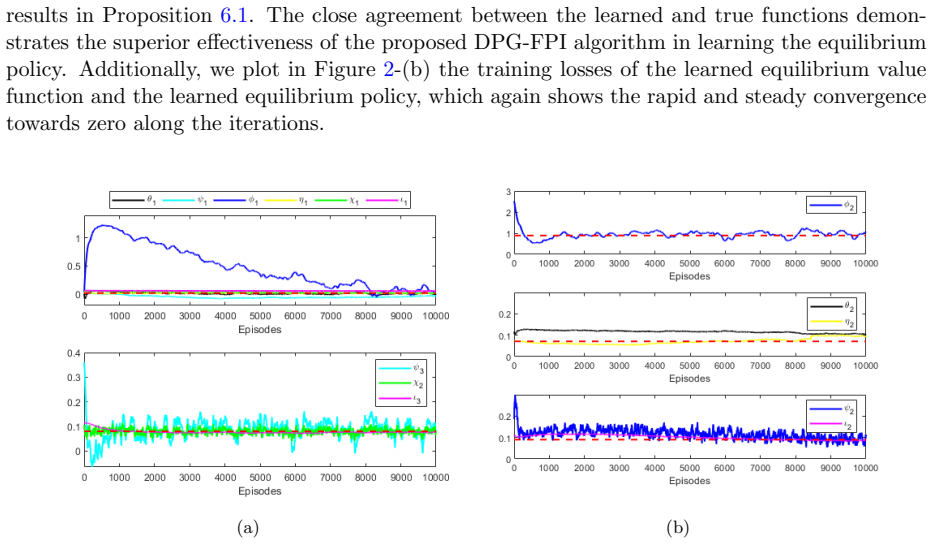
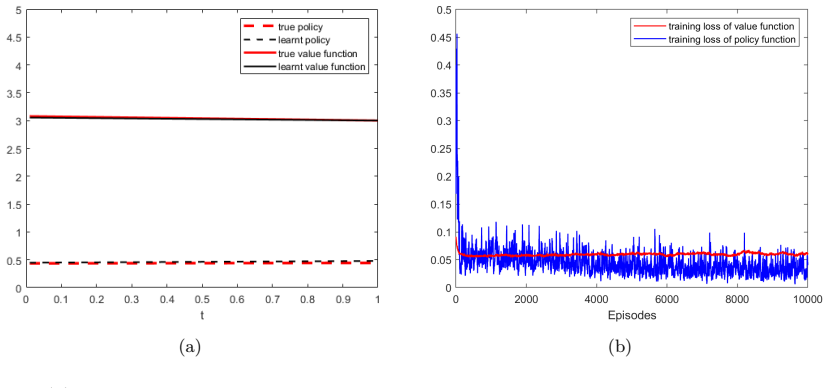
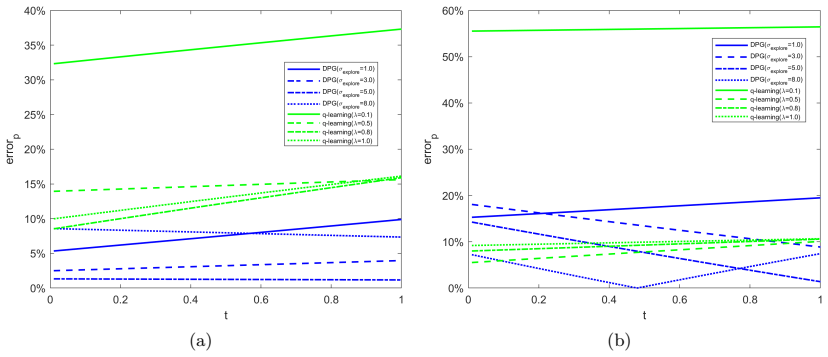
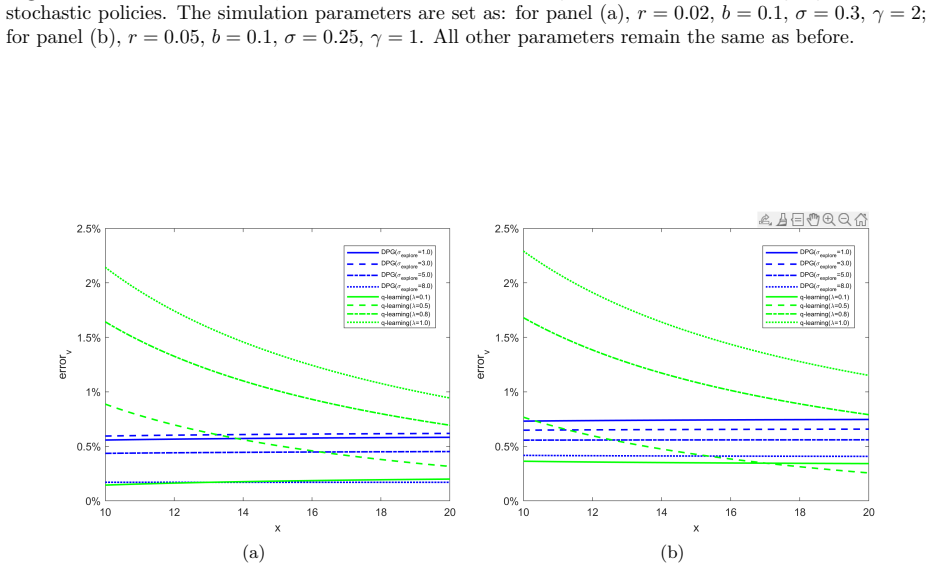
Deterministic Policy Gradient for Learning Equilibrium in Time-Inconsistent Control Problems
Pith reviewed 2026-06-27 07:54 UTC · model grok-4.3
The pith
A two-stage actor-critic algorithm learns deterministic equilibrium policies for time-inconsistent control problems by recasting them as an auxiliary time-consistent problem plus fixed-point updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By repeating actor-critic style iterations across two stages, the algorithm learns the equilibrium under different sources of time-inconsistency in a unified manner: the first stage applies deterministic policy gradient to an auxiliary time-consistent control problem for given auxiliary functions, while the second stage uses inner fixed-point iterations and martingale characterizations to update those auxiliary functions, with the extended Hamilton-Jacobi-Bellman system guaranteeing equivalence to the original problem.
What carries the argument
The extended Hamilton-Jacobi-Bellman system that recasts the time-inconsistent problem into an equivalent two-stage problem whose inner fixed-point iterations converge under mild assumptions.
Load-bearing premise
The extended Hamilton-Jacobi-Bellman system allows an exact recasting of the original time-inconsistent problem into an equivalent two-stage problem whose inner fixed-point iterations converge.
What would settle it
Apply the algorithm to a low-dimensional time-inconsistent problem whose equilibrium policy is known in closed form and check whether the learned policy converges to that known equilibrium within numerical error.
Figures
read the original abstract
In this paper, we develop a continuous-time model-free reinforcement learning algorithm to learn deterministic equilibrium policies in general time-inconsistent control problems. Utilizing the extended Hamilton-Jacobi-Bellman system, we recast the original time-inconsistent problem into an equivalent two-stage problem. In the first stage, for given auxiliary functions, we employ the deterministic policy gradient approach to learn an optimal policy in an auxiliary time-consistent control problem. In the second stage, given the updated policy, we exploit the inner fixed point iterations and some martingale characterizations to learn the auxiliary functions. As a theoretical contribution, we provide some mild model assumptions and establish the convergence of inner fixed point iterations. By repeating this actor-critic style of iterations across two stages, our algorithm aims to learn the equilibrium under different sources of time-inconsistency in a unified manner. The superior effectiveness of the proposed algorithm are illustrated in two classical financial applications with time-inconsistency: mean-variance portfolio management and optimal tracking portfolio under non-exponential discounting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a continuous-time model-free reinforcement learning algorithm based on deterministic policy gradient (DPG) to learn deterministic equilibrium policies for general time-inconsistent stochastic control problems. It recasts the original problem as an equivalent two-stage problem via the extended Hamilton-Jacobi-Bellman system: for fixed auxiliary functions the first stage solves an auxiliary time-consistent problem with DPG, while the second stage updates the auxiliary functions via inner fixed-point iterations (with martingale characterizations); the stages are alternated in an actor-critic loop. Convergence of the inner iterations is asserted under mild model assumptions, and the method is illustrated on mean-variance portfolio management and optimal tracking portfolio selection under non-exponential discounting.
Significance. If the claimed exact equivalence and convergence of the inner fixed-point iterations hold in the continuous-time stochastic setting, the work would supply a unified model-free RL framework for equilibrium computation under multiple sources of time-inconsistency, extending DPG methods to an important class of financial control problems.
major comments (2)
- [§3] §3 (theoretical contribution on convergence): the manuscript asserts that the extended HJB system yields an exact two-stage recasting whose inner fixed-point iterations converge under the stated mild model assumptions, yet supplies neither the derivation of the fixed-point map, error bounds, nor verification that the conditions suffice for the continuous-time Itô-process setting used in the financial examples; this equivalence is load-bearing for both the unified treatment and the outer actor-critic guarantee.
- [Numerical experiments] Numerical experiments section (mean-variance and tracking examples): the illustrations report only qualitative behavior; no quantitative metrics (e.g., distance to known equilibrium, iteration counts to convergence, or comparison against analytic solutions) are supplied to confirm that the learned policy satisfies the equilibrium condition.
minor comments (2)
- [Algorithm description] Notation for the auxiliary functions and the two-stage operator should be introduced with explicit definitions before the algorithm pseudocode.
- [Abstract] The abstract states convergence is established, but the precise statement of the mild assumptions (e.g., Lipschitz constants, discount factors, or moment bounds) appears only later; a forward reference or boxed statement would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (theoretical contribution on convergence): the manuscript asserts that the extended HJB system yields an exact two-stage recasting whose inner fixed-point iterations converge under the stated mild model assumptions, yet supplies neither the derivation of the fixed-point map, error bounds, nor verification that the conditions suffice for the continuous-time Itô-process setting used in the financial examples; this equivalence is load-bearing for both the unified treatment and the outer actor-critic guarantee.
Authors: The extended HJB system and the resulting two-stage recasting are derived in Section 3 of the manuscript, where the fixed-point map on the auxiliary functions is obtained directly from the martingale characterization of the equilibrium condition. Convergence of the inner iterations is proved under the listed mild assumptions by showing that the map is a contraction in an appropriate function space. We acknowledge that the presentation can be strengthened by making the derivation of the fixed-point operator more explicit and by adding a brief verification that the assumptions are compatible with the Itô-process dynamics in the examples. Quantitative error bounds are not currently derived; we will add a remark on this point and note it as a direction for future work rather than claiming rates in the present version. revision: partial
-
Referee: [Numerical experiments] Numerical experiments section (mean-variance and tracking examples): the illustrations report only qualitative behavior; no quantitative metrics (e.g., distance to known equilibrium, iteration counts to convergence, or comparison against analytic solutions) are supplied to confirm that the learned policy satisfies the equilibrium condition.
Authors: We agree that quantitative metrics would strengthen the numerical section. In the revised manuscript we will add, for both examples, (i) the distance between the learned policy and the known analytic equilibrium (where available), (ii) the number of outer actor-critic iterations required for stabilization of the auxiliary functions, and (iii) a direct check that the learned policy satisfies the equilibrium condition via the martingale characterization. These additions will be placed in the existing numerical section without altering the qualitative illustrations. revision: yes
Circularity Check
No circularity; derivation relies on external HJB recasting and independent convergence claim
full rationale
The paper recasts the time-inconsistent control problem into an equivalent two-stage formulation via the extended Hamilton-Jacobi-Bellman system, applies deterministic policy gradient to the auxiliary time-consistent problem for fixed auxiliaries, and uses inner fixed-point iterations (with martingale characterizations) to update the auxiliaries. It claims convergence of those iterations under separately stated mild model assumptions as a theoretical contribution. No equations reduce the target equilibrium to a quantity defined by the algorithm's own outputs or fitted parameters by construction, no load-bearing self-citation chain is invoked to justify the equivalence or convergence, and the method is presented as using standard RL updates on an externally motivated reformulation. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The extended Hamilton-Jacobi-Bellman system recasts the original time-inconsistent problem into an equivalent two-stage problem.
- domain assumption Inner fixed-point iterations converge under mild model assumptions.
Reference graph
Works this paper leans on
-
[1]
and Murgoci, A
Bj¨ ork, T. and Murgoci, A. (2014). A theory of Markovian time-inconsistent stochastic control in discrete time.Finance and Stochastics,18(3): 545-592. Bj¨ ork, T., Khapko, M. and Murgoci, A. (2017). On time-inconsistent stochastic control in continuous time. Finance and Stochastics,21(2): 331-360. Bj¨ ork, T., Khapko, M. and Murgoci, A. (2021).Time-Incon...
2014
-
[2]
and Yu, X
Bo, L., Huang, Y. and Yu, X. (2025). On optimal tracking portfolio in incomplete markets: The reinforce- ment learning approach.SIAM Journal on Control and Optimization,63(1): 321-348
2025
-
[3]
Bo, L., Huang, Y., Yu, X. and Zhang, T. (2024). Continuous-time q-learning for jump-diffusion models under Tsallis entropy.Preprint, available at arXiv:2407.03888
arXiv 2024
-
[4]
Cao, H., Dong, Y. and Yang, Z. (2025). A two-fold randomization framework for impulse control problems. Preprint, available at arXiv:2509.12018
Pith/arXiv arXiv 2025
-
[5]
Cheng, Z., Guo, X. and Zhang, Y. (2025). Deterministic policy gradient for reinforcement learning with continuous time and space.Preprint, available at arXiv:2509.23711
arXiv 2025
-
[6]
and Jia, Y
Dai, M., Dong, Y. and Jia, Y. (2023). Learning equilibrium mean-variance strategy.Mathematical Finance, 33(4), 1166-1212
2023
-
[7]
and Li, L
Dai, M., Dong, Y. and Li, L. (2025). Reinforcement learning for arbitrage strategies in stock index futures. Preprint, available at SSRN 5403455
2025
-
[8]
Dai, M., Sun, Y., Xu, Z. Q. and Zhou, X. Y. (2026). Learning to optimally stop diffusion processes, with financial applications.Management Science, available at:https://doi.org/10.1287/mnsc.2024. 07614
- [9]
-
[10]
Dong, Y. (2024). Randomized optimal stopping problem in continuous time and reinforcement learning algorithm.SIAM Journal on Control and Optimization,62(3): 1590-1614. 39
2024
-
[11]
Ekeland, I. and Lazrak, A. (2006). Being serious about non-commitment: subgame perfect equilibrium in continuous time.Preprint, available at arXiv:math/0604264
Pith/arXiv arXiv 2006
-
[12]
Gao, X., Li, L. and Zhou, X. Y. (2026). Reinforcement learning for jump-diffusions, with financial appli- cations.Mathematical Finance, available at:https://doi.org/10.1111/mafi.70027
-
[13]
and Zariphopoulou, T
Guo, X., Xu, R. and Zariphopoulou, T. (2022). Entropy regularization for mean field games with learning. Mathematics of Operations Research,47(4), 3239-3260
2022
-
[14]
Huang, Y., Li, M., Yu, X. and Zhou, Z. (2025). Continuous-time reinforcement learning for optimal switch- ing over multiple regimes.Preprint, available at arXiv:2512.04697
arXiv 2025
-
[15]
Huang, Y.-J., Yu, X. and Zhang, K. (2026). Policy iteration achieves regularized equilibrium under time inconsistency.Preprint, available at arXiv:2603.06145
arXiv 2026
-
[16]
Jia, Y., Ouyang, D. and Zhang, Y. (2025). Accuracy of discretely sampled stochastic policies in continuous- time reinforcement learning.Preprint, available at arXiv:2503.09981
arXiv 2025
-
[17]
and Zhou, X
Jia, Y. and Zhou, X. Y. (2023). q-Learning in continuous time.Journal of Machine Learning Research, 24(161): 1-61
2023
-
[18]
(2019).Stochastic Flows and Jump-Diffusions
Kunita, K. (2019).Stochastic Flows and Jump-Diffusions. Springer-Verlag, New York
2019
-
[19]
and Zhang, Y
Sethi, D., ˇSiˇ ska, D. and Zhang, Y. (2025). Entropy annealing for policy mirror descent in continuous time and space.SIAM Journal on Control and Optimization,63(4), 3006-3041
2025
-
[20]
Strotz, R. H. (1955). Myopia and inconsistency in dynamic utility maximization.Review of Economic Studies,23(3): 165-180
1955
-
[21]
and Zhang, Y
Szpruch, L., Treetanthiploet, T. and Zhang, Y. (2024): Optimal scheduling of entropy regularization for continuous-time linear-quadratic reinforcement learning.SIAM Journal on Control and Optimization, 62(1), 135-166
2024
-
[22]
Tang, W., Zhang, Y. P. and Zhou, X. Y. (2022). Exploratory hjb equations and their convergence.SIAM Journal on Control and Optimization,60(6), 3191-3216
2022
-
[23]
and Zhou, X
Wang, H., Zariphopoulou, T. and Zhou, X. Y. (2020). Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research,21(198): 1-34
2020
-
[24]
Wang, Z., Yu, X., Zhang, J. and Zhou, Z. (2026). Equilibrium under time-inconsistency: A new existence theory by vanishing entropy regularization. Preprint, available at arXiv:2603.10321
Pith/arXiv arXiv 2026
-
[25]
and Yu, X
Wei, X. and Yu, X. (2025). Continuous-Time q-learning for mean-field control problems.Applied Mathe- matics&Optimization, 91(1):10
2025
-
[26]
and Zhou, X
Yao, D., Zhang, S. and Zhou, X. Y. (2006). Tracking a financial benchmark using a few assets.Operations Research,54(2): 232-246. 40
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.