Corpus Augmentation for Sign Language Translation via LLM-Guided Video Stitching
Pith reviewed 2026-06-27 10:04 UTC · model grok-4.3
The pith
Stitching per-gloss sign clips with LLM-generated sentences raises BLEU-4 by 2.92 without model changes
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
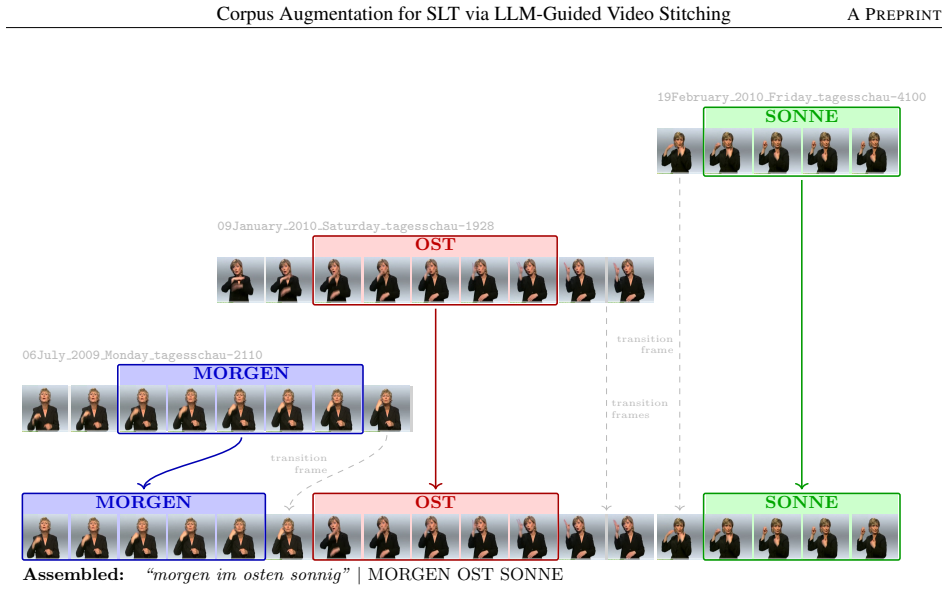
LLM-guided generation of novel gloss-sentence pairs from the training corpus, followed by extraction of per-gloss clips and random assignment into stitched synthetic videos, supplies architecture-agnostic training examples that improve gloss-free sign language translation by 2.92 BLEU-4 when added to the original data.
What carries the argument
LLM-anchored sentence generation combined with CTC-forced per-gloss clip extraction and random sentence sampling for video assembly
If this is right
- Synthetic pairs can be consumed directly by any RGB-based SLT model or converted to pose or feature inputs.
- The augmentation improves fine-tuning objectives but degrades vision-language pretraining performance.
- Abrupt clip boundaries function as implicit regularization under L2 loss criteria.
- Optimizing stitched transitions for visual smoothness reduces downstream translation accuracy.
Where Pith is reading between the lines
- The same extraction-plus-LLM-stitching pattern could be tested on other annotated video-to-text tasks such as action captioning.
- Varying the LLM prompt diversity beyond strict corpus anchoring might further increase coverage of rare constructions.
- Measuring performance on test sentences that contain long-tail glosses would isolate whether the gain comes mainly from vocabulary expansion.
Load-bearing premise
The stitched synthetic videos keep their visual and linguistic distribution close enough to real data that models receive a net positive signal rather than harmful artifacts.
What would settle it
Re-running the identical GFSLT-VLP training protocol with the augmented data and observing zero or negative change in BLEU-4 on the same test set would falsify the improvement claim.
Figures
read the original abstract
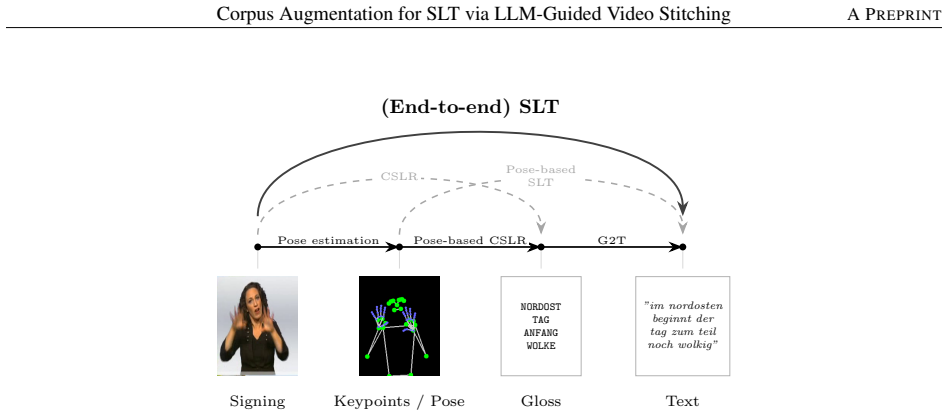
Sign language translation (SLT) converts sign language video into spoken language text and holds significant promise for improving accessibility and enabling communication between signing and non-signing communities. While large weakly-aligned datasets have enabled pre-training at scale and gloss-free methods have reduced reliance on expert annotation, high-quality parallel sign video-text pairs for fine-tuning remain scarce, limiting generalisation on long-tail vocabulary and unseen constructions. We propose a corpus augmentation approach that requires no additional human annotation, external sign-language video corpora, or generative video models, relying only on the existing gloss-annotated training corpus and an LLM for sentence generation: per-gloss clips are extracted from training videos via CTC forced-alignment, novel gloss-sentence pairs are generated by a corpus-anchored LLM, and synthetic sequences are assembled through random sentence sampling and clip assignment. The resulting synthetic RGB video-text pairs are architecture-agnostic at the downstream training stage and can be consumed directly by RGB-based SLT models, or converted into pose or feature representations by pipelines that derive such inputs from video. Sincan et al. re-evaluated five recent gloss-free methods under strictly identical conditions; the largest verified gain over the GFSLT-VLP baseline was only 0.98 BLEU-4. Our augmentation, applied within the same framework, achieves +2.92 BLEU-4 without any change to architecture or training protocol. We further identify that synthetic data harms vision-language pretraining despite improving its objectives, and that optimising clip transitions for visual smoothness is counter-productive under L2-based criteria; we propose that abrupt boundaries may act as a form of implicit regularisation. Code is available at https://github.com/robizso/slt-datagen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a corpus augmentation method for sign language translation (SLT) that extracts per-gloss clips from training videos via CTC forced-alignment, generates novel gloss-sentence pairs with a corpus-anchored LLM, and assembles synthetic RGB video-text pairs through random sentence sampling and clip assignment. No new human annotation, external corpora, or generative video models are required. When applied within the GFSLT-VLP framework under identical conditions, the method yields a +2.92 BLEU-4 gain over the baseline—the largest verified improvement among recent gloss-free approaches. Additional observations include that the same synthetic data harms vision-language pre-training objectives and that optimizing clip transitions for visual smoothness is counterproductive, with the suggestion that abrupt boundaries may provide implicit regularization. Public code is released.
Significance. If the +2.92 BLEU-4 gain proves robust, the work is significant for addressing the scarcity of high-quality parallel SLT data through a low-resource augmentation pipeline that leverages only existing gloss annotations and LLMs. The architecture-agnostic design and explicit release of code support reproducibility and adoption. The counter-intuitive pre-training versus fine-tuning contrast and the smoothness finding contribute to broader understanding of synthetic data effects in SLT, provided the distribution-shift concerns are resolved.
major comments (2)
- [§3] §3 (Method description): The headline +2.92 BLEU-4 claim depends on the assumption that CTC-extracted clips and LLM-generated sentences produce synthetic videos whose visual/linguistic distribution remains sufficiently close to real data for net-positive downstream signal. No quantitative validation of alignment boundary cleanliness, co-articulation fidelity, or LLM sentence grammatical match to sign-language usage is reported; this is load-bearing because the paper itself notes distribution shift harms pre-training.
- [§5] §5 (Experiments and analysis): The reported fine-tuning gain is presented without controls (e.g., label-shuffled synthetics, multiple random seeds, or ablation on alignment quality) to distinguish improved coverage from unintended regularization arising from the same shift acknowledged in pre-training; this directly affects whether the central result generalizes or could reverse under different conditions.
minor comments (1)
- [Abstract] Abstract and §5: The +2.92 BLEU-4 figure is given without error bars, explicit dataset split details, or protocol for random seeds, which would strengthen assessment of statistical reliability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method description): The headline +2.92 BLEU-4 claim depends on the assumption that CTC-extracted clips and LLM-generated sentences produce synthetic videos whose visual/linguistic distribution remains sufficiently close to real data for net-positive downstream signal. No quantitative validation of alignment boundary cleanliness, co-articulation fidelity, or LLM sentence grammatical match to sign-language usage is reported; this is load-bearing because the paper itself notes distribution shift harms pre-training.
Authors: The +2.92 BLEU-4 gain under identical conditions to the GFSLT-VLP baseline constitutes empirical evidence that the synthetic distribution supplies net-positive signal for fine-tuning, even while the same shift harms pre-training objectives. We will revise §3 to incorporate qualitative examples of CTC-aligned clips, sample LLM-generated sentences, and a manual inspection summary of boundary quality on a random subset of 100 clips (reporting the fraction with clean gloss boundaries). This addresses the request for validation while remaining within the scope of existing data. revision: partial
-
Referee: [§5] §5 (Experiments and analysis): The reported fine-tuning gain is presented without controls (e.g., label-shuffled synthetics, multiple random seeds, or ablation on alignment quality) to distinguish improved coverage from unintended regularization arising from the same shift acknowledged in pre-training; this directly affects whether the central result generalizes or could reverse under different conditions.
Authors: We agree that explicit controls would better isolate coverage gains from regularization effects. In the revised §5 we will add an ablation that replaces our synthetic pairs with label-shuffled versions and with synthetics formed from randomly assigned (non-CTC) clips; we will also report performance variance across three random seeds in the supplementary material. These additions directly respond to the concern about generalizability. revision: yes
Circularity Check
No significant circularity; empirical gain measured on independent baseline
full rationale
The paper's central claim is an empirical performance improvement (+2.92 BLEU-4) obtained by applying a corpus-augmentation pipeline (CTC clip extraction, LLM sentence generation, random stitching) to an existing training set and retraining the unchanged GFSLT-VLP model. No equations, fitted parameters, or first-principles derivations are presented whose outputs reduce by construction to the inputs; the reported gain is measured against an external re-evaluation baseline (Sincan et al.) under fixed conditions. The method is architecture-agnostic and the result is directly falsifiable by the BLEU metric on held-out data. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work appear in the load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CTC forced-alignment accurately extracts clean per-gloss clips from the training videos
- domain assumption An LLM can generate novel gloss-sentence pairs that remain within the corpus vocabulary and are linguistically plausible for sign language
Reference graph
Works this paper leans on
-
[1]
Gloss-free sign language translation: An unbiased evaluation of progress in the field.Computer Vision and Image Understanding, 261:104498, 2025
Ozge Mercanoglu Sincan, Jian He Low, Sobhan Asasi, and Richard Bowden. Gloss-free sign language translation: An unbiased evaluation of progress in the field.Computer Vision and Image Understanding, 261:104498, 2025. 13 Corpus Augmentation for SLT via LLM-Guided Video StitchingA PREPRINT
2025
-
[2]
How2sign: A large-scale multimodal dataset for continuous american sign language
Amanda Duarte, Shruti Palaskar, Lucas Ventura, Deepti Ghadiyaram, Kenneth DeHaan, Florian Metze, Jordi Torres, and Xavier Giro-i Nieto. How2sign: A large-scale multimodal dataset for continuous american sign language. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2735–2744, 2021
2021
-
[3]
Uni-Sign: Toward unified sign language understanding at scale
Zecheng Li, Wengang Zhou, Wei Zhao, Kepan Wu, Houqiang Hu, and Houqiang Li. Uni-Sign: Toward unified sign language understanding at scale. InProceedings of the 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[4]
Improving sign language translation with monolingual data by sign back-translation
Hao Zhou, Wengang Zhou, Weizhen Qi, Junfu Pu, and Houqiang Li. Improving sign language translation with monolingual data by sign back-translation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1316–1325, 2021
2021
-
[5]
Harry Walsh, Maxim Ivashechkin, and Richard Bowden. Using sign language production as data augmentation to enhance sign language translation.arXiv preprint arXiv:2506.09643, 2025
-
[6]
PoseStitch-SLT: Linguistically inspired pose-stitching for end-to-end sign language translation
Amit Joshi, Vaishnavi Sharma, Sukhdeep Singh, and Ashutosh Modi. PoseStitch-SLT: Linguistically inspired pose-stitching for end-to-end sign language translation. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 13834–13853, Suzhou, China, 2025
2025
-
[7]
Towards online continuous sign language recognition and translation
Ronglai Zuo, Fangyun Wei, and Brian Mak. Towards online continuous sign language recognition and translation. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 11050–11067, 2024
2024
-
[8]
MSKA: Multi-stream keypoint attention network for sign language recognition and translation.Pattern Recognition, 165(C):111602, 2025
Mo Guan, Yan Wang, Guangkun Ma, Jiarui Liu, and Mingzu Sun. MSKA: Multi-stream keypoint attention network for sign language recognition and translation.Pattern Recognition, 165(C):111602, 2025
2025
-
[9]
Neural sign language translation
Necati Cihan Camgöz, Simon Hadfield, Oscar Koller, Hermann Ney, and Richard Bowden. Neural sign language translation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7784–7793, 2018
2018
-
[10]
Sign language transformers: Joint end-to-end sign language recognition and translation
Necati Cihan Camgöz, Oscar Koller, Simon Hadfield, and Richard Bowden. Sign language transformers: Joint end-to-end sign language recognition and translation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10023–10033, 2020
2020
-
[11]
Two-stream network for sign language recognition and translation.Advances in Neural Information Processing Systems (NeurIPS), 35:17043– 17056, 2022
Yutong Chen, Ronglai Zuo, Fangyun Wei, Yu Wu, Shujie Liu, and Brian Mak. Two-stream network for sign language recognition and translation.Advances in Neural Information Processing Systems (NeurIPS), 35:17043– 17056, 2022
2022
-
[12]
Szabó, Ádám Rák, Zsolt Robotka, and András Horváth
Jalal Al-Afandi, Péter Pócsi, Gábor Borbély, Henrietta M. Szabó, Ádám Rák, Zsolt Robotka, and András Horváth. Assessing the capabilities of large language models in translating American Sign Language gloss to English. In Proceedings of the 2nd International Conference on Generative Pre-trained Transformer Models and Beyond (GPTMB), pages 9–14, 2025
2025
-
[13]
Gloss-free sign language translation: Improving from visual-language pretraining
Benjia Zhou, Zhigang Chen, Albert Clapés, Jun Wan, Yanyan Liang, Sergio Escalera, Zhen Lei, and Da Zhang. Gloss-free sign language translation: Improving from visual-language pretraining. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 20871–20881, 2023
2023
-
[14]
Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, and Angela Fan. Multilingual translation with extensible multilingual pretraining and finetuning.arXiv preprint arXiv:2008.00401, 2020
-
[15]
Improving gloss-free sign language translation by reducing representation density
Jinhui Ye, Xing Wang, Wenxiang Jiao, Junwei Liang, and Hui Xiong. Improving gloss-free sign language translation by reducing representation density. InProceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[16]
C2RL: Content and context representation learning for gloss-free sign language translation and retrieval
Zhigang Chen, Benjia Zhou, Yuanbo Huang, Jun Wan, Yanfeng Hu, Hailin Shi, Yanyan Liang, Zhen Lei, and Da Zhang. C2RL: Content and context representation learning for gloss-free sign language translation and retrieval. IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[17]
Ryan Wong, Necati Cihan Camgöz, and Richard Bowden. Sign2GPT: Leveraging large language models for gloss-free sign language translation.arXiv preprint arXiv:2405.04164, 2024
-
[18]
Factorized learning assisted with large language model for gloss-free sign language translation
Zhigang Chen, Benjia Zhou, Jingyi Li, Jun Wan, Zhen Lei, Ning Jiang, Qiguang Lu, and Guoying Zhao. Factorized learning assisted with large language model for gloss-free sign language translation. InProceedings of the Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING), Torino, Italy, 2024
2024
-
[19]
Data augmentation for sign language gloss translation
Amit Moryossef, Kayo Yin, Graham Neubig, and Yoav Goldberg. Data augmentation for sign language gloss translation. InProceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages (AT4SSL), pages 1–11, 2021. 14 Corpus Augmentation for SLT via LLM-Guided Video StitchingA PREPRINT
2021
-
[20]
S. M. Abdullah, Avishek Paul, Shebuti Rayana, Ashraful Kabir, and Zahid Masud. State-of-the-art translation of text-to-gloss using mBART: A case study of Bangla.arXiv preprint arXiv:2504.02293, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Extending the public DGS corpus in size and depth
Thomas Hanke, Marc Schulder, Reiner Konrad, and Elena Jahn. Extending the public DGS corpus in size and depth. InProceedings of the LREC 2020 9th Workshop on Representation and Processing of Sign Languages, pages 75–82, 2020
2020
-
[22]
Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison
Dongxu Li, Cristian Rodriguez, Xin Yu, and Hongdong Li. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1459–1469, 2020
2020
-
[23]
CISLR: Corpus for Indian Sign Language recognition
Amit Joshi, Ashwin Bhat, Preethi P, Prajwal Gole, Shreya Gupta, Shashank Agarwal, and Ashutosh Modi. CISLR: Corpus for Indian Sign Language recognition. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 10357–10366, Abu Dhabi, United Arab Emirates, 2022
2022
-
[24]
Signing at scale: Learning to co-articulate signs for large-scale photo-realistic sign language production
Ben Saunders, Necati Cihan Camgöz, and Richard Bowden. Signing at scale: Learning to co-articulate signs for large-scale photo-realistic sign language production. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5141–5151, 2022
2022
-
[25]
SignSplat: Rendering sign language via Gaussian splatting.arXiv preprint arXiv:2505.02108, 2025
Maxim Ivashechkin, Oscar Mendez, and Richard Bowden. SignSplat: Rendering sign language via Gaussian splatting.arXiv preprint arXiv:2505.02108, 2025
-
[26]
BLEU: A method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: A method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), pages 311–318, Philadelphia, PA, USA, 2002
2002
-
[27]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InProceedings of the Workshop on Text Summarization Branches Out, pages 74–81, Barcelona, Spain, 2004
2004
-
[28]
A call for clarity in reporting BLEU scores
Matt Post. A call for clarity in reporting BLEU scores. InProceedings of the 3rd Conference on Machine Translation (WMT), pages 186–191, Brussels, Belgium, 2018
2018
-
[29]
Cross-modality data augmentation for end-to-end sign language translation
Jinhui Ye, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, and Hui Xiong. Cross-modality data augmentation for end-to-end sign language translation. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 13558–13571, Singapore, 2023. 15
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.