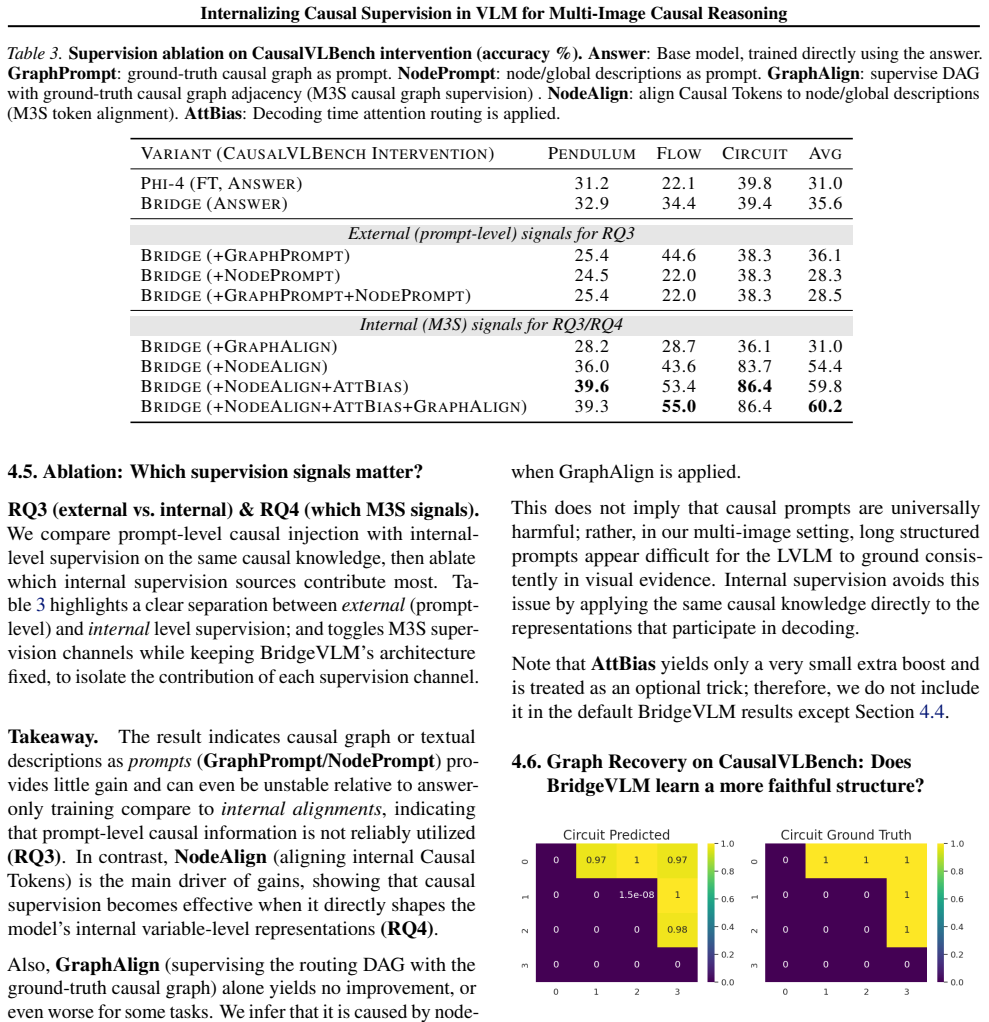
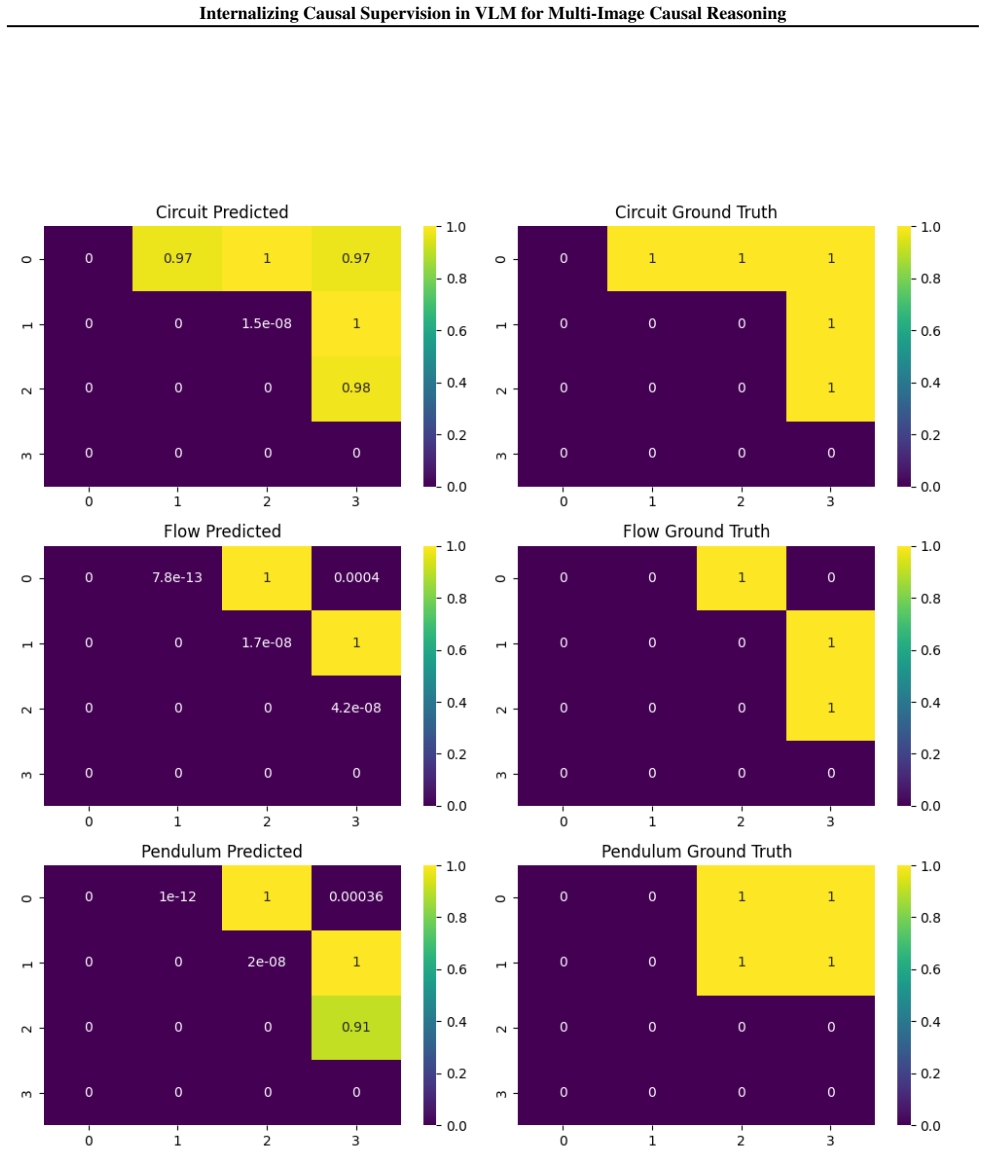
BridgeVLM internalizes visual causal reasoning by inducing a causal graph from multi-image inputs and converting it into structured Causal Tokens executed by RAMP layers injected into the LLM decoder for causal message passing. A unified training interface M3S supplies fine-grained causal supervision from different granularities. On CausalVLBench this raises intervention-task accuracy from 33.2 percent with prompt supervision to 54.4 percent, lifts Causal3D accuracy from 43.6 percent to 49.0 percent, and improves causal-structure F1 from 33.4 percent to 75.1 percent.
What carries the argument
Induction of a causal graph from multi-image inputs followed by its conversion into Causal Tokens that are processed by RAMP layers inserted in the LLM decoder to perform causal message passing.
If this is right
- Intervention accuracy on CausalVLBench rises from 33.2 percent to 54.4 percent.
- Accuracy on Causal3D rises from 43.6 percent to 49.0 percent.
- Causal structure learning F1 on CausalVLBench rises from 33.4 percent to 75.1 percent.
- Causal supervision is supplied through a single M3S interface that works at both local and global granularity.
Where Pith is reading between the lines
- The same token-and-layer pattern could be tested on single-image or video inputs to check whether the gain generalizes when the number of images changes.
- Removing the RAMP layers at inference time would show whether the performance lift truly depends on the internal message-passing mechanism.
- Applying the same conversion step to other structured relations such as temporal or spatial graphs might improve related reasoning tasks.
Load-bearing premise
An induced causal graph from multi-image inputs can be turned into tokens whose processing by the added layers produces genuine causal message passing that holds up outside the training benchmarks.
What would settle it
Run the model on a fresh multi-image causal benchmark whose images and intervention types were never seen in training and measure whether intervention accuracy stays above the prompt-only baseline.
Figures

read the original abstract
Visual causal reasoning is essential for understanding and intervening in the physical world, requiring identification of causal variables from visual inputs and reasoning over intervention effects. Despite recent progress, large vision--language models (VLMs) remain brittle at such tasks, especially for interventional and counterfactual queries over multi-image inputs. Most existing explorations inject causal knowledge via textual prompts, leaving causal mechanisms external to model execution and limiting reliable control during inference. To address this problem, we propose BridgeVLM, which internalizes visual causal reasoning by inducing a causal graph from multi-image inputs and converting it into structured Causal Tokens executed by RAMP layers injected into the LLM decoder for causal message passing. We further introduce a unified training interface M3S for fine-grained causal supervision from different granularities (local/global level). BridgeVLM achieves 54.4% accuracy on intervention tasks on CausalVLBench (vs. 33.2% with prompt-level supervision), improves results on Causal3D from 43.6% to 49.0%, and substantially improves causal structure learning on CausalVLBench ($F_1$: 33.4% $\rightarrow$ 75.1%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BridgeVLM to internalize visual causal reasoning in VLMs: it induces a causal graph from multi-image inputs, converts the graph into structured Causal Tokens, and executes them via injected RAMP layers in the LLM decoder to perform causal message passing. A unified M3S training interface supplies fine-grained (local/global) causal supervision. On CausalVLBench the model reaches 54.4% accuracy on intervention tasks (vs. 33.2% with prompt-level supervision), improves Causal3D from 43.6% to 49.0%, and raises causal-structure F1 from 33.4% to 75.1%.
Significance. If the reported gains are shown to arise from genuine causal message passing rather than extra capacity or supervision granularity, the work would constitute a meaningful advance over prompt-only causal injection, offering a route to more reliable interventional and counterfactual reasoning inside the model itself. The magnitude of the accuracy and F1 lifts on two benchmarks would be noteworthy for multi-image causal VLM research.
major comments (1)
- [Abstract and §3] Abstract and §3 (method description of RAMP layers and Causal Tokens): the central claim that the induced graph is converted into tokens whose execution inside RAMP layers produces verifiable causal message passing (i.e., interventions propagate according to graph edges) is load-bearing for the contribution. No ablation is described that (a) keeps the token format but randomizes or removes the graph structure, or (b) replaces RAMP layers with otherwise identical decoder layers while preserving token count and training objective. Without such a control the 54.4% vs. 33.2% delta on intervention tasks cannot be attributed to internalized causal mechanics rather than M3S supervision or added parameters.
minor comments (2)
- [Abstract] Abstract: numeric results are given without error bars, number of runs, or statistical tests, which weakens assessment of the reliability of the reported improvements.
- [Results] Results section: tables or figures reporting the benchmark numbers should include variance or confidence intervals and clarify whether the baselines use identical training data and compute.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description of RAMP layers and Causal Tokens): the central claim that the induced graph is converted into tokens whose execution inside RAMP layers produces verifiable causal message passing (i.e., interventions propagate according to graph edges) is load-bearing for the contribution. No ablation is described that (a) keeps the token format but randomizes or removes the graph structure, or (b) replaces RAMP layers with otherwise identical decoder layers while preserving token count and training objective. Without such a control the 54.4% vs. 33.2% delta on intervention tasks cannot be attributed to internalized causal mechanics rather than M3S supervision or added parameters.
Authors: We agree that these specific controls are needed to isolate whether gains arise from causal message passing. Our prompt-level baseline controls for supervision granularity but not for token structure or RAMP architecture. We will add the requested ablations—(a) randomizing graph structure while preserving token format/count and (b) swapping RAMP layers for equivalent decoder layers—and report the results in the revision to strengthen attribution of the intervention accuracy lift. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description introduce BridgeVLM as an architectural approach that induces causal graphs, converts them to Causal Tokens, and executes them via injected RAMP layers under M3S supervision, with reported empirical gains on CausalVLBench and Causal3D. No equations, derivations, or self-citations appear that reduce these gains or the claimed internalization of causal message passing to quantities defined by the same inputs or prior self-referential results. The performance deltas are framed as outcomes of the new components rather than statistical artifacts of fitting or renaming. The derivation chain is self-contained against external benchmarks with no load-bearing steps that collapse by construction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Causal Tokens
no independent evidence
-
RAMP layers
no independent evidence
Reference graph
Works this paper leans on
-
[1]
C ausal VLB ench: Benchmarking Visual Causal Reasoning in Large Vision-Language Models
Komanduri, Aneesh and Bhaila, Karuna and Wu, Xintao. C ausal VLB ench: Benchmarking Visual Causal Reasoning in Large Vision-Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1561
-
[2]
2025 , eprint=
CAUSAL3D: A Comprehensive Benchmark for Causal Learning from Visual Data , author=. 2025 , eprint=
2025
-
[3]
CELLO : Causal Evaluation of Large Vision-Language Models
Chen, Meiqi and Peng, Bo and Zhang, Yan and Lu, Chaochao. CELLO : Causal Evaluation of Large Vision-Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1247
-
[4]
Zhao, Haozhe and Si, Shuzheng and Chen, Liang and Zhang, Yichi and Sun, Maosong and Chang, Baobao and Zhang, Minjia. Looking Beyond Text: Reducing Language Bias in Large Vision-Language Models via Multimodal Dual-Attention and Soft-Image Guidance. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1...
-
[5]
2025 , url=
Vision Language Models are Biased , author=. 2025 , url=
2025
-
[6]
The Thirteenth International Conference on Learning Representations , year=
Mitigating Modality Prior-Induced Hallucinations in Multimodal Large Language Models via Deciphering Attention Causality , author=. The Thirteenth International Conference on Learning Representations , year=
-
[7]
Rethinking Misalignment in Vision-Language Model Adaptation from a Causal Perspective , volume =
Zhang, Yanan and Li, Jiangmeng and Liu, Lixiang and Qiang, Wenwen , booktitle =. Rethinking Misalignment in Vision-Language Model Adaptation from a Causal Perspective , volume =. doi:10.52202/079017-1238 , editor =
-
[8]
Forty-second International Conference on Machine Learning , year=
Learning Invariant Causal Mechanism from Vision-Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[9]
The Thirteenth International Conference on Learning Representations , year=
Causal Graphical Models for Vision-Language Compositional Understanding , author=. The Thirteenth International Conference on Learning Representations , year=
-
[10]
2018 , eprint=
DAGs with NO TEARS: Continuous Optimization for Structure Learning , author=. 2018 , eprint=
2018
-
[11]
UAI 2022 Workshop on Causal Representation Learning , year=
Can Foundation Models Talk Causality? , author=. UAI 2022 Workshop on Causal Representation Learning , year=
2022
-
[12]
Transactions on Machine Learning Research , issn=
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[13]
Unveiling Causal Reasoning in Large Language Models: Reality or Mirage? , url =
Chi, Haoang and Li, He and Yang, Wenjing and Liu, Feng and Lan, Long and Ren, Xiaoguang and Liu, Tongliang and Han, Bo , booktitle =. Unveiling Causal Reasoning in Large Language Models: Reality or Mirage? , url =. doi:10.52202/079017-3064 , editor =
-
[14]
CLADDER: assessing causal reasoning in language models , year =
Jin, Zhijing and Chen, Yuen and Leeb, Felix and Gresele, Luigi and Kamal, Ojasv and Lyu, Zhiheng and Blin, Kevin and Gonzalez, Fernando and Kleiman-Weiner, Max and Sachan, Mrinmaya and Sch\". CLADDER: assessing causal reasoning in language models , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[15]
C ausal B ench: A Comprehensive Benchmark for Evaluating Causal Reasoning Capabilities of Large Language Models
Wang, Zeyu. C ausal B ench: A Comprehensive Benchmark for Evaluating Causal Reasoning Capabilities of Large Language Models. Proceedings of the 10th SIGHAN Workshop on Chinese Language Processing (SIGHAN-10). 2024
2024
-
[16]
2024 , eprint=
Can large language models build causal graphs? , author=. 2024 , eprint=
2024
-
[17]
2023 , eprint=
Causal Discovery with Language Models as Imperfect Experts , author=. 2023 , eprint=
2023
-
[18]
2024 , eprint=
Efficient Causal Graph Discovery Using Large Language Models , author=. 2024 , eprint=
2024
-
[19]
2024 , eprint=
Large Language Models are Effective Priors for Causal Graph Discovery , author=. 2024 , eprint=
2024
-
[20]
2024 , eprint=
LLM-initialized Differentiable Causal Discovery , author=. 2024 , eprint=
2024
-
[21]
2025 , eprint=
Large Language Models for Causal Discovery: Current Landscape and Future Directions , author=. 2025 , eprint=
2025
-
[22]
Zhang, Congzhi and Zhang, Linhai and Wu, Jialong and He, Yulan and Zhou, Deyu , title =. Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2025 , isbn =. doi:...
-
[23]
2024 , url=
Haitao Jiang and Lin Ge and Yuhe Gao and Jianian Wang and Rui Song , booktitle=. 2024 , url=
2024
-
[24]
2024 , eprint=
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning , author=. 2024 , eprint=
2024
-
[25]
2025 , eprint=
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs , author=. 2025 , eprint=
2025
-
[26]
2024 , eprint=
LLaVA-OneVision: Easy Visual Task Transfer , author=. 2024 , eprint=
2024
-
[27]
2024 , howpublished =
Gemini 2.0 Flash (Model Documentation) , author =. 2024 , howpublished =
2024
-
[28]
2023 , eprint=
Causal Parrots: Large Language Models May Talk Causality But Are Not Causal , author=. 2023 , eprint=
2023
-
[29]
2020 , eprint=
End-to-End Object Detection with Transformers , author=. 2020 , eprint=
2020
-
[30]
Kuhn, H. W. , title =. Naval Research Logistics Quarterly , volume =. doi:https://doi.org/10.1002/nav.3800020109 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/nav.3800020109 , abstract =
-
[31]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[32]
2024 , eprint=
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding , author=. 2024 , eprint=
2024
-
[33]
arXiv preprint arXiv:2502.13923 , year=
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[34]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Causal inference with large language model: A survey , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[35]
Proceedings of the 36th International Conference on Machine Learning , pages =
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[36]
On the Connection Between
Cai, Chen and Hy, Truong Son and Yu, Rose and Wang, Yusu , booktitle =. On the Connection Between. 2023 , editor =
2023
-
[37]
Object-Centric Learning with Slot Attention , url =
Locatello, Francesco and Weissenborn, Dirk and Unterthiner, Thomas and Mahendran, Aravindh and Heigold, Georg and Uszkoreit, Jakob and Dosovitskiy, Alexey and Kipf, Thomas , booktitle =. Object-Centric Learning with Slot Attention , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.