Frozen Multimodal Embeddings for AI-Assisted Interview Assessment of Personality and Cognitive Ability
Pith reviewed 2026-06-27 08:28 UTC · model grok-4.3
The pith
Frozen multimodal embeddings with trait-specific late fusion reduce personality prediction error from video interviews by 19 percent over baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
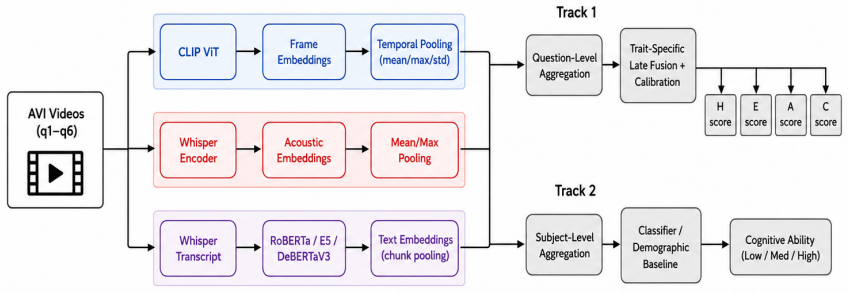
Using frozen multimodal encoders (CLIP for visual features, Whisper for acoustic features and transcripts, and RoBERTa, E5, and DeBERTaV3 for textual representations) followed by low-capacity downstream models and late fusion, the trait-specific system reaches an average validation MSE of 0.2696 on HEXACO personality traits, compared with the official baseline of 0.3334, while ablation shows stepwise gains from global modeling (0.3189) to per-trait modeling (0.2871) to per-trait late fusion (0.2696). On cognitive ability classification the multimodal ensemble reaches 0.5313 accuracy, above the baseline of 0.4062 yet below a compact subject-attribute baseline of 0.5781, indicating that perfor
What carries the argument
Frozen multimodal encoders (CLIP, Whisper, RoBERTa/E5/DeBERTaV3) feeding low-capacity models with per-trait regression and late fusion.
If this is right
- Per-trait modeling alone lowers MSE relative to a single global model.
- Late fusion across visual, acoustic, and multiple text encoders produces an additional reduction to 0.2696 MSE.
- Cognitive ability classification is better explained by subject attributes than by multimodal interview content.
- Frozen encoders suffice for personality trait prediction when labeled data are limited.
- Dataset construction for cognitive ability tasks must control for demographic shortcuts to support genuine content-based inference.
Where Pith is reading between the lines
- Future AVI datasets could deliberately decorrelate subject attributes from targets to test whether frozen embeddings capture interview content rather than demographics.
- The same frozen pipeline could be applied to other small-sample psychological prediction tasks where fine-tuning is impractical.
- One could measure how much additional gain comes from including more text encoders or different fusion weights on a shortcut-free split.
Load-bearing premise
The personality trait validation split lacks the subject-attribute shortcuts that appear to drive the cognitive ability results.
What would settle it
Evaluating the identical frozen-embedding pipeline on a new validation split in which subject attributes such as age, gender, or education level are balanced or uncorrelated with the target traits would show whether the 19 percent MSE reduction remains.
Figures
read the original abstract
Predicting psychological traits from asynchronous video interviews (AVIs) is a challenging problem in AI-assisted interview assessment because labeled datasets are limited while each response contains high-dimensional visual, acoustic, and verbal signals. This paper presents our solution for the ACM Multimedia AVI Challenge 2026, which evaluates two tasks: Track~1 predicts self-reported HEXACO personality traits from personality-related interview responses, and Track~2 classifies cognitive ability levels from structured AVI responses. We treat the problem as a small-sample representation learning task. Instead of fine-tuning large pretrained models, we use frozen multimodal encoders, including CLIP for visual features, Whisper for acoustic features and transcripts, and RoBERTa, E5, and DeBERTaV3 for textual representations, followed by low-capacity downstream models. For Track~1, our trait-specific regression and late-fusion system achieves an average validation MSE of 0.2696, improving over the official baseline of 0.3334. Ablation results show a three-step improvement from a global model (0.3189), to per-trait modeling (0.2871), to per-trait late fusion (0.2696), corresponding to a 19.1% relative MSE reduction over the official baseline. For Track~2, a compact subject-attribute baseline reaches 0.5781 accuracy, while our multimodal ensemble reaches 0.5313, both above the official baseline of 0.4062. We interpret this result as evidence of possible subject-attribute shortcuts in the validation split rather than robust cognitive inference from AVI content. Overall, our findings suggest that AVI-based psychological assessment benefits from trait-specific multimodal modeling, but cognitive ability prediction requires careful control of dataset shortcuts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a solution for the ACM Multimedia AVI Challenge 2026 using frozen multimodal encoders (CLIP, Whisper, RoBERTa, E5, DeBERTaV3) and low-capacity downstream models for two tasks. For Track 1 (HEXACO personality traits), trait-specific regression with late fusion achieves average validation MSE of 0.2696 (vs. official baseline 0.3334), with ablations showing gains from global model (0.3189) to per-trait (0.2871) to late-fusion (0.2696), a 19.1% relative reduction. For Track 2 (cognitive ability), the multimodal ensemble reaches 0.5313 accuracy but is outperformed by a subject-attribute baseline at 0.5781 (both above official baseline 0.4062), which the authors interpret as evidence of validation-split shortcuts rather than robust content-based inference.
Significance. If the central empirical claims hold after addressing the noted gaps, the work provides a clear demonstration of the benefits of trait-specific modeling and late fusion with frozen embeddings for personality prediction, along with transparent ablation results. The explicit reporting and interpretation of the subject-attribute baseline for Track 2 is a strength, as it directly tests for dataset artifacts in psychological assessment tasks and offers a reproducible cautionary example for similar small-sample AVI studies.
major comments (2)
- [Track 1 results paragraph] Track 1 results paragraph (and abstract): The interpretation that the three-step ablation (global 0.3189 → per-trait 0.2871 → late-fusion 0.2696) demonstrates genuine signal capture by the frozen embeddings (yielding 19.1% MSE reduction) assumes the personality validation split contains no subject-attribute shortcuts of the kind shown for Track 2. No equivalent subject-attribute regression baseline is reported on the Track 1 targets, leaving this load-bearing assumption untested.
- [Track 1 and Track 2 results paragraphs] Track 1 and Track 2 results paragraphs: All central performance numbers (MSE values 0.2696/0.3189/0.2871, accuracies 0.5313/0.5781) are reported from a single challenge validation split without error bars, statistical significance tests against the baseline, or external validation, which directly affects the reliability of the claimed improvements and the shortcut interpretation.
minor comments (1)
- [Methods] Methods section: Provide additional detail on the exact architecture and hyperparameters of the low-capacity downstream regression/classification heads and the late-fusion procedure to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting important limitations in our evaluation. We address each point below with honest revisions where feasible within the challenge constraints.
read point-by-point responses
-
Referee: [Track 1 results paragraph] Track 1 results paragraph (and abstract): The interpretation that the three-step ablation (global 0.3189 → per-trait 0.2871 → late-fusion 0.2696) demonstrates genuine signal capture by the frozen embeddings (yielding 19.1% MSE reduction) assumes the personality validation split contains no subject-attribute shortcuts of the kind shown for Track 2. No equivalent subject-attribute regression baseline is reported on the Track 1 targets, leaving this load-bearing assumption untested.
Authors: We agree this is a valid concern and a load-bearing assumption. We will add an equivalent subject-attribute regression baseline for the Track 1 targets in the revision to directly test for shortcuts and allow comparison with the Track 2 analysis. revision: yes
-
Referee: [Track 1 and Track 2 results paragraphs] Track 1 and Track 2 results paragraphs: All central performance numbers (MSE values 0.2696/0.3189/0.2871, accuracies 0.5313/0.5781) are reported from a single challenge validation split without error bars, statistical significance tests against the baseline, or external validation, which directly affects the reliability of the claimed improvements and the shortcut interpretation.
Authors: We acknowledge the limitation of reporting from a single fixed validation split provided by the challenge. We will add error bars by re-running models across multiple random seeds where computationally feasible. Statistical significance testing is difficult without multiple independent splits, and external validation on separate datasets is outside the scope of this challenge paper. revision: partial
- External validation on independent datasets beyond the challenge-provided split
Circularity Check
No circularity: all results are direct empirical measurements
full rationale
The paper reports MSE values (0.2696, 0.3189, 0.2871, 0.2696) and accuracies (0.5781, 0.5313) obtained by training low-capacity models on frozen encoder outputs and evaluating on the challenge validation split. No equations, derivations, or first-principles claims exist. No self-citations are invoked for uniqueness or load-bearing premises. The three-step ablation is a sequence of measured outcomes, not quantities that reduce to fitted parameters by construction. The interpretation about shortcuts is an external hypothesis, not an internal derivation step. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- downstream model capacity
axioms (1)
- domain assumption Frozen multimodal encoders capture personality-related signals without task-specific fine-tuning
Reference graph
Works this paper leans on
-
[1]
Sylvain Arlot and Alain Celisse. 2010. A survey of cross-validation procedures for model selection.Statistics Surveys4 (2010), 40–79. doi:10.1214/09- SS054
work page doi:10.1214/09- 2010
-
[2]
Michael C. Ashton and Kibeom Lee. 2007. Empirical, theoretical, and practical advantages of the HEXACO model of personality structure.Personality and Social Psychology Review11, 2 (2007), 150–166. doi:10.1177/1088868306294907
-
[3]
1956.Perception and the Representative Design of Psychological Experiments
Egon Brunswik. 1956.Perception and the Representative Design of Psychological Experiments. University of California Press, Berkeley, CA
1956
-
[4]
John B. Carroll. 1993.Human Cognitive Abilities: A Survey of Factor-Analytic Studies. Cambridge University Press, Cambridge, UK
1993
-
[5]
David C. Funder. 1995. On the accuracy of personality judgment: A realistic approach.Psychological Review102, 4 (1995), 652–670. doi:10.1037/0033- 295X.102.4.652 9
-
[6]
Pierre Geurts, Damien Ernst, and Louis Wehenkel. 2006. Extremely randomized trees.Machine Learning63, 1 (2006), 3–42. doi:10.1007/s10994-006- 6226-1
-
[7]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2023. DeBERTaV3: Improving DeBERTa using ELECTRA-style pre-training with gradient- disentangled embedding sharing. InThe Eleventh International Conference on Learning Representations (ICLR 2023). https://openreview.net/forum? id=sE7-XhLxHA
2023
-
[8]
Louis Hickman, Nigel Bosch, Vincent Ng, Rachel Saef, Louis Tay, and Sang Eun Woo. 2022. Automated video interview personality assessments: Reliability, validity, and generalizability investigations.Journal of Applied Psychology107, 8 (2022), 1323–1351. doi:10.1037/apl0000695
-
[9]
Louis Hickman, Louis Tay, and Sang Eun Woo. 2025. Are automated video interviews smart enough? Behavioral modes, reliability, validity, and bias of machine learning cognitive ability assessments.Journal of Applied Psychology110, 3 (2025), 314–335. doi:10.1037/apl0001236
-
[10]
Arthur E. Hoerl and Robert W. Kennard. 1970. Ridge regression: Biased estimation for nonorthogonal problems.Technometrics12, 1 (1970), 55–67. doi:10.1080/00401706.1970.10488634
-
[11]
Julio C. S. Jacques Junior, Yağmur Güçlütürk, Marc Pérez, Umut Güçlü, Carlos Andujar, Xavier Baró, Hugo Jair Escalante, Isabelle Guyon, Marcel A. J. van Gerven, Rob van Lier, and Sergio Escalera. 2022. First impressions: A survey on vision-based apparent personality trait analysis.IEEE Transactions on Affective Computing13, 1 (2022), 75–95. doi:10.1109/TA...
-
[12]
Rongfan Liao, Siyang Song, and Hatice Gunes. 2024. An open-source benchmark of deep learning models for audio-visual apparent and self-reported personality recognition.IEEE Transactions on Affective Computing15, 3 (2024), 1590–1607. doi:10.1109/TAFFC.2024.3363710
-
[13]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A robustly optimized BERT pretraining approach. arXiv:1907.11692
Pith/arXiv arXiv 2019
-
[14]
Eden-Raye Lukacik, Joshua S. Bourdage, and Nicolas Roulin. 2022. Into the void: A conceptual model and research agenda for the design and use of asynchronous video interviews.Human Resource Management Review32, 1 (2022), 100789. doi:10.1016/j.hrmr.2020.100789
-
[15]
Kevin S. McGrew. 2009. CHC theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research.Intelligence37, 1 (2009), 1–10. doi:10.1016/j.intell.2008.08.004
-
[16]
Iftekhar Tanveer, Daniel Gildea, and Mohammed Ehsan Hoque
Iftekhar Naim, Md. Iftekhar Tanveer, Daniel Gildea, and Mohammed Ehsan Hoque. 2018. Automated analysis and prediction of job interview performance.IEEE Transactions on Affective Computing9, 2 (2018), 191–204. doi:10.1109/TAFFC.2016.2614299
-
[17]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning (ICML 2021). PMLR, 8748–8763
2021
-
[18]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. InProceedings of the 40th International Conference on Machine Learning (ICML 2023). PMLR, 28492–28518
2023
-
[19]
Manish Raghavan, Solon Barocas, Jon Kleinberg, and Karen Levy. 2020. Mitigating bias in algorithmic hiring: Evaluating claims and practices. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (FAT* ’20). Association for Computing Machinery, New York, NY, USA, 469–481. doi:10.1145/3351095.3372828
-
[20]
Frank L. Schmidt and John E. Hunter. 1998. The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings.Psychological Bulletin124, 2 (1998), 262–274. doi:10.1037/0033-2909.124.2.262
-
[21]
Chanchal Suman, Sriparna Saha, Aditya Gupta, Saurabh Kumar Pandey, and Pushpak Bhattacharyya. 2022. A multi-modal personality prediction system.Knowledge-Based Systems236 (2022), 107715. doi:10.1016/j.knosys.2021.107715
-
[22]
Xiaoming Sun, Jian Huang, Shaokai Zheng, Xin Rao, and Min Wang. 2022. Personality assessment based on multimodal attention network learning with category-based mean square error.IEEE Transactions on Image Processing31 (2022), 2162–2174. doi:10.1109/TIP.2022.3152049
-
[23]
Robert P. Tett, Margaret J. Toich, and S. Burak Ozkum. 2021. Trait activation theory: A review of the literature and applications to five lines of personality dynamics research.Annual Review of Organizational Psychology and Organizational Behavior8 (2021), 199–233. doi:10.1146/annurev- orgpsych-012420-062228
-
[24]
Alessandro Vinciarelli and Gelareh Mohammadi. 2014. A survey of personality computing.IEEE Transactions on Affective Computing5, 3 (2014), 273–291. doi:10.1109/TAFFC.2014.2330816
-
[25]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text embeddings by weakly-supervised contrastive pre-training. arXiv:2212.03533
Pith/arXiv arXiv 2022
-
[26]
Oostrom, Djurre Holtrop, Zhaojie Luo, and Reinout E
Tianyi Zhang, Tianhua Qi, Antonis Koutsoumpis, Yuan Zong, Wenming Zheng, Janneke K. Oostrom, Djurre Holtrop, Zhaojie Luo, and Reinout E. de Vries. 2025. Assessing personality traits and interview performance from asynchronous video interviews. InProceedings of the 33rd ACM International Conference on Multimedia (MM ’25). Association for Computing Machiner...
-
[27]
Oostrom, Djurre Holtrop, Zhaojie Luo, and Reinout E
Tianyi Zhang, Tianhua Qi, Antonis Koutsoumpis, Yuan Zong, Wenming Zheng, Janneke K. Oostrom, Djurre Holtrop, Zhaojie Luo, and Reinout E. de Vries. 2026. AVI Challenge 2026: Assessing True Personality Traits and Cognitive Ability from Asynchronous Video Interviews (AVIs). Challenge description. ACM MM ’26. Retrieved May 21, 2026 from https://avichallenge.g...
2026
-
[28]
Hui Zou and Trevor Hastie. 2005. Regularization and variable selection via the elastic net.Journal of the Royal Statistical Society Series B: Statistical Methodology67, 2 (2005), 301–320. doi:10.1111/j.1467-9868.2005.00503.x 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.