Exploration Structure in LLM Agents for Multi-File Change Localization
Pith reviewed 2026-06-27 09:11 UTC · model grok-4.3
The pith
Non-linear domain-scoped parallel agent spawning outperforms linear exploration for localizing multi-file changes in software repositories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
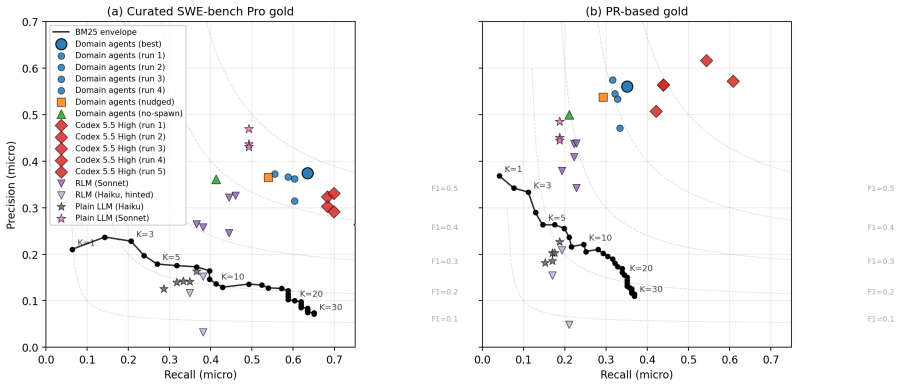
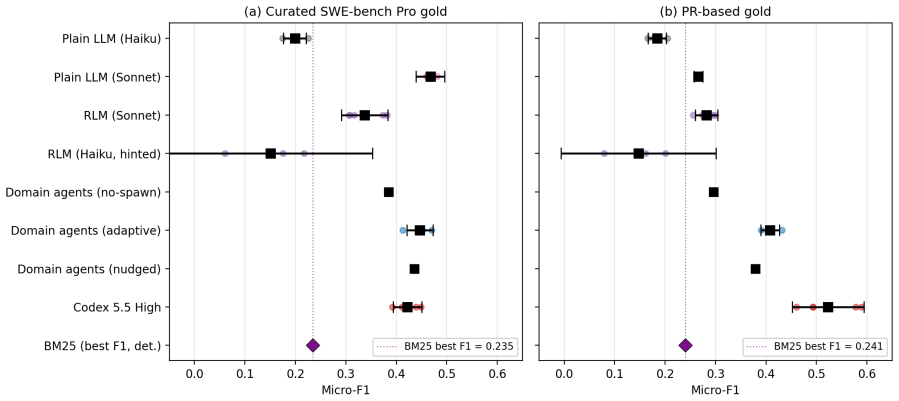
Domain scoped parallel agent spawning with a small Haiku-class model achieves the highest micro F1 among Haiku class models by a large margin. On the original SWE-bench Pro benchmark a larger plain LLM baseline reaches higher micro F1 by predicting fewer files, but the parallel domain-agent approach ranks second overall on an expanded set that includes more recent pull requests.
What carries the argument
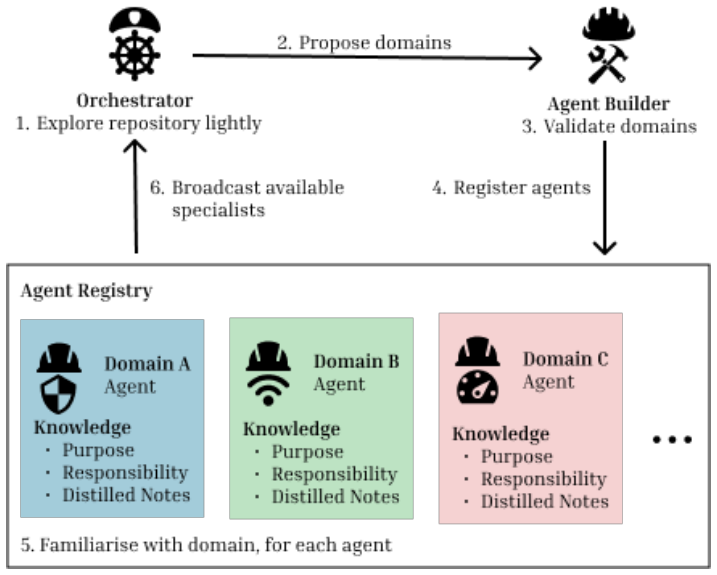
Domain-scoped parallel agent spawning: a non-linear traversal method that launches multiple independent agents in parallel, each restricted to files and directories within one repository domain or subsystem.
If this is right
- Documentation evolution remains an unresolved latent dependency across all tested approaches.
- Naive file-system access can degrade localization accuracy through over-prediction of test files.
- Forcing consultation among multiple agents raises token cost without measurable improvement in localization.
- The parallel structure ranks behind only a much larger model on an expanded benchmark that includes 2025 and 2026 pull requests.
Where Pith is reading between the lines
- The same parallel structure could be tested on tasks that also require multi-subsystem reasoning, such as refactoring or cross-module debugging.
- Smaller models gaining the largest relative benefit suggests the method may enable lower-cost deployment for localization without sacrificing accuracy.
- Anchoring evaluation at one commit may overlook how repository evolution changes which files are relevant over time.
Load-bearing premise
The persistent-session evaluation anchored at a single base commit on GitHub issues from SWE-bench Pro focused on ansible is representative of real multi-file change localization tasks.
What would settle it
A replication study on a different language or repository collection in which linear sequential agents match or exceed the micro F1 of the domain-scoped parallel agents would falsify the central performance claim.
Figures
read the original abstract
Software engineering tools increasingly rely on LLM based agents to localize files to change to resolve a software issue. Most AI agents explore repositories linearly, that is, visiting one directory or file per step. We postulate that this is a structural mismatch for changes that span several subsystems. We compare linear sequential exploration against non-linear, domain-scoped parallel agentic exploration. Using SWE Bench Pro as initial benchmark, we focus on ansible as an exemplar. We construct an approach for persistent-session evaluation of GitHub issues anchored at a single base commit. We compare our non-linear domain-agent file traversal system against a base LLM without direct repository access, a single agent Recursive Language Model (RLM) baseline with a persistent Python REPL and an external CLI baseline using Codex 5.5 High. Domain scoped parallel agent spawning with a small Haiku-class model achieves the highest micro F1 among Haiku class models by a large margin. Domain-agents is the second highest behind only the much larger Codex 5.5 High on our own expanded benchmark including over more recent PRs from 2025 and 2026. On the original, curated, 2020 SWE-bench Pro benchmark, a larger Sonnet plain LLM baseline attains higher micro F1 by predicting few files, leading to higher precision, but at significantly lower all gold recall. We also present three additional findings. First, documentation evolution is a latent dependency unresolved by any approach. Second, naive file system access can degrade localization driven by test-file over prediction. Lastly, forced multi-agent consultation does not measurably help and raises token cost substantially.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that non-linear domain-scoped parallel agent spawning outperforms linear sequential exploration for multi-file change localization tasks. Using a persistent-session evaluation anchored at a single base commit on ansible issues from SWE-bench Pro, it reports that a domain-agents approach with a small Haiku-class model achieves the highest micro F1 among Haiku-class models by a large margin (second only to the larger Codex 5.5 High baseline on an expanded set), while also presenting three post-hoc findings on documentation evolution, naive FS access causing test-file over-prediction, and lack of benefit from forced multi-agent consultation.
Significance. If the central empirical comparison holds after addressing evaluation confounds, the work would indicate that exploration structure is a load-bearing design choice for LLM agents in software engineering, with potential to improve localization on subsystem-spanning issues. The persistent-session setup anchored at one commit is a methodological strength that supports reproducibility and controlled comparison.
major comments (3)
- [Abstract] Abstract: the claim that domain scoped parallel agent spawning 'achieves the highest micro F1 among Haiku class models by a large margin' is presented without any quantitative F1 values, confidence intervals, error bars, or statistical tests, making it impossible to evaluate the magnitude or reliability of the reported superiority.
- [Abstract] Abstract / Evaluation description: the persistent-session evaluation is restricted to an ansible-only subset of SWE-bench Pro anchored at a single base commit; this setup does not isolate exploration structure from domain-specific factors or state, especially given the abstract's own observation that documentation evolution remains unresolved by all methods and that naive FS access drives test-file over-prediction.
- [Abstract] Abstract: the chosen baselines (plain LLM without repository access, single-agent RLM with REPL, Codex CLI) do not appear to control for project-specific scoping or multi-session state that parallel domain spawning may implicitly introduce, so gains cannot be confidently attributed to non-linear structure rather than unmatched confounds.
minor comments (1)
- [Abstract] The three additional findings are described qualitatively without supporting quantitative data or tables, reducing their utility as evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and evaluation design. We address each point below and will revise the manuscript where the suggestions strengthen clarity without changing the core claims or results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that domain scoped parallel agent spawning 'achieves the highest micro F1 among Haiku class models by a large margin' is presented without any quantitative F1 values, confidence intervals, error bars, or statistical tests, making it impossible to evaluate the magnitude or reliability of the reported superiority.
Authors: We agree that the abstract would be improved by including the specific micro F1 values. The results section reports the exact scores demonstrating the margin for the Haiku-class domain-agents approach relative to other Haiku baselines. We will update the abstract to state the quantitative F1 scores and the observed margin. revision: yes
-
Referee: [Abstract] Abstract / Evaluation description: the persistent-session evaluation is restricted to an ansible-only subset of SWE-bench Pro anchored at a single base commit; this setup does not isolate exploration structure from domain-specific factors or state, especially given the abstract's own observation that documentation evolution remains unresolved by all methods and that naive FS access drives test-file over-prediction.
Authors: The ansible subset serves as a focused exemplar of multi-subsystem changes, and anchoring all methods at the identical base commit ensures they operate under the same repository state. The findings regarding documentation evolution and test-file over-prediction are reported as applying across all methods. We will revise the abstract to more explicitly describe how the persistent-session design enables controlled comparison of exploration structures. revision: partial
-
Referee: [Abstract] Abstract: the chosen baselines (plain LLM without repository access, single-agent RLM with REPL, Codex CLI) do not appear to control for project-specific scoping or multi-session state that parallel domain spawning may implicitly introduce, so gains cannot be confidently attributed to non-linear structure rather than unmatched confounds.
Authors: The baselines represent standard non-agentic LLM use, single-agent persistent interaction via REPL, and a strong external agent system. The RLM baseline incorporates multi-turn state, while the domain-agents approach tests the addition of non-linear parallel spawning within domain scopes. We maintain that the primary contrast is exploration structure and that the results support attribution to this factor rather than unmatched confounds. revision: no
Circularity Check
No circularity: purely empirical benchmark comparisons with no derivations or self-referential reductions
full rationale
The paper reports experimental results from persistent-session evaluations on SWE-bench Pro (ansible subset) and an expanded set of PRs. It compares domain-scoped parallel agents against baselines (plain LLM, single-agent RLM with REPL, Codex CLI) using micro F1, precision, and recall. No equations, parameter fittings, uniqueness theorems, or ansatzes are present. Central claims are direct outcome measurements from the described setups, not quantities that reduce by construction to inputs or prior self-citations. The evaluation design and findings (including limitations on documentation evolution and test-file over-prediction) are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SWE-bench Pro issues anchored at a single base commit provide a fair test of multi-file change localization across subsystems.
Reference graph
Works this paper leans on
-
[1]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, et al. MetaGPT: Meta programming for a multi-agent collaborative framework.arXiv preprint arXiv:2308.00352,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, et al. LongBench v2: Towards deeper understanding and reasoning on realistic long-context multitasks.arXiv preprint arXiv:2412.15204,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
SWE-bench Pro: Enterprise-level software engineering evaluation.Hugging Face Dataset, 2025.https://huggingface.co/datasets/ScaleAI/SWE-bench_Pro
Scale AI. SWE-bench Pro: Enterprise-level software engineering evaluation.Hugging Face Dataset, 2025.https://huggingface.co/datasets/ScaleAI/SWE-bench_Pro. SWE-bench team. SWE-bench Verified. Princeton NLP,
2025
-
[4]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
https://huggingface.co/ datasets/princeton-nlp/SWE-bench_Verified. Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, et al. OpenHands: An open platform for AI software developers as generalist agents.arXiv preprint arXiv:2407.16741,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying LLM- based software engineering agents.arXiv preprint arXiv:2407.01489,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, et al. SWE-agent: Agent-computer interfaces enable automated software engineering.arXiv preprint arXiv:2405.15793,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Alex L. Zhang, Tim Kraska, and Omar Khattab. Recursive language models.arXiv preprint arXiv:2512.24601,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
SequenceR: Sequence-to-sequence learning for end-to-end program repair.IEEE Transactions on Software Engineering, 47(9):1943–1959,
Zimin Chen, Steve Kommrusch, Michele Tufano, Louis-No ¨el Pouchet, Denys Poshyvanyk, and Mar- tin Monperrus. SequenceR: Sequence-to-sequence learning for end-to-end program repair.IEEE Transactions on Software Engineering, 47(9):1943–1959,
1943
-
[9]
CodeR: Issue resolving with multi-agent and task graphs.arXiv preprint arXiv:2406.01304,
Dong Chen, Shaoxin Lin, Muhan Zeng, Daoguang Zan, Jian-Gang Wang, Anton Cheshkov, Jun Sun, Hao Yu, Guoliang Dong, Artem Aliev, Jie Wang, Xiao Cheng, Guangtai Liang, Yuchi Ma, Pan Bian, Tao Xie, and Qianxiang Wang. CodeR: Issue resolving with multi-agent and task graphs.arXiv preprint arXiv:2406.01304,
-
[10]
Yingwei Ma, Rongyu Cao, Yongchang Cao, Yue Zhang, Jue Chen, Yibo Liu, Yuchen Liu, Binhua Li, Fei Huang, and Yongbin Li. Lingma SWE-GPT: An open development-process-centric language model for automated software improvement.arXiv preprint arXiv:2411.00622,
-
[11]
How to understand whole software repository?arXiv preprint arXiv:2406.01422,
Yingwei Ma, Qingping Yang, Rongyu Cao, Binhua Li, Fei Huang, and Yongbin Li. How to understand whole software repository?arXiv preprint arXiv:2406.01422,
-
[12]
Huy Nhat Phan, Phong X. Nguyen, and Nghi D. Q. Bui. HyperAgent: Generalist software engineering agents to solve coding tasks at scale.arXiv preprint arXiv:2409.16299,
-
[13]
files": [
A Prompt Templates Task Prompt (Plain LLM, RLM, domain agents, Codex) Identify the repo-relative files that would need to be modified to implement the requested fix. Include code, test, and documentation files when they would need edits. Do not edit files. Use the repository tools to inspect the codebase (where available). Prefer exact existing file paths...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.